Автор: Денис Аветисян
Обзор посвящен развитию и ограничениям моделей искусственного интеллекта, способных извлекать информацию из графиков и диаграмм.
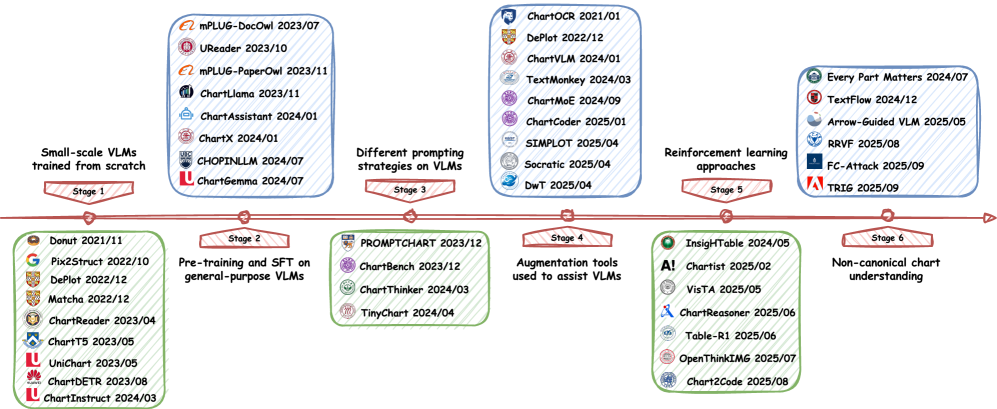
Анализ современных подходов к мультимодальному слиянию данных и перспективы улучшения визуального рассуждения в моделях, работающих с нетрадиционными типами графиков.
Несмотря на очевидную необходимость интеграции визуальной и текстовой информации для полноценного понимания графиков, существующие подходы к анализу данных часто оказываются фрагментированными. В настоящем обзоре, озаглавленном ‘Multimodal Information Fusion for Chart Understanding: A Survey of MLLMs — Evolution, Limitations, and Cognitive Enhancement’, систематизированы основные компоненты и тенденции развития мультимодальных больших языковых моделей (MLLM) в контексте анализа графиков. Показано, что, несмотря на значительный прогресс, текущие модели демонстрируют ограничения в перцептивных способностях и логическом выводе, особенно при работе с нестандартными типами диаграмм. Какие новые стратегии обучения и архитектуры MLLM позволят преодолеть эти ограничения и создать действительно интеллектуальные системы для анализа данных?
Визуализация Данных: Ключ к Пониманию Информации
Эффективная коммуникация напрямую зависит от способности преобразовывать сложные данные в понятные и доступные форматы. Сложные массивы информации, будь то статистические отчеты, научные исследования или экономические показатели, часто остаются невостребованными, если их сложно интерпретировать. Преобразование этих данных в визуально привлекательные и легко воспринимаемые формы, такие как графики, диаграммы и интерактивные карты, позволяет быстро выявлять закономерности, тренды и аномалии. Этот процесс не просто упрощает понимание информации, но и способствует более эффективному принятию решений, поскольку позволяет заинтересованным сторонам быстро ориентироваться в данных и делать обоснованные выводы. В конечном итоге, способность ясно и доступно представлять информацию является ключевым фактором успеха в любой области, требующей анализа и интерпретации данных.
Визуализация данных выступает в роли ключевого моста между сырыми цифрами и практическими выводами. Она позволяет не просто увидеть закономерности, но и мгновенно их оценить, существенно ускоряя процесс принятия обоснованных решений. Преобразование сложных наборов данных в графики, диаграммы и интерактивные представления делает информацию доступной для широкого круга пользователей, даже без специальной подготовки в области анализа. В результате, визуализация данных становится незаменимым инструментом для выявления тенденций, обнаружения аномалий и прогнозирования будущих событий, что особенно важно в условиях постоянно растущего объема информации.
Несмотря на потенциальную ценность скрытых в данных закономерностей, их истинное значение часто остается нераскрытым без эффективной визуализации. Даже самые глубокие аналитические выводы и статистически значимые результаты бессильны, если они представлены в форме, недоступной для понимания широкой аудитории. Отсутствие наглядных графиков, диаграмм и интерактивных представлений данных приводит к тому, что информация остается запертой в таблицах и отчетах, лишая ее способности влиять на принятие решений и стимулировать инновации. В результате, ценные знания, содержащиеся в данных, оказываются невостребованными и теряются, подчеркивая критическую важность визуализации как инструмента для раскрытия потенциала информации.
Канонические Диаграммы: Основа Визуализации Данных
Стандартные типы диаграмм, такие как столбчатые диаграммы, линейные графики и гистограммы, сохраняют свою доминирующую позицию благодаря своей простоте и широкой узнаваемости. Эта распространенность обусловлена тем, что эти типы визуализаций легко воспринимаются и не требуют специальной подготовки для интерпретации. Большинство пользователей уже знакомы с принципами их построения и чтения, что снижает когнитивную нагрузку и позволяет быстро извлекать информацию. Простота реализации и поддержки в различных программных пакетах и библиотеках также способствует их повсеместному использованию.
Стандартные графики, такие как столбчатые диаграммы, линейные графики и гистограммы, эффективно визуализируют прямые сравнения и тенденции в одном или ограниченном количестве измерений. Они особенно полезны для демонстрации количественных различий между категориями данных или для отслеживания изменений одной переменной во времени. Способность четко отображать данные в этих ограниченных измерениях делает их пригодными для быстрого анализа и принятия решений, поскольку не требуют сложной интерпретации многомерных отношений. Применимость таких графиков ограничена сложными наборами данных, требующими визуализации нескольких взаимосвязанных переменных.
Широкое распространение стандартных типов диаграмм — столбчатых диаграмм, линейных графиков и гистограмм — обеспечивает немедленное понимание данных для широкой аудитории. Это связано с тем, что большинство пользователей знакомы с принципами их построения и интерпретации, что формирует базовый уровень восприятия информации. Повсеместное использование этих диаграмм позволяет исследователям и аналитикам представлять данные таким образом, чтобы минимизировать когнитивную нагрузку на читателя и обеспечить быстрое извлечение ключевых выводов, что критически важно для эффективной коммуникации и принятия решений.
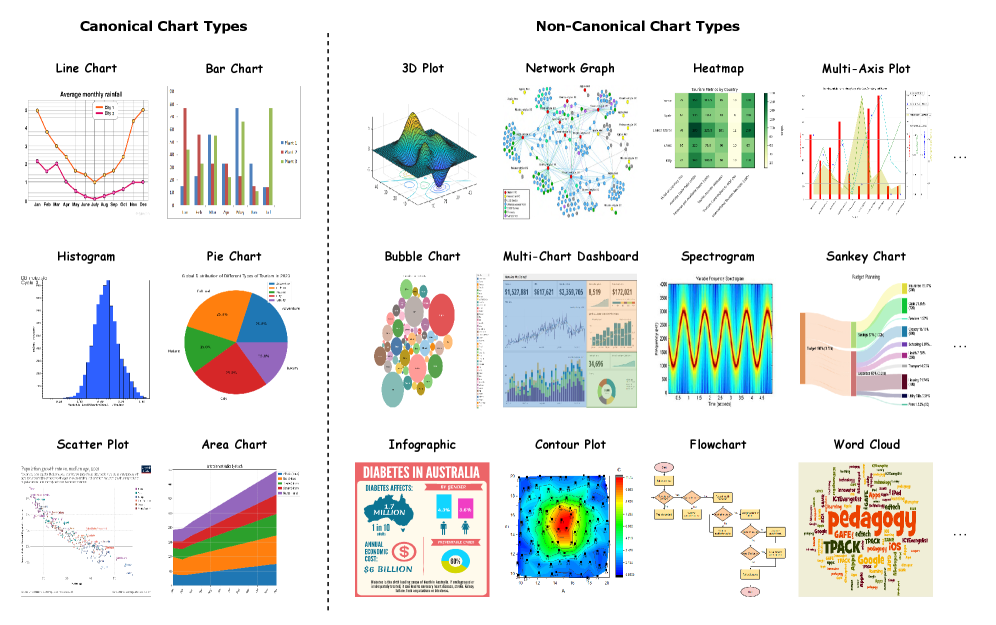
За Пределами Базовых: Исследование Неканонических Диаграмм
Сложные наборы данных часто требуют использования нетрадиционных типов диаграмм — блок-схем, радарных диаграмм, древовидных диаграмм и других — для выявления скрытых закономерностей. В то время как стандартные графики, такие как гистограммы и линейные графики, эффективны для представления простых отношений, они могут оказаться недостаточными для визуализации многомерных данных или сложных взаимосвязей. Неканонические диаграммы позволяют представлять несколько переменных, отношения между ними и иерархические структуры в едином представлении, что делает возможным обнаружение корреляций и трендов, которые были бы невидимы при использовании более простых методов визуализации. Выбор подходящего неканонического типа диаграммы зависит от конкретных характеристик данных и целей анализа.
Продвинутые визуализации, такие как блок-схемы, радарные диаграммы и древовидные диаграммы, позволяют одновременно отображать несколько переменных, связи между ними и иерархические структуры данных. В отличие от базовых графиков, они способны представить сложные взаимосвязи в едином визуальном представлении, что особенно важно при анализе многомерных данных. Например, радарные диаграммы эффективно демонстрируют характеристики нескольких объектов по различным параметрам, а древовидные диаграммы визуализируют иерархические отношения, такие как организационные структуры или классификации. Такой подход обеспечивает более полное понимание данных, чем использование отдельных графиков для каждой переменной или взаимосвязи.
Настоящий обзор охватывает широкий спектр актуальных исследований в области понимания диаграмм с использованием мультимодальных больших языковых моделей (MLLM). Проанализированные работы демонстрируют разнообразие подходов к интерпретации визуальной информации, включая задачи распознавания элементов диаграмм, извлечения данных и логического вывода на их основе. Особое внимание уделено сравнительному анализу различных архитектур MLLM и методов обучения, применяемых для решения задач понимания диаграмм различной сложности и типов, включая не только стандартные графики, но и более сложные визуализации, такие как блок-схемы, радарные диаграммы и древовидные структуры. Исследования охватывают как задачи классификации диаграмм, так и более сложные задачи генерации текстовых описаний и ответов на вопросы по визуальному контенту.
Неканонические диаграммы, требующие более развитых навыков интерпретации, позволяют выявлять закономерности, скрытые при использовании более простых методов визуализации. Способность к анализу и пониманию этих сложных графических представлений коррелирует с развитием когнитивных способностей, что в контексте исследований МLLM оценивается как проявление “Системы 2” — медленного, аналитического и требующего больших усилий мышления, в отличие от быстрой, интуитивной “Системы 1”. Таким образом, улучшение способности МLLM к обработке неканонических диаграмм рассматривается не просто как расширение функциональности, но и как индикатор развития более сложных когнитивных процессов.
