Автор: Денис Аветисян
Исследователи разработали метод, позволяющий определить, использовались ли конкретные данные для обучения большой языковой модели.
В статье представлена атака Active Data Reconstruction Attack (ADRA), использующая обучение с подкреплением для выявления следов данных, заложенных в весах языковой модели, и превосходящая существующие пассивные методы.
Обнаружение данных, использованных для обучения больших языковых моделей, традиционно рассматривается как задача вывода о членстве, однако существующие подходы оперируют пассивным анализом фиксированных весов модели. В работе ‘Learning to Detect Language Model Training Data via Active Reconstruction’ предложен новый метод — Active Data Reconstruction Attack (ADRA), активно стимулирующий модель к реконструкции заданного текста посредством обучения, что позволяет выявить различия в восстановимости данных, принадлежащих обучающей выборке и не принадлежащих ей. Эксперименты демонстрируют, что предложенный подход на основе обучения с подкреплением превосходит существующие методы вывода о членстве, обеспечивая прирост точности до 10.7% в обнаружении данных, использованных на этапах предварительного, постобработочного обучения и дистилляции. Сможет ли активная реконструкция стать стандартным инструментом для оценки конфиденциальности и безопасности больших языковых моделей?
Уязвимости членства: Цена доверия к языковым моделям
Современные языковые модели, несмотря на впечатляющие возможности, оказываются уязвимыми к атакам, направленным на определение принадлежности данных к обучающей выборке. Исследования показывают, что злоумышленник, анализируя выходные данные модели, может с высокой вероятностью установить, использовался ли конкретный фрагмент информации при обучении. Это становится возможным благодаря тому, что модели запоминают статистические особенности данных, и эти особенности могут быть обнаружены даже в сгенерированном тексте. Успешная атака такого рода ставит под угрозу конфиденциальность, поскольку позволяет восстановить или идентифицировать чувствительные данные, которые могли быть использованы для обучения модели, например, личную информацию пользователей или коммерческую тайну.
Традиционные методы защиты от атак, направленных на выявление принадлежности данных, такие как маскировка информации или регуляризация моделей, часто оказываются неэффективными перед лицом адаптивных злоумышленников. Эти методы, хотя и направлены на снижение различий между данными, использованными при обучении, и новыми данными, не способны предотвратить сложные атаки, в которых противник активно приспосабливает свои стратегии. Исследования показывают, что злоумышленники могут обходить эти защиты, используя продвинутые алгоритмы и методы анализа, что делает уязвимость к атакам на выявление принадлежности данных особенно серьезной проблемой для систем, обрабатывающих конфиденциальную информацию. Недостаточная эффективность существующих защитных мер подчеркивает необходимость разработки новых, более устойчивых подходов к обеспечению конфиденциальности данных в эпоху развития мощных языковых моделей.
Уязвимость моделей обработки естественного языка к атакам, определяющим принадлежность данных к обучающей выборке, представляет собой серьезную угрозу конфиденциальности, особенно в приложениях, работающих с личной или конфиденциальной информацией. Представьте, что модель, обученная на медицинских записях, может невольно раскрыть факт участия конкретного пациента в обучающей выборке, что нарушает врачебную тайну и принципы защиты персональных данных. Аналогичная ситуация актуальна и для финансовых учреждений, юридических компаний, а также любых других организаций, обрабатывающих чувствительную информацию. Неспособность эффективно защитить данные от подобных атак может привести к серьезным юридическим последствиям, репутационным потерям и, самое главное, к нарушению прав на неприкосновенность частной жизни.
