Автор: Денис Аветисян
Представлен ChartComplete — масштабный датасет, призванный значительно улучшить способность искусственного интеллекта к анализу и интерпретации разнообразных типов графиков.
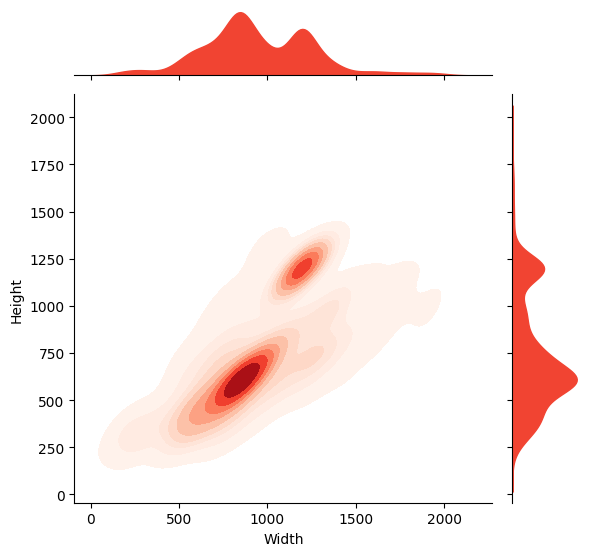
Датасет ChartComplete включает 30 различных типов диаграмм и основан на структурированной таксономии, что позволяет преодолеть ограничения существующих бенчмарков в области визуального анализа данных.
Несмотря на значительный прогресс в области машинного обучения и компьютерного зрения, существующие наборы данных для анализа диаграмм зачастую ограничены небольшим количеством типов визуализаций. В данной работе мы представляем ‘ChartComplete: A Taxonomy-based Inclusive Chart Dataset’ — новый, всесторонний набор данных, основанный на классификации диаграмм, включающий тридцать различных типов. Данный ресурс призван преодолеть ограничения существующих бенчмарков и способствовать более точному измерению эффективности мультимодальных больших языковых моделей в понимании графических данных. Позволит ли ChartComplete создать более надежные и универсальные системы автоматизированного анализа визуальной информации?
Выявление Истинной Сущности Визуального Рассуждения
Несмотря на значительный прогресс в области искусственного интеллекта, машины всё ещё испытывают трудности с тонким визуальным мышлением, необходимым для эффективной интерпретации графиков и диаграмм. В то время как алгоритмы успешно справляются с распознаванием отдельных элементов, понимание взаимосвязей между данными, выявление тенденций и экстракция значимой информации требуют гораздо более сложного когнитивного процесса. Это связано с тем, что визуальные представления данных часто содержат неявные подсказки, контекстуальную информацию и требуют интуитивного понимания принципов визуализации, которые пока что трудно воспроизвести в машинных системах. В результате, даже самые современные алгоритмы могут ошибаться в простых задачах, требующих не просто распознавания формы, но и понимания смысла, закодированного в визуальном представлении данных.
Существующие системы понимания графиков демонстрируют недостаточную устойчивость при работе с разнообразием визуализаций и данных, встречающихся в реальных сценариях. Они часто оказываются неспособными корректно интерпретировать графики, отличающиеся по стилю, цветовой схеме, используемым меткам или типу представленных данных. Это связано с тем, что большинство подходов разрабатываются и тестируются на ограниченных, тщательно отобранных наборах данных, что не позволяет им обобщать знания и эффективно работать с графиками, отличающимися от тех, на которых они обучались. В результате, даже небольшие изменения в визуальном представлении или структуре данных могут привести к существенному снижению точности и надежности работы таких систем, ограничивая их применимость в практических задачах анализа и извлечения информации.
Отсутствие надежного визуального анализа данных существенно ограничивает возможности автоматизированного принятия решений и извлечения ценной информации. Неспособность машин корректно интерпретировать графики и диаграммы приводит к ошибкам в прогнозировании, неверной оценке тенденций и, как следствие, к неоптимальным стратегиям в различных областях — от финансов и медицины до научных исследований и управления производством. В условиях экспоненциального роста объемов визуальных данных, эта проблема становится все более острой, поскольку полагаться на ручной анализ становится непрактично и ресурсоемко. Разработка систем, способных к надежной интерпретации визуальной информации, является ключевым фактором для раскрытия полного потенциала данных и обеспечения объективности принимаемых решений.
