Автор: Денис Аветисян
Новое исследование оценивает способность ИИ к самостоятельному поиску информации и анализу данных, а не просто к выполнению заданных инструкций.
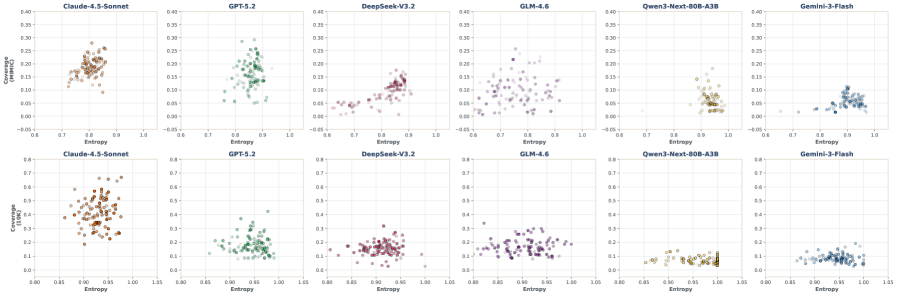
Представлен DDR-Bench — эталонный набор данных для оценки навыков автономного исследования данных у больших языковых моделей.
В то время как современные большие языковые модели демонстрируют впечатляющую способность отвечать на вопросы, их потенциал в автономном исследовании и извлечении знаний остается недостаточно изученным. В работе ‘Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models’ предложен новый подход к оценке так называемого “исследовательского интеллекта” — способности модели самостоятельно ставить цели и анализировать данные, а не просто выполнять заданные инструкции. Авторы представляют DDR-Bench — масштабный бенчмарк, предназначенный для верификации способности моделей к автономному анализу данных и выявлению ключевых инсайтов. Какие стратегии позволят языковым моделям не просто “охотиться” за ответами, но и самостоятельно формулировать значимые вопросы и находить скрытые закономерности в данных?
За гранью исполнения: рождение исследовательского интеллекта
Традиционные большие языковые модели демонстрируют впечатляющую эффективность в решении чётко сформулированных задач, будь то перевод текста, написание кода или ответы на конкретные вопросы. Однако, их возможности ограничиваются рамками заданного, им свойственна неспособность к самостоятельному поиску информации и генерации новых знаний. В отличие от человека, способного формулировать гипотезы и исследовать различные направления, современные LLM нуждаются в детальных инструкциях и заранее определённых параметрах. Эта особенность ограничивает их потенциал в задачах, требующих креативности, анализа больших объёмов данных с целью выявления скрытых закономерностей, и, как следствие, самостоятельного открытия нового.
Существенным ограничением современных больших языковых моделей является неспособность самостоятельно определять, какие вопросы задавать и какие данные исследовать. В отличие от выполнения чётко определённых задач, требующих лишь обработки информации, подлинное открытие требует инициативы в выборе направлений поиска. Модели, лишённые этой способности к автономному формулированию исследовательских запросов, сталкиваются с трудностями при анализе сложных, неоднозначных данных и выявлении скрытых закономерностей. Отсутствие самостоятельности в определении приоритетов исследования препятствует переходу от простого извлечения информации к генерации новых знаний и пониманию, что существенно ограничивает их потенциал в областях, требующих критического мышления и инноваций.
Недостаток так называемого “исследовательского интеллекта” у современных языковых моделей требует разработки принципиально новых критериев оценки и методик совершенствования их способности к самостоятельному поиску и анализу данных. Традиционные метрики, ориентированные на выполнение заданных инструкций, оказываются неадекватными для измерения способности модели самостоятельно формулировать исследовательские вопросы, выявлять релевантную информацию и делать обоснованные выводы. Поэтому, для достижения подлинного прогресса в области искусственного интеллекта, необходимо создавать комплексные бенчмарки, имитирующие реальные исследовательские задачи, и разрабатывать алгоритмы, позволяющие моделям не просто обрабатывать данные, но и активно их искать, анализировать и интерпретировать, подобно учёным-исследователям.

DDR-Bench: платформа для автономных открытий
В отличие от традиционных бенчмарков, оценивающих языковые модели (LLM) по выполнению конкретных задач, DDR-Bench фокусируется на оценке их способностей в области глубокого анализа данных. Целью является не просто получение ответа на заданный вопрос, а автономная генерация новых знаний и инсайтов из данных. Это подразумевает, что LLM должна самостоятельно формулировать исследовательские направления, выдвигать гипотезы, проводить анализ и обосновывать логику своих действий, что существенно отличается от решения предопределенных задач и требует более высокого уровня когнитивных способностей.
