Автор: Денис Аветисян
Исследователи предлагают метод повышения эффективности работы больших языковых моделей за счет адаптивной проверки предсказаний на основе стабильности принимаемых решений.
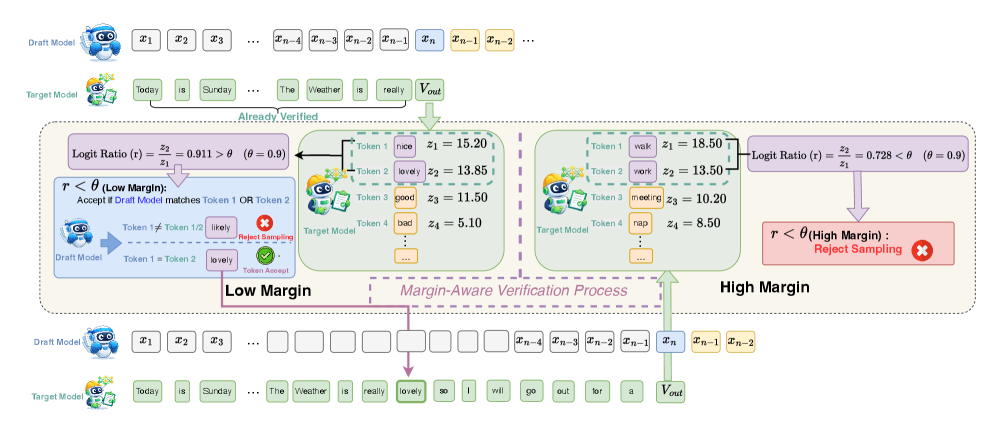
Предложенная методика MARS позволяет значительно ускорить процесс вывода, используя спекулятивное декодирование и адаптивную верификацию на основе логитных марж.
Несмотря на успехи спекулятивного декодирования в ускорении работы больших языковых моделей, традиционные механизмы верификации часто оказываются неэффективными в условиях низкой уверенности модели. В данной работе, представленной под названием ‘MARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification’, предлагается новый подход, адаптирующий строгость верификации к локальной уверенности целевой модели, измеряемой на основе разницы в логарифмах вероятностей токенов \mathcal{N}. Разработанная стратегия позволяет значительно повысить скорость инференса без потери качества генерации. Можно ли с помощью подобных адаптивных методов верификации добиться еще большей эффективности и надежности больших языковых моделей в различных областях применения?
Задержка в выводе больших языковых моделей: фундаментальное ограничение
Большие языковые модели, такие как `Target Model`, демонстрируют впечатляющие возможности в решении широкого спектра задач, однако их авторегрессивная природа создает принципиальное ограничение по задержке. В основе работы этих моделей лежит последовательное предсказание следующего токена, опирающееся на все предыдущие. Этот процесс, хотя и позволяет генерировать связные и осмысленные тексты, неизбежно увеличивает время отклика, поскольку каждый новый токен не может быть сгенерирован до завершения предыдущего этапа. Таким образом, авторегрессия, являясь ключевым элементом эффективности модели в плане качества, одновременно становится узким местом, ограничивающим скорость обработки и затрудняющим применение в сценариях, требующих оперативного взаимодействия.
Авторегрессивная природа больших языковых моделей (БЯМ) обуславливает последовательную зависимость генерации каждого токена от предыдущего. Это означает, что для предсказания следующего слова или символа, модель должна учитывать всю предыдущую сгенерированную последовательность. Такая зависимость существенно ограничивает пропускную способность и увеличивает время отклика, поскольку новый токен не может быть сгенерирован до завершения генерации предыдущего. В результате, даже при наличии мощного вычислительного оборудования, скорость обработки запросов ограничивается необходимостью последовательного выполнения операций, что становится критическим фактором при создании приложений, требующих мгновенной реакции, и при масштабировании сервисов, использующих БЯМ.
Последовательное декодирование, присущее генеративным языковым моделям, представляет собой значительное препятствие для их применения в задачах, требующих мгновенного отклика, и для масштабирования соответствующих сервисов. Каждый сгенерированный токен напрямую зависит от предыдущего, что исключает возможность параллельной обработки и существенно увеличивает время генерации ответа. Это особенно критично для интерактивных приложений, таких как чат-боты или системы голосового управления, где задержка даже в несколько сотен миллисекунд может негативно сказаться на пользовательском опыте. Помимо этого, последовательная природа генерации ограничивает пропускную способность системы, затрудняя одновременную обработку большого числа запросов и усложняя масштабирование инфраструктуры для обслуживания растущей аудитории пользователей. Поэтому оптимизация процесса декодирования и поиск способов распараллеливания вычислений являются ключевыми задачами для разработчиков и исследователей в области больших языковых моделей.