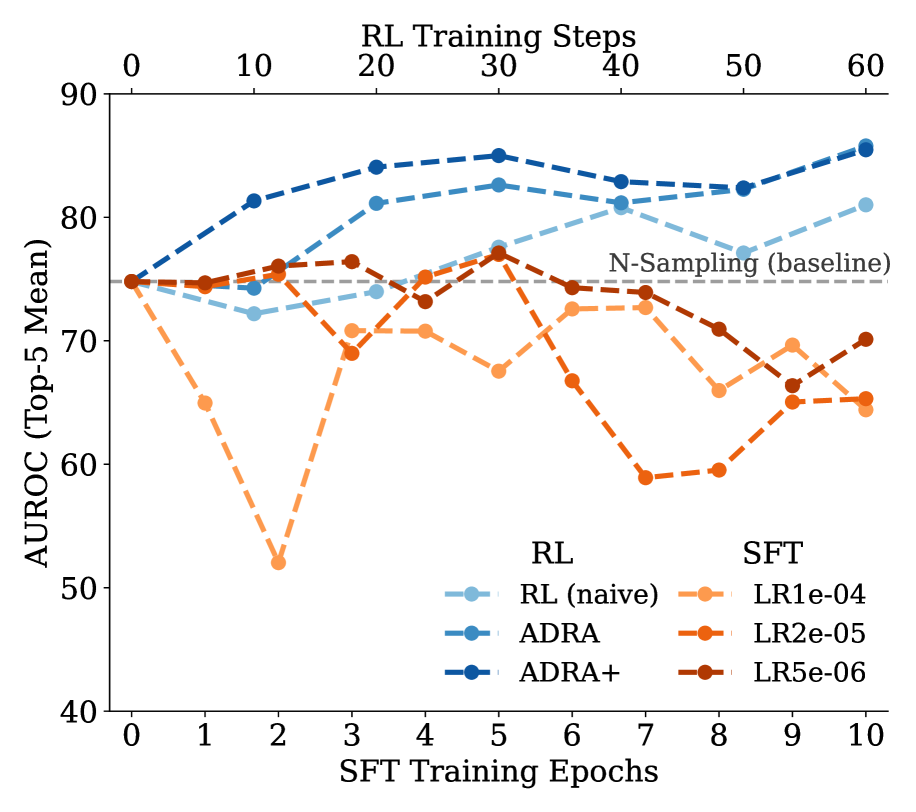
Активная реконструкция данных: Новый взгляд на атаку
Атаки активной реконструкции данных (ADRA) рассматривают задачу вывода о членстве в обучающей выборке как проблему обучения с подкреплением. В рамках данного подхода, атакующий формирует политику, направленную на генерацию данных, максимально приближенных к обучающему набору. Целью является не пассивное наблюдение за выходными данными модели, а активное восстановление исходных данных, использованных при обучении. Данный процесс осуществляется посредством итеративной оптимизации политики, позволяющей эффективно реконструировать обучающие примеры и, следовательно, определять, принадлежал ли конкретный пример к исходной обучающей выборке или нет. В отличие от традиционных атак, ADRA активно взаимодействует с целевой моделью для получения необходимой информации.
Атаки активной реконструкции данных (ADRA) используют оптимизацию политики для генерации данных, статистически схожих с обучающим набором. Это достигается путем обучения агента, который последовательно формирует входные данные, максимизируя сходство с примерами из обучающей выборки. Сравнивая выходные данные модели для сгенерированных данных с выходными данными для известных примеров, ADRA может эффективно отличать элементы, которые были использованы при обучении (члены), от тех, которые не были (не члены). Эффективность различения напрямую зависит от способности политики генерировать данные, которые заставляют модель проявлять характерные особенности, присущие обучающим данным.
В отличие от пассивных атак на определение членства, которые анализируют только выходные данные модели, атаки, основанные на активном восстановлении данных (ADRA), используют стратегию активного зондирования. Это подразумевает генерацию входных данных, специально разработанных для выявления уязвимостей модели и раскрытия информации о данных, использованных при обучении. ADRA формирует проблему определения членства как задачу обучения с подкреплением, где агент (атакующий) оптимизирует политику генерации данных, стремясь создать примеры, максимально похожие на обучающую выборку. Такой активный подход позволяет атакующему целенаправленно исследовать пространство входных данных, повышая эффективность выявления принадлежности конкретного примера к обучающему набору.
