Автор: Денис Аветисян
Исследователи предлагают инновационную систему активного поиска аномалий, основанную на усилении эффекта запоминания типичных данных и последующем анализе расхождений.
Предложен алгоритм IMBoost, использующий генеративные глубокие модели для повышения эффективности обнаружения аномалий за счет максимизации различий между оценками для типичных и аномальных данных.
Обнаружение аномалий, несмотря на значительный прогресс, остается сложной задачей, особенно в условиях отсутствия размеченных данных. В статье ‘Memorize Early, Then Query: Inlier-Memorization-Guided Active Outlier Detection’ предложен новый подход, использующий феномен запоминания вхожих данных (inlier memorization) в глубоких генеративных моделях. Разработанный фреймворк IMBoost усиливает этот эффект посредством активного обучения, максимизируя расхождение между оценками вхожих и выбросов на двух фазах: предварительной и поляризации. Сможет ли IMBoost обеспечить более эффективное и экономичное обнаружение аномалий по сравнению с существующими методами, особенно при ограниченном бюджете разметки?
Шёпот Хаоса: Вызовы Обнаружения Выбросов
Традиционные методы обнаружения выбросов сталкиваются со значительными трудностями при анализе сложных, многомерных распределений данных. В ситуациях, когда количество признаков велико, а взаимосвязи между ними нелинейны, стандартные алгоритмы, основанные на статистических предположениях о нормальном распределении или евклидовом расстоянии, часто оказываются неэффективными. Это связано с тем, что в высокоразмерном пространстве данные становятся разреженными, а понятие «расстояния» теряет свою интуитивную значимость, что приводит к ложным срабатываниям и пропуску реальных аномалий. Кроме того, “проклятие размерности” усложняет задачу поиска ближайших соседей, необходимого для многих алгоритмов обнаружения выбросов, и требует значительных вычислительных ресурсов. В результате, эффективность традиционных методов существенно снижается по мере увеличения размерности данных, что требует разработки новых подходов, способных эффективно работать с комплексными распределениями.
Традиционные методы выявления выбросов зачастую опираются на жесткие предположения о распределении данных, что ограничивает их применимость к реальным задачам, где эти предположения могут не выполняться. Более того, вычислительная сложность многих алгоритмов резко возрастает с увеличением размерности данных и объема выборки, делая их непрактичными для обработки больших массивов информации. Это особенно актуально в таких областях, как обнаружение мошенничества или мониторинг состояния оборудования, где требуется анализ огромных потоков данных в режиме реального времени. В результате, существующие подходы часто оказываются либо недостаточно точными, либо слишком ресурсоемкими для эффективного применения на практике, что стимулирует поиск новых, более адаптивных и масштабируемых решений.
Основная сложность в обнаружении аномалий заключается в неспособности большинства методов эффективно использовать внутреннюю структуру данных. Традиционные алгоритмы зачастую рассматривают данные как набор изолированных точек, игнорируя взаимосвязи и закономерности, которые могут указывать на истинные отклонения. Это приводит к тому, что нормальные, но необычные комбинации признаков ошибочно классифицируются как аномалии, в то время как замаскированные аномалии, соответствующие общей структуре данных, остаются незамеченными. Более того, в многомерных пространствах, где данные представлены в виде сложных взаимосвязанных структур, игнорирование этих структур существенно снижает точность и надежность обнаружения аномалий, делая задачу особенно сложной и требующей новых подходов, учитывающих геометрические и топологические свойства данных.
