Автор: Денис Аветисян
Новое исследование показывает, что современные алгоритмы машинного обучения, используемые для защиты от киберугроз, подвержены атакам, и предлагает способ оценки и повышения их устойчивости.
Анализ устойчивости к состязательным воздействиям и изменение интерпретируемости классификаторов кибербезопасности.
Несмотря на широкое внедрение машинного обучения в системы кибербезопасности, их уязвимость к намеренным, едва заметным изменениям входных данных остается серьезной проблемой. В работе ‘Empirical Analysis of Adversarial Robustness and Explainability Drift in Cybersecurity Classifiers’ представлен эмпирический анализ устойчивости и снижения интерпретируемости моделей, применяемых в задачах классификации фишинговых URL и обнаружения сетевых вторжений. Полученные результаты демонстрируют, что повышение устойчивости к состязательным атакам часто сопровождается ухудшением интерпретируемости, а предложенный индекс устойчивости позволяет количественно оценить этот компромисс. Как можно разработать надежные и прозрачные системы искусственного интеллекта для защиты от постоянно эволюционирующих киберугроз?
Хрупкость современной кибербезопасности: предвестие сбоя
В современной кибербезопасности всё более значимую роль играют модели машинного обучения, которые активно применяются для решения таких задач, как обнаружение фишинговых URL-адресов и выявление сетевых вторжений. Эти алгоритмы, способные анализировать огромные объемы данных и выявлять аномалии, позволяют автоматизировать процессы защиты и оперативно реагировать на возникающие угрозы. Они успешно применяются для фильтрации вредоносного трафика, классификации подозрительной активности и прогнозирования потенциальных атак, значительно повышая эффективность систем безопасности. Вместе с тем, всё большее доверие к этим технологиям требует тщательной оценки их надежности и устойчивости к различным видам атак, поскольку от их корректной работы зависит безопасность критически важной инфраструктуры и данных.
Несмотря на впечатляющую эффективность, современные модели машинного обучения, применяемые в кибербезопасности, оказываются уязвимыми к так называемым «атакам противником». Суть этих атак заключается в создании специально модифицированных входных данных, которые незначительно отличаются от нормальных, но способны вызвать ошибочную классификацию модели. Например, небольшие, практически незаметные изменения в URL-адресе могут привести к тому, что система защиты ошибочно сочтет фишинговый сайт безопасным. Эта уязвимость представляет серьезную угрозу, поскольку злоумышленники могут обходить системы безопасности, эксплуатируя эти слабости, и оставаться незамеченными, маскируя вредоносные действия под безобидные запросы.
Уязвимость моделей машинного обучения представляет собой серьезную угрозу для современных систем безопасности. Злоумышленники могут обойти защиту, используя специально разработанные входные данные, которые приводят к ошибочной классификации. Эти так называемые «атакующие примеры» часто отличаются от обычных данных незначительно, что делает их обнаружение крайне сложным. Использование этих уязвимостей позволяет обходить фильтры спама, обнаруживать вредоносные программы или даже получать несанкционированный доступ к конфиденциальной информации, подрывая доверие к цифровым системам и ставя под угрозу безопасность пользователей и организаций. Подобные атаки демонстрируют, что надежность систем безопасности напрямую зависит от устойчивости применяемых алгоритмов к манипуляциям.
Искусство обмана: как работают состязательные атаки
Адверсарная возмущающая обработка (Adversarial Perturbation) заключается во внесении незначительных, зачастую незаметных для человеческого глаза, изменений в исходные входные данные. Эти изменения, как правило, представляют собой небольшие возмущения, добавляемые к значениям пикселей в изображениях или к числовым значениям в других типах данных. Несмотря на свою малость, эти возмущения способны привести к ошибочной классификации входных данных моделью машинного обучения, даже если модель демонстрирует высокую точность на корректных данных. Важно отметить, что эти возмущения могут быть рассчитаны алгоритмически, чтобы максимизировать вероятность ошибки модели, а не быть случайными.