Спекулятивное декодирование: параллельный подход к ускорению вывода
Спекулятивное декодирование решает проблему задержки при генерации текста, используя черновую модель для параллельного предсказания кандидатов в токены. Вместо последовательной генерации каждого токена, черновая модель создает несколько вероятных вариантов одновременно. Эти варианты затем проверяются основной моделью, что позволяет значительно сократить общее время генерации, поскольку верификация может происходить параллельно с предсказанием следующего токена.
Снижение задержки достигается за счет одновременной верификации предложенных кандидатов в токены (draft tokens) и генерации следующих токенов основной моделью. Традиционный подход предполагает последовательную генерацию и проверку каждого токена, что является узким местом в процессе. Параллельная верификация позволяет перекрывать эти этапы, существенно сокращая общее время генерации текста. В то время как основная модель продолжает генерировать следующие токены, отдельный процесс верифицирует уже сгенерированные, что позволяет избежать простоя и повысить пропускную способность системы.
Основная концепция спекулятивного декодирования заключается в намеренном увеличении вычислительных затрат на этапе проверки с целью существенного снижения общей задержки генерации. Вместо последовательного формирования каждого токена, система генерирует несколько кандидатов параллельно. Несмотря на необходимость проверки достоверности этих кандидатов, параллельное выполнение генерации и верификации позволяет сократить время, необходимое для получения конечного результата, поскольку верификация может выполняться одновременно с генерацией следующих токенов. Этот подход предполагает компромисс между дополнительными вычислительными ресурсами, затраченными на проверку, и значительным ускорением процесса генерации.
Адаптивная верификация: повышение надежности и точности декодирования
Простая верификация по точному совпадению (Exact Match Verification) служит базовым уровнем, однако адаптивная верификация (Adaptive Verification) повышает устойчивость системы за счет динамической корректировки строгости проверки, основываясь на уверенности модели. Вместо применения фиксированного порога, адаптивная верификация позволяет снижать требования к совпадению при низкой уверенности модели, и наоборот — повышать их при высокой уверенности. Это позволяет избежать ложных отказов в случаях, когда модель не уверена в своем ответе, и одновременно поддерживать высокую точность при уверенных предсказаниях. Такой подход позволяет более эффективно использовать ресурсы и повысить общую надежность системы.
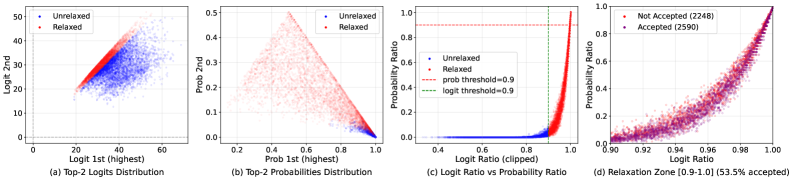
Отношение логитов (Logit Ratio) является ключевым показателем для оценки уверенности модели при верификации. Оно рассчитывается как отношение логитов для предпочтительного и непредпочтительного вариантов ответа. Низкомаржинальный режим (Low-Margin Regime) характеризуется значениями Logit Ratio, близкими к единице, что указывает на слабую уверенность модели в своем выборе. В таких случаях, небольшие изменения во входных данных могут привести к смене предпочтения. Идентификация низкомаржинального режима позволяет применять более гибкие стратегии верификации, такие как снижение порога строгости, для повышения робастности системы без существенного увеличения числа ложных срабатываний. Точный контроль над этим режимом достигается путем анализа LogitRatio = \frac{logit(preferred)}{logit(non-preferred)}.
Метод верификации с учетом запаса (Margin-Aware Speculative Verification) повышает эффективность за счет выборочного ослабления требований к проверке, когда уверенность модели в предпочтениях невелика. В ситуациях низкой маржинальности — когда разница между логарифмами вероятностей наиболее и наименее предпочтительных вариантов невелика — вместо строгой верификации применяется спекулятивная проверка. Это позволяет снизить вычислительные затраты, сохраняя при этом приемлемый уровень точности, поскольку ослабление требований оправдано низкой уверенностью модели в конкретном выборе. Эффективность подхода заключается в динамической адаптации строгости проверки в зависимости от степени уверенности модели, что позволяет оптимизировать баланс между скоростью и точностью верификации.
Логиты, являясь входными данными для функции softmax, формируют основу для вычисления вероятностного распределения, представляющего уверенность модели в каждом классе. logits \rightarrow softmax \rightarrow probability\, distribution . Анализ значений логитов позволяет оценить степень предпочтения модели для конкретного ответа, а их соотношение (logit ratio) используется для определения «низкомаржинальных» случаев, когда разница между наиболее и наименее вероятными классами невелика. Именно эта информация о логитах и вероятностном распределении лежит в основе адаптивной верификации и методов, учитывающих маржу, позволяя динамически регулировать строгость проверки и повышать эффективность системы.
Оптимизация декодирования: ускорение, эффективность и снижение затрат
Для дальнейшего снижения задержки в генерации текста применяется метод потерянного спекулятивного декодирования. Данная техника допускает незначительное снижение качества генерируемого текста в обмен на существенное ускорение процесса. Суть подхода заключается в принятии предварительных, потенциально не совсем точных, гипотез относительно следующих токенов, что позволяет продолжить генерацию без ожидания полной проверки каждого токена. В случае ошибки, незначительное ухудшение качества оказывается приемлемой ценой за значительное увеличение скорости работы модели, особенно в сценариях, где важна скорость ответа, а небольшие неточности допустимы.
Параллельная верификация множества вариантов продолжения текста, известная как древовидная верификация, представляет собой инновационный подход к повышению производительности языковых моделей. Вместо последовательной проверки каждого токена, данный метод позволяет одновременно оценивать несколько ветвей вероятных продолжений, значительно увеличивая пропускную способность системы. Это достигается за счет организации процесса верификации в виде дерева, где каждая ветвь представляет собой отдельную гипотезу о следующем токене. Благодаря распараллеливанию вычислений, система способна обрабатывать больше данных за единицу времени, что особенно важно при генерации длинных текстов или при работе с приложениями, требующими высокой скорости ответа. Эффективность древовидной верификации напрямую зависит от способности системы эффективно распределять вычислительные ресурсы между различными ветвями, оптимизируя баланс между скоростью и точностью.
Система EAGLE, разработанная для повышения производительности языковых моделей, использует контекстную информацию для значительного улучшения точности так называемой “черновой модели” (Draft Model). Вместо слепого предсказания следующего токена, EAGLE анализирует окружающий текст, выявляя скрытые зависимости и вероятные смысловые связи. Этот подход позволяет модели более эффективно разрешать неоднозначности и генерировать более правдоподобные и когерентные последовательности. В результате, снижается потребность в ресурсоемкой верификации, поскольку черновая модель изначально предлагает более качественные варианты, что в свою очередь ведет к уменьшению задержки и повышению общей скорости обработки текста.
Методы дистилляции знаний позволяют существенно оптимизировать процесс генерации текста, снижая затраты на последующую верификацию. Суть подхода заключается в обучении упрощенной, “студенческой” модели, имитирующей поведение более сложной, “учительской” модели. Вместо прямого обучения на исходных данных, “студент” учится воспроизводить вероятностное распределение, выдаваемое “учителем”. Это позволяет получить модель, способную быстро генерировать черновой вариант текста, требующий минимальной проверки на корректность. Таким образом, дистилляция знаний выступает эффективным инструментом для повышения скорости и снижения вычислительных ресурсов, необходимых для генерации текста, особенно в задачах, требующих высокой пропускной способности.
Будущее LLM: масштабируемость, доступность и перспективы развития
Метод спекулятивного декодирования и его усовершенствования открывают новые перспективы для широкого доступа к мощным языковым моделям. Вместо последовательной генерации каждого токена, данный подход позволяет модели предсказывать несколько токенов заранее, значительно ускоряя процесс вывода. Эта инновация особенно важна, поскольку позволяет снизить вычислительные затраты, делая использование крупных языковых моделей доступным даже на устройствах с ограниченными ресурсами. Таким образом, спекулятивное декодирование способствует демократизации искусственного интеллекта, позволяя большему числу пользователей и разработчиков использовать передовые технологии обработки естественного языка для создания инновационных приложений и сервисов.