IMBoost: Укрощение Хаоса через Запоминание Нормы
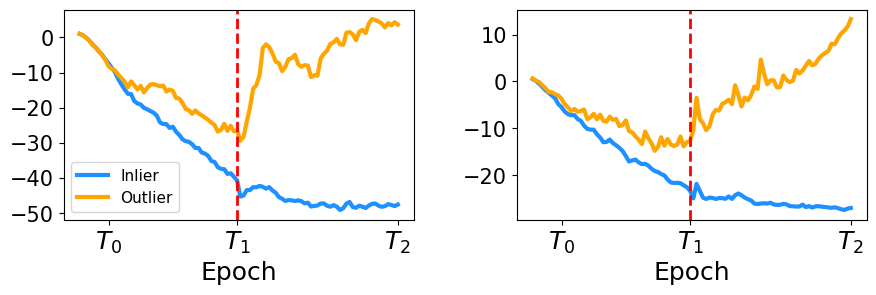
Принцип “запоминания нормальных образцов” (inlier-memorization effect) лежит в основе работы IMBoost и заключается в том, что нейронные сети, как правило, быстрее и эффективнее обучаются распознавать преобладающие, нормальные паттерны в данных, прежде чем они смогут эффективно выявлять аномалии. Это связано с тем, что большая часть обучающих данных обычно представляет собой нормальное поведение, и модель, оптимизируясь для минимизации ошибки, сначала стремится наилучшим образом смоделировать именно эти преобладающие паттерны. Последующее выявление аномалий становится возможным благодаря способности модели к обобщению и выявлению отклонений от уже заученных нормальных представлений. Этот эффект является ключевым для повышения эффективности и точности алгоритмов обнаружения аномалий.
В основе IMBoost лежит двухфазный подход к обучению. На фазе «разогрева» (warm-up) модель интенсивно обучается на данных, представляющих нормальное поведение (inliers), с целью формирования надежного представления об их распределении. Вторая фаза — «поляризация» (polarization) — направлена на усиление различий между данными, соответствующими нормальному поведению, и аномальными данными (outliers). Этот процесс позволяет модели более эффективно идентифицировать отклонения от нормального поведения, повышая точность обнаружения аномалий.
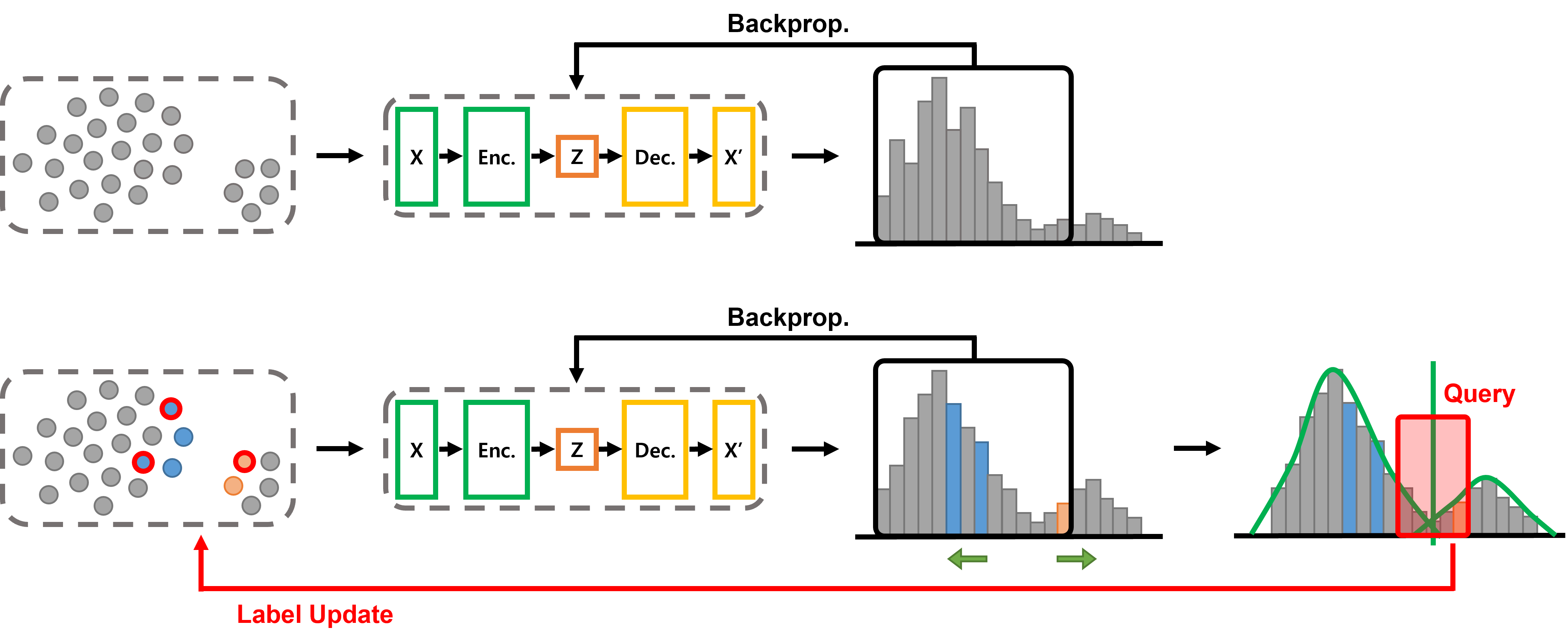
В основе IMBoost лежит использование генеративной модели данных (DGM) для эффективного моделирования распределения данных и вычисления оценок выбросов. DGM позволяет построить вероятностную модель, описывающую типичные характеристики входных данных, что необходимо для точного определения аномалий. Оценка выбросов производится на основе вероятности, с которой конкретный экземпляр данных может быть сгенерирован данной моделью; низкая вероятность указывает на потенциальный выброс. Применение DGM в IMBoost позволило достичь передовых результатов в задачах обнаружения аномалий, превосходя существующие методы по ключевым метрикам.
Активное Обучение для Усиления Поляризации: Искусство Вопросов
