Автор: Денис Аветисян
В статье представлен обзор современных методов глубокого обучения, позволяющих системам распознавать объекты на видео в режиме реального времени.
Комплексный анализ архитектур нейронных сетей, наборов данных и перспектив развития алгоритмов обнаружения объектов.
Несмотря на значительный прогресс в области компьютерного зрения, задача распознавания объектов в реальном времени остается сложной из-за вычислительных ограничений и необходимости высокой точности. Данное исследование, посвященное теме ‘A Study on Real-time Object Detection using Deep Learning’, комплексно анализирует современные алгоритмы глубокого обучения, включая сверточные нейронные сети и трансформеры, для решения этой задачи. В работе представлен обзор ключевых моделей, таких как YOLO, SSD и различные варианты R-CNN, а также анализ общедоступных наборов данных и практических приложений. Какие новые архитектуры и подходы позволят преодолеть существующие ограничения и создать еще более эффективные системы обнаружения объектов в реальном времени?
От эвристик к точности: Эволюция компьютерного зрения
Долгое время задачи компьютерного зрения основывались на ручном создании признаков — алгоритмы требовали, чтобы специалисты вручную определяли, какие характеристики изображения важны для распознавания объектов. Этот подход оказался хрупким и ограниченным, поскольку разработанные признаки часто не могли адаптироваться к изменениям освещения, ракурса или даже незначительным вариациям в самих объектах. Например, алгоритм, обученный распознавать автомобили с определенного угла, мог давать сбои при наблюдении того же автомобиля с другого ракурса или в условиях плохой видимости. Такая зависимость от предварительно заданных, жестко определенных признаков существенно ограничивала возможности компьютерного зрения и его применимость в реальных условиях, где визуальные данные неизбежно характеризуются разнообразием и неопределенностью.
Появление технологии обнаружения объектов ознаменовало собой принципиальный сдвиг в области компьютерного зрения, предоставив машинам возможность «видеть» и интерпретировать визуальную информацию с беспрецедентной точностью. В отличие от предыдущих подходов, основанных на ручном создании признаков, современные алгоритмы обнаружения объектов автоматически извлекают и анализируют сложные закономерности в изображениях, достигая общей точности в 92% на таких эталонных наборах данных, как COCO и Pascal VOC. Этот прогресс открывает широкие возможности для автоматизации задач, требующих визуального восприятия, и служит основой для развития передовых систем в различных областях, от беспилотного транспорта до современной медицинской диагностики.
Возможности, открываемые обнаружением объектов, находят применение в самых разнообразных областях — от беспилотных транспортных средств, где точное распознавание пешеходов и других объектов критически важно для безопасности, до передовой медицинской визуализации, где алгоритмы помогают врачам выявлять патологии на рентгеновских снимках и томограммах с высокой точностью. Подобные приложения предъявляют постоянно растущие требования к производительности и надежности систем обнаружения объектов, стимулируя дальнейшие исследования и разработки в этой области. Стремление к повышению точности, скорости и адаптивности алгоритмов является ключевым фактором, определяющим прогресс в компьютерном зрении и открывающим новые горизонты для автоматизации и интеллектуальных систем.