В качестве основы для оценки, DDR-Bench использует разнообразные наборы данных, включающие MIMIC-IV — обширную базу данных медицинских записей, 10-K Database — информацию о финансовых отчётах публичных компаний, и GLOBEM — глобальный набор данных о микробиомных исследованиях. Данные MIMIC-IV представляют собой комплексную задачу из-за своей структурированности и необходимости понимания медицинской терминологии. 10-K Database требует анализа структурированных и неструктурированных данных для выявления финансовых тенденций. GLOBEM, в свою очередь, представляет собой задачу из-за сложности интерпретации данных о микробиоте и необходимости учитывать множество факторов, влияющих на её состав. Использование этих наборов данных позволяет проверить способность больших языковых моделей (LLM) к работе с реальными, сложными данными, требующими глубокого анализа и понимания предметной области.
В отличие от традиционных бенчмарков, DDR-Bench не предоставляет предварительно сформулированных вопросов или задач для языковых моделей. Это вынуждает LLM самостоятельно определять направления исследования, выдвигать гипотезы и обосновывать логику своих действий. Оценка проводится не по точности ответа на конкретный вопрос, а по способности модели к автономному формированию исследовательского плана, проведению анализа данных и предоставлению аргументированного отчёта о проделанной работе. Такой подход позволяет оценить не только знания модели, но и её способность к критическому мышлению и самостоятельному поиску новой информации.
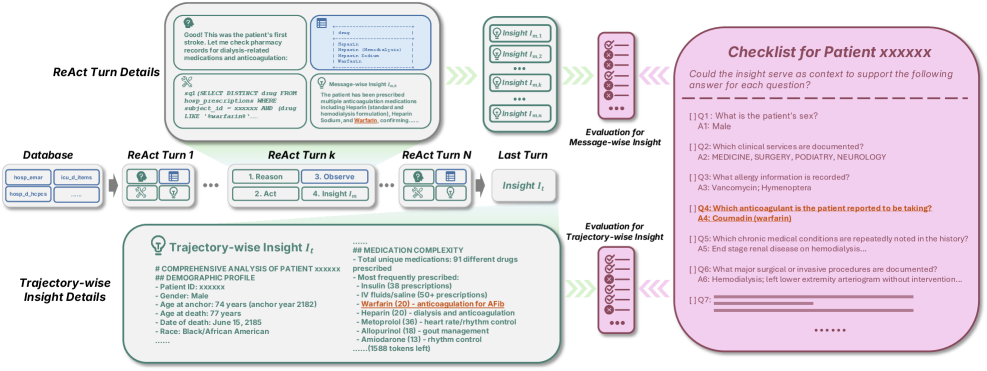
Проверка инсайтов: методы надёжной оценки
В DDR-Bench для проверки фактической точности и полноты полученных результатов используется методика оценок на основе контрольных списков (Checklist-Based Evaluation). Данный подход предполагает наличие заранее определённых критериев и фактов, по которым оценивается соответствие представленных выводов. Контрольные списки охватывают ключевые аспекты данных и предметной области, позволяя систематически выявлять неточности, упущения или несоответствия в ответах языковой модели. Оценка проводится путем сопоставления каждого утверждения с соответствующими пунктами контрольного списка, что обеспечивает количественную и качественную оценку достоверности представленной информации.
Анализ траектории (Trajectory Analysis) представляет собой метод оценки работы языковой модели (LLM), заключающийся в изучении последовательности действий, предпринятых моделью в процессе исследования данных. Данный анализ позволяет отследить логику принятия решений LLM, выявить этапы, на которых происходили изменения в стратегии поиска, и оценить, как каждый шаг влиял на конечный результат. В частности, фиксируется порядок обращения к различным источникам данных, типы запросов, используемые фильтры и логика обработки полученной информации. Это позволяет не только оценить обоснованность полученных выводов, но и выявить потенциальные ошибки в процессе рассуждений, а также оптимизировать стратегию исследования данных для повышения эффективности и надёжности LLM.
В процессе валидации результатов, важным компонентом является использование другой языковой модели в качестве проверяющего (LLM-as-a-Checker). Эта модель оценивает фактическую корректность полученных выводов, выявляя несоответствия и ошибки. Параллельно применяется механизм обнаружения галлюцинаций (Hallucination Detection), который предназначен для идентификации утверждений, не подкреплённых данными или логическими обоснованиями. Данные методы позволяют отфильтровать недостоверную информацию и повысить надёжность аналитических выводов, полученных с помощью больших языковых моделей.
Фреймворк ReAct (Reason + Act) представляет собой архитектуру агента, объединяющую этапы рассуждения и действия в цикле. В рамках этого подхода, агент чередует генерацию мысленных шагов (рассуждений), определяющих дальнейшие действия, и выполнение этих действий в среде. Такая итеративная структура позволяет агенту не только достигать целей, но и предоставлять прозрачную цепочку рассуждений, подтверждающую каждый шаг. Это существенно упрощает отладку и верификацию процесса исследования, поскольку каждый шаг агента непосредственно связан с его предыдущими рассуждениями и предпринятыми действиями, что обеспечивает более надёжный и проверяемый процесс анализа данных.