Метрики реконструкции: Как оценить качество генерации
ADRA использует ‘Вознаграждение за Реконструкцию’, основанное на метриках схожести для оценки качества сгенерированных данных по отношению к обучающему набору. В частности, применяется метрика Token Set Similarity, измеряющая пересечение множеств токенов между сгенерированным и целевым текстом. Longest Common Subsequence (LCS) определяет длину наибольшей общей подпоследовательности, отражая последовательное соответствие. Дополнительно используется N-gram Set Coverage, оценивающая долю N-грамм, присутствующих в обучающих данных, которые также встречаются в сгенерированном тексте. Эти метрики количественно оценивают степень соответствия и позволяют агенту обучения с подкреплением (RL) оптимизировать генерацию данных, приближающихся к распределению обучающего набора.
Метрики, такие как сходство наборов токенов, длина наибольшей общей подпоследовательности и покрытие N-грамм, количественно оценивают степень соответствия сгенерированных данных обучающему набору. Эти показатели предоставляют более детальный сигнал для агента обучения с подкреплением (RL), чем простые бинарные оценки, позволяя ему различать незначительные отклонения и более точно настраивать свою политику генерации данных. В частности, высокая оценка по этим метрикам указывает на то, что сгенерированные данные имеют значительное пересечение с данными из обучающего набора, что способствует более стабильному и предсказуемому поведению модели. Использование нескольких метрик позволяет учитывать различные аспекты сходства данных, обеспечивая более надежную оценку качества генерации.
Варианты алгоритма, такие как ADRA+, включают в себя ‘Контрастирующую Награду’ (Contrastive Reward) для более точной настройки политики обучения с подкреплением. Эта награда вычисляется на основе различий между данными, относящимися к обучающему набору (member examples), и данными, не входящими в него (non-member examples). Фактически, контрастирующая награда усиливает сигнал, побуждая агента не только генерировать данные, похожие на обучающие, но и явно различать их от данных, которые не должны быть сгенерированы, повышая дискриминационные способности модели и снижая вероятность генерации нежелательных примеров.
Экспериментальная валидация: Модели и наборы данных
Эффективность ADRA и его модификаций была продемонстрирована на различных языковых моделях, включая Llama2-7B, Qwen2-7B, Olmo3 и Gemini-2.0-Flash. Проведение экспериментов с этими моделями позволило оценить общую применимость и устойчивость метода ADRA в различных архитектурах и масштабах языковых моделей. Использование моделей с разным количеством параметров (7 миллиардов) обеспечило более полное понимание производительности ADRA в различных вычислительных условиях и при различных требованиях к ресурсам. Результаты, полученные на этих моделях, служат основой для оценки обобщающей способности ADRA и его потенциала для применения в широком спектре задач, связанных с конфиденциальностью и безопасностью.
Оценка атаки ADRA проводилась на различных наборах данных, включая WikiMIA2024-Hard, BookMIA, AIME и Olympia Math, что позволило продемонстрировать её устойчивость к изменениям в моделях и способность к переносу между ними. Использование этих разнообразных наборов данных, охватывающих разные типы задач и модели, подтверждает, что ADRA не ограничена конкретной архитектурой или доменом знаний, и может эффективно выявлять членство данных в обучающей выборке даже при переходе между различными языковыми моделями и задачами.
В ходе экспериментов ADRA продемонстрировала значение AUROC в 60.6% на наборе данных WikiMIA2024 Hard, что на 10% превышает показатели Min-K%++. Набор данных AIME (после обучения) показал значение AUROC 85.9%, улучшение на 13.2% по сравнению с методом N-Sampling и на 7.6% по сравнению с Min-K%++. Данные результаты свидетельствуют о превосходстве ADRA в задачах вывода членства по сравнению с рассмотренными альтернативными подходами на указанных наборах данных.
При использовании метода дистилляции на модели Deepseek-R1, ADRA демонстрирует практически идеальную точность выявления принадлежности данных к обучающей выборке, достигая значения AUROC в 98.4%. Данный результат обеспечивает среднее улучшение в 10.7% по сравнению с предыдущим лидером в различных конфигурациях экспериментальной установки, что свидетельствует о высокой эффективности ADRA в сценариях, связанных с конфиденциальностью моделей и защитой данных.