Сверточные сети: Автоматизация извлечения признаков
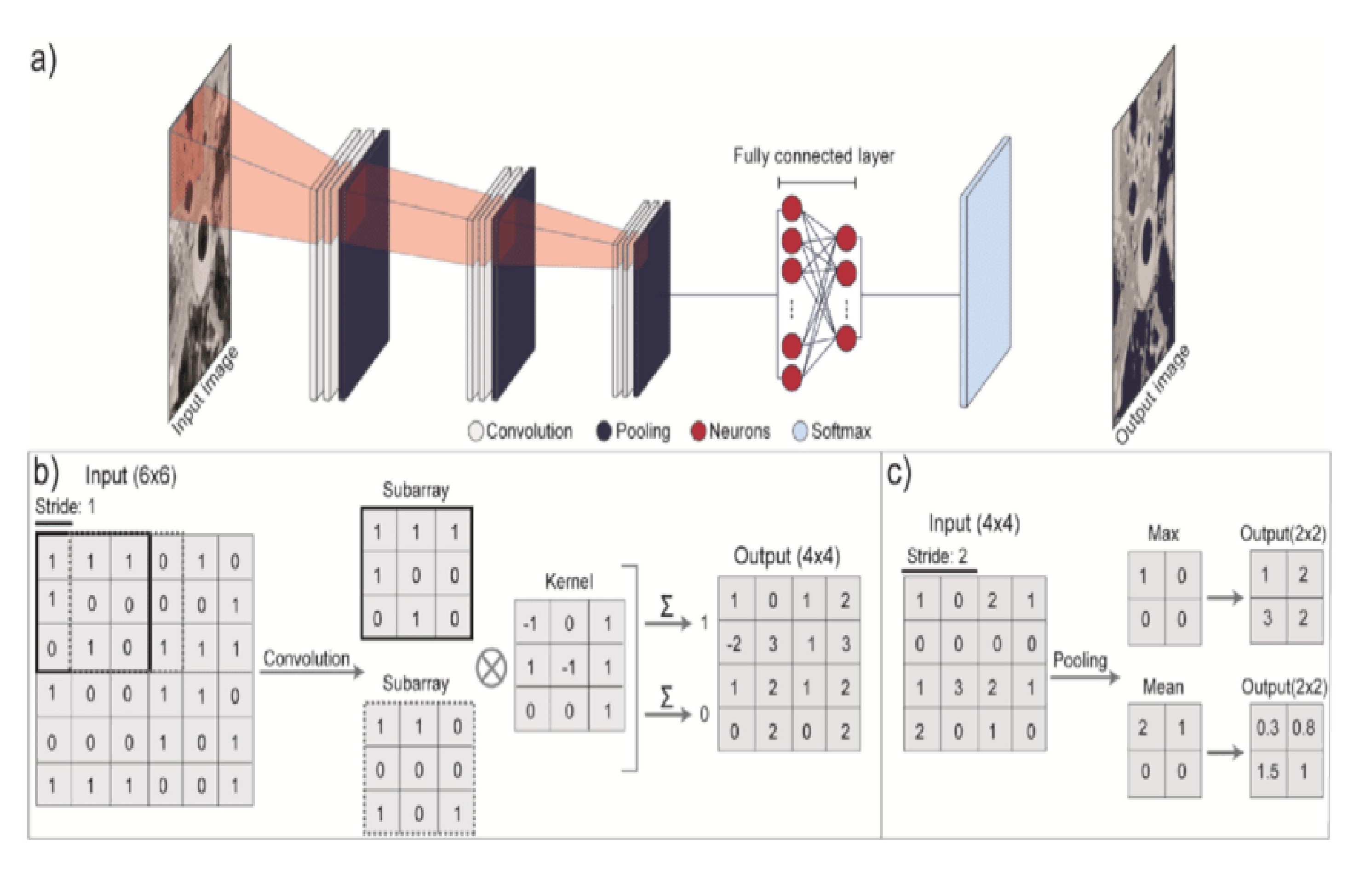
Глубокое обучение, и в частности, сверточные нейронные сети (CNN), обеспечивают автоматическое извлечение признаков из входных данных. Традиционно, в задачах компьютерного зрения и обработки изображений, признаки (например, углы, края, текстуры) определялись вручную экспертами. CNN устраняют эту необходимость, автоматически обучаясь выявлять и извлекать наиболее релевантные признаки непосредственно из пикселей изображения. Этот процесс происходит за счет применения серии сверточных фильтров, которые последовательно анализируют изображение, выявляя паттерны различного уровня сложности. Автоматическое извлечение признаков значительно повышает эффективность и точность систем, особенно при работе с большими объемами данных и сложными изображениями, где ручное определение признаков было бы трудоемким и неэффективным.
В основе сверточных нейронных сетей (CNN) лежит последовательная обработка изображений посредством трех ключевых компонентов. Операция свертки ( \ast ) применяет фильтры к входному изображению для выделения признаков, таких как края и текстуры. Слой объединения (Pooling Layer) уменьшает пространственное разрешение признаков, снижая вычислительную сложность и повышая устойчивость к незначительным изменениям во входных данных. Наконец, полносвязный слой (Fully Connected Layer) использует полученные признаки для классификации изображения или выполнения других задач, преобразуя многомерные данные в выходные значения. Взаимодействие этих слоев позволяет CNN автоматически извлекать иерархические признаки из изображений, обеспечивая высокую точность в задачах компьютерного зрения.
