Автор: Денис Аветисян
Исследователи предлагают инновационную систему, позволяющую значительно повысить скорость работы больших языковых моделей за счет повторного использования скрытых состояний.

Представленная система Lyanna ускоряет вывод текста за счет оптимизации спекулятивного декодирования и повторного использования информации о токенах.
Ускорение вывода больших языковых моделей (LLM) часто достигается за счет спекулятивного декодирования, однако значительная часть вычислений при этом оказывается потраченной впустую из-за отклонения сгенерированных черновиков. В статье ‘Make Every Draft Count: Hidden State based Speculative Decoding’ предложена система Lyanna, позволяющая повторно использовать скрытые состояния отклоненных токенов, что значительно повышает эффективность вычислений. Ключевой идеей является сохранение семантики на уровне скрытых состояний и отсрочка интеграции информации о токенах, обеспечивая возможность переиспользования этих состояний. Сможет ли данный подход кардинально изменить парадигму спекулятивного декодирования и открыть новые горизонты в оптимизации LLM?
Узкое Место Авторегрессии: Цена Последовательности
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, однако их работа основана на авторегрессионном декодировании — процессе, требующем значительных вычислительных ресурсов. Этот подход предполагает последовательное предсказание следующего токена в последовательности, опираясь на все ранее сгенерированные токены. Несмотря на эффективность в достижении связных и осмысленных текстов, последовательная природа авторегрессии становится узким местом при увеличении размера модели и длины обрабатываемых последовательностей. Каждый новый токен требует повторного прогона всей предыдущей информации через нейронную сеть, что экспоненциально увеличивает время обработки и ограничивает возможности масштабирования, особенно в задачах, требующих обработки больших объемов данных или генерации длинных текстов.
Традиционные методы обработки естественного языка, используемые в больших языковых моделях, предполагают последовательную генерацию токенов — по одному за раз. Этот принцип, хотя и понятен с точки зрения логики работы модели, создает серьезное ограничение в производительности по мере увеличения её размера и длины обрабатываемых последовательностей. Каждый новый токен генерируется только после завершения обработки предыдущего, что исключает возможность параллельных вычислений и значительно замедляет процесс. По мере роста числа параметров модели и длины входных данных, время генерации увеличивается линейно, становясь узким местом в реализации мощных языковых возможностей. В результате, обработка длинных текстов или решение сложных задач требует всё больше вычислительных ресурсов и времени, ограничивая практическое применение этих моделей в реальном времени.
Последовательная природа авторегрессивного декодирования существенно ограничивает возможности параллельной обработки информации, что особенно критично при решении сложных задач. Каждый новый токен генерируется только после завершения обработки предыдущего, создавая узкое место в вычислительном процессе. Это препятствует эффективному использованию современных многоядерных процессоров и графических ускорителей, потенциально способных значительно ускорить генерацию текста. В результате, модели сталкиваются с трудностями при анализе длинных последовательностей и выполнении задач, требующих комплексного рассуждения, поскольку время обработки экспоненциально увеличивается с ростом длины входных данных. Разработка методов, позволяющих распараллелить процесс декодирования, является ключевым направлением исследований в области больших языковых моделей, открывающим путь к более быстрым и эффективным системам искусственного интеллекта.

Спекулятивное Декодирование: Шаг к Параллельности
Спекулятивное декодирование предлагает решение за счет параллельного предсказания будущих токенов с использованием “черновой” модели (draft model). Вместо последовательного генерирования каждого токена основной моделью, черновая модель параллельно предсказывает несколько следующих токенов. Это позволяет начать работу над генерацией токенов до того, как будет завершен полный прямой проход основной модели, тем самым увеличивая общую скорость генерации текста. Предсказанные токены затем проверяются основной моделью, и в случае соответствия используются без дополнительных вычислений.
Верификация предсказаний, выполненных предварительной моделью, позволяет существенно снизить количество полных прямых проходов (forward passes) на сгенерированный токен. Вместо последовательного вычисления каждого токена основной моделью, спекулятивное декодирование параллельно проверяет предсказанные токены. Если предсказание подтверждается основной моделью, вычисление токена пропускается, что приводит к экономии вычислительных ресурсов и снижению задержки. В случае неверного предсказания, выполняется стандартный прямой проход для коррекции, но общая частота выполнения полных проходов значительно уменьшается, особенно при генерации длинных последовательностей.
Параллельный подход в спекулятивном декодировании обеспечивает повышение пропускной способности и снижение задержки, особенно при генерации длинных последовательностей. Вместо последовательного вычисления каждого токена, несколько токенов предсказываются параллельно «черновым» (draft) моделями. Это позволяет избежать необходимости полного прямого прохода для каждого токена, так как верификация предсказаний происходит параллельно с генерацией. Для длинных последовательностей, где суммарная задержка от последовательных вычислений становится значительной, преимущества параллелизации наиболее заметны, поскольку общее время генерации снижается пропорционально уменьшению количества необходимых полных проходов.
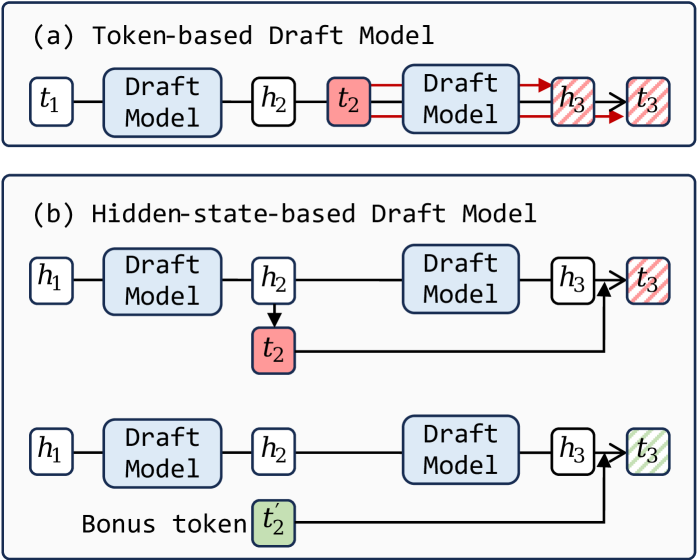
Lyanna: Оптимизация Спекулятивного Декодирования для Максимальной Производительности
Lyanna использует подход к спекулятивному декодированию, основанный на повторном использовании спроектированных скрытых состояний (drafted hidden states), что позволяет минимизировать вычислительные издержки. Вместо того, чтобы пