Автор: Денис Аветисян
Новый подход позволяет повысить качество синтетических данных для обучения моделей распознавания намерений, фокусируясь на устранении двусмысленности.
Предложена итеративная методика DDAIR, использующая Sentence Transformers и большие языковые модели для выявления и перегенерации неоднозначных синтетических запросов, что повышает точность распознавания намерений.
Несмотря на эффективность больших языковых моделей (LLM) в задаче аугментации данных для классификации интентов, сгенерированные ими примеры могут быть неоднозначными и приводить к ошибкам. В работе ‘How DDAIR you? Disambiguated Data Augmentation for Intent Recognition’ предложен метод DDAIR, использующий Sentence Transformers для выявления и исправления неоднозначных синтетических примеров, генерируемых LLM в условиях ограниченных ресурсов. Показано, что итеративное перегенерирование примеров с использованием векторных представлений предложений позволяет значительно улучшить качество данных и повысить точность распознавания интентов. Не приведет ли данный подход к созданию более надежных и устойчивых систем понимания естественного языка в задачах, где границы между интентами размыты?
Проблема Ограниченных Данных в Распознавании Намерений
Для достижения высокой точности в распознавании намерений пользователя требуется значительный объем размеченных данных, что представляет собой существенную проблему, особенно в узкоспециализированных областях или при работе с нюансированными запросами. Процесс ручной разметки является трудоемким и дорогостоящим, требующим привлечения квалифицированных лингвистов или экспертов в предметной области. Это создает серьезные препятствия для разработки и внедрения систем распознавания намерений в новых доменах или для редких, но важных типов запросов, где доступность размеченных данных ограничена. Фактически, стоимость сбора и подготовки данных зачастую превышает стоимость разработки самой модели, что существенно замедляет прогресс в данной области и ограничивает возможности масштабирования систем.
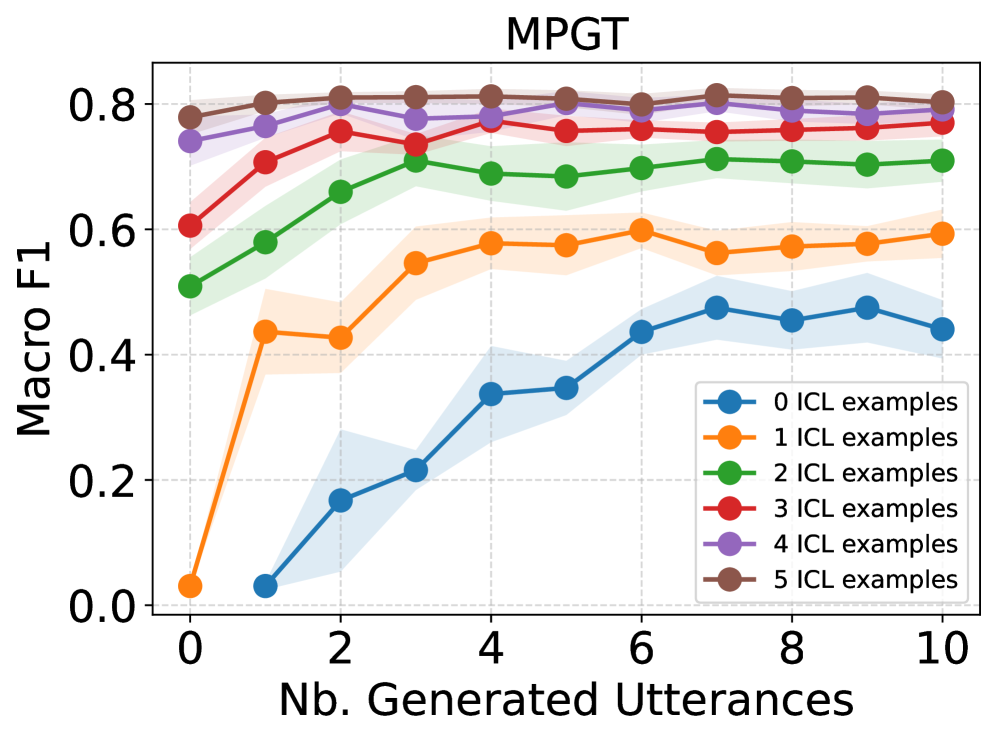
Существующие методы распознавания намерений, такие как те, что используют корпуса CLINC150, MPGT и BANKING77, демонстрируют ограниченную способность к обобщению в условиях недостатка данных. Эти модели, обученные на больших объемах размеченных данных, часто испытывают трудности при применении к новым доменам или задачам, где количество доступных примеров значительно меньше. Неспособность эффективно адаптироваться к низкоресурсным сценариям проявляется в снижении точности и надежности распознавания намерений, что ограничивает их практическое применение в специализированных областях, где сбор обширных размеченных данных является сложной или дорогостоящей задачей. Проблема усугубляется разнообразием лингвистических конструкций и контекстов, которые модели не могут адекватно охватить при ограниченном количестве обучающих примеров.
