Автор: Денис Аветисян
Новое исследование показывает, как анализ тематики и тональности текстов, связанных с хедж-фондами, позволяет выявить закономерности, предсказывающие их будущую эффективность.
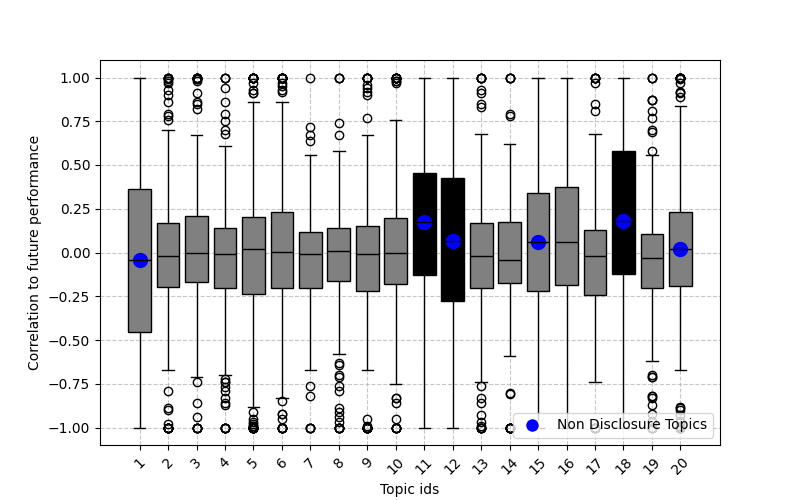
Применение методов тематического моделирования (LDA, Top2Vec, BERTopic) для анализа документов хедж-фондов и выявления корреляции между настроениями в текстах и финансовыми результатами.
Непрозрачность индустрии хедж-фондов и ограниченность раскрываемой информации создают значительные трудности для инвесторов. В своей работе ‘Unveiling Hedge Funds: Topic Modeling and Sentiment Correlation with Fund Performance’ авторы предлагают инновационный подход к анализу неструктурированных данных хедж-фондов, используя методы тематического моделирования и анализа тональности. Исследование выявило, что комбинация тематического моделирования с использованием LDA и анализа тональности, основанного на DistilBERT, позволяет установить корреляцию между содержанием документов и будущей доходностью фондов. Возможно ли, таким образом, создать новые, основанные на данных, инструменты поддержки принятия инвестиционных решений в сфере хедж-фондов?
Ясность в хаосе: Об анализе текстовых данных хедж-фондов
Документация хедж-фондов представляет собой ценный, но неструктурированный источник информации для инвестиционного анализа. Объем этих данных, включающий отчеты, аналитические записки и переписку, огромен и постоянно растет. Традиционный подход к анализу, предполагающий ручное прочтение и интерпретацию каждого документа, становится невозможным из-за масштаба задачи и ограниченности времени. Необходимость обработки огромных массивов текстовой информации требует автоматизированных решений, способных эффективно извлекать ключевые сведения и выявлять скрытые тенденции, что делает ручной анализ непрактичным и неэффективным для принятия своевременных инвестиционных решений.
Анализ больших объемов текстовой информации, содержащихся в документах хедж-фондов, представляет собой сложную задачу для традиционных методов обработки данных. Ручной просмотр и кодирование этих текстов крайне неэффективны и не масштабируемы, а существующие алгоритмы часто не способны выявить скрытые взаимосвязи и ключевые темы, что затрудняет своевременное принятие обоснованных инвестиционных решений. Традиционные подходы, такие как частотный анализ ключевых слов или построение семантических сетей, оказываются недостаточно точными и требуют значительных трудозатрат для интерпретации результатов, что препятствует оперативному выявлению тенденций и потенциальных рисков на финансовых рынках. В результате, возможности для проактивного управления портфелем и повышения доходности оказываются упущенными из-за неспособности эффективно извлекать ценную информацию из неструктурированных данных.