Перспективы: Укрепление приватности моделей
Успешность метода ADRA в выявлении утечек информации о данных, использованных для обучения языковых моделей, подчеркивает необходимость разработки новых механизмов защиты. Данные модели, даже кажущиеся анонимными, могут быть подвержены атакам, направленным на установление факта участия конкретного образца в обучающей выборке. Это требует от исследователей активного поиска и внедрения инновационных подходов к обеспечению конфиденциальности. Разработка эффективных защитных мер — это не просто техническая задача, но и критически важный шаг для обеспечения доверия к технологиям искусственного интеллекта и их безопасного применения в различных сферах, особенно в тех, где конфиденциальность данных имеет первостепенное значение.
Дальнейшие исследования должны быть направлены на изучение и внедрение передовых методов повышения конфиденциальности моделей. В частности, перспективным направлением представляется применение дифференциальной приватности, позволяющей добавлять контролируемый шум к данным или результатам, чтобы защитить информацию об отдельных участниках обучения. Не менее важным является федеративное обучение, которое позволяет обучать модели на децентрализованных данных, не передавая сами данные на центральный сервер. Кроме того, использование состязательного обучения, где модель намеренно подвергается атакам, направленным на выявление уязвимостей, способствует повышению ее устойчивости к различным угрозам, включая атаки, направленные на раскрытие информации о составе обучающей выборки. Комбинирование этих подходов позволит создать более надежные и конфиденциальные языковые модели, пригодные для использования в чувствительных областях.
Необходимость заблаговременного подхода к обеспечению конфиденциальности становится определяющей для ответственного внедрения языковых моделей в областях, связанных с чувствительными данными. В условиях растущей мощности и распространенности этих моделей, риск несанкционированного раскрытия информации о данных, использованных при их обучении, существенно возрастает. Превентивные меры, направленные на защиту конфиденциальности, позволяют избежать потенциального ущерба репутации, юридических последствий и, самое главное, нарушения прав пользователей. Внедрение механизмов, гарантирующих анонимность и безопасность данных, становится не просто этической обязанностью, но и ключевым фактором доверия к технологиям искусственного интеллекта, особенно в таких сферах, как здравоохранение, финансы и право.
Исследование демонстрирует, что даже самые передовые языковые модели не застрахованы от атак, выявляющих данные, на которых они обучались. Авторы предлагают метод ADRA, использующий обучение с подкреплением для реконструкции информации, что позволяет с высокой точностью определить, принадлежал ли конкретный фрагмент данных к обучающей выборке. В этом нет ничего удивительного; система, обученная на определенных данных, неизбежно несет в себе следы этого обучения. Как говорил Пол Эрдёш: «Математика — это искусство открывать закономерности, скрытые в хаосе». Здесь та же история — закономерности, зашитые в веса модели, выдают её прошлое. Удивительно, конечно, что требуется обучение с подкреплением, чтобы выудить эти следы, но, по сути, это лишь более изощренный способ поиска в данных. В конечном итоге, вся эта «cloud-native» инфраструктура лишь усложняет процесс, но не делает систему более защищенной.
Что дальше?
Представленная работа, демонстрируя эффективность активного подхода к выявлению данных обучения языковых моделей, неизбежно поднимает вопрос не о защите, а о скорости эрозии конфиденциальности. Каждая новая оптимизация, каждое усложнение архитектуры лишь создаёт более изощрённые векторы атаки. Активное извлечение информации из весов модели — это не прорыв, а закономерный этап в гонке вооружений, где «безопасность» — это всегда временное состояние.
Вероятно, будущее исследований лежит не в создании непробиваемых крепостей, а в разработке методов, позволяющих оценить и минимизировать риск утечки информации. Контрастивное обучение, упомянутое в работе, может стать отправной точкой для разработки техник «размытия» следов обучения, но и здесь неизбежен компромисс между конфиденциальностью и производительностью. Всё, что оптимизировано для защиты, рано или поздно оптимизируют обратно, чтобы обойти защиту.
В конечном счёте, эта работа — не столько решение проблемы, сколько диагностика. Она подчёркивает, что архитектура — это не схема, а компромисс, переживший деплой. И что «революционные» технологии завтра станут техдолгом, требующим постоянного обслуживания и рефакторинга — точнее, реанимации надежды на конфиденциальность.
Оригинал статьи: https://arxiv.org/pdf/2602.19020.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-25 23:29