Исследования показывают, что производительность современных моделей обработки естественного языка, таких как BERT, часто достигает плато при работе с ограниченными объемами данных. Оценка с использованием метрики Macro-F1 Score демонстрирует, что прирост точности в условиях дефицита данных, как правило, не превышает 2-3%, что существенно ограничивает их применимость в реальных сценариях. Данное явление связано с тем, что модели, обученные на больших объемах данных, испытывают трудности с обобщением и адаптацией к новым, незнакомым запросам при недостатке обучающих примеров. Таким образом, проблема ограниченности данных становится ключевым препятствием для широкого внедрения передовых технологий распознавания намерений в специализированных областях и повседневных приложениях.
Синтетические Данные: Мощный Инструмент Расширения
Синтетические данные представляют собой перспективное решение проблемы нехватки данных для обучения моделей машинного обучения. Искусственное расширение обучающих наборов позволяет увеличить объем доступной информации, что особенно важно для задач, где сбор и аннотация реальных данных затруднены или дорогостоящи. Увеличение размера обучающей выборки посредством синтетических данных способствует повышению устойчивости модели к обобщениям, снижению переобучения и улучшению ее способности к корректной работе с новыми, ранее не встречавшимися примерами. В частности, это актуально для моделей, требующих большого объема данных для достижения высокой точности, таких как системы обработки естественного языка и компьютерного зрения.
В настоящее время для генерации синтетических данных всё чаще используются большие языковые модели (LLM). Однако, прямое, «наивное» генерирование данных без дополнительных механизмов контроля часто приводит к введению неоднозначности и снижению производительности моделей, обучаемых на этих данных. Это обусловлено тем, что LLM могут генерировать примеры, которые грамматически корректны, но семантически неточны, нерелевантны задаче или содержат противоречия, что негативно сказывается на качестве обучения и обобщающей способности итоговой модели.
Эффективная генерация синтетических данных требует применения методов контроля качества и релевантности генерируемых высказываний для предотвращения внесения вводящих в заблуждение или нерелевантных примеров. Это достигается посредством использования различных техник, таких как фильтрация по метрикам правдоподобия, проверка на соответствие заданным критериям (например, грамматической корректности и семантической согласованности), а также применение алгоритмов, оценивающих степень соответствия сгенерированных данных исходному распределению реальных данных. Важным аспектом является автоматизированная оценка качества с использованием метрик, специфичных для конкретной задачи (например, BLEU, ROUGE для задач генерации текста), и последующая отбраковка примеров, не соответствующих заданным порогам. Также применяются методы активного обучения, при которых модель самостоятельно выбирает наиболее информативные примеры для генерации, что позволяет оптимизировать процесс и повысить качество синтетического набора данных.
DDAIR: Обнаружение и Исправление Неоднозначности в Синтетических Данных
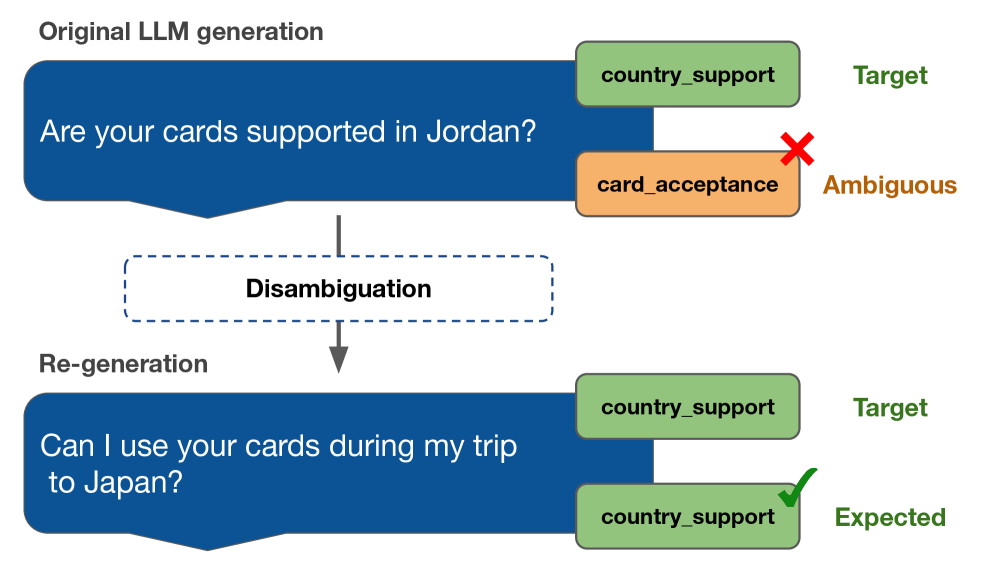
Система DDAIR использует Sentence Transformers для выявления потенциально неоднозначных высказываний в сгенерированных синтетических данных. Sentence Transformers — это предварительно обученные модели, преобразующие текст в векторные представления, позволяющие оценивать семантическую схожесть между высказываниями. DDAIR применяет эти модели для расчета векторных представлений каждого высказывания в синтетическом наборе данных и выявления тех, которые имеют низкую степень семантической определенности или высокую схожесть с другими высказываниями, что может привести к ошибкам классификации. Выявленные неоднозначные высказывания помечаются для последующей перегенерации.