Необходимость в создании всестороннего и адаптируемого эталона для ответов на вопросы по графикам представляется критически важной, поскольку существующие подходы зачастую оказываются неспособны адекватно оценивать и сравнивать различные системы автоматического анализа визуальных данных. Такой эталон должен включать в себя разнообразные типы графиков, сложности вопросов и способы представления данных, чтобы обеспечить надежную и объективную оценку прогресса в области машинного зрения и искусственного интеллекта. Он позволит исследователям не только оценивать эффективность новых алгоритмов, но и выявлять слабые места существующих, стимулируя разработку более устойчивых и интеллектуальных систем, способных извлекать ценную информацию из визуальных представлений данных и принимать обоснованные решения.
ChartComplete: Новый Эталон для Надёжного Анализа Графиков
Набор данных ChartComplete представляет собой новую коллекцию, включающую 30 различных типов диаграмм, разработанную с целью повышения устойчивости и обобщающей способности моделей ChartQA. В отличие от существующих наборов данных, ChartComplete охватывает более широкий спектр визуализаций, что позволяет моделям лучше справляться с разнообразием графических представлений данных, встречающихся в реальных сценариях. Это достигается за счет целенаправленного включения как распространенных, так и менее типичных типов диаграмм, что способствует развитию моделей, способных к более надежному анализу и интерпретации данных, представленных в различных форматах.
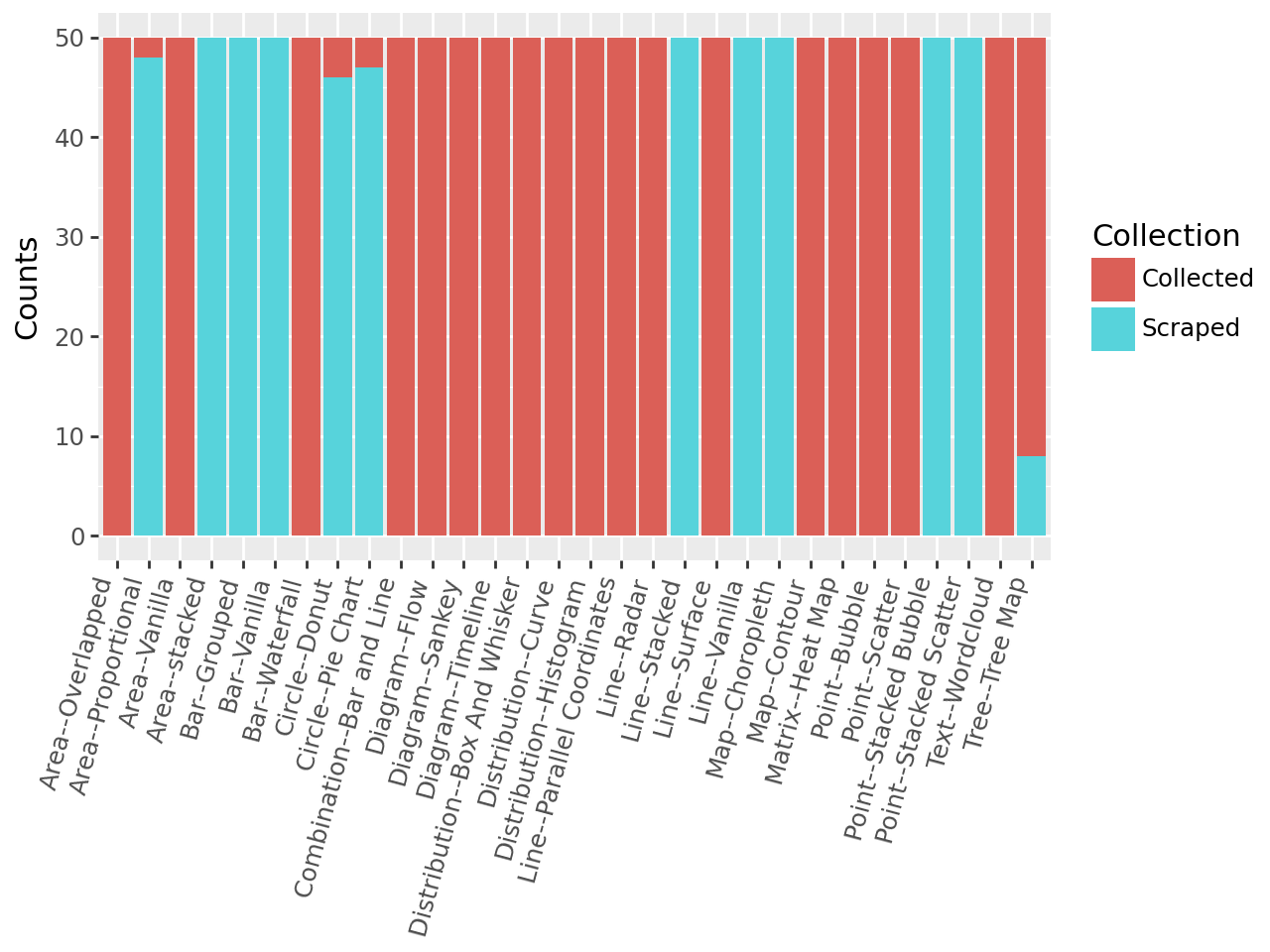
Набор данных ChartComplete содержит 1500 изображений графиков, по 50 экземпляров каждого из 30 различных типов. Это значительно превышает масштаб существующих наборов данных для задач ChartQA. Увеличение количества примеров позволяет обучать модели с повышенной обобщающей способностью и улучшает их устойчивость к вариациям в представлении данных. Более крупный набор данных способствует более надежной оценке производительности моделей и снижает риск переобучения на ограниченном количестве примеров.
