Автор: Денис Аветисян
Исследователи обнаружили, что механизмы внимания в современных языковых моделях способны эффективно извлекать релевантную информацию из объемных документов, открывая новые возможности для поиска и генерации текстов.
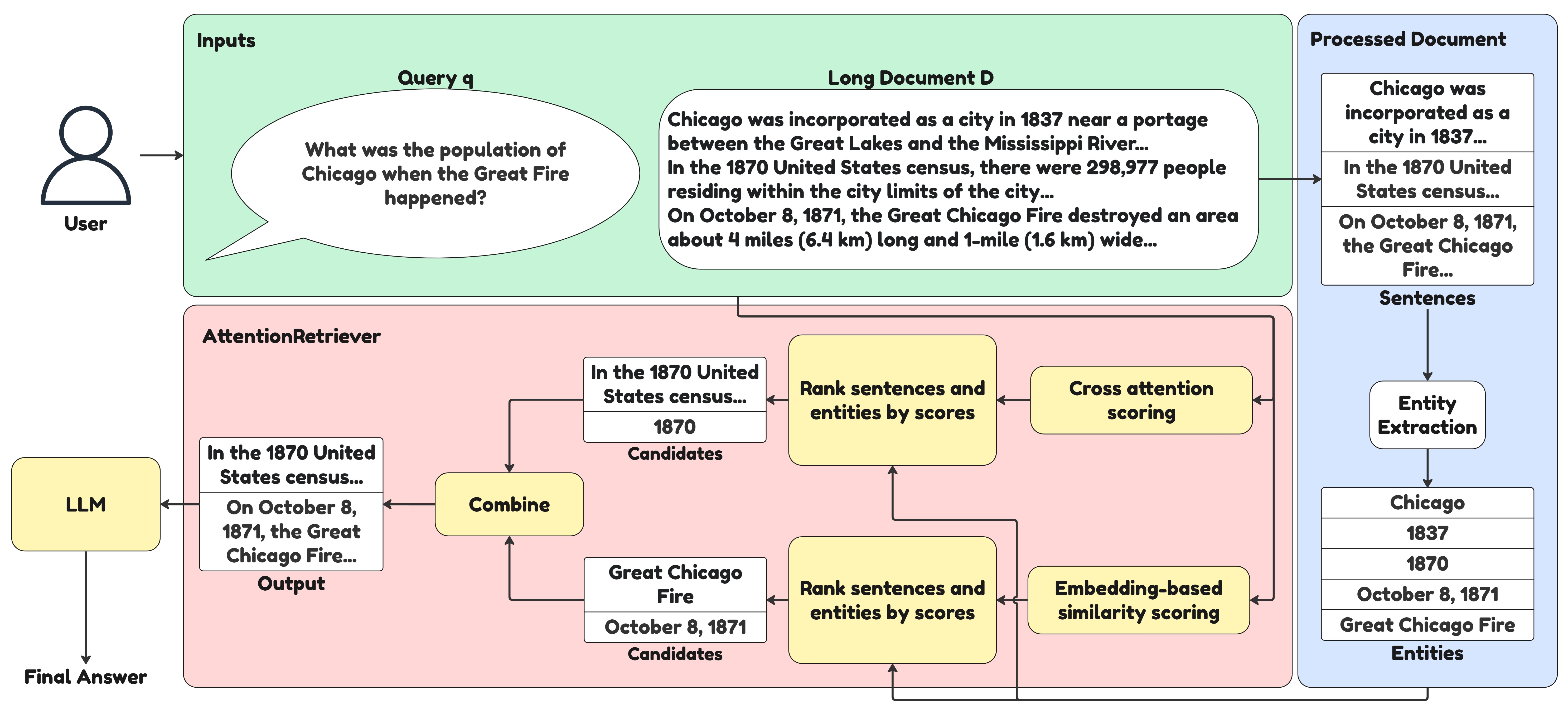
Представленная модель AttentionRetriever использует механизмы внимания и графы сущностей для повышения точности и эффективности извлечения информации из длинных документов.
Несмотря на широкое распространение генеративных моделей с поисковым дополнением (RAG), существующие методы поиска часто оказываются неэффективными при работе с длинными документами. В данной работе, представленной под названием ‘AttentionRetriever: Attention Layers are Secretly Long Document Retrievers’, предлагается новый подход к поиску, использующий механизм внимания и извлечение информации на основе сущностей для построения контекстно-зависимых представлений длинных документов. Показано, что разработанная модель AttentionRetriever значительно превосходит существующие методы поиска по длинным документам, сохраняя при этом высокую эффективность. Возможно ли дальнейшее повышение точности и скорости поиска за счет более глубокой интеграции механизмов внимания и графовых представлений знаний?
Потерянный контекст: Препятствие на пути к глубокому пониманию длинных текстов
Несмотря на впечатляющие возможности, современные большие языковые модели (LLM) демонстрируют снижение эффективности при обработке информации, расположенной в центральной части длинных документов — явление, получившее название “проблема потерянного в середине”. Исследования показывают, что LLM склонны уделять больше внимания началу и концу текста, в то время как содержание, находящееся в середине, часто упускается из виду или недооценивается. Это связано с архитектурными особенностями моделей и сложностью поддержания контекста на протяжении всей последовательности, что негативно сказывается на задачах, требующих глубокого понимания и извлечения знаний из обширных текстовых данных. В результате, точность ответов и качество анализа существенно снижаются по мере увеличения длины документа.
Существенная проблема в обработке длинных текстов языковыми моделями заключается в сложностях поддержания контекста и релевантности информации на протяжении всей последовательности. По мере увеличения длины текста, модели испытывают трудности в удержании связи между начальными и конечными фрагментами, что негативно сказывается на способности к логическим умозаключениям и извлечению знаний. Эта тенденция проявляется в снижении точности ответов на вопросы, требующие понимания взаимосвязей между отдаленными частями документа, и в затруднениях при идентификации ключевой информации, рассеянной по всему тексту. В результате, способность модели к глубокому анализу и эффективному использованию информации, содержащейся в длинных документах, существенно ограничена.
Традиционные методы обработки длинных документов часто прибегают к усечению или использованию скользящих окон, что неизбежно ведет к потере важной информации и снижению эффективности при решении сложных задач. Данный подход особенно заметно проявляется в сравнении с AttentionRetriever — системой, разработанной для работы с наборами данных, характеризующимися значительно большей средней длиной документов, чем существующие эталоны для оценки систем поиска по длинным текстам. В отличие от усечения и скользящих окон, AttentionRetriever стремится сохранить целостность контекста на протяжении всего документа, что позволяет более точно извлекать знания и проводить рассуждения даже в самых объемных текстах. Таким образом, AttentionRetriever представляет собой шаг вперед в решении проблемы обработки длинных документов, позволяя эффективно работать с информацией, которая ранее оказывалась недоступной из-за ограничений традиционных методов.
Внимание к сущностям: AttentionRetriever для восстановления контекста
Модель AttentionRetriever представляет собой новый подход к поиску информации, разработанный для решения проблемы “Lost in the Middle” — снижения точности при извлечении релевантных фрагментов из середины длинных документов. В основе модели лежит использование механизмов внимания (attention) и извлечения информации на основе сущностей. Вместо традиционного последовательного анализа текста, AttentionRetriever фокусируется на взаимосвязях между сущностями, представленными в документе, что позволяет более эффективно определять релевантность фрагментов, независимо от их расположения. Это достигается за счет динамического взвешивания различных частей документа на основе их связи с ключевыми сущностями и запросом пользователя.
Модель AttentionRetriever использует граф сущностей (Entity Graph) для установления связей между текстовыми фрагментами посредством выделения и сопоставления сущностей. Такой подход позволяет расширить контекстное понимание и, как следствие, повысить точность поиска релевантной информации в длинных документах. В ходе тестирования AttentionRetriever продемонстрировал значительное превосходство над современными моделями разреженного и плотного поиска (sparse and dense retrieval models) в задачах поиска по одному документу, что подтверждается результатами сравнительного анализа.
Модель AttentionRetriever эффективно определяет контекстные зависимости и извлекает релевантную информацию из длинных документов, фокусируясь на связях между сущностями и используя метрику эмбеддинговой схожести. В процессе работы модель устанавливает взаимосвязи между текстовыми фрагментами через сущности, что позволяет ей учитывать более широкий контекст и повышать точность поиска. При этом, AttentionRetriever демонстрирует производительность, сопоставимую с крупными плотными моделями, такими как GTE, Qwen3 и GritLM, по времени обработки данных, обеспечивая эффективный поиск в длинных документах.
От поиска к пониманию: Причинно-следственная связь в основе работы AttentionRetriever
Модель AttentionRetriever не ограничивается простой выдачей информации, а активно поддерживает причинно-следственное мышление путём выявления промежуточных ответов и установления связей между связанными концепциями внутри документа. В процессе работы модель идентифицирует не только прямые ответы на запросы, но и сопутствующие данные, необходимые для построения логической цепочки и понимания контекста. Это достигается за счет анализа семантических связей между различными фрагментами текста, что позволяет выявлять косвенные зависимости и формировать целостное представление о предметной области. Выделение промежуточных ответов и связанных концепций способствует более глубокому пониманию информации и позволяет LLM эффективно решать сложные задачи, требующие интеграции данных из разных частей документа.
Модель AttentionRetriever эффективно решает проблему “зависимости от запроса” путем извлечения фоновой информации, релевантной запросу, даже если она не содержит ключевых слов, напрямую связанных с ним. Это достигается за счет анализа семантической близости и контекста, позволяющего выявлять взаимосвязи между различными частями документа. В результате, модель способна предоставлять более полные и точные ответы на вопросы, требующие понимания общей картины, а не просто сопоставления ключевых слов, что особенно важно для сложных информационных задач.
Модель AttentionRetriever обеспечивает возможность ответа на сложные вопросы, требующие интеграции информации из различных частей документа, за счет учета “каузальной зависимости”. В отличие от традиционных методов извлечения информации, которые фокусируются на ключевых словах, AttentionRetriever определяет промежуточные ответы и связи между понятиями, позволяя языковым моделям (LLM) понимать контекст и логические взаимосвязи. Это особенно важно для задач, требующих тонкого понимания, где ответ не может быть получен напрямую из одного фрагмента текста, а требует синтеза информации из нескольких источников внутри документа. Учет каузальной зависимости существенно повышает производительность LLM в решении сложных вопросов и задач, требующих глубокого анализа.
Больше, чем извлечение: Интеграция AttentionRetriever в систему генерации
Модель AttentionRetriever органично встраивается в системы генерации, дополненные поиском (Retrieval-Augmented Generation, RAG), предоставляя большим языковым моделям (LLM) доступ к значительно более обширной и релевантной базе знаний. Вместо использования стандартных методов поиска, AttentionRetriever динамически определяет, какие фрагменты информации наиболее важны для конкретного запроса, и предоставляет LLM именно эти данные. Это позволяет не только повысить точность генерируемого текста, но и обогатить его деталями, которые могли бы быть упущены при использовании традиционных подходов. По сути, AttentionRetriever действует как интеллектуальный фильтр, отсеивая ненужную информацию и предоставляя LLM сконцентрированный поток релевантных данных, что существенно улучшает качество и связность сгенерированного контента.
Сочетание сильных сторон моделей плотного поиска и генеративных возможностей больших языковых моделей (LLM) позволяет системе RAG, усиленной AttentionRetriever, значительно повысить качество и связность генерируемого текста. В отличие от традиционных подходов, где LLM полагаются исключительно на свои внутренние знания, AttentionRetriever предоставляет доступ к релевантной внешней информации, что позволяет создавать более точные, информативные и контекстуально обоснованные ответы. Это особенно важно при работе со сложными запросами или специализированными областями знаний, где внутренние знания LLM могут быть недостаточными или устаревшими. Благодаря такому симбиозу, генерируемый текст не только лучше отражает факты, но и демонстрирует более логичную структуру и последовательность изложения.
Модель AttentionRetriever значительно расширяет возможности обработки длинных документов благодаря технологии ‘Context Length Extension’. Это позволяет языковым моделям (LLM) анализировать и генерировать текст на основе гораздо большего объема информации, чем было возможно ранее. Традиционные LLM часто сталкиваются с ограничениями по длине контекста, что затрудняет работу с объемными текстами, такими как научные статьи, юридические документы или книги. Расширение длины контекста, реализованное в AttentionRetriever, позволяет преодолеть эти ограничения, открывая новые перспективы для создания и анализа длинных текстов, например, автоматического реферирования, углубленного анализа данных и генерации развернутых отчетов. Благодаря этому, модель способна учитывать более широкий спектр информации, обеспечивая более точные, последовательные и контекстуально релевантные результаты.
Исследование демонстрирует, что внимание, изначально задуманное как механизм фокусировки внутри нейронных сетей, обладает скрытым потенциалом в извлечении информации из длинных документов. Авторы предлагают AttentionRetriever — систему, использующую этот механизм для повышения точности и эффективности поиска. Подход к структурированию данных через графы сущностей позволяет системе не просто находить релевантные фрагменты, но и понимать контекст, что критически важно для работы с большими объемами информации. Как заметил Линус Торвальдс: «Плохой дизайн — это когда все работает, но никто не знает почему». В данном исследовании, наоборот, раскрывается скрытая функциональность существующей архитектуры, демонстрируя элегантность простого решения сложной задачи.
Что Дальше?
Представленная работа, демонстрируя неожиданную способность механизмов внимания к извлечению релевантной информации из длинных документов, поднимает вопрос о природе самой «внимательности» в контексте больших языковых моделей. Вместо сложной инженерии признаков и громоздких систем поиска, внимание, как оказалось, уже содержит зачатки эффективного извлечения. Однако, стоит признать, что это лишь первый шаг. Устойчивость к «шуму» в данных, адаптация к различным форматам документов и, самое главное, понимание семантической структуры текста — всё это остается областью активных исследований.
Простота предложенного подхода — его сила, но и потенциальная слабость. Если решение слишком элегантно, то оно, вероятно, не учитывает всю сложность реального мира. Дальнейшие исследования должны быть направлены на интеграцию AttentionRetriever с более сложными системами представления знаний, такими как графы сущностей, не как добавку, а как органичную часть единой системы. Настоящая задача — не просто «найти» информацию, а понять её значение в контексте.
В конечном итоге, успех этого направления будет зависеть от способности создать системы, которые не просто имитируют понимание, а действительно его демонстрируют. И пусть кажущаяся простота AttentionRetriever станет напоминанием о том, что иногда самое эффективное решение — это самое ясное и элегантное.
Оригинал статьи: https://arxiv.org/pdf/2602.12278.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-16 00:22