DDAIR использует большие языковые модели (LLM) для перегенерации двусмысленных высказываний, обнаруженных в синтетических данных. В процессе перегенерации применяется обучение с контекстным обучением (In-Context Learning), при котором LLM предоставляется небольшое количество примеров желаемого формата и содержания. Это позволяет модели адаптироваться к конкретным требованиям задачи и генерировать более чёткие и релевантные высказывания, устраняя неоднозначность исходных данных. Использование In-Context Learning обеспечивает направленную перегенерацию, фокусируясь на повышении ясности и снижении вероятности классификационных ошибок.
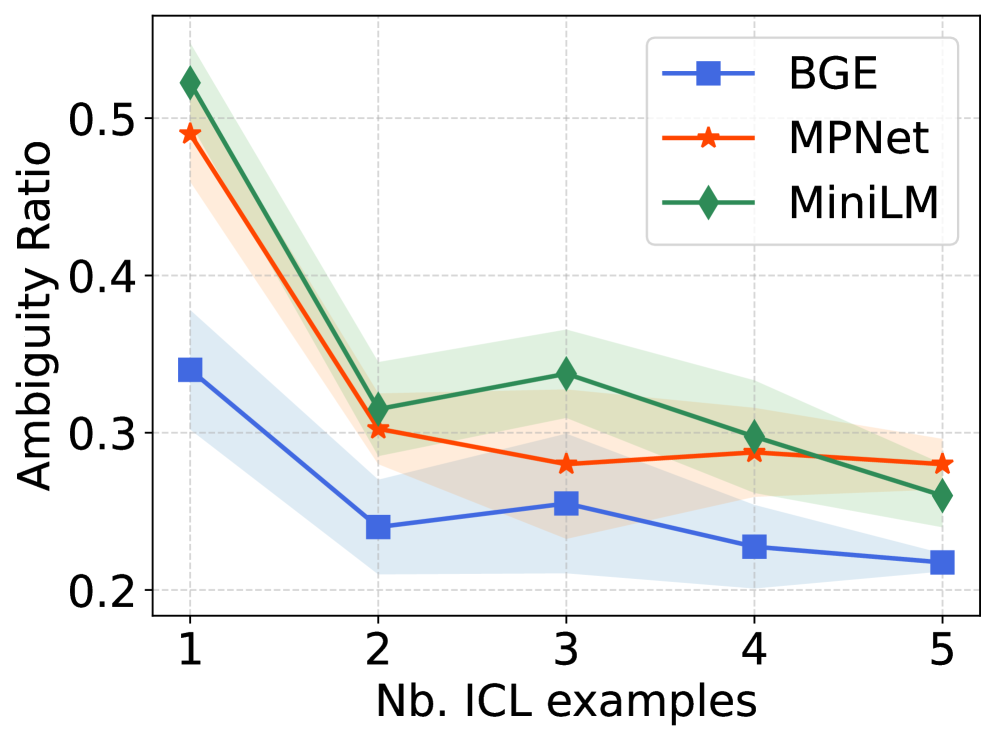
Итеративный процесс, используемый в DDAIR, демонстрирует повышение качества синтетических данных и, как следствие, улучшение производительности в сценариях малого количества размеченных данных (Few-Shot Learning). После каждого этапа устранения неоднозначности наблюдается снижение коэффициента неоднозначности (ambiguity ratio), что количественно подтверждает улучшение ясности и релевантности генерируемых примеров. Этот показатель, измеряемый после каждой итерации, служит метрикой эффективности процесса disambiguation и указывает на последовательное улучшение качества синтетического набора данных, необходимого для обучения моделей при ограниченном объеме размеченных данных.
