Автор: Денис Аветисян
Новый подход позволяет обнаруживать аномалии и определять их источники в промышленных системах без обмена данными и модификации существующих моделей.
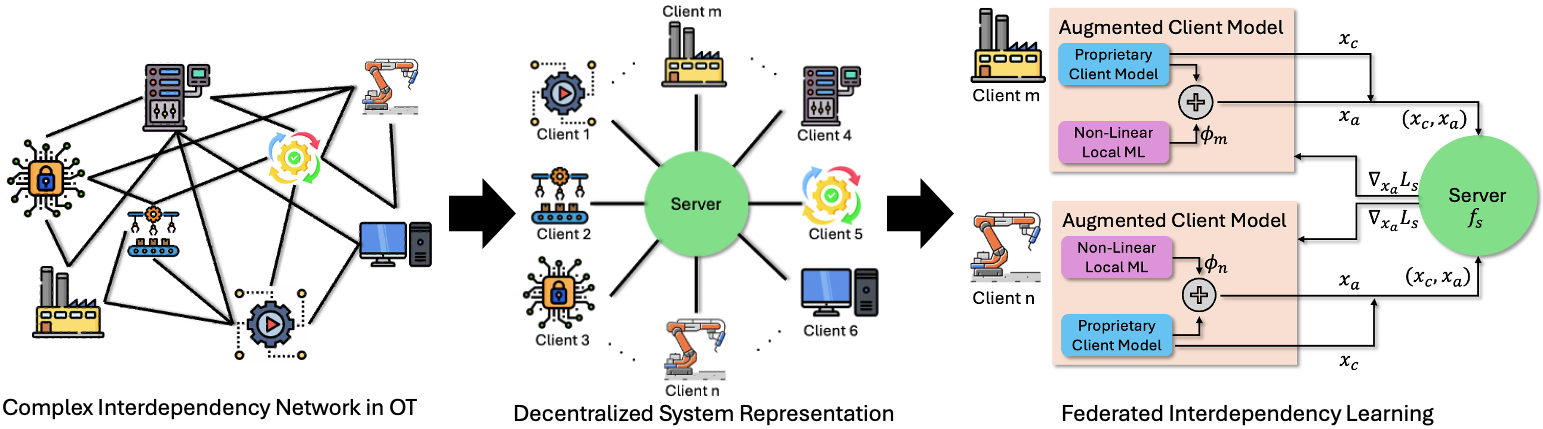
Предложена платформа федеративного обучения для децентрализованного анализа первопричин в нелинейных динамических системах с применением дифференциальной конфиденциальности.
Анализ первопричин сбоев в сложных сетевых промышленных системах затруднен из-за скрытых и динамически меняющихся взаимосвязей между географически распределенными узлами. В работе ‘Learning Unknown Interdependencies for Decentralized Root Cause Analysis in Nonlinear Dynamical Systems’ предложен децентрализованный подход, использующий федеративное обучение для выявления этих взаимосвязей без прямого доступа к данным клиентов или модификации их проприетарных моделей. Предлагаемый метод позволяет эффективно анализировать нелинейные временные ряды, формируя согласованные представления данных при сохранении конфиденциальности с помощью калиброванного дифференциального шума. Не откроет ли это новые возможности для повышения надежности и безопасности критически важных инфраструктур?
Вызов распределенного интеллекта
Традиционные методы машинного обучения часто требуют консолидации данных в едином централизованном хранилище. Этот подход, несмотря на свою эффективность в некоторых сценариях, несет в себе значительные риски для конфиденциальности информации. Собирая данные в одном месте, создается привлекательная цель для злоумышленников, а также возникает необходимость в строгом контроле доступа и соблюдении нормативных требований. Кроме того, передача больших объемов данных к центральному серверу создает узкие места в сети и увеличивает задержки, особенно в случаях, когда источники данных географически распределены или имеют ограниченную пропускную способность. В результате, применение классического машинного обучения становится проблематичным в таких областях, как здравоохранение, финансы и интернет вещей, где конфиденциальность и скорость обработки данных имеют первостепенное значение.
Ограничения традиционного машинного обучения особенно заметны в ситуациях, где данные являются конфиденциальными или распределены по географически удаленным источникам. Представьте, например, медицинские учреждения, каждое из которых хранит данные пациентов, или сеть датчиков, разбросанных по огромной территории. Передача таких данных в централизованное хранилище для обучения моделей не только сопряжена с риском нарушения конфиденциальности, но и создает серьезные проблемы с пропускной способностью сети и задержками. Эти факторы существенно снижают эффективность и практическую применимость традиционных подходов, подчеркивая необходимость разработки альтернативных методов, способных эффективно обрабатывать данные непосредственно в местах их генерации, без необходимости их централизации.