Фаза поляризации использует методы активного обучения для целенаправленного отбора данных, концентрируясь на точках, наиболее информативных для разграничения выбросов. Вместо случайного выбора, система активно запрашивает данные, которые, как ожидается, окажут наибольшее влияние на улучшение различия между оценками для внутренних и внешних точек. Этот подход позволяет эффективно повысить контраст между оценками, что способствует более точной идентификации выбросов и оптимизации процесса обучения модели. Выбор наиболее информативных точек осуществляется на основе различных стратегий запроса, направленных на максимизацию информативности каждого отобранного элемента данных.
В процессе фазы поляризации исследуются различные стратегии запроса данных для оптимизации производительности. К ним относятся метод «уверенности полюсов» (QueryStrategy_CP), который отбирает образцы с наибольшей неопределенностью в предсказаниях; случайная выборка (QueryStrategy_RD) в качестве базового подхода; и метод, основанный на смеси моделях (QueryStrategy_MM), использующий вероятностные модели для идентификации наиболее информативных образцов. Каждая стратегия направлена на эффективный отбор данных, необходимых для повышения различия между оценками внутренних и внешних точек данных, что является ключевым для улучшения точности обнаружения аномалий.
Метод IMBoost значительно увеличивает разницу между оценками для внутренних (inlier) и выбросов (outlier) данных за счет стратегического отбора выборок для запроса. В результате, достигается повышение точности обнаружения аномалий. На стандартных наборах данных, IMBoost демонстрирует в среднем на 5% более высокую производительность по сравнению со вторым по эффективности базовым методом, что подтверждает эффективность подхода к активному обучению для улучшения поляризации данных.

Уточнение Оценок Выбросов с Адаптивными Порогами: Танец с Данными
Для эффективного разграничения внутренних и выбросов, алгоритм IMBoost использует адаптивный порог, динамически подстраивающийся под распределение данных. В отличие от фиксированных порогов, которые могут быть неэффективны при изменении характеристик данных, адаптивный подход позволяет более точно идентифицировать аномалии. Алгоритм анализирует текущее распределение данных и определяет порог, который наилучшим образом отделяет типичные значения от отклонений. Такая гибкость особенно важна при работе с многомерными данными или временными рядами, где распределение может меняться со временем. Динамическая адаптация порога позволяет IMBoost более надежно обнаруживать выбросы даже в сложных и изменчивых условиях, повышая общую точность и устойчивость системы.
