Автор: Денис Аветисян
Новая работа демонстрирует, как современные нейросети могут достичь экспертного уровня в сложной игре Го, опираясь на знания и опыт лучших игроков.

Представлена модель LoGos, объединяющая самообучение с подкреплением и тщательно подобранный набор данных, демонстрирующий человеческую стратегию игры Го.
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в решении общих задач рассуждения, их применение в специализированных областях, таких как игра Го, сталкивается со значительными трудностями. В своей работе ‘Mixing Expert Knowledge: Bring Human Thoughts Back To the Game of Go’ мы представляем LoGos — LLM, способную демонстрировать уровень игры, сопоставимый с профессиональными игроками, благодаря инновационному подходу к интеграции экспертных знаний и общих навыков рассуждения. LoGos достигает этого посредством смешанного обучения с подкреплением, используя как структурированные знания о Го, так и общепринятые цепочки рассуждений. Сможем ли мы, используя подобный подход, расширить возможности LLM и в других узкоспециализированных областях, где требуются глубокие экспертные знания?
Искусство Стратегии: Вызовы Рассуждений в Сложных Играх
Традиционные методы искусственного интеллекта, демонстрирующие впечатляющие результаты в шахматах, сталкиваются с серьезными трудностями при анализе игры Го. Причина кроется в колоссальной комбинаторной сложности Го, где количество возможных позиций значительно превосходит шахматное. В отличие от шахмат, где можно эффективно оценивать позиции, в Го требуется не просто просчитывать варианты, но и понимать стратегическую ценность каждой позиции, учитывать долгосрочные последствия и оценивать тонкие нюансы, определяющие преимущество. Поэтому, для успешной игры в Го необходим не просто алгоритм перебора, а глубокое понимание стратегии и интуиция, что представляет собой значительную проблему для классических AI-систем.
Несмотря на впечатляющие успехи в обработке естественного языка, современные большие языковые модели (LLM) сталкиваются с серьезными ограничениями при анализе сложных игровых ситуаций. Эта проблема, известная как “Проклятие Контекста”, проявляется в том, что способность модели к эффективному рассуждению экспоненциально снижается с увеличением длины игровой последовательности и глубины требуемого анализа. По мере роста объема информации о состоянии игры, модель испытывает трудности с поддержанием релевантности всей этой информации, что приводит к ошибкам в стратегическом планировании и принятии решений. В результате, даже самые мощные LLM могут уступать игрокам-людям или специализированным алгоритмам в играх, требующих глубокого понимания контекста и долгосрочного прогнозирования.
LoGos: Новый Подход к Искусственному Интеллекту в Го
LoGos — это новая большая языковая модель (LLM), разработанная для решения задач, связанных с игрой в Го. В качестве основы для обучения используются модели Qwen2.5-7B-Base и Qwen2.5-32B-Base, обеспечивающие надежную базу для последующего освоения специфических знаний о Го. Выбор данных моделей обусловлен их способностью к эффективной обработке последовательностей и извлечению закономерностей, что критически важно для понимания стратегий и тактики игры. Использование двух вариантов базовых моделей позволяет оценить влияние размера модели на конечные результаты и выбрать оптимальную конфигурацию для достижения наилучшей производительности LoGos.
Модель LoGos использует данные из различных источников для формирования всестороннего понимания игры Го. В частности, применяется Go Commentary Dataset, содержащий комментарии к партиям, и Next Step Prediction Dataset, сгенерированный с помощью движка KataGo. Данный подход позволяет LoGos изучать не только ходы, но и рассуждения, лежащие в их основе, а также предсказывать наиболее вероятные следующие ходы, что способствует повышению эффективности обучения и качества игры.
При построении набора данных для предсказания следующего хода (Next Step Prediction Dataset) ключевую роль играют эвристические правила. Они используются для генерации высококачественных данных, имитирующих игру на уровне экспертов. Применение этих правил позволяет создать обучающую выборку, содержащую ходы, соответствующие общепринятым стратегиям и тактикам игры в Го. Это обеспечивает более эффективное начальное обучение и последующую доработку модели, поскольку она сразу получает информацию о предпочтительных и логичных последовательностях действий, что ускоряет процесс освоения сложной игровой механики.

Обучение и Оптимизация LoGos: Путь к Совершенству
LoGos использует алгоритм Group Relative Policy Optimization (GRPO) для обучения с подкреплением, что позволяет эффективно исследовать игровое пространство и совершенствовать стратегическое понимание. GRPO отличается от стандартных алгоритмов обучения с подкреплением тем, что оценивает политику не относительно абсолютных наград, а относительно производительности группы агентов. Это способствует более стабильному обучению и ускоряет сходимость, особенно в сложных игровых средах, где абсолютная оценка действий может быть зашумлена. Применение GRPO в LoGos позволяет агенту адаптироваться к изменяющимся условиям игры и находить оптимальные стратегии, основываясь на относительных улучшениях в производительности по сравнению с другими агентами, что значительно повышает эффективность обучения и позволяет превзойти стратегии, основанные на статичных данных.
