Автор: Денис Аветисян
Новый подход к построению нейронных сетей позволяет им надежно распознавать объекты даже в условиях незнакомых изменений и искажений.
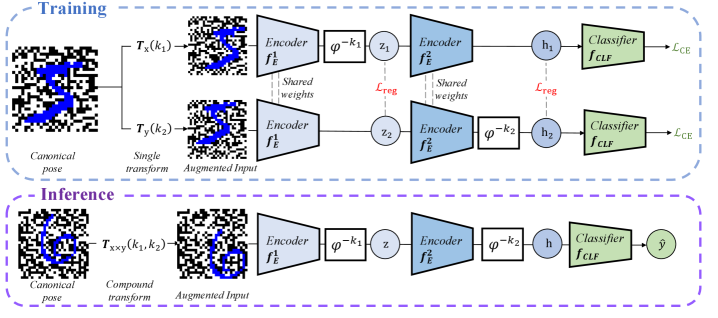
В статье рассматриваются латентные эквивариантные операторы, обеспечивающие обобщение моделей при работе с данными, отличными от обучающей выборки, и устойчивость к трансформационным изменениям изображений.
Несмотря на успехи глубокого обучения в компьютерном зрении, распознавание объектов, подвергшихся симметричным преобразованиям, редко встречающимся в обучающих данных, остается сложной задачей. В работе ‘Latent Equivariant Operators for Robust Object Recognition: Promise and Challenges’ исследуется подход, основанный на обучении скрытых эквивариантных операторов, позволяющий сетям обобщать данные при различных преобразованиях без априорных знаний о них. Показано, что предложенная архитектура успешно справляется с классификацией данных, полученных из внераспределительного набора, превосходя традиционные и эквивариантные сети на задачах распознавания изображений с шумом и поворотами. Какие перспективы открываются для масштабирования данной архитектуры на более сложные и реалистичные наборы данных?
Почему нейронные сети так легко обмануть?
Несмотря на впечатляющие успехи в распознавании изображений, глубокие нейронные сети часто демонстрируют ограниченную способность к обобщению на данные, отличающиеся от тех, на которых они обучались. Эта проблема, известная как «вне-распределительное обобщение», проявляется в виде внезапного снижения точности при незначительных изменениях входных данных, таких как изменение освещения, угла обзора или небольшие искажения. Существующие сети, как правило, «запоминают» признаки, характерные для обучающего набора, вместо того, чтобы формировать истинное понимание сути изображаемых объектов. В результате, даже незначительные отклонения от привычного формата могут привести к ошибочным предсказаниям, что ограничивает их применение в реальных условиях, где входные данные редко бывают идеальными или полностью совпадают с обучающими примерами.
Хрупкость глубоких нейронных сетей при столкновении с незнакомыми данными обусловлена их чрезмерной чувствительностью к вариациям входных данных, особенно к изменениям позы и угла обзора. Исследования показывают, что сети часто не способны обобщить знания, полученные на одном наборе данных, на слегка измененные изображения, что указывает на отсутствие настоящего понимания, а не просто запоминания паттернов. Вместо того чтобы выделять фундаментальные свойства объектов, сети склонны фиксироваться на поверхностных деталях, таких как конкретная ориентация или освещение. Это приводит к тому, что даже небольшие отклонения от привычных условий могут вызывать значительные ошибки в предсказаниях, демонстрируя, что сети, по сути, не “видят” объекты, а лишь распознают пиксельные конфигурации.
Традиционные методы, такие как увеличение обучающей выборки путем применения различных преобразований к изображениям, направлены на повышение устойчивости глубоких нейронных сетей к изменениям входных данных. Однако, для достижения реальной обобщающей способности, необходимо охватить абсолютно все возможные вариации — изменения в освещении, ракурсе, позе объекта и многие другие. Полное перечисление и моделирование всех этих трансформаций практически невозможно, поскольку количество потенциальных изменений бесконечно. Это создает значительную проблему, поскольку даже исчерпывающий набор преобразований, кажущийся полным, может оказаться недостаточным при столкновении с совершенно новыми, ранее не встречавшимися ситуациями, что демонстрирует ограниченность подхода, основанного исключительно на увеличении объема данных.
Симметрия и инвариантность: как заставить сеть “понимать”
Теория групп предоставляет математический аппарат для описания преобразований, таких как вращение, трансляция и масштабирование, обеспечивая принципиальный способ определения инвариантности. В рамках этой теории, преобразования рассматриваются как элементы группы, а инвариантность определяется как свойство объекта оставаться неизменным при применении этих преобразований. Математически, группа определяется как множество элементов с операцией, удовлетворяющей четырем аксиомам: замкнутость, ассоциативность, наличие нейтрального элемента и наличие обратного элемента. Применение теории групп позволяет формально определить, какие свойства данных остаются неизменными при определенных преобразованиях, что критически важно для разработки алгоритмов, устойчивых к изменениям в данных, например, в задачах компьютерного зрения и робототехники. G обозначает группу, а ρ — ее представление.