Традиционный подход к машинному обучению, предполагающий централизованный сбор данных, всё чаще сталкивается с ограничениями, особенно в контексте растущих проблем конфиденциальности и увеличения объемов информации. Вместо того, чтобы перемещать данные к алгоритмам, возникает необходимость в принципиально иной парадигме — переносе процесса обучения непосредственно к источникам данных. Такой подход позволяет избежать рисков, связанных с передачей чувствительной информации, и значительно снижает задержки, возникающие при обработке больших массивов данных, распределенных географически. Это смещение фокуса открывает новые возможности для обучения на децентрализованных данных, обеспечивая более эффективное и безопасное использование информации в различных областях, от здравоохранения до интернета вещей.
Децентрализованное обучение представляет собой инновационный подход к машинному обучению, позволяющий проводить тренировку моделей непосредственно на устройствах, где генерируются данные. Вместо отправки информации в централизованное хранилище, алгоритмы обучения распределяются и выполняются локально, на смартфонах, датчиках или других периферийных устройствах. Такой подход существенно повышает конфиденциальность данных, снижает задержки, связанные с передачей больших объемов информации, и позволяет эффективно использовать ресурсы, находящиеся непосредственно у источника данных. Это особенно важно в областях, где конфиденциальность является приоритетом, таких как здравоохранение или финансы, а также в сценариях с ограниченной пропускной способностью сети, например, в удаленных регионах или при использовании интернета вещей. В результате, децентрализованное обучение открывает новые возможности для создания интеллектуальных систем, способных адаптироваться и обучаться в реальном времени, не ставя под угрозу приватность и эффективность.
Федеративное обучение и кодирование взаимозависимостей
Федеративное обучение (FL) является расширением концепции децентрализованного обучения, предоставляя структурированный подход к совместной тренировке моделей машинного обучения на распределенных данных. В отличие от традиционных централизованных методов, где все данные собираются в одном месте, FL позволяет обучать модель непосредственно на устройствах или серверах, где находятся данные, без необходимости их передачи. Этот процесс включает в себя итеративный обмен обновлениями модели (например, градиентами) между участниками, координируемый центральным сервером, который агрегирует эти обновления для создания глобальной модели. Ключевым преимуществом FL является обеспечение конфиденциальности данных и снижение требований к пропускной способности сети, поскольку необработанные данные остаются локально на устройствах участников.
Вертикальное федеративное обучение (VFL) представляет собой усовершенствованный подход к федеративному обучению, предназначенный для ситуаций, когда различные участники владеют разными признаками одних и тех же образцов данных. В отличие от традиционного федеративного обучения, где каждый участник имеет полный набор признаков, VFL позволяет объединить эти разрозненные наборы признаков для обучения единой модели. Это достигается путем совместного вычисления градиентов и обмена информацией о моделях между участниками, при этом сами данные остаются локальными и не передаются. VFL особенно актуально в сценариях, где конфиденциальность данных является приоритетом, и когда полные данные доступны только при объединении информации от нескольких сторон, например, в банковской сфере или здравоохранении.
Эффективное федеративное обучение (FL) требует учета и использования межклиентских взаимозависимостей, присущих распределенным данным. Распределенные наборы данных часто содержат общие сущности или переменные, коррелирующие между различными клиентами, что создает зависимости, которые могут значительно повлиять на производительность модели. Игнорирование этих взаимозависимостей может привести к неоптимальным глобальным моделям и снижению точности. Учет этих взаимозависимостей позволяет алгоритмам FL более эффективно обобщать данные и улучшать сходимость, поскольку модели могут учиться на общих закономерностях и корреляциях, присутствующих в данных, распределенных между клиентами. Методы, направленные на моделирование и использование этих взаимозависимостей, являются ключевыми для достижения высокой производительности в сценариях федеративного обучения.
Нелинейные локальные модели машинного обучения играют ключевую роль в кодировании взаимосвязей между данными, распределенными по разным клиентам. В отличие от линейных моделей, нелинейные модели способны улавливать сложные зависимости и взаимодействия между признаками, что позволяет создавать более информативные и выразительные локальные представления данных. Эти представления, полученные на каждом клиенте, содержат информацию не только о локальных данных, но и о скрытых взаимосвязях с данными других клиентов. Использование таких моделей позволяет существенно повысить эффективность федеративного обучения, особенно в задачах, где эти взаимосвязи имеют важное значение для общей точности модели. Примерами таких моделей являются нейронные сети и градиентный бустинг, способные моделировать сложные нелинейные функции и выявлять скрытые закономерности в данных.