Оценка DDAIR: Метрики Качества и Прирост Производительности
Качество генерируемых синтетических данных оценивалось с использованием метрики, известной как коэффициент силуэта. Данный показатель позволяет количественно оценить, насколько сгенерированные речевые образцы соответствуют предполагаемому намерению, то есть, насколько близко они по смыслу к тем, которые должны быть сгенерированы для конкретной цели. Высокий коэффициент силуэта указывает на то, что сгенерированные данные хорошо кластеризуются вокруг целевого намерения, что свидетельствует об их релевантности и полезности для обучения моделей обработки естественного языка. По сути, данный показатель служит индикатором того, насколько «правдоподобны» и «согласованы» синтетические данные с точки зрения семантической близости к исходному намерению.
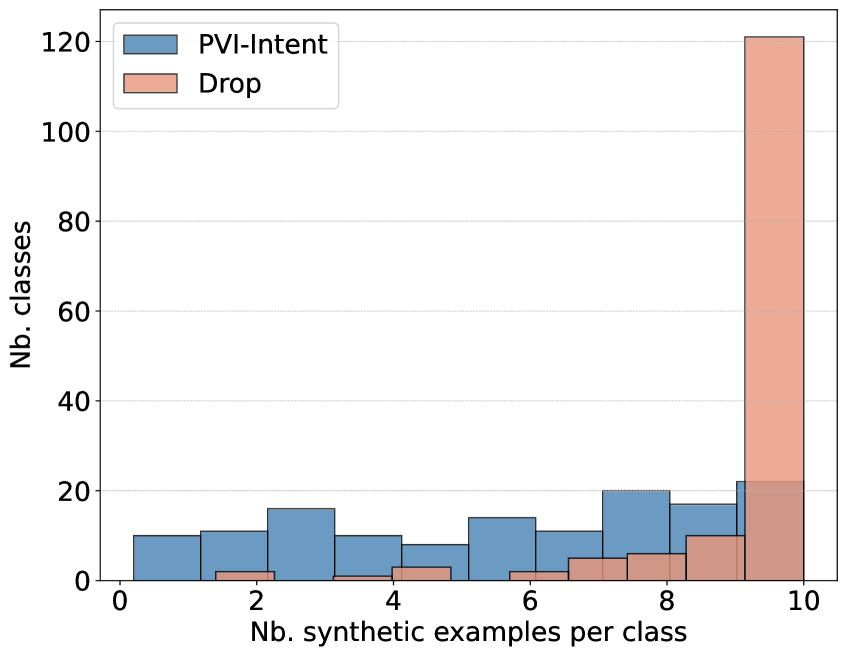
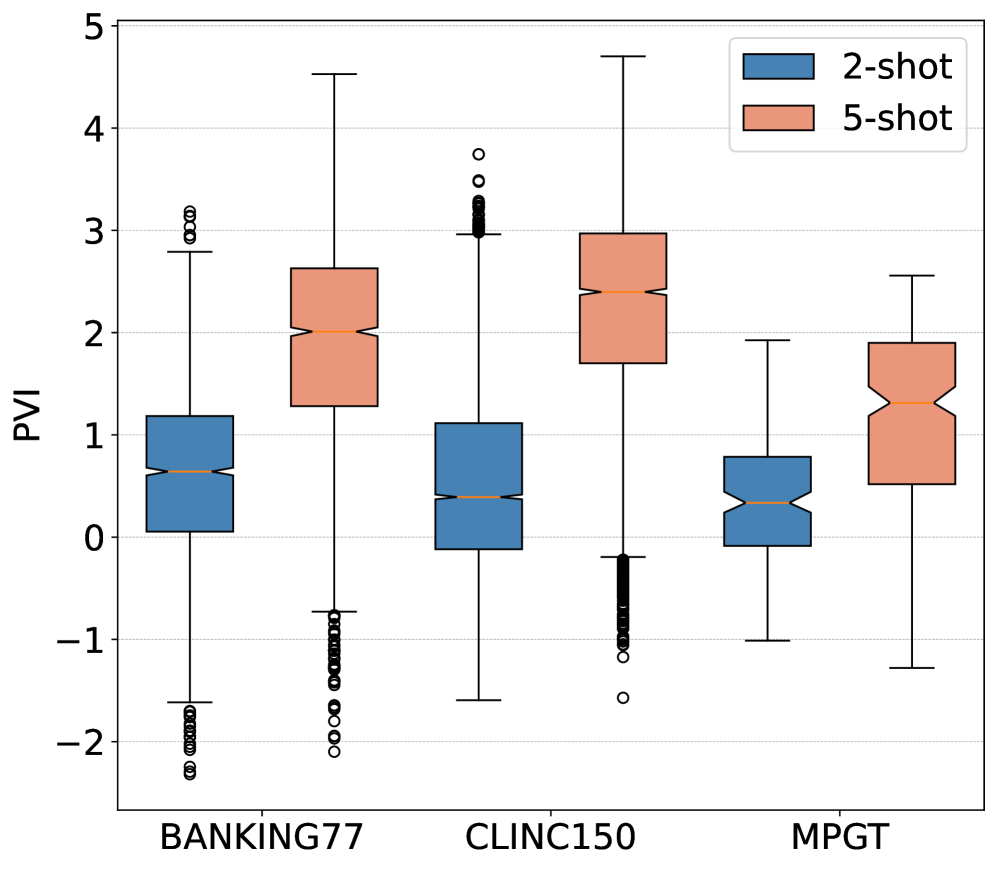
Для оценки информативности сгенерированных данных в контексте классификации намерений используется метрика PVI (Pointwise V-Information). Суть PVI заключается в измерении того, насколько хорошо каждое сгенерированное высказывание способствует различению между различными намерениями. Более высокие значения PVI указывают на то, что сгенерированные данные содержат больше полезной информации для точной классификации, что позволяет моделям лучше различать тонкие нюансы между разными запросами пользователей. Таким образом, PVI служит ключевым индикатором качества синтетических данных, подчеркивая их ценность для улучшения производительности систем распознавания намерений, особенно в ситуациях, когда доступ к реальным данным ограничен.
Исследования показали, что разработанная система DDAIR генерирует синтетические данные высокого качества, что приводит к заметному улучшению результатов в задачах распознавания намерений. Особенно выражен положительный эффект в условиях ограниченного объема исходных данных, где наблюдается увеличение показателя Macro-F1 до 6% на корпусе MPGT. При этом, после каждого этапа уточнения (disambiguation), стабильно растет коэффициент Silhouette, подтверждающий повышение качества и согласованности сгенерированных данных. Такие результаты свидетельствуют о потенциале DDAIR для эффективного дополнения обучающих выборок и повышения точности систем понимания естественного языка даже при недостатке реальных данных.