Явное моделирование трансформаций, таких как вращение и изменение положения, позволяет создавать нейронные сети, устойчивые к изменениям точки зрения и позы объекта. Это достигается за счет включения в архитектуру сети слоев или механизмов, которые учитывают эти преобразования, например, с помощью сверточных нейронных сетей, инвариантных к трансляции, или за счет использования групповых сверток. Такой подход позволяет сети обобщать информацию, полученную из данных, представленных в различных ориентациях и положениях, что существенно повышает ее производительность и надежность при обработке новых, ранее не встречавшихся данных. В результате, сеть становится менее чувствительной к конкретному представлению входных данных и более способной извлекать значимые признаки, независимо от их положения или ориентации.
Для реализации инвариантности к преобразованиям необходимо понимание влияния этих преобразований на структуру данных и их математическое представление. Преобразования, такие как вращение, трансляция и масштабирование, изменяют координаты точек в пространстве данных. Группы преобразований, описываемые в математике, позволяют формально определить эти изменения и их комбинации. Математически, преобразование можно представить как функцию T: X \rightarrow X, отображающую элемент x из пространства данных X в другой элемент того же пространства. Понимание алгебраических свойств этих групп, включая операции композиции и обратных преобразований, критически важно для разработки моделей, устойчивых к изменениям представления данных.
Скрытое пространство: учим сеть не обращать внимания на «мелочи»
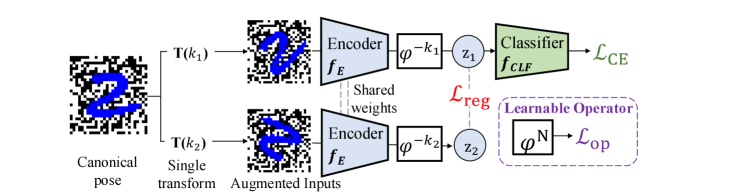
Методы латентной эквивариантности (Latent Equivariant Operator Methods) представляют собой эффективное решение для задач, требующих учета симметрий и преобразований данных. Они позволяют обучать операторы, действующие в латентном пространстве, которые сохраняют инвариантность или эквивариантность относительно определенной группы преобразований. Вместо явного задания правил преобразования, эти методы извлекают их из примеров данных, что позволяет им адаптироваться к сложным и нелинейным зависимостям. В результате, модель может обобщать знания на новые, ранее не встречавшиеся данные, подверженные тем же преобразованиям, обеспечивая устойчивость и эффективность в различных приложениях, таких как обработка изображений и видео, робототехника и молекулярное моделирование.
Для преобразования входных данных в латентное пространство используется линейный энкодер. Этот энкодер сопоставляет исходные данные с векторами в латентном пространстве, где оператор сдвига выполняет выравнивание представлений к канонической позе. Оператор сдвига позволяет нормализовать представления, устраняя вариации, связанные с положением или ориентацией объекта во входном пространстве, что способствует повышению устойчивости и обобщающей способности модели. Линейность энкодера упрощает обучение и позволяет эффективно использовать информацию о групповых преобразованиях.
Функция потерь, обеспечивающая согласованность представлений (representation consistency loss), играет ключевую роль в повышении устойчивости и обобщающей способности модели. Она работает путем минимизации расстояния между представлениями, полученными из исходных данных и их преобразованных версий. По сути, функция потерь заставляет модель кодировать преобразованные виды одного и того же входного сигнала в близкие векторы в латентном пространстве. Это достигается путем применения различных преобразований (например, поворотов, сдвигов) к входным данным и последующего вычисления потерь на основе разницы между полученными представлениями. Минимизация этих потерь гарантирует, что модель не чувствительна к изменениям во входных данных, что приводит к более надежной и обобщающей способности модели при работе с новыми, ранее не встречавшимися данными.
В рамках данной системы используется периодический оператор для обеспечения согласованности поведения изученных преобразований во всем латентном пространстве. Этот оператор, по сути, гарантирует, что применение преобразования к представлению в латентном пространстве, а затем повторное применение этого же преобразования, приведет к результату, эквивалентному исходному представлению. Это достигается за счет введения периодичности в функцию преобразования, что позволяет избежать накопления ошибок и обеспечивает предсказуемость поведения системы при различных входных данных и последовательностях преобразований. Такая конструкция критически важна для обеспечения стабильности и надежности системы, особенно при работе с данными, требующими точного выравнивания и сохранения структуры.