Автоматическое тематическое моделирование представляет собой масштабируемое решение для анализа обширных массивов неструктурированных данных, таких как документы хедж-фондов. Исследование выявило статистически значимую корреляцию между тональностью, выраженной в рамках определенных тематических кластеров, и последующей эффективностью инвестиций. Это позволяет рассматривать анализ тональности внутри тематических групп как новый количественный индикатор, способный повысить точность оценки инвестиционной привлекательности и эффективности работы фондов, значительно превосходя традиционные методы ручного анализа и обеспечивая более оперативное принятие обоснованных инвестиционных решений.

Методы тематического моделирования: от простого к сложному
Существует несколько методов тематического моделирования, каждый из которых обладает уникальными преимуществами в выявлении тонких тематических особенностей текста. Latent Dirichlet Allocation (LDA) использует вероятностную модель для определения тем на основе распределения слов в документах. Top2Vec, в отличие от LDA, основывается на векторных представлениях слов (word embeddings) и кластеризации для выявления тем, что позволяет лучше учитывать семантические связи. BERTopic, также использующий word embeddings, применяет технику уменьшения размерности UMAP и кластеризацию HDBSCAN для создания четких и интерпретируемых тематических кластеров. Выбор конкретного метода зависит от характеристик данных и целей анализа.
Методы BERTopic и Top2Vec используют векторные представления слов (word embeddings), такие как Word2Vec, GloVe или FastText, для построения более связных и семантически осмысленных представлений тем. В отличие от традиционных методов, таких как Latent Dirichlet Allocation (LDA), которые оперируют с частотой встречаемости слов, эти методы учитывают семантические отношения между словами. Это позволяет более точно выявлять скрытые темы и группировать документы, даже если они используют разные слова для выражения одного и того же понятия. Использование векторных представлений значительно улучшает интерпретируемость результатов тематического моделирования и позволяет получать более релевантные и понятные темы.
Современные методы тематического моделирования, такие как LDA, Top2Vec и BERTopic, развивают базовые принципы анализа текстовых данных, предлагая более сложные подходы к выявлению тематик. В частности, результаты тестирования показали, что LDA 20 достигла наивысших показателей когерентности тем, что указывает на лучшую интерпретируемость полученных тематических моделей по сравнению с Top2Vec. Показатель когерентности оценивает семантическую согласованность слов внутри каждой темы, и более высокие значения свидетельствуют о более четко определенных и осмысленных тематических кластерах.

Подготовка данных: основа качественного анализа
Эффективное тематическое моделирование начинается с тщательной подготовки данных, первым этапом которой является оптическое распознавание символов (OCR) для извлечения текста из PDF-документов. Процесс OCR преобразует изображения текста в машиночитаемый формат, необходимый для дальнейшего анализа. Качество распознавания напрямую влияет на точность последующего тематического моделирования, поэтому выбор подходящего программного обеспечения OCR и его правильная настройка для конкретного типа документов критически важны. Некорректно распознанные символы или слова могут привести к ошибкам в анализе и искажению результатов. Перед применением OCR рекомендуется предварительная обработка изображений для улучшения их качества, например, коррекция наклона и контрастности.
Очистка документов является критически важным этапом подготовки данных, включающим удаление нерелевантного контента, такого как колонтитулы, нижние колонтитулы, таблицы и графические элементы, которые не содержат текстовую информацию, значимую для тематического моделирования. Нормализация текста предполагает приведение к единому регистру, удаление знаков препинания, стоп-слов и приведение слов к их начальной форме (лемматизация или стемминг). Эти процедуры необходимы для повышения точности анализа, поскольку они уменьшают шум и позволяют алгоритмам тематического моделирования более эффективно выявлять закономерности и темы в текстовых данных. Недостаточная очистка может привести к появлению ложных или нерепрезентативных тем, искажая результаты анализа.
Качество тем, выделяемых при тематическом моделировании, напрямую зависит от степени предварительной обработки данных. Недостаточная очистка текста от нерелевантной информации, ошибок OCR или несогласованностей в форматировании приводит к искажению статистических данных и, как следствие, к формированию нерепрезентативных или бессмысленных тем. Тщательная предварительная обработка, включающая удаление стоп-слов, приведение к нижнему регистру, лемматизацию и удаление пунктуации, обеспечивает более точное представление текстовых данных и, следовательно, более качественные и интерпретируемые результаты тематического моделирования. Отсутствие или недостаточное применение методов предварительной обработки снижает достоверность и практическую ценность полученных тем.