К агентным LLM: последствия и перспективы
Разработка DDR-Bench и сопутствующих методологий знаменует собой переход от традиционных языковых моделей, ориентированных на выполнение конкретных задач, к агентным моделям, способным к автономным исследованиям. Вместо простого ответа на запрос, такие модели демонстрируют способность самостоятельно формулировать гипотезы, планировать этапы исследования, анализировать полученные данные и делать обоснованные выводы. Это представляет собой фундаментальное изменение парадигмы, открывающее возможности для создания искусственного интеллекта, способного к самостоятельной научной деятельности и решению сложных проблем без непосредственного участия человека. Такой подход позволяет автоматизировать рутинные этапы исследований, ускорить процесс открытия новых знаний и расширить горизонты научных изысканий.
Фундаментальным аспектом перехода к автономным языковым моделям является способность к длительному взаимодействию — поддержанию сложного рассуждения и целенаправленного исследования на протяжении расширенных периодов времени. В отличие от моделей, ориентированных на выполнение отдельных задач, агентные модели требуют не просто обработки информации, но и способности планировать, оценивать результаты и корректировать стратегию в процессе длительного поиска. Именно эта способность к устойчивому мышлению позволяет им успешно решать сложные исследовательские задачи, требующие многоэтапного анализа и синтеза информации. Развитие методов оценки, таких как DDR-Bench, показывает, что модели, демонстрирующие высокую устойчивость в длительном взаимодействии, способны достигать значительных результатов в автономном исследовании, что открывает новые возможности для применения в различных областях, от научных открытий до финансового анализа.
Исследования показали, что модели, такие как Claude 4.5 Sonnet, демонстрируют впечатляющую способность к автономным исследованиям, достигая до 40% точности на бенчмарке DDR-Bench. Этот результат существенно превосходит показатели других исследованных моделей и указывает на значительный прогресс в области создания действительно агентных больших языковых моделей. Высокая точность на DDR-Bench свидетельствует о способности модели эффективно планировать и выполнять сложные исследовательские задачи, самостоятельно собирать и анализировать информацию, а также формулировать обоснованные выводы. Такая производительность открывает перспективы для автоматизации научных исследований, анализа данных и решения сложных проблем, требующих глубокого понимания и способности к самостоятельному обучению.
Исследования показали, что передовые языковые модели, такие как Claude, DeepSeek и GLM, демонстрируют впечатляющую способность к генерации содержательных и валидных идей в процессе автономного исследования. Высокий и устойчивый коэффициент валидных инсайтов указывает на то, что эти модели не просто генерируют большой объём информации, но и обеспечивают высокую информационную плотность в своих ответах. Это означает, что каждая сгенерированная идея или факт с большей вероятностью будет релевантным и полезным для решения поставленной задачи, что критически важно для создания действительно автономных интеллектуальных агентов, способных к глубокому и продуктивному исследованию различных областей знаний.
Исследования показали, что склонность больших языковых моделей к галлюцинациям — то есть генерации неверной или бессмысленной информации — оказывает пренебрежимо малое влияние на их способность решать сложные исследовательские задачи. Анализ данных, полученных в ходе тестирования моделей на DDR-Bench, выявил крайне слабую корреляцию между частотой галлюцинаций и точностью выполнения заданий — коэффициент корреляции составил всего 0.125 при p-value 0.8779 для выборки в 10 000 случаев. Это свидетельствует о том, что модели способны эффективно отфильтровывать недостоверную информацию или компенсировать её влияние в процессе длительного исследования, сохраняя высокую точность и информационную плотность при поиске и анализе данных. Полученные результаты подчеркивают важность развития не только способности моделей к генерации текста, но и их способности к критической оценке и верификации информации.
Метод оценки, использующий большие языковые модели (LLM) в качестве проверяющих, продемонстрировал высокую стабильность и надёжность в различных сценариях. Коэффициент вариации, показатель, отражающий степень разброса результатов, оставался ниже 5% во всех проведённых испытаниях. Это указывает на то, что LLM-как-проверяющий обеспечивает последовательную и воспроизводимую оценку, независимо от конкретных условий или задач. Такая стабильность критически важна для разработки надёжных систем автономных агентов, способных к самостоятельному исследованию и принятию решений, поскольку гарантирует объективность и достоверность получаемых результатов. Данный подход позволяет не только автоматизировать процесс оценки, но и значительно повысить его точность и надёжность.