Проверка на практике: MNIST и за его пределами
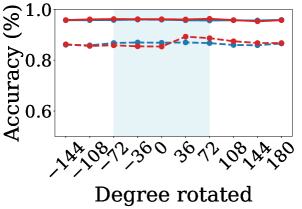
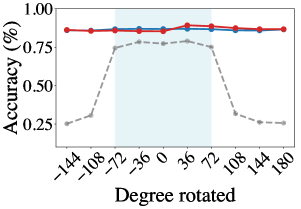
Для проверки работоспособности разработанной системы использовался широко известный набор данных MNIST, состоящий из рукописных цифр. Для повышения реалистичности и оценки устойчивости модели к изменениям, набор данных подвергся дополнительной обработке. К изображениям были применены различные преобразования, включая вращения и сдвиги, имитирующие естественные вариации в положении объектов. Кроме того, для создания более сложного визуального фона, изображения были наложены на шахматную доску. Такой подход позволил оценить способность системы обобщать знания и корректно классифицировать цифры даже при наличии новых, ранее не встречавшихся преобразований, что является важным условием для практического применения в реальных условиях.
В рамках исследования для определения позы объекта в скрытом пространстве использовался алгоритм K-ближайших соседей (k-NN). Этот подход позволяет модели эффективно справляться с ранее не встречавшимися трансформациями изображения, такими как повороты и сдвиги. Суть метода заключается в поиске наиболее похожих представлений в латентном пространстве и использовании их для восстановления информации о позе. Эффективность k-NN демонстрирует способность модели к обобщению и адаптации к новым условиям, не требуя переобучения при изменении входных данных. Данный метод позволяет сохранять инвариантность к трансформации, обеспечивая надежную работу системы даже при незнакомых искажениях изображения.
Обучение модели осуществлялось с использованием функции потерь кросс-энтропии, что позволило одновременно оптимизировать точность классификации и её устойчивость к различным преобразованиям изображений. Этот подход обеспечивает не только правильное распознавание цифр, но и сохранение этой способности даже при поворотах, сдвигах и других изменениях, имитирующих реальные условия. Кросс-энтропия, будучи стандартным инструментом в задачах классификации, в данном контексте способствует формированию представлений, инвариантных к определенным типам преобразований, что критически важно для обобщающей способности модели и её адаптации к новым, ранее не встречавшимся данным.
Результаты экспериментов на наборе данных MNIST демонстрируют стабильно высокую точность классификации — от 95 до 96 процентов — даже при воздействии неизвестных ранее трансформаций изображений. Данный показатель значительно превосходит результаты, полученные с использованием базовых моделей, что подтверждает эффективность предложенного подхода. Применение алгоритма k-ближайших соседей (k-NN) для оценки позы в латентном пространстве позволило достичь точности в 70-80 процентов, используя размер эталонного набора в 2000 примеров. Это свидетельствует о способности модели эффективно обобщать информацию и сохранять высокую производительность при работе с незнакомыми вариациями входных данных.
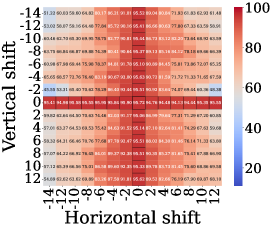
Исследование демонстрирует, что скрытые эквивариантные операторы позволяют нейронным сетям обобщать данные, даже при ограниченном объеме обучающей выборки. Авторы предлагают способ научить сеть инвариантности к трансформациям, что повышает устойчивость к новым, ранее не встречавшимся данным. В этом нет ничего революционного. Как отмечал Дэвид Марр: «Представление о том, что вычислительная система выполняет процесс, не обязательно означает, что она выполняет его таким образом, каким мы можем его описать». То есть, элегантная теория эквивариантности рано или поздно столкнется с жестокой реальностью продакшена, где данные всегда будут грязнее, чем в лабораторных условиях. И тогда придётся искать обходные пути, а не идеальные решения.
Что дальше?
Представленные латентные эквивариантные операторы, безусловно, демонстрируют потенциал для обобщения моделей в условиях, не предусмотренных при обучении. Однако, стоит помнить: каждая элегантная абстракция рано или поздно встретит суровую реальность продакшена. Заманчиво говорить о робастности к неизвестным преобразованиям, но в конечном итоге, любое развёрнутое решение однажды рухнет под натиском неожиданного входного потока. Вопрос не в том, упадёт ли, а когда.
Следующим шагом представляется не столько улучшение точности на MNIST, сколько проверка работоспособности подхода в задачах, где входные данные далеки от идеальных — шумные изображения, неполные данные, аномалии. Настоящий вызов — это не столько обобщение к новым преобразованиям, сколько устойчивость к непредсказуемому шуму реального мира.
И всё же, даже зная, что всё развёрнутое однажды упадёт, нельзя не признать, что красиво умирающие абстракции — это приятно. Изучение латентных эквивариантных операторов, вероятно, приведёт к новым способам представления данных, которые, хотя и обречены, будут элегантно справляться со своей задачей до последнего момента.
Оригинал статьи: https://arxiv.org/pdf/2602.18406.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
2026-02-24 03:45