Снижение затрат на инференс больших языковых моделей (LLM) открывает возможности для их широкого внедрения даже в условиях ограниченных ресурсов. Ранее требующие значительных вычислительных мощностей и энергозатрат, LLM теперь могут быть развернуты на менее производительном оборудовании, включая мобильные устройства и периферийные системы. Это особенно важно для регионов с ограниченным доступом к современной инфраструктуре, а также для приложений, требующих автономной работы. Такая доступность позволит использовать LLM в образовательных программах, системах здравоохранения в удаленных районах, и в других областях, где ранее развертывание подобных технологий было экономически нецелесообразным. Уменьшение стоимости инференса не только расширяет географию применения, но и способствует инновациям, позволяя разработчикам создавать новые приложения и сервисы, ориентированные на более широкую аудиторию.
Перспективные исследования, направленные на адаптивную верификацию и оптимизацию предварительных моделей, обещают значительное повышение производительности больших языковых моделей. В частности, совершенствование методов адаптивной верификации позволит более эффективно отсеивать неверные прогнозы на ранних стадиях генерации, снижая вычислительную нагрузку без существенной потери качества. Параллельно, оптимизация предварительных моделей, основанная на анализе их слабых мест и применении специализированных алгоритмов, способствует повышению скорости и снижению потребления ресурсов. Комбинация этих подходов открывает возможности для создания более быстрых, эффективных и доступных систем искусственного интеллекта, способных решать сложные задачи в различных областях применения.
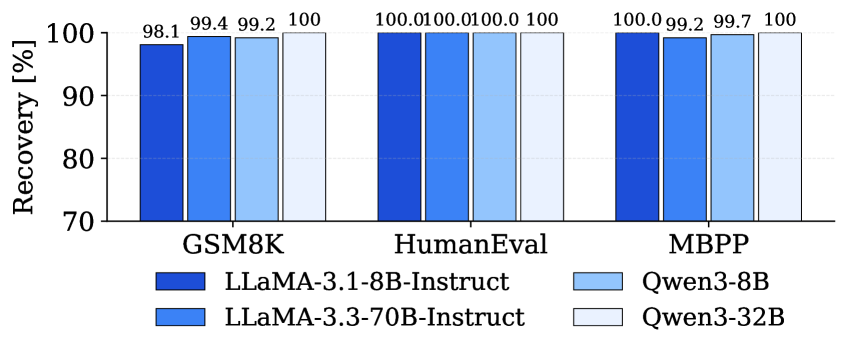
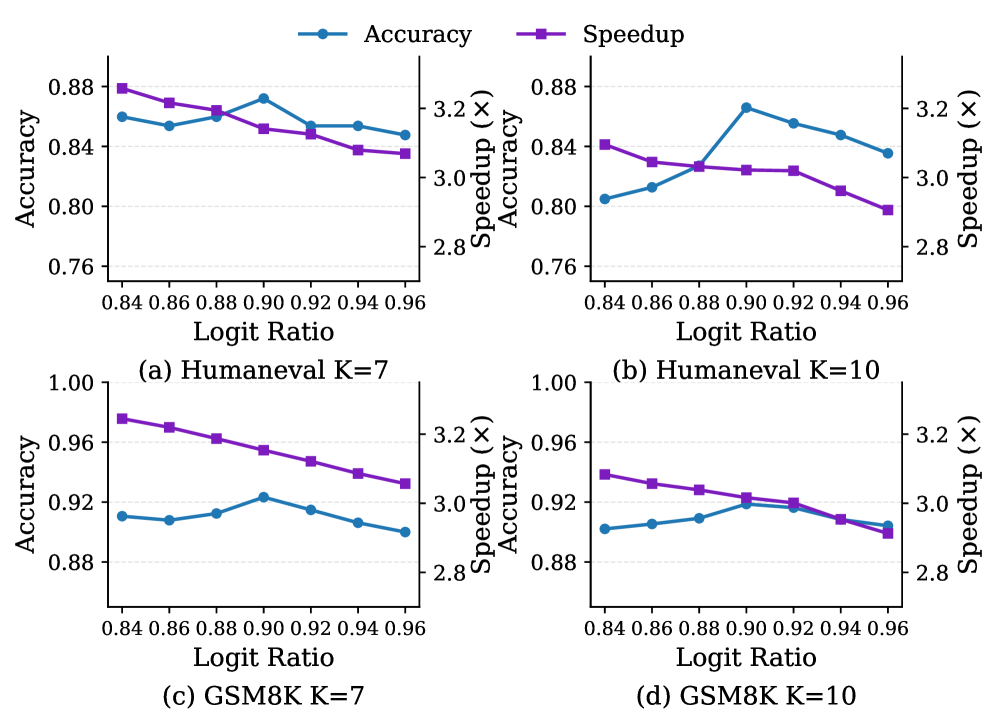
Разработанный подход демонстрирует значительное ускорение процесса инференса больших языковых моделей, в частности, на модели LLaMA-3.3-70B, достигая увеличения скорости до 4.76x. При этом, ключевым аспектом является сохранение высокой точности генерируемых результатов — показатель восстановления точности составляет от 98.1% до 100% в различных задачах. Это означает, что предлагаемый метод не только существенно повышает производительность, но и гарантирует надежность и качество получаемых ответов, открывая возможности для более эффективного использования мощных языковых моделей в широком спектре приложений.