Исследование демонстрирует, что даже самые передовые модели требуют качественных данных для эффективной работы. Авторы предлагают итеративный подход DDAIR, фокусируясь на выявлении и устранении неоднозначности в синтетических данных, что позволяет повысить точность распознавания намерений. Этот процесс напоминает декомпиляцию сложной системы: необходимо разобрать её на части, понять логику работы и исправить ошибки. Как однажды заметил Карл Фридрих Гаусс: «Если бы я знал, что умру завтра, я бы потратил его на изучение математики». Ведь понимание фундаментальных принципов, будь то математика или обработка естественного языка, позволяет взломать любую задачу, устраняя неточности и выявляя скрытые закономерности. Каждый «патч» в алгоритме — это признание сложности и несовершенства системы, и стремление к более элегантному решению.
Куда же дальше?
Представленная методика DDAIR, безусловно, демонстрирует потенциал в очистке синтетических данных для распознавания намерений. Однако, следует признать, что обнаружение и устранение неоднозначности — это не просто техническая задача, а скорее философский вызов. Итеративное улучшение данных — лишь приближение к идеалу, ведь сама природа языка допускает множественность интерпретаций. Вопрос в том, насколько далеко можно зайти в автоматической «разборке» этой многозначности, не потеряв при этом тонкие нюансы смысла.
Следующим шагом видится не просто увеличение объема аугментированных данных, а разработка более глубоких моделей понимания контекста. Возможно, стоит обратить внимание на интеграцию с системами знаний, позволяющими оценивать не только синтаксическую, но и семантическую правдоподобность сгенерированных предложений. Или же, напротив, следует исследовать намеренное внесение контролируемой «шумности» в данные, чтобы модели научились устойчивости к нечетким запросам — ведь реальный пользователь редко формулирует свои намерения идеально.
В конечном итоге, успех в этой области зависит не от совершенства алгоритмов, а от готовности признать, что «идеальные» данные — это миф. Задача исследователя — не «починить» язык, а понять его хаотичную, непредсказуемую природу, и научить машины работать в этих условиях. И тогда, возможно, мы увидим системы, способные не просто распознавать намерения, а действительно понимать, что от них хотят.
Оригинал статьи: https://arxiv.org/pdf/2601.11234.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-01-21 00:05