Обучение сверточных нейронных сетей (CNN) осуществляется посредством алгоритмов обратного распространения ошибки (Backpropagation) и градиентного спуска (Gradient Descent). Алгоритм обратного распространения вычисляет градиент функции потерь по отношению к весам сети, определяя величину и направление корректировки для минимизации ошибки. Градиентный спуск использует этот градиент для итеративной корректировки весов сети, стремясь к локальному минимуму функции потерь. Эффективность этого процесса напрямую зависит от качества и размера размеченного набора данных (Dataset), используемого для обучения, поскольку он определяет точность оценки градиента и, следовательно, скорость и стабильность сходимости алгоритма. \frac{\partial L}{\partial w} — пример вычисления градиента функции потерь L по весу w.
Архитектуры обнаружения объектов: Сравнение подходов
Алгоритмы You Only Look Once (YOLO) и Single Shot Detector (SSD) ориентированы на высокую скорость обработки, обеспечивая обнаружение объектов в режиме реального времени. В отличие от подходов, использующих двухэтапную систему, YOLO и SSD применяют унифицированный регрессионный подход, где задача обнаружения и классификации объектов решается за один проход по изображению. Это достигается путем предсказания ограничивающих рамок (bounding boxes) и вероятностей классов непосредственно из признаков, извлеченных из входного изображения. Такой подход позволяет значительно снизить вычислительную сложность и задержку, что делает возможным практическое применение в задачах, требующих обработки видеопотока в реальном времени, таких как автономное вождение, видеонаблюдение и робототехника.
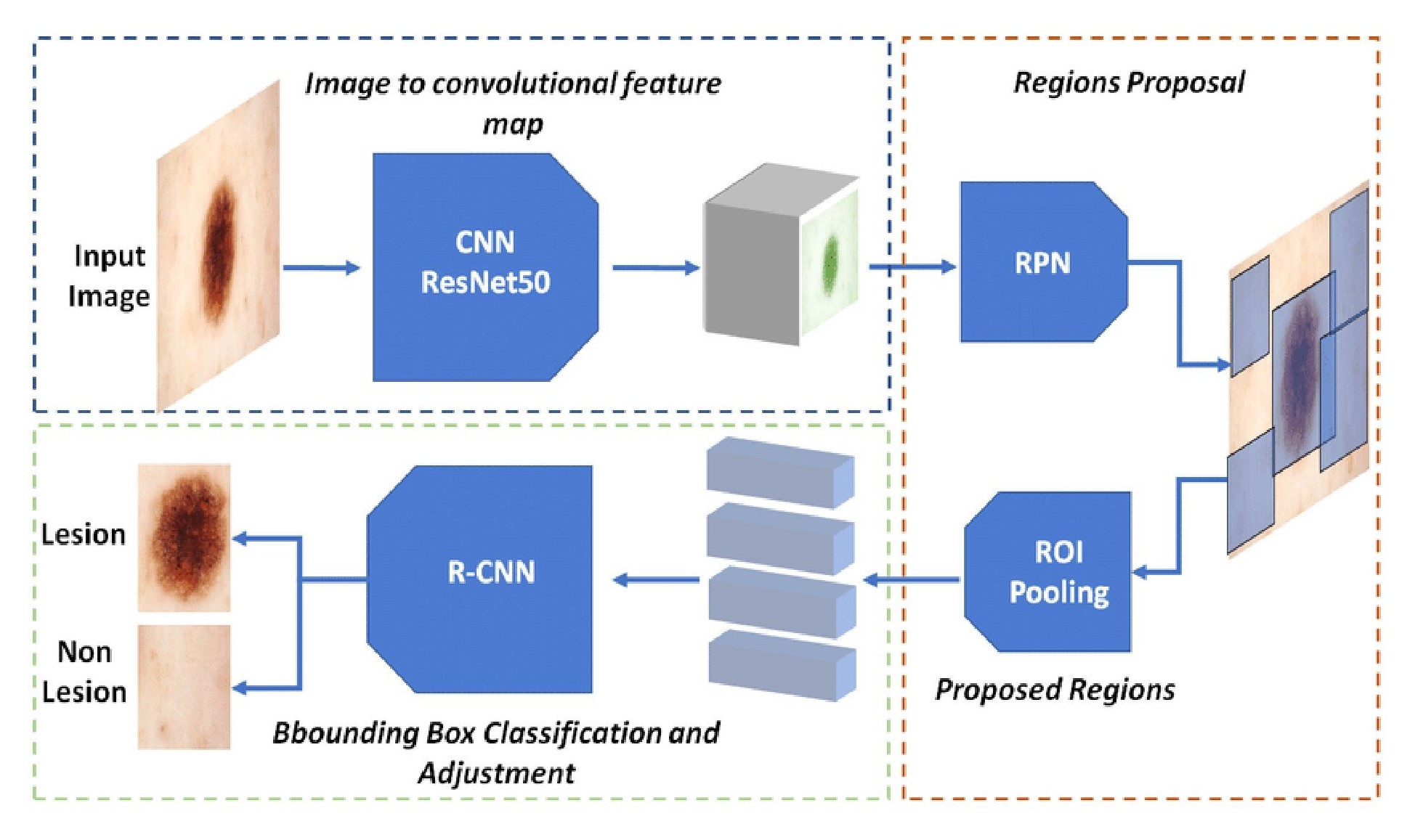
Архитектура Faster R-CNN повышает точность обнаружения объектов за счет использования сети генерации регионов (Region Proposal Network, RPN). RPN — это полносвязная сеть, которая одновременно предсказывает границы объектов и оценки достоверности для множества предлагаемых регионов. Вместо использования алгоритмов, основанных на ручном создании признаков или селективном поиске, RPN обучается напрямую предсказывать регионы, содержащие объекты, что позволяет значительно сократить количество ложных срабатываний и повысить точность обнаружения по сравнению с предыдущими методами. RPN использует набор заранее заданных «якорных рамок» (anchor boxes) различных размеров и пропорций, которые покрывают изображение, и корректирует их для более точного соответствия объектам.