Взаимосвязь тематик и инвестиционных результатов
Анализ тональности, осуществляемый с помощью передовых моделей, таких как DistilBERT и FinBERT, позволяет оценить эмоциональную окраску текстов, содержащихся в документах хедж-фондов. Эти модели, обученные на больших объемах финансовых данных, способны выявлять даже скрытые оттенки настроений — от оптимизма и уверенности до тревоги и пессимизма. Процесс заключается в автоматическом определении субъективности и полярности высказываний, что дает возможность количественно оценить общее настроение, преобладающее в конкретном документе или отчете. Полученные данные, таким образом, предоставляют ценную информацию о восприятии рыночной ситуации управляющими активами и могут служить индикатором их будущих инвестиционных решений.
Анализ корреляции между эмоциональной окраской текстов и результатами инвестиционной деятельности позволил выявить потенциальные связи между тематикой документов и финансовыми показателями. Исследование показало, что наиболее выраженные взаимосвязи наблюдаются в разделах «Обзор рынка» и «Комментарии к результатам», где статистическая значимость полученных данных подтверждена p-значениями, не превышающими 0.05. Данный результат указывает на то, что тональность, используемая в этих конкретных документах, может служить индикатором будущих инвестиционных результатов, предоставляя ценную информацию для инвесторов и аналитиков при принятии обоснованных решений.
Полученные результаты представляют значимую ценность для инвесторов и аналитиков, открывая возможности для более обоснованных инвестиционных решений. Анализ тональности текстов, в частности, позволяет выявить скрытые взаимосвязи между тематикой отчетов хедж-фондов и их фактической доходностью. Это, в свою очередь, дает возможность оценивать не только количественные показатели, но и качественные аспекты, отражающие уверенность управляющих и их видение рыночной ситуации. Подобный подход способствует более глубокому пониманию факторов, влияющих на инвестиционные результаты, и позволяет выстраивать стратегии, учитывающие как статистические данные, так и эмоциональный контекст, что, в конечном итоге, может привести к повышению эффективности инвестиционного процесса.
Исследование, представленное в статье, демонстрирует, как извлечение ключевых тем из текстовых данных может предоставить ценную информацию о будущей эффективности инвестиционных фондов. Применение методов тематического моделирования, в частности LDA, позволяет выявить скрытые закономерности и взаимосвязи, которые остаются незамеченными при традиционном анализе. Мари Кюри однажды заметила: «Не следует бояться ошибок, следует бояться отсутствия попыток». Это высказывание находит отклик в данном исследовании, поскольку авторы не боятся экспериментировать с различными алгоритмами и подходами, стремясь к более глубокому пониманию сложной динамики финансовых рынков. Успешное применение LDA, как надежного метода интерпретации тем, подтверждает важность простоты и ясности в анализе данных.
Куда же дальше?
Представленная работа, подобно тщательному разбору механизма, выявила корреляции, но не упразднила сложности. Автоматическое извлечение смыслов из неструктурированных текстов, пусть и продемонстрированное на материалах хедж-фондов, остаётся искусством приближения к истине, а не её полным постижением. Подобно алхимику, отделившему золото от свинца, исследователи выделили темы и настроения, однако вопрос о причинно-следственных связях, о первичности темы или настроения, остается открытым.
Будущие исследования, вероятно, столкнутся с необходимостью преодоления ограниченности данных. Существующие корпуса текстов, как правило, отражают лишь часть картины, и их расширение, включение альтернативных источников, может внести существенные коррективы в полученные результаты. Кроме того, стоит обратить внимание на динамику тем и настроений во времени, на их эволюцию и взаимовлияние, что потребует разработки более сложных моделей и алгоритмов.
И, наконец, не стоит забывать о скромном месте подобного анализа в общей картине инвестиционных решений. Выявление корреляций — это лишь первый шаг, и превращение их в практическую пользу потребует интеграции с другими факторами, с глубоким пониманием рынка и, возможно, с долей интуиции. Помните: убрать одно — и смысл станет виден.
Оригинал статьи: https://arxiv.org/pdf/2512.06620.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2025-12-09 15:09