Набор данных ChartComplete формируется на основе информации, полученной из авторитетных онлайн-источников, в частности, Statista (12 635 графиков) и Our World in Data (4 113 графиков). Использование этих источников обеспечивает соответствие распределения данных в наборе реальным распределениям данных, встречающимся в практических приложениях. Такой подход позволяет обучать модели ChartQA на более репрезентативных данных, что способствует повышению их точности и надежности при работе с реальными графиками.
Набор данных ChartComplete использует комбинированный подход к сбору, сочетая автоматизированный сбор (scraping) и ручную аннотацию. Из 30 представленных типов диаграмм, 18 были собраны исключительно вручную, 8 — исключительно посредством автоматизированного сбора данных, а оставшиеся 4 типа диаграмм сформированы с использованием комбинации обоих методов. Такой гибридный подход позволяет обеспечить разнообразие данных и контроль качества, учитывая как масштабность автоматизированного сбора, так и точность ручной аннотации.
Визуализация и Сравнение Графиков: Методы и Инструменты
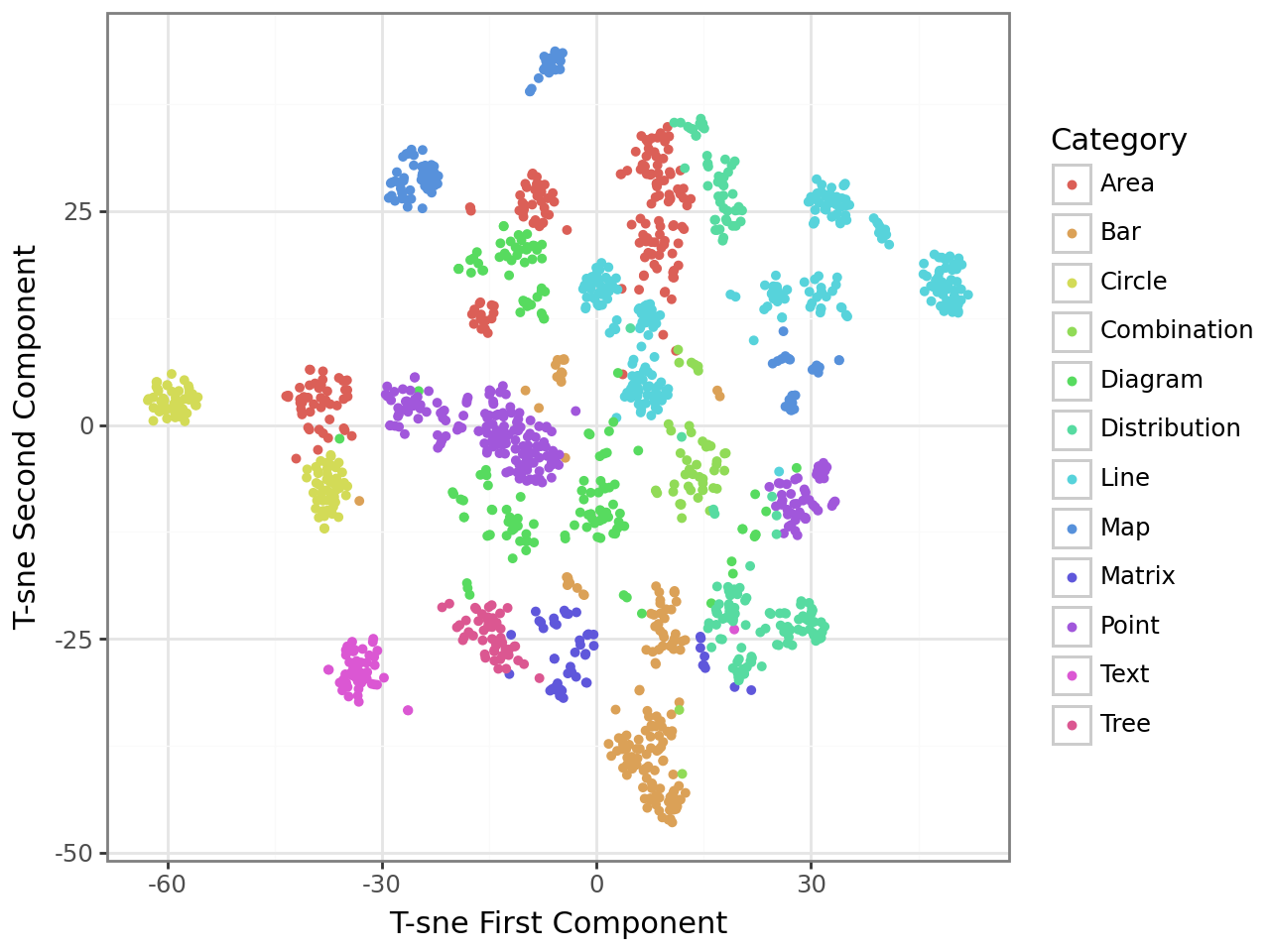
Для извлечения информативных признаков из каждого графика в наборе данных используется модель Google ViT (Vision Transformer). ViT, изначально разработанная для обработки изображений, применяет механизм self-attention для выявления сложных паттернов и взаимосвязей в визуальном представлении графиков. Это позволяет получить векторные представления, отражающие не только пиксельные данные, но и семантическое содержание графика, такое как типы диаграмм, используемые цвета, и взаиморасположение элементов. Полученные признаки служат основой для дальнейшего анализа и сравнения графиков, обеспечивая возможность понимания их структуры и содержания на более высоком уровне.