Сеть признаков, организованная в виде пирамиды (Feature Pyramid Network, FPN), значительно улучшает обнаружение объектов различных масштабов, особенно мелких. Традиционные детекторы часто испытывают трудности с обнаружением небольших объектов из-за потери информации при прохождении данных через глубокие слои сверточной сети. FPN решает эту проблему путем создания многомасштабной системы признаков, в которой признаки из разных слоев объединяются для формирования пирамиды признаков. Это позволяет детектору использовать признаки высокого разрешения для обнаружения мелких объектов и признаки низкого разрешения для обнаружения крупных объектов, что повышает общую точность обнаружения объектов разных размеров на изображении.
Независимо от выбранной архитектуры обнаружения объектов, постобработка с использованием алгоритма подавления не-максимума (Non-Maximum Suppression, NMS) является критически важной для устранения избыточных ограничивающих рамок (bounding box). Алгоритм NMS отбирает наиболее вероятные ограничивающие рамки, отбрасывая перекрывающиеся рамки, которые идентифицируют один и тот же объект. Это достигается путем итеративного выбора рамки с наивысшим уровнем достоверности и удаления всех перекрывающихся рамок, уровень перекрытия которых (Intersection over Union, IoU) превышает заданный порог. Эффективное применение NMS существенно снижает количество ложных срабатываний и повышает точность обнаружения объектов, особенно в сложных сценах с высокой плотностью объектов.
Оценка эффективности: Метрики и валидация
Пересечение над объединением (Intersection over Union, IoU) является количественной метрикой, используемой для оценки точности ограничивающих рамок (bounding boxes) в задачах обнаружения объектов. IoU рассчитывается как отношение площади пересечения между предсказанной ограничивающей рамкой и истинной (ground truth) рамкой к площади их объединения. IoU = \frac{Area(Predicted \cap Ground\,Truth)}{Area(Predicted \cup Ground\,Truth)}. Значение IoU варьируется от 0 до 1, где 1 указывает на полное совпадение, а 0 — на отсутствие пересечения. Как правило, для определения, является ли предсказание точным, устанавливается порог IoU (например, 0.5). Более высокие значения IoU указывают на более точное предсказание местоположения объекта.