Исследования показали значительное увеличение скорости работы языковой модели Vicuna-13B благодаря применению спекулятивного декодирования. В ходе экспериментов удалось добиться ускорения в 3.74 раза, при этом средняя длина принятого фрагмента текста (τ) составила 7.20 токенов. Этот показатель свидетельствует о высокой эффективности предложенного подхода в поддержании связности и логичности генерируемого текста даже при значительном увеличении скорости обработки. Ускорение в обработке данных открывает возможности для развертывания мощных языковых моделей на устройствах с ограниченными ресурсами, делая передовые технологии искусственного интеллекта более доступными и отзывчивыми для широкого круга пользователей.
Развитие технологий, направленных на повышение скорости обработки данных большими языковыми моделями, открывает новые горизонты для создания более отзывчивых и увлекательных взаимодействий с искусственным интеллектом. Повышение эффективности и снижение затрат на инференс позволяют внедрять сложные модели в разнообразные приложения, от персональных ассистентов и интерактивных образовательных платформ до систем поддержки клиентов и креативных инструментов. Это способствует созданию более естественных и интуитивно понятных интерфейсов, где взаимодействие с ИИ становится не просто функциональным, но и приятным, что значительно расширяет возможности применения этих технологий в повседневной жизни и профессиональной деятельности.
Исследование, представленное в данной работе, демонстрирует стремление к элегантности в оптимизации алгоритмов обработки естественного языка. Подход MARS, основанный на адаптивном ослаблении требований к верификации на основе стабильности решения модели, является ярким примером поиска оптимального баланса между эффективностью и точностью. Как однажды заметил Джон фон Нейманн: «В науке не бывает простых ответов, только простые вопросы». В контексте MARS, сложность задачи ускорения вывода больших языковых моделей решается путём тонкой настройки критериев верификации, что позволяет добиться значительного прироста скорости без существенной потери качества. Данный метод подчеркивает, что красота алгоритма проявляется не в трюках, а в непротиворечивости его границ и предсказуемости.
Куда Далее?
Представленная работа, демонстрируя возможность адаптивного ослабления требований к верификации в процессе спекулятивного декодирования, лишь подчеркивает фундаментальную проблему: стремление к эффективности часто идет рука об руку с риском внесения ошибок. Иллюзия скорости, достигнутая за счет частичного отказа от строгой проверки, требует особого внимания к оценке надежности полученных результатов. Истинную элегантность решения можно будет увидеть лишь тогда, когда будет доказано, что снижение вычислительных затрат не приводит к пропорциональному снижению достоверности.
Очевидным направлением дальнейших исследований представляется разработка более точных метрик стабильности модели, выходящих за рамки простого анализа логит-маржи. Необходимо учитывать контекст запроса, сложность генерируемого текста и даже внутреннюю архитектуру модели. Простое увеличение скорости генерации бессмысленно, если результат — лишь правдоподобная, но ошибочная информация. В хаосе данных спасает только математическая дисциплина.
Интересным представляется и вопрос о применимости представленного подхода к другим задачам, требующим быстрого принятия решений, например, в системах автоматического управления или в задачах обработки сигналов. Однако, прежде чем говорить о универсальности метода, необходимо провести тщательный анализ его ограничений и разработать надежные механизмы защиты от потенциальных ошибок. В конечном счете, ценность алгоритма определяется не только его скоростью, но и его безошибочностью.
Оригинал статьи: https://arxiv.org/pdf/2601.15498.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-24 10:20