В архитектуре LoGos реализован механизм рассуждений типа “Длинная цепочка мыслей” (Long Chain-of-Thought, CoT), который позволяет системе анализировать сложные игровые ситуации путем последовательного применения логических шагов. Этот подход обеспечивает более глубокое понимание игрового состояния, чем традиционные методы, поскольку CoT позволяет LoGos не просто оценивать текущую позицию, но и прослеживать потенциальные последствия различных действий на несколько шагов вперед. В процессе анализа система генерирует промежуточные рассуждения, которые позволяют ей выявлять неочевидные стратегические возможности и принимать более обоснованные решения, что существенно повышает эффективность игры в сложных сценариях.
Обучение с подкреплением позволяет LoGos выходить за рамки ограничений, присущих статичным наборам данных, и открывать новые стратегии, превосходящие человеческий опыт. В процессе самообучения LoGos самостоятельно исследует игровое пространство, генерируя собственные данные для обучения. Это позволяет системе адаптироваться к меняющимся условиям и находить нетривиальные решения, которые не были предусмотрены разработчиками или не встречаются в существующих базах данных игровых партий. Такой подход позволяет LoGos постоянно совершенствовать свои навыки и развивать стратегии, которые могут быть не очевидны для человека-эксперта.
Оценка Эффективности и Влияние LoGos: Новый Рубеж в Искусственном Интеллекте
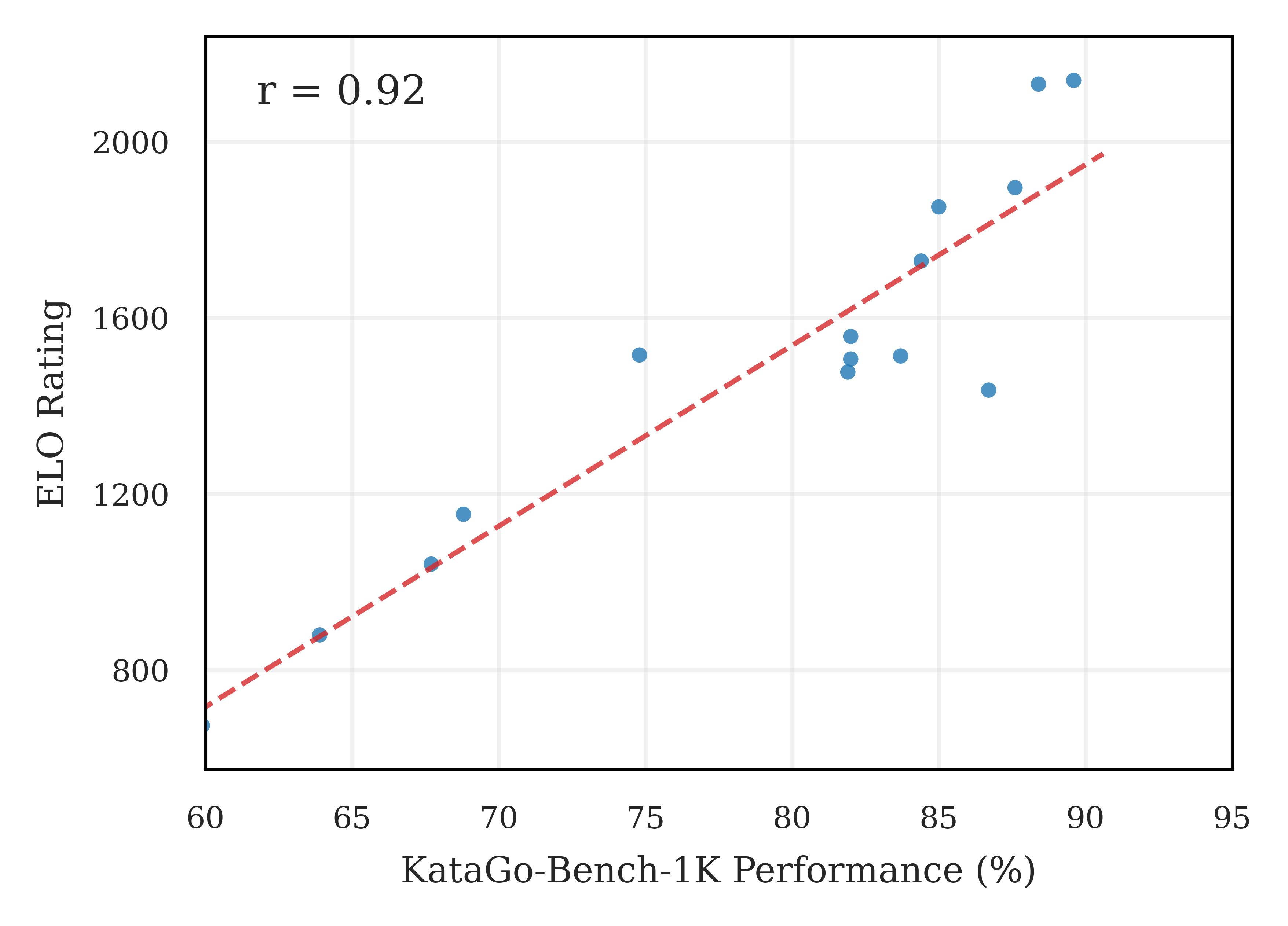
Для оценки возможностей LoGos в игре го использовался бенчмарк KataGo-Bench-1K, представляющий собой набор из тысячи игровых позиций. Оценка производилась с применением системы рейтинга Эло, общепринятого метода определения относительного уровня мастерства игроков. Этот подход позволил объективно сравнить LoGos с другими моделями искусственного интеллекта, специализирующимися на игре го, и установить его текущий уровень, демонстрируя способность к точной оценке позиций и принятию стратегически обоснованных решений. Использование KataGo-Bench-1K как стандартного теста обеспечивает надежность и воспроизводимость результатов, позволяя четко определить прогресс в развитии игровых алгоритмов.