Для генерации возмущений, используемых в adversarial атаках, применяются алгоритмы, такие как FGSM (Fast Gradient Sign Method) и PGD (Projected Gradient Descent). FGSM вычисляет градиент функции потерь модели по отношению к входным данным и добавляет небольшое возмущение в направлении знака этого градиента, максимизируя ошибку модели. PGD является итеративным методом, который многократно применяет небольшие возмущения, проецируя результат на допустимую область, что позволяет найти более сильные adversarial примеры. Оба алгоритма систематически исследуют пространство входных данных для определения минимальных изменений, необходимых для приведения модели к ошибочному предсказанию.
Эффективность атак на основе состязательных возмущений демонстрирует недостаточную устойчивость современных моделей машинного обучения, даже при высокой точности на чистых данных. Несмотря на впечатляющие результаты на стандартных тестовых наборах, незначительные, намеренные изменения во входных данных могут привести к ошибочным предсказаниям. Этот феномен указывает на то, что модели часто полагаются на поверхностные корреляции в данных, а не на истинные признаки, что делает их уязвимыми к манипуляциям. Устойчивость к таким атакам является критически важным аспектом для применения моделей машинного обучения в критически важных системах, таких как автономное вождение и медицинская диагностика, где даже небольшие ошибки могут иметь серьезные последствия.
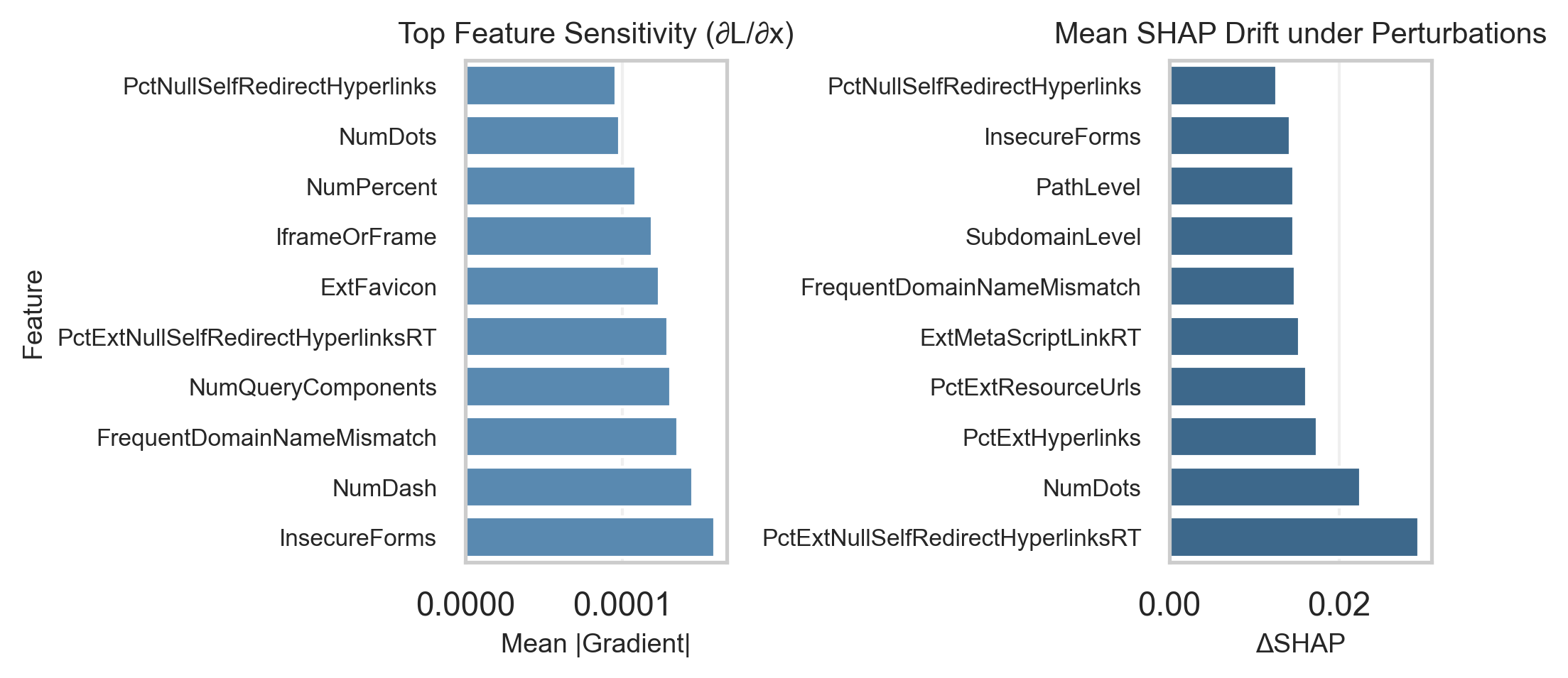
Раскрытие скрытой нестабильности: чувствительность к признакам и отклонение атрибуции
Чувствительность к признакам (Feature Sensitivity) оценивает степень изменения выходных данных модели при небольших изменениях входных признаков. Этот показатель позволяет определить, насколько сильно модель полагается на конкретные входные данные для принятия решений. Высокая чувствительность к определенному признаку указывает на то, что даже незначительное изменение этого признака может привести к существенному изменению предсказания модели. Анализ чувствительности к признакам является важным инструментом для понимания поведения модели и выявления потенциальных проблем, связанных с чрезмерной зависимостью от определенных входных данных, что может указывать на нестабильность или предвзятость модели.