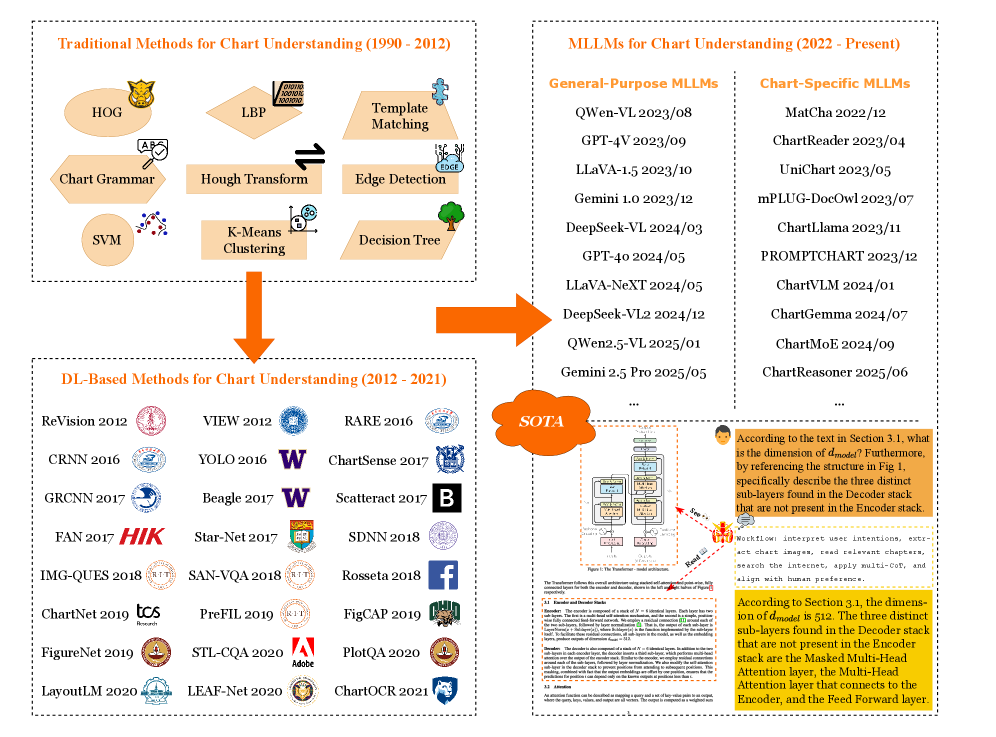
Исследование, представленное в обзоре, демонстрирует эволюцию мультимодальных больших языковых моделей (MLLM) в контексте понимания графиков. Особое внимание уделяется ограничениям текущих подходов, в частности, неспособности к надежному визуальному рассуждению и эффективному слиянию информации из различных источников. Как отмечал Ян Лекун: «Машинное обучение — это поиск закономерностей». Именно поиск и воспроизведение закономерностей в визуальных данных, а также их интерпретация, являются ключевыми задачами, которые необходимо решить для создания действительно интеллектуальных систем анализа графиков. Если закономерность нельзя воспроизвести или объяснить, её не существует — этот принцип особенно актуален при оценке эффективности MLLM в обработке нетрадиционных типов графиков.
Куда двигаться дальше?
Представленный обзор демонстрирует, что кажущийся триумф мультимодальных больших языковых моделей в области понимания диаграмм скрывает глубокие закономерности, требующие дальнейшего исследования. Каждое изображение, даже самое простое, таит в себе структурные зависимости, которые пока лишь частично улавливаются существующими моделями. Успех не должен измеряться красивыми результатами, а интерпретацией лежащих в основе моделей — именно здесь кроется подлинный прогресс.
Очевидным направлением является преодоление ограничений в визуальном рассуждении. Модели должны не просто «видеть» диаграмму, но и понимать её внутреннюю логику, уметь экстраполировать данные и делать обоснованные выводы. Особое внимание следует уделить работе с неканоническими диаграммами — теми, что нарушают привычные правила визуализации. Именно в этих отклонениях и кроется истинный тест для интеллектуальной системы.
Перспективы включают в себя разработку более эффективных методов слияния информации, возможно, с использованием принципов обучения с подкреплением, а также углубленное изучение когнитивных механизмов, лежащих в основе человеческого понимания данных. В конечном итоге, задача состоит не в том, чтобы создать модель, имитирующую интеллект, а в том, чтобы понять, что вообще представляет собой этот интеллект.
Оригинал статьи: https://arxiv.org/pdf/2602.10138.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-13 01:49