Развитие интеллекта, направленного на исследование и сбор информации, открывает принципиально новые возможности в различных областях. В научной сфере, подобные системы смогут автономно анализировать огромные объемы данных, выдвигать гипотезы и проводить предварительные исследования, значительно ускоряя темпы открытий. В финансовом анализе, улучшенная способность к расследованию и синтезу информации позволит более точно прогнозировать рыночные тенденции и оценивать риски. Особое значение это имеет в области персонализированной медицины, где системы с развитым интеллектом исследователя смогут анализировать индивидуальные данные пациентов, выявлять закономерности и предлагать наиболее эффективные стратегии лечения, учитывая уникальные особенности каждого организма. Таким образом, совершенствование интеллекта, ориентированного на сбор и анализ данных, является ключевым фактором для прорыва в науке, финансах и здравоохранении.
Дальнейшие исследования направлены на повышение устойчивости и обобщающей способности разработанных методик, что позволит создать по-настоящему автономных AI-исследователей. Усилия сконцентрированы на преодолении ограничений существующих моделей в адаптации к новым задачам и источникам информации, а также на обеспечении надёжности и воспроизводимости результатов в различных условиях. Перспективные направления включают разработку более эффективных алгоритмов поиска и анализа информации, механизмов самокоррекции и валидации знаний, а также создание систем, способных к долгосрочному планированию и принятию решений в условиях неопределенности. Успешная реализация этих задач откроет новые возможности для автоматизации научных исследований, ускорения инноваций и решения сложных проблем в различных областях знания.
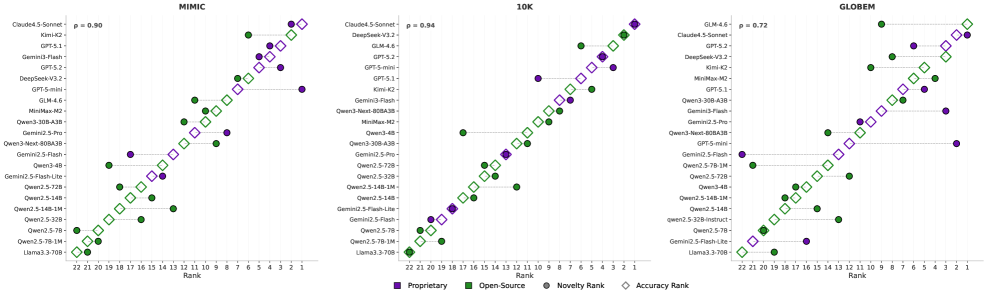
Исследование демонстрирует, что современные большие языковые модели всё ещё далеки от настоящего исследовательского интеллекта. DDR-Bench выявляет их склонность к поверхностному анализу и неспособность к глубокому погружению в данные, что подтверждает старую истину: автоматизация — лишь инструмент, а не панацея. Как говорил Пауль Эрдеш: «Математика — это искусство находить закономерности, а не просто решать задачи». Иными словами, LLM пока умеют решать задачи, но закономерности в данных находят с трудом. Эта работа, по сути, показывает, что даже самые продвинутые модели нуждаются в направлении и критической оценке, иначе они просто перебирают варианты, не вникая в суть. И да, этот «понедельник» для автоматизированного анализа данных уже предсказуем.
Что дальше?
Представленный бенчмарк, DDR-Bench, закономерно пытается оцифровать то, что долгое время оставалось уделом интуиции — способность модели самостоятельно «копаться» в данных. Однако, каждая новая метрика — это лишь приближение к сложной реальности, и не стоит обольщаться, полагая, что «интеллектуальное исследование» можно свести к набору тестов. Оптимизация под DDR-Bench, как и любая другая, неизбежно породит контр-оптимизации, и архитектура, призванная искать истину, рано или поздно начнёт искать лишь проходные баллы.
Более глубокая проблема кроется в самой концепции «автономного исследования». Что есть истинное открытие? Это корреляция, вычисленная алгоритмом, или инсайт, рожденный в контексте человеческого понимания? Искусственный интеллект может находить закономерности, но способен ли он задать правильный вопрос? Более того, каждый «революционный» агент, стремящийся к самообучению, неизбежно столкнётся с проблемой «техдолга» — необходимостью рефакторинга накопленных знаний, когда первоначальные предположения окажутся ошибочными.
В конечном счете, DDR-Bench — это не финишная прямая, а лишь очередной рубеж в бесконечной гонке между теорией и практикой. Это напоминает скорее реанимацию надежды, чем создание полноценного интеллекта. Следующим шагом видится не столько улучшение метрик, сколько разработка методов оценки контекстуальной релевантности полученных знаний, а также учет неизбежных ограничений, накладываемых реальными данными и ресурсами.
Оригинал статьи: https://arxiv.org/pdf/2602.02039.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-03 12:58