Метод снижения размерности t-SNE (t-distributed Stochastic Neighbor Embedding) применяется для визуализации пространства признаков, полученных из векторных представлений графиков. Этот метод позволяет отобразить многомерные данные в двумерном или трехмерном пространстве, сохраняя при этом локальную структуру данных. В результате, графики схожих типов, имеющие близкие значения признаков, оказываются расположены близко друг к другу на визуализации. Это облегчает выявление закономерностей и связей между различными типами графиков, а также позволяет обнаружить кластеры, представляющие собой группы графиков с общими характеристиками. Визуализация пространства признаков с помощью t-SNE является эффективным инструментом для анализа и интерпретации данных, полученных из набора графиков.
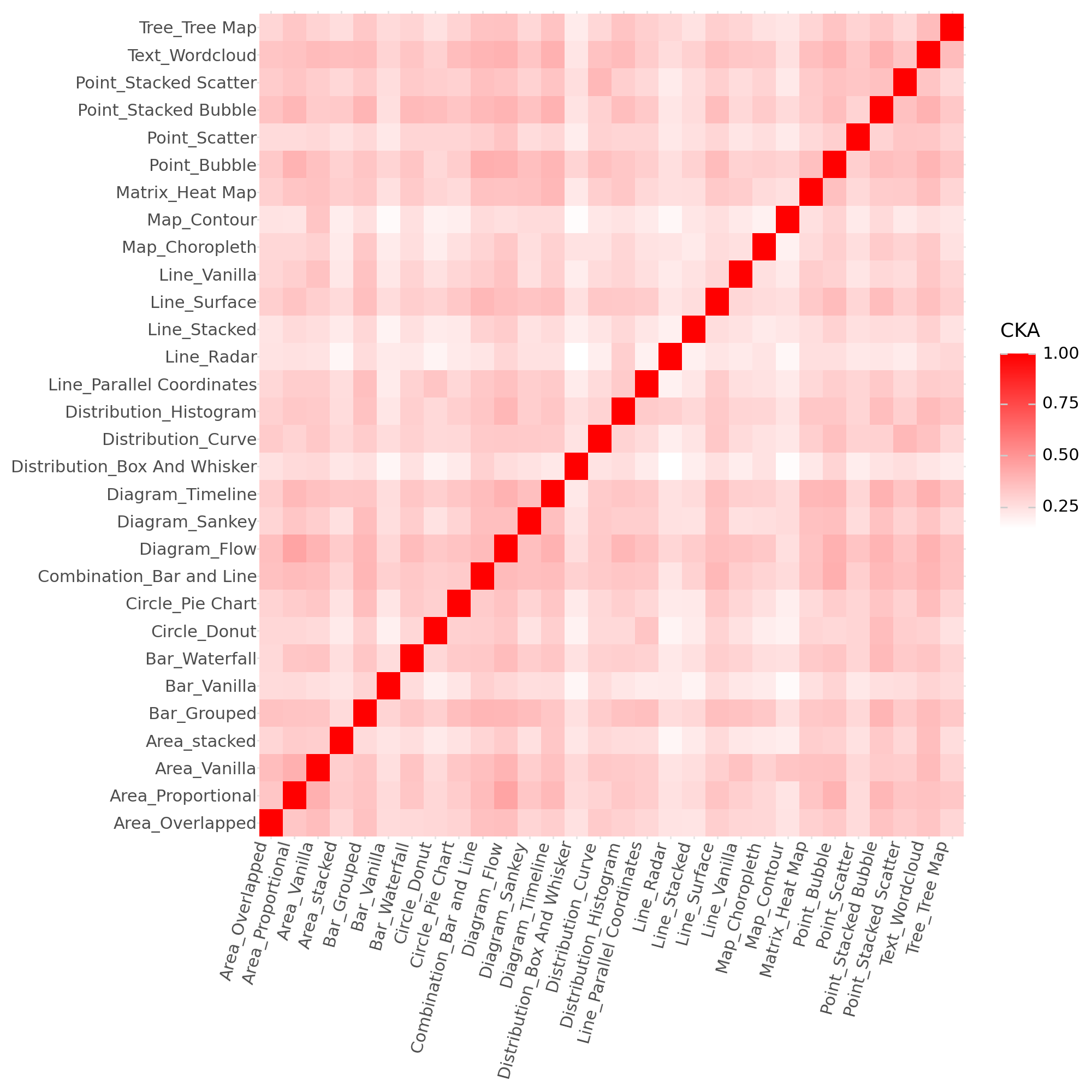
Центрированное выравнивание ядер (CKA) представляет собой количественную метрику, используемую для оценки сходства между представлениями признаков, полученными из различных источников или моделей. CKA вычисляет корреляцию между центрированными ядрами, определяемыми матрицами Грама признаков. Формально, CKA между двумя наборами признаков X и Y определяется как CKA(X, Y) = \frac{\sum_{i,j} K_{X}(i,j)K_{Y}(i,j)}{\sqrt{\sum_{i,j} K_{X}(i,j)^2 \sum_{i,j} K_{Y}(i,j)^2}}, где K — матрица ядра. Значение CKA варьируется от 0 до 1, где 1 указывает на полное сходство, а 0 — на отсутствие сходства между представлениями. В контексте визуализации графиков, CKA позволяет численно оценить, насколько похожи представления различных типов графиков, полученные с помощью Google ViT.