Глобальная агрегация и оценка состояния
Глобальная серверная модель функционирует как центральный агрегатор, собирая и обобщая информацию, полученную из локальных моделей. Этот процесс включает в себя получение обновлений состояния, параметров и прогнозов от каждого клиента, последующую обработку этих данных с использованием заранее определенных алгоритмов, и формирование единой, согласованной картины состояния всей системы. Агрегация не ограничивается простым усреднением; она может включать в себя взвешивание вкладов от разных клиентов в зависимости от их надежности, релевантности или других факторов, определяемых логикой системы. Полученная агрегированная информация затем используется для улучшения глобальной модели, корректировки прогнозов и принятия решений, влияющих на работу всей системы и отдельных клиентов.
Эффективность глобального сервера напрямую зависит от корректно определенной функции потерь (Loss Function), которая точно отражает глобальную целевую функцию системы. Несоответствие между функцией потерь и реальными целями оптимизации приводит к неоптимальным решениям и снижению общей производительности. Функция потерь должна учитывать все значимые факторы, влияющие на глобальную задачу, и обеспечивать адекватную оценку отклонения прогнозов модели от желаемых результатов. Ключевым аспектом является выбор подходящей метрики для измерения этого отклонения, учитывающей специфику решаемой задачи и характеристики данных. L = \sum_{i=1}^{n} l(y_i, \hat{y}_i), где l — функция потерь для отдельной точки данных, а y_i и \hat{y}_i — фактическое и прогнозируемое значения соответственно.
Оценка состояния играет ключевую роль в отслеживании и прогнозировании поведения системы, особенно в динамически меняющихся условиях. Эта задача заключается в определении текущего состояния системы на основе доступных измерений и модели ее динамики. В динамических средах, где условия постоянно меняются, точная и своевременная оценка состояния необходима для принятия эффективных решений и поддержания оптимальной производительности. Неточности в оценке состояния могут привести к ошибкам в управлении системой и снижению ее эффективности. Методы оценки состояния, такие как фильтр Калмана и его расширенные версии, позволяют учитывать шум в измерениях и неопределенности в модели системы, обеспечивая надежные оценки даже в сложных условиях. Точность оценки состояния напрямую влияет на качество прогнозирования будущего поведения системы и, следовательно, на эффективность планирования и управления.
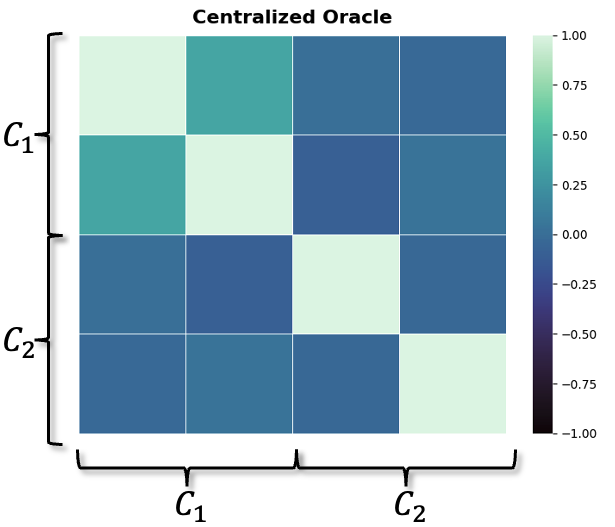
Расширенный фильтр Калмана (EKF) является надежным методом нелинейной оценки состояния, используемым в качестве основы для проприетарных клиентских моделей. EKF позволяет эффективно оценивать состояние динамических систем, даже при наличии нелинейностей в модели и измерениях. Внутренняя реализация EKF предполагает линеаризацию нелинейных функций с использованием якобианов, что позволяет применять стандартные алгоритмы фильтра Калмана. Достигнутая производительность клиентских моделей, основанных на EKF, сопоставима с производительностью централизованного оракула, что подтверждается результатами тестирования и анализа данных. Применение EKF обеспечивает высокую точность и устойчивость оценки состояния в реальных условиях эксплуатации.

Конфиденциальность и обнаружение аномалий в распределенных системах
Для обеспечения конфиденциальности данных клиентов в распределенных системах применяется дифференциальная приватность, достигаемая за счет добавления гауссовского шума при агрегации моделей. Данный подход позволяет защитить чувствительную информацию, сохраняя при этом возможность обучения модели на децентрализованных данных. Добавление контролируемого шума N(0, \sigma^2) маскирует вклад отдельных клиентов, затрудняя идентификацию их данных, при этом не оказывая существенного влияния на общую точность модели. Эффективность этого метода заключается в создании баланса между защитой приватности и полезностью данных, что особенно важно в сценариях, где необходимо обучать модели на конфиденциальной информации, например, в здравоохранении или финансах.