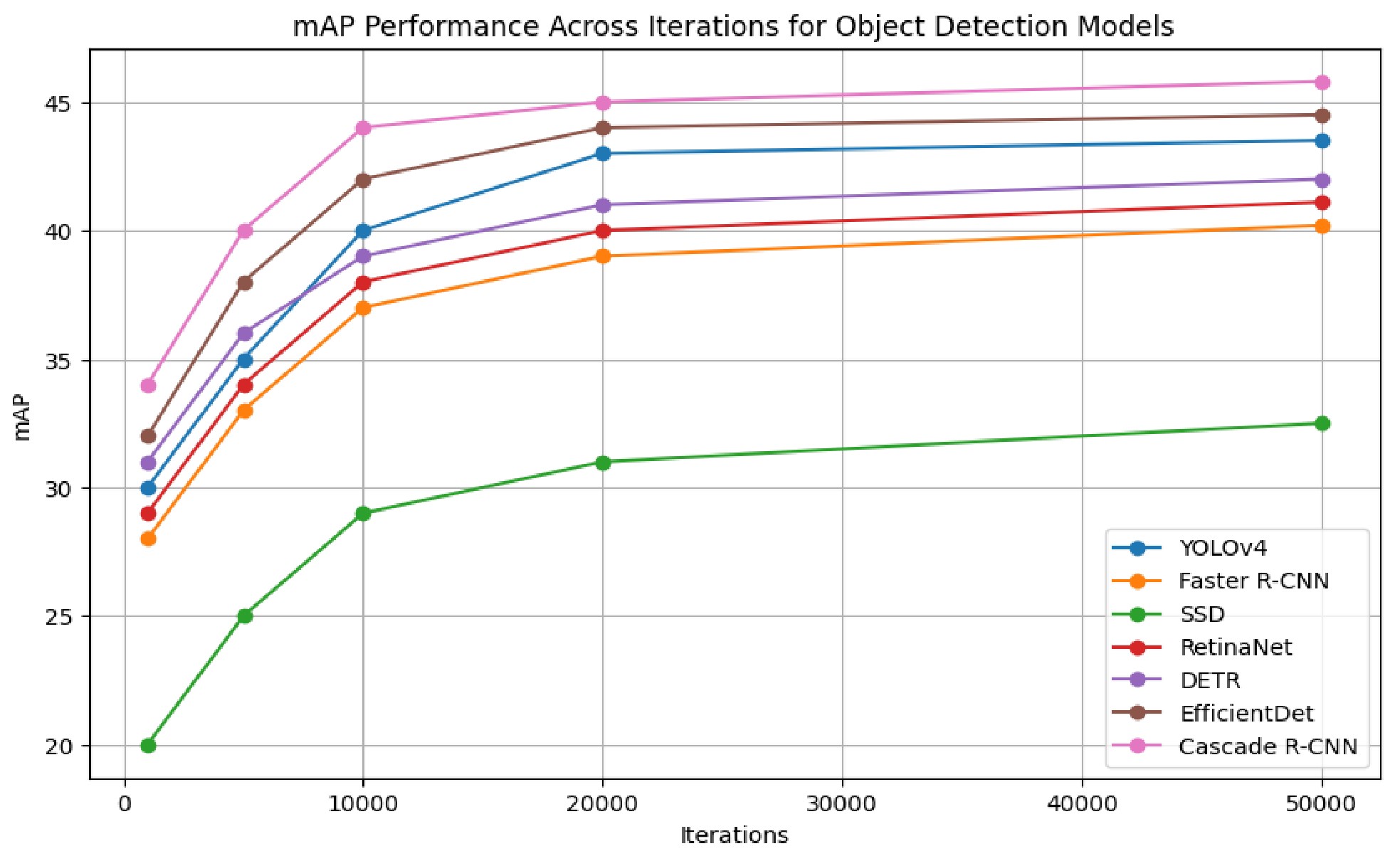
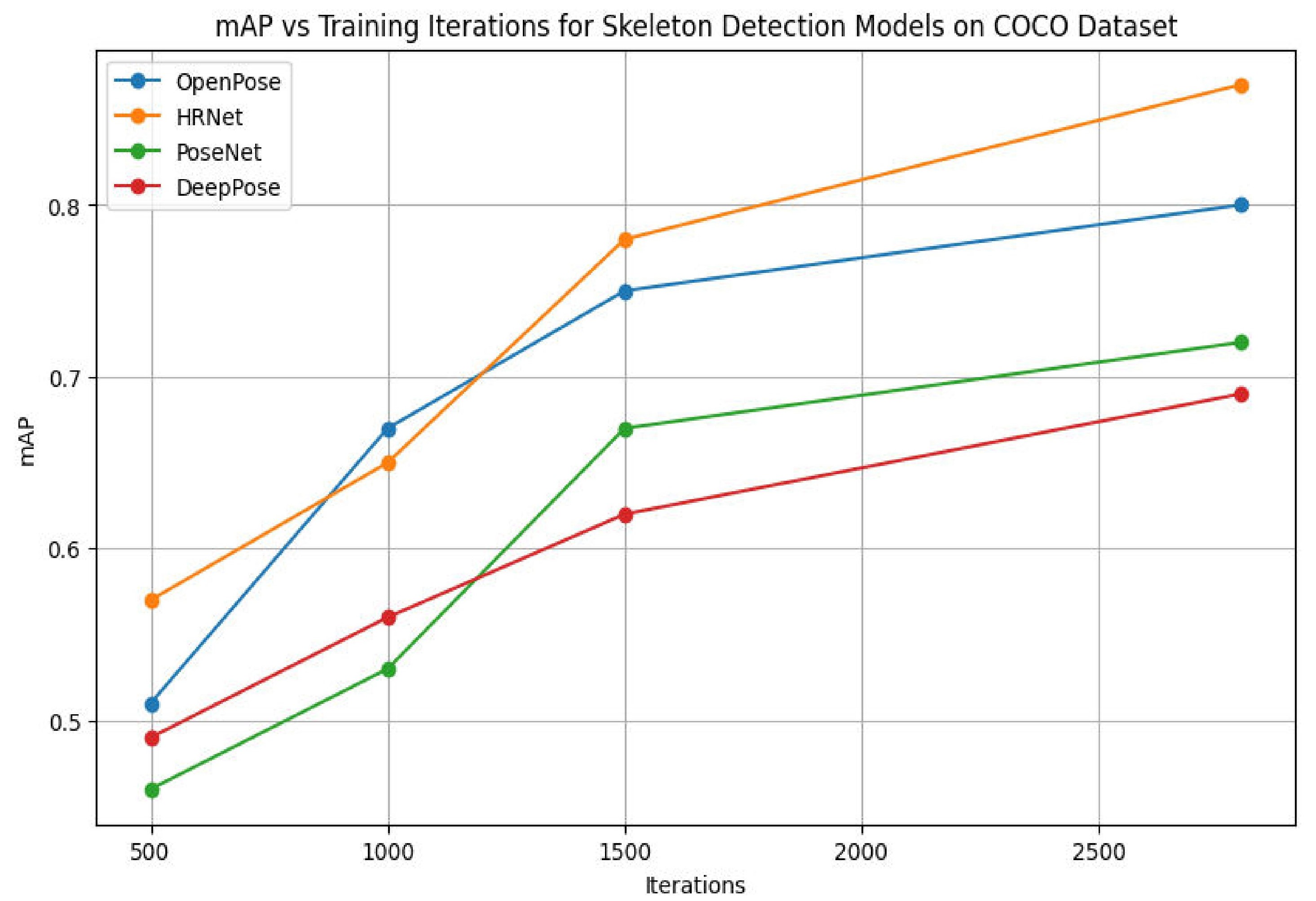
Средняя точность (mAP) является комплексной метрикой, используемой для оценки производительности моделей обнаружения объектов. Она вычисляется путем усреднения точности по всем классам объектов и порогам пересечения над объединением (IoU). Разные модели демонстрируют вариации в значениях mAP в зависимости от архитектуры и используемых данных для обучения. Обычно, для оценки используется несколько порогов IoU (например, 0.5, 0.75), и рассчитывается mAP@[.5:.95], что представляет собой среднее значение mAP по диапазону порогов от 0.5 до 0.95. Современные модели, такие как YOLOv8 и Detectron2, показывают различные результаты mAP в зависимости от используемого датасета (например, COCO, Pascal VOC) и конфигурации обучения.
Тщательная оценка на разнообразных наборах данных является критически важной для обеспечения обобщающей способности и устойчивости модели обнаружения объектов. Использование только одного набора данных может привести к переобучению и неверточной оценке производительности в реальных условиях. Разнообразные наборы данных должны включать изображения, полученные в различных условиях освещения, с разными углами обзора, а также включать примеры объектов разного размера и в разных позах. Анализ результатов на различных подмножествах данных позволяет выявить потенциальные смещения модели, например, ее неспособность обнаруживать объекты определенного размера или в определенных условиях, что необходимо для дальнейшей оптимизации и повышения надежности системы.