Система FAISS (Facebook AI Similarity Search) обеспечивает высокоскоростной поиск схожих графиков на основе извлеченных визуальных признаков. Используя алгоритмы индексирования и приближенного поиска ближайших соседей, FAISS позволяет эффективно сканировать большие наборы данных графиков и быстро находить экземпляры, обладающие схожими визуальными характеристиками. Это достигается за счет квантования векторов признаков и использования специализированных структур данных, оптимизированных для поиска в многомерных пространствах. Производительность FAISS значительно превосходит традиционные методы поиска, особенно при работе с миллионами графиков, что делает ее незаменимым инструментом для задач визуального анализа и категоризации.
Расширяя Границы Chart Question Answering
Набор данных ChartComplete создан для непосредственной поддержки и расширения возможностей существующих бенчмарков ChartQA, предоставляя более сложную и реалистичную платформу для оценки систем ответа на вопросы по диаграммам. В отличие от предыдущих подходов, ChartComplete включает в себя диаграммы, требующие более глубокого анализа и синтеза информации, а также вопросы, сформулированные с учетом реальных сценариев использования. Это позволяет более точно оценить способность моделей к рассуждениям, основанным на визуальных данных, и выявить слабые места в существующих алгоритмах. Таким образом, ChartComplete способствует развитию более интеллектуальных инструментов анализа данных и автоматизированного извлечения полезной информации.