Значения SHAP (SHapley Additive exPlanations) представляют собой метод интерпретации машинного обучения, основанный на теории игр. Они позволяют определить вклад каждой входной характеристики в конкретное предсказание модели. По сути, значения SHAP рассчитывают средний вклад каждой характеристики путем рассмотрения всех возможных комбинаций характеристик. Для каждой характеристики рассчитывается её влияние на предсказание, усредненное по всем возможным подмножествам других характеристик. Результатом является вектор значений SHAP, где каждое значение показывает, насколько вклад конкретной характеристики отклоняется от её среднего вклада по всему набору данных. Положительные значения SHAP указывают на то, что характеристика способствовала увеличению предсказания, а отрицательные — на уменьшение. Абсолютное значение SHAP показывает силу влияния данной характеристики.
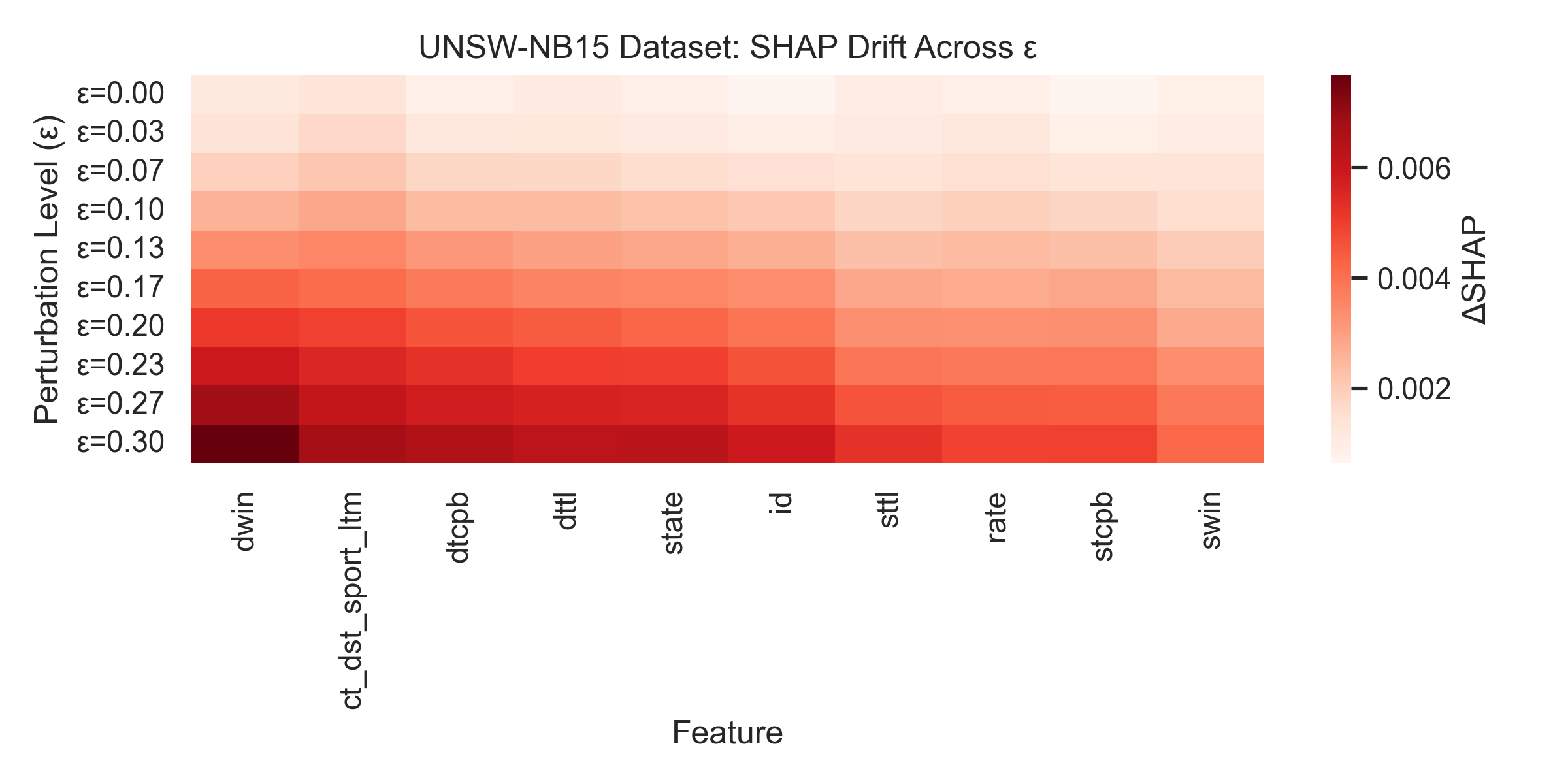
Дрифт атрибуции SHAP, проявляющийся как изменение значений SHAP при небольших, намеренных искажениях входных данных (adversarial perturbations), указывает на нестабильность важности признаков. Это означает, что признаки, которые модель считает наиболее значимыми для конкретного предсказания, могут быстро потерять эту значимость при незначительных изменениях входных данных. Подобная нестабильность ставит под сомнение надежность и достоверность объяснений, предоставляемых моделью, поскольку важность признаков не является устойчивой характеристикой, а зависит от конкретной реализации входных данных и может быть подвержена манипуляциям.
Построение устойчивых систем: к надежному машинному обучению
Адиверсативная тренировка (Adversarial Training) представляет собой эффективный метод повышения устойчивости моделей машинного обучения к намеренным искажениям входных данных. Суть подхода заключается в добавлении в обучающую выборку специально сгенерированных примеров — адиверсативных примеров — которые незначительно отличаются от исходных данных, но способны вызвать ошибочную классификацию. В процессе обучения модель подвергается воздействию как обычных, так и адиверсативных примеров, что позволяет ей научиться игнорировать незначительные возмущения и фокусироваться на существенных признаках, повышая тем самым свою устойчивость к атакам и общую надежность.
Применение методов предварительной обработки данных, таких как Z-нормализация, к моделям машинного обучения, в частности к многослойным персептронам (MLP), способствует повышению их производительности и стабильности. Z-нормализация стандартизирует данные, приводя их к нулевому среднему и единичному стандартному отклонению, что позволяет избежать доминирования признаков с большими значениями и ускорить процесс обучения. Это особенно важно для моделей MLP, чувствительных к масштабу входных данных, поскольку позволяет оптимизировать веса сети и улучшить обобщающую способность модели на новых данных. Отсутствие нормализации может приводить к неустойчивости обучения и снижению точности прогнозов.