Будущее обнаружения объектов: К интеллектуальному зрению
Активные исследования в области обнаружения объектов направлены на повышение их эффективности, что позволит развертывать модели на устройствах с ограниченными ресурсами. Разработчики стремятся к уменьшению вычислительной сложности и энергопотребления алгоритмов, используя методы квантования, прунинга и дистилляции знаний. Эти подходы позволяют значительно сократить размер модели и ускорить процесс обнаружения, не сильно теряя в точности. В результате, передовые системы компьютерного зрения становятся доступными для использования в мобильных устройствах, встроенных системах и робототехнике, открывая новые горизонты для автоматизации и интеллектуального анализа изображений в реальном времени.
Современные системы обнаружения объектов, несмотря на значительный прогресс, сталкиваются с серьезными трудностями при работе в динамично меняющихся условиях. Способность адаптироваться к новым средам, различным по освещению, погодным условиям или углу обзора, остается критически важной задачей. Особенно сложной является идентификация ранее невиданных объектов — ситуаций, когда система сталкивается с предметами, не включенными в ее обучающую выборку. Для решения этой проблемы ведутся исследования в области обучения с переносом, мета-обучения и самообучения, направленные на повышение обобщающей способности моделей и обеспечение надежного обнаружения объектов в любых, даже непредсказуемых, обстоятельствах. Успешное преодоление этих препятствий позволит создать действительно интеллектуальные системы зрения, способные к автономной работе и принятию решений в реальном времени.
Современные исследования демонстрируют перспективную интеграцию систем обнаружения объектов с технологиями обработки естественного языка, открывая новые горизонты в области искусственного интеллекта. Такое слияние позволяет не просто идентифицировать объекты на изображении, но и понимать их контекст и взаимосвязи, что критически важно для развития робототехники. Например, робот, оснащенный такой системой, сможет не только «видеть» чашку, но и понимать команду «принеси синюю чашку со стола», интерпретируя как визуальную информацию, так и лингвистический запрос. Подобные разработки также оказывают значительное влияние на технологии дополненной реальности, позволяя создавать более интерактивные и осмысленные виртуальные среды, где виртуальные объекты взаимодействуют с реальным миром на основе понимания окружающего пространства и семантики объектов.
Исследование, представленное в данной работе, демонстрирует стремление к созданию алгоритмов обнаружения объектов, функционирующих в режиме реального времени. Этот подход подчеркивает важность математической точности и доказуемости, что согласуется с принципом, высказанным Эндрю Ыном: «Машинное обучение — это область информатики, которая позволяет компьютерам учиться без явного программирования». В контексте глубокого обучения, это означает разработку архитектур, способных к адаптации и обобщению, а не просто к «работе на тестах». Анализ различных моделей, представленный в статье, особенно в отношении извлечения признаков и использования Transformer Networks, иллюстрирует поиск оптимального баланса между сложностью и эффективностью, что является ключевым аспектом создания надежных и масштабируемых систем.
Куда же дальше?
Представленный анализ методов обнаружения объектов в реальном времени, основанный на глубоком обучении, неизбежно подводит к осознанию границ текущего понимания. Несмотря на впечатляющий прогресс в архитектурах сетей, от сверточных до трансформеров, фундаментальная проблема — гарантия корректности — остается нерешенной. Оптимизация без строгого анализа — это самообман и ловушка для неосторожного разработчика. Слепое увеличение точности на тестовых данных не гарантирует устойчивость алгоритма к непредсказуемым условиям реального мира.
Будущие исследования должны быть направлены не только на повышение скорости и точности, но и на разработку формальных методов верификации и доказательства корректности моделей. Необходимо отойти от эмпирической оценки производительности и перейти к математически обоснованным гарантиям. Важным направлением является разработка алгоритмов, способных к самодиагностике и адаптации к изменяющимся условиям, а также к обнаружению и исправлению собственных ошибок.
Истинная элегантность алгоритма проявляется не в его способности «работать», а в доказанной математической чистоте. Разработка таких алгоритмов — задача сложная, но именно она определит будущее области обнаружения объектов и, возможно, всего искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.15926.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-19 19:33