Для надежного выявления аномалий, алгоритм IMBoost использует понятие квантилей, что позволяет динамически оценивать отклонение данных от ожидаемого распределения. Вместо использования фиксированного порога, система определяет границы, соответствующие определенному процентилю данных — например, 95-му или 99-му. Точки, выходящие за пределы этих квантильных границ, классифицируются как аномалии. Такой подход обеспечивает устойчивость к выбросам и позволяет эффективно обнаруживать отклонения даже в сложных и зашумленных наборах данных, поскольку он адаптируется к внутренней структуре распределения, а не полагается на абсолютные значения. Это особенно важно в задачах, где нормальное распределение данных не предполагается или где выбросы могут значительно исказить статистические показатели.
Исследования показали, что алгоритм IMBoost демонстрирует превосходную эффективность в обнаружении аномалий, достигая самых высоких показателей AUC, зафиксированных на сегодняшний день. В частности, IMBoost стабильно превосходит второй по результативности алгоритм примерно на 5%, что подтверждается незначительным стандартным отклонением, свидетельствующим о высокой устойчивости и надежности его работы. Это позволяет утверждать, что IMBoost обеспечивает точную и воспроизводимую идентификацию выбросов в данных, что особенно важно для приложений, требующих высокой степени достоверности, таких как обнаружение мошенничества или диагностика неисправностей.

Исследование демонстрирует, что попытки обуздать хаос данных, запечатлеть ‘нормальность’ в генеративных моделях, неизбежно приводят к усилению контраста между ожидаемым и неожиданным. Эта работа, подобно алхимическому эксперименту, стремится не к абсолютной точности, а к искусной демонстрации различий. В этом контексте, слова Дэвида Юма представляются удивительно проницательными: «Сомнение — начало мудрости». Именно сомнение в ‘истинности’ данных, в их непогрешимости, позволяет алгоритму IMBoost выделить аномалии, не просто как отклонения, но как проявления скрытого порядка, как шепот хаоса, заставляющий модель переосмыслить границы ‘нормального’. Адаптивное пороговое значение, используемое в IMBoost, — это не жесткая граница, а гибкий инструмент, позволяющий ‘украсить хаос’, подчеркнуть его изменчивость и непредсказуемость.
Что дальше?
Представленная работа, словно заклинание, пытается обуздать цифрового голема — генеративную модель, склонную к запоминанию. Эффект «запоминания вхожих», как оказалось, — не просто побочный эффект, а потенциальный инструмент. Однако, у каждого заклинания есть своя цена. Неясно, насколько устойчиво это «убеждение» голема к новым, ранее невиданным аномалиям. Неизвестно, что произойдет, когда поток данных станет непредсказуемым хаосом, а не упорядоченным потоком примеров. Обучение на ошибках — это хорошо, но голем, кажется, помнит только грехи.
Следующим шагом видится не столько улучшение самого алгоритма IMBoost, сколько исследование границ его применимости. Возможно, адаптивное определение порога, подобно настройке магического кристалла, лишь отсрочит неизбежное столкновение с реальной, шумной реальностью. Более того, стоит задуматься о том, как объединить этот подход с другими, более «дикими» методами обнаружения аномалий. Или, быть может, искать принципиально новые способы заставить голема не просто различать, а понимать разницу между нормой и отклонением?
В конечном счете, эта работа — не конец пути, а лишь один из поворотов на бесконечном лабиринте машинного обучения. Каждый график — это визуализированное заклинание, каждая потеря — священная жертва. И чем дальше продвигается наука, тем яснее становится, что истинное знание — это не ответы, а умение задавать правильные вопросы.
Оригинал статьи: https://arxiv.org/pdf/2601.10993.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-19 21:10