Исследования показали, что LoGos демонстрирует экспертный уровень владения игрой Го, достигнув точности в 88.6% на бенчмарке KataGo-Bench-1K. Этот показатель свидетельствует о способности модели эффективно оценивать позиции и выбирать оптимальные ходы, сравнимые с уровнем опытных игроков. Успех LoGos в решении сложных задач, требующих стратегического планирования и глубокого понимания правил игры, подчеркивает потенциал больших языковых моделей, усиленных обучением с подкреплением и специализированными знаниями в конкретной области. Достижение подобного уровня точности открывает новые перспективы для применения искусственного интеллекта в решении различных задач, требующих анализа и принятия решений в условиях неопределенности.
Исследование продемонстрировало, что LoGos превосходит существующие модели в игре го, значительно опережая Claude3.7-Sonnet с результатом в 34.3% и достигая сопоставимой эффективности с KataGo-Human-SL-9d — 88.6%. Данный прорыв не ограничивается рамками настольной игры; он указывает на перспективность использования больших языковых моделей (LLM), усиленных обучением с подкреплением и специализированными знаниями, для решения сложных стратегических задач в различных областях. Успех LoGos подчеркивает возможность применения подобного подхода к задачам, требующим глубокого анализа и планирования, от управления ресурсами до разработки сложных алгоритмов, открывая новые горизонты для искусственного интеллекта.
Исследование демонстрирует стремление к созданию алгоритмов, которые не просто достигают результата, но и обладают внутренней логической стройностью. Как отмечал Брайан Керниган: «Отладка — это удаление ошибок; программирование — внесение их». Данный подход LoGos, объединяющий самообучение с экспертными знаниями, подчеркивает важность не только достижения высокого уровня игры в Го, но и построения системы, способной к обоснованным решениям. Интеграция эвристических данных в процесс обучения позволяет преодолеть ограничения чистого самообучения, создавая более надежный и понятный алгоритм, что соответствует принципу доказательства корректности, а не просто работы на тестовых примерах.
Куда Далее?
Представленная работа, безусловно, демонстрирует возможность интеграции декларативных знаний в системы, обучающиеся методом самообучения. Однако, истинная проверка заключается не в достижении «экспертного уровня» в конкретной игре, а в обобщении принципов. Нельзя забывать, что Go — игра с конечным числом состояний, а мир — нет. Следовательно, вопрос заключается не в создании сильного игрока в Go, а в создании алгоритма, способного к адаптации и масштабированию на задачи, где объём информации и сложность правил значительно превосходят возможности полного перебора.
Особое внимание следует уделить формализации «экспертных знаний». В текущей реализации, это, по сути, эвристическая база данных, созданная человеком. Будущие исследования должны сосредоточиться на автоматическом извлечении и верификации подобных знаний из неструктурированных источников. Иначе говоря, задача не в том, чтобы научить машину играть в Go, а в том, чтобы научить её мыслить — то есть, строить формальные доказательства, а не просто «угадывать» оптимальные ходы.
Наконец, необходимо признать, что асимптотическая сложность большинства алгоритмов обучения с подкреплением остаётся проблемой. Простое увеличение вычислительных ресурсов не является решением; необходимы принципиально новые подходы к оптимизации и представлению знаний. В противном случае, мы рискуем создать системы, которые впечатляют на демонстрациях, но оказываются бесполезными в реальных условиях.
Оригинал статьи: https://arxiv.org/pdf/2601.16447.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-26 22:56