В распределенных системах выявление аномалий играет ключевую роль в обеспечении безопасности и стабильности работы. Необычное поведение, будь то следствие вредоносной активности или непредвиденных сбоев, может быстро привести к серьезным последствиям, включая потерю данных и нарушение сервисов. Автоматизированное обнаружение таких отклонений от нормы позволяет оперативно реагировать на угрозы и предотвращать их развитие. Разработка эффективных методов выявления аномалий, способных адаптироваться к динамичной природе распределенных сред и обрабатывать большие объемы данных, является важной задачей современной информационной безопасности. В контексте сложных систем, характеризующихся множеством взаимодействующих компонентов, своевременное обнаружение и локализация аномалий становится критически важным для поддержания надежности и целостности всей инфраструктуры.
Анализ остатков и расстояние Махаланобиса представляют собой эффективные инструменты для выявления отклонений от нормального поведения в распределенных системах. Анализ остатков позволяет оценить разницу между предсказанными и фактическими значениями, выявляя выбросы и аномалии, которые могут указывать на сбои или злонамеренную активность. В свою очередь, расстояние Махаланобиса учитывает корреляции между переменными, предоставляя более точную оценку отклонения точки данных от центра распределения, чем простое евклидово расстояние. Комбинированное использование этих методов позволяет не только обнаружить аномалии, но и определить их статистическую значимость и потенциальное влияние на систему, что критически важно для обеспечения ее надежности и безопасности. d(x) = \sqrt{(x - \mu)^T \Sigma^{-1} (x - \mu)} — формула расстояния Махаланобиса, где x — точка данных, μ — вектор средних значений, а Σ — ковариационная матрица.
Разработанная система была тщательно протестирована на наборе данных HAIL, представляющем собой реальные данные из области промышленной кибербезопасности. Результаты демонстрируют высокую точность выявления аномалий в сложных сетевых сценариях. Важно отметить, что система сохраняет стабильность обучения даже при добавлении значительного уровня шума — до 10^1 и 10^5 — что подтверждает её устойчивость к неблагоприятным условиям. Кроме того, система успешно масштабируется до шестнадцати клиентов, что позволяет применять её в крупных распределенных системах без потери производительности и точности выявления угроз.
Разработанная система демонстрирует высокую точность в определении первопричин аномалий, что позволяет оперативно выявлять и устранять потенциальные угрозы в распределенных системах. Результаты исследований показывают, что эффективность анализа причинно-следственных связей сопоставима с результатами, полученными при использовании централизованного оракула — эталонного метода, требующего сбора и обработки данных в единой точке. Такое соответствие достигается без ущерба для конфиденциальности данных, что особенно важно. Высокая производительность и точность, в сочетании с децентрализованным подходом, делают данную систему перспективным решением для обеспечения безопасности и надежности в сложных распределенных средах, где централизованный контроль не всегда возможен или желателен.

Исследование демонстрирует стремление к упрощению сложных систем, что соответствует принципам структурной честности. Авторы предлагают децентрализованный подход к анализу первопричин аномалий, избегая необходимости централизованного сбора данных. Этот подход особенно важен для промышленных систем, где конфиденциальность данных и автономность узлов критичны. В рамках предложенной схемы федеративного обучения, выявление взаимосвязей между компонентами системы становится возможным без прямого доступа к проприетарным моделям. Как однажды заметил Винтон Серф: «Интернет — это сеть сетей». Эта фраза отражает суть представленного исследования — построение сети знаний о взаимосвязях внутри сложной системы, без нарушения границ и сохранения конфиденциальности данных.
Куда Далее?
Представленная работа, при всей своей элегантности, лишь обнажает глубину нерешенных вопросов. Поиск первопричин в сложных системах, даже при использовании федеративного обучения, неизбежно сталкивается с проблемой неполноты данных. Каждый участник сети владеет лишь фрагментом истины, и объединение этих фрагментов не гарантирует целостную картину. Неизбежна борьба с ложными корреляциями, с призраками, порожденными недостатком информации. Система, требующая все больше и больше данных для повышения точности, уже признала свое поражение.
Будущие исследования должны сосредоточиться не на увеличении объема данных, а на разработке более эффективных методов их фильтрации и интерпретации. Следует обратить внимание на методы активного обучения, позволяющие системе самостоятельно запрашивать недостающую информацию, но при этом избегать излишней навязчивости. Понятность — это вежливость; алгоритм, требующий от оператора расшифровки его собственных действий, обречен на провал.
В конечном итоге, успех в этой области зависит не от сложности алгоритмов, а от их способности к самоочищению. Идеальное решение — это не то, которое включает в себя все возможные факторы, а то, которое безжалостно отбрасывает все лишнее. Сложность — это тщеславие; ясность — милосердие. И только тогда, когда нечего убрать, можно говорить о приближении к совершенству.
Оригинал статьи: https://arxiv.org/pdf/2602.21928.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-26 14:40