Предыдущая работа над набором данных FigureQA заложила важный фундамент для развития систем ответа на вопросы по графикам, однако ChartComplete значительно расширяет его возможности и масштаб. Если FigureQA фокусировался на базовых типах графиков и простых вопросах, то ChartComplete представляет собой более сложный и разнообразный набор данных, включающий широкий спектр визуализаций и требующий более глубокого понимания представленной информации. Это расширение позволяет исследователям разрабатывать и оценивать модели, способные справляться с более реалистичными и сложными сценариями анализа данных, что, в свою очередь, открывает перспективы для создания интеллектуальных инструментов, способных автоматически извлекать ценные сведения из графиков и диаграмм.
Набор данных ChartComplete предоставлен научному сообществу под лицензией CC BY, что обеспечивает свободный доступ, возможность модификации и распространения для любых целей, включая коммерческие. Такой подход стимулирует широкое сотрудничество между исследователями, позволяя им использовать и улучшать существующий ресурс для разработки новых методов и алгоритмов в области анализа графиков и ответов на вопросы, основанные на данных. Открытый доступ к набору данных существенно ускоряет прогресс в этой области, поскольку позволяет избежать дублирования усилий и способствует быстрому обмену знаниями и результатами исследований, создавая благоприятную среду для инноваций и технологического развития.
Разработка данного подхода открывает перспективы для создания интеллектуальных инструментов анализа данных и автоматизированного получения выводов, что находит широкое применение в различных областях. Возможность автоматической интерпретации графических данных позволяет существенно ускорить процесс принятия решений в финансах, медицине, маркетинге и других сферах, где визуализация информации играет ключевую роль. Автоматизация анализа не только экономит время и ресурсы, но и позволяет выявлять закономерности и тренды, которые могут быть упущены при ручном анализе, способствуя более глубокому пониманию сложных данных и повышению эффективности принимаемых решений. В перспективе, подобные инструменты могут стать неотъемлемой частью систем поддержки принятия решений и помочь в решении сложных задач, требующих обработки больших объемов визуальной информации.
Исследование, представленное в данной работе, демонстрирует стремление к созданию всеобъемлющей базы данных для визуализации данных — ChartComplete. Это, по сути, попытка формализовать понимание графиков, классифицировать их типы и обеспечить надежную основу для развития систем искусственного интеллекта в области анализа визуальной информации. В этой связи, вспоминается высказывание Давида Гильберта: «Пусть N стремится к бесконечности — что останется устойчивым?». В контексте ChartComplete, устойчивым должно остаться не только корректное распознавание базовых типов графиков, но и способность системы адаптироваться к новым, ранее не встречавшимся визуализациям, расширяя границы своего понимания и обеспечивая надежность анализа данных при любом объеме информации.
Что Дальше?
Представленный набор данных, ChartComplete, безусловно, является шагом вперёд в систематизации и расширении возможностей систем искусственного интеллекта в области понимания графиков. Однако, следует признать, что само по себе увеличение количества типов графиков не решает фундаментальную проблему — извлечение смысла. Достаточность данных — необходимое, но не достаточное условие. Истинная проверка алгоритма заключается не в его способности классифицировать график как “столбчатую диаграмму”, а в корректном извлечении из него информации и её представлении в формализованном виде.
Очевидным направлением дальнейших исследований является разработка метрик, способных оценивать не только точность классификации, но и семантическую близость извлечённой информации к истинному значению. Простота алгоритма, его асимптотическая сложность и масштабируемость, должны быть приоритетнее, чем достижение высокой точности на ограниченном наборе тестовых примеров. Необходимо отбросить иллюзию, что большое количество данных автоматически гарантирует понимание.
Будущие работы должны сосредоточиться на разработке алгоритмов, способных к обобщению и адаптации к новым, ранее не встречавшимся типам графиков. Вместо слепого увеличения размера набора данных, необходимо искать элегантные и математически обоснованные решения, способные к построению устойчивых и доказуемо корректных моделей понимания визуальной информации. Иначе, мы лишь усложним задачу, не приближаясь к её истинному решению.
Оригинал статьи: https://arxiv.org/pdf/2601.10462.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-01-18 19:29