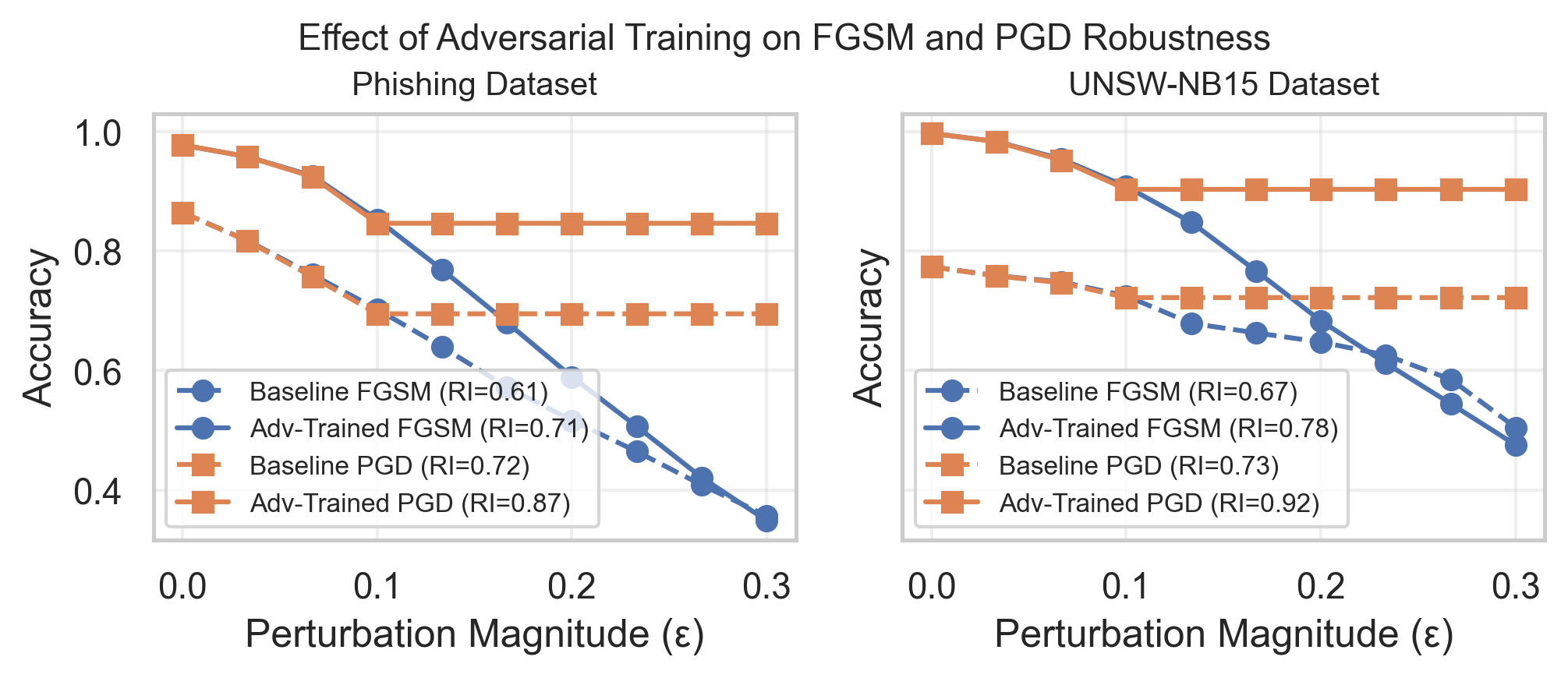
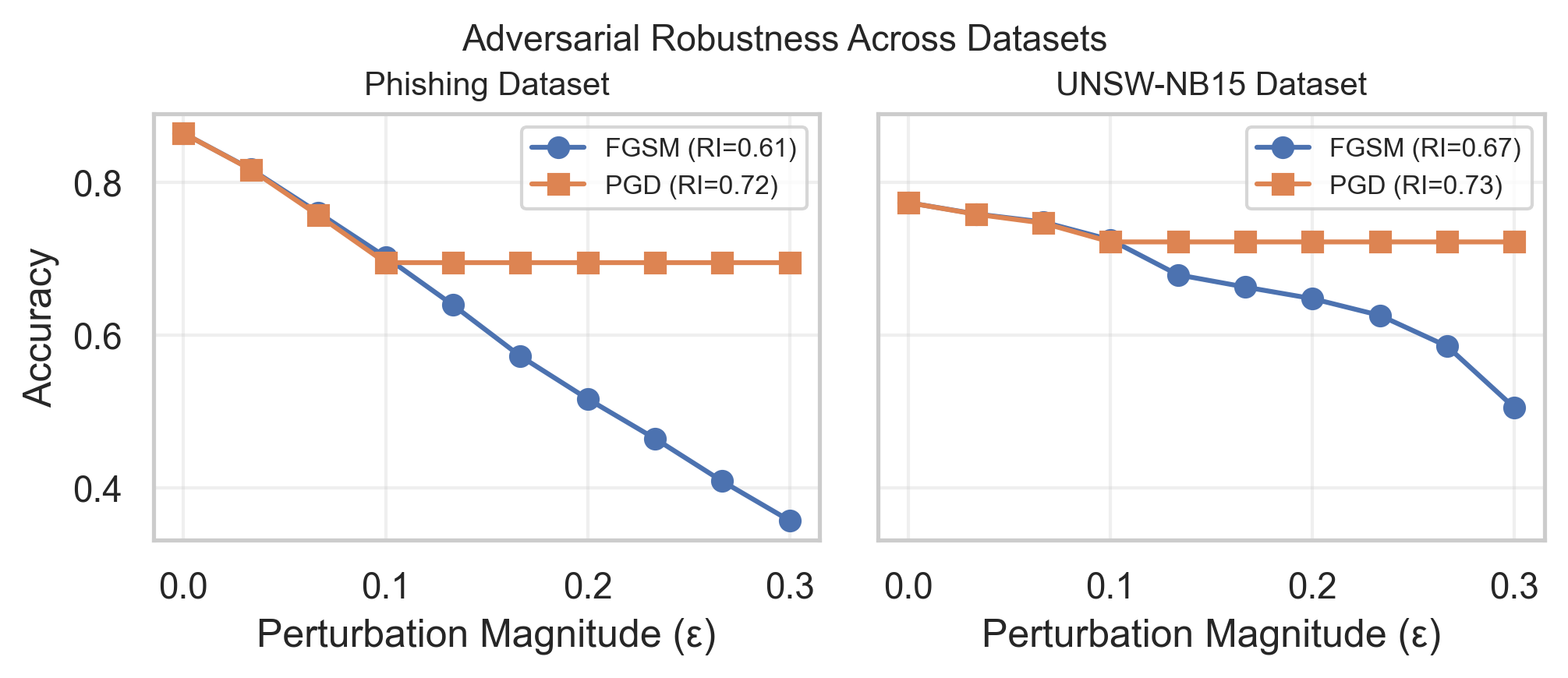
Для оценки устойчивости моделей машинного обучения к состязательным атакам был разработан Индекс Устойчивости (Robustness Index, RI). Этот индекс предоставляет стандартизированную метрику для сравнительного анализа устойчивости различных моделей. Проведенные исследования показали, что применение состязательного обучения (adversarial training) позволяет увеличить RI до 0.19 на наборах данных, используемых для обнаружения фишинговых сайтов и сетевых вторжений. В частности, для фишинговых сайтов наблюдалось увеличение RI на 0.10 при атаке FGSM и на 0.15 при атаке PGD. Для набора данных UNSW-NB15, используемого для обнаружения вторжений, увеличение RI составило 0.11 при атаке FGSM и 0.19 при атаке PGD, что подтверждает эффективность состязательного обучения в повышении устойчивости моделей.
В ходе экспериментов с использованием метода Adversarial Training наблюдалось повышение Robustness Index (RI) для различных наборов данных и атак. Для веб-сайтов, классифицируемых как фишинговые, прирост RI составил 0.10 при атаке FGSM и 0.15 при атаке PGD. Для набора данных UNSW-NB15, предназначенного для обнаружения вторжений, RI увеличился на 0.11 при атаке FGSM и на 0.19 при атаке PGD. Данные результаты демонстрируют эффективность Adversarial Training в повышении устойчивости моделей машинного обучения к различным типам adversarial атак.
Перспективы развития: обеспечение безопасности следующего поколения ИИ
Необходимость в усовершенствовании методов состязательного обучения (Adversarial Training) обусловлена их вычислительной сложностью и ограниченной масштабируемостью. Текущие подходы зачастую требуют значительных ресурсов для обработки больших объемов данных, что препятствует их применению в реальных условиях. Исследования направлены на разработку более эффективных алгоритмов, которые позволят снизить вычислительные затраты и повысить скорость обучения, не жертвуя при этом надежностью и точностью моделей. Особое внимание уделяется методам, позволяющим обобщать полученные знания и эффективно противостоять новым, ранее неизвестным атакам, что критически важно для обеспечения безопасности и стабильности систем искусственного интеллекта в динамично меняющейся цифровой среде.
Для подтверждения практической ценности разработанных методов повышения устойчивости искусственного интеллекта к враждебным атакам, необходимо их тестирование на реальных наборах данных в сфере кибербезопасности. В частности, такие датасеты, как UNSW-NB15, содержащий записи сетевого трафика, и наборы данных, содержащие информацию о фишинговых веб-сайтах, предоставляют возможность оценить эффективность этих методов в условиях, приближенных к реальным угрозам. Анализ результатов на этих данных позволит выявить слабые места и оптимизировать алгоритмы, обеспечивая более надежную защиту от атак, направленных на обход систем обнаружения вторжений и обман пользователей. Применение этих техник к разнообразным наборам данных кибербезопасности является ключевым шагом на пути к созданию действительно устойчивых и надежных систем искусственного интеллекта.
Разработка искусственного интеллекта, ориентированного на устойчивость и понятность, становится ключевым фактором обеспечения безопасного цифрового будущего. Недостаточно создавать мощные алгоритмы; необходимо, чтобы эти алгоритмы были способны надежно функционировать в условиях непредсказуемых атак и изменений данных. Повышенная интерпретируемость позволяет понять логику принятия решений ИИ, что критически важно для выявления и устранения потенциальных уязвимостей и ошибок. Приоритет устойчивости и понятности не только повышает надежность систем искусственного интеллекта, но и способствует укреплению доверия к ним, открывая новые возможности для их применения в критически важных областях, таких как кибербезопасность, здравоохранение и автономные системы.
Исследование демонстрирует уязвимость систем машинного обучения в сфере кибербезопасности к намеренным возмущениям, что заставляет переосмыслить подходы к их построению. Подобно тому, как архитекторы сталкиваются с неизбежностью будущих сбоев, создатели этих систем должны признать, что абсолютной защиты не существует. Г.Х. Харди однажды заметил: «Математика — это наука о неточностях». Эта фраза, как нельзя лучше отражает суть работы: стремление к совершенству в мире алгоритмов — иллюзия. Анализ, представленный в статье, подчеркивает взаимосвязь между устойчивостью модели и её интерпретируемостью, демонстрируя, что каждое изменение в архитектуре — это своего рода пророчество о потенциальных уязвимостях. Система не строится, она растёт, и каждый её элемент несёт в себе отпечаток будущих компромиссов.
Что же дальше?
Представленное исследование, словно карта звездного неба, указывает на неизбежность дрейфа. Не дрейфа в смысле улучшения, но в смысле изменения — непредсказуемого и постоянного. Устойчивость к враждебным воздействиям и объяснимость, кажущиеся двумя сторонами одной медали, оказываются лишь иллюзией стабильности. Каждое усовершенствование защиты — это, по сути, пророчество о новом, более изощренном нападении. Система не становится сильнее, она лишь приобретает новые уязвимости, скрытые под маской кажущейся неуязвимости.
Не стоит стремиться построить “непробиваемую” систему. Это напоминает попытку остановить течение времени. Гораздо продуктивнее — выращивать экосистему, способную к самовосстановлению и адаптации. Фокус должен сместиться с абсолютной защиты на скорость обнаружения и реагирования на аномалии. Если система молчит, это не значит, что она надежна — это значит, что она готовит сюрприз.
Вместо поиска “идеального” алгоритма, следует признать, что отладка никогда не закончится. Она лишь перейдет в фазу скрытого наблюдения. Анализ чувствительности признаков и оценка объяснимости — это не конечные цели, а бесконечный процесс, требующий постоянного внимания и переосмысления. Ибо, в конечном итоге, любая система — это лишь отражение сложности мира, в котором она существует.
Оригинал статьи: https://arxiv.org/pdf/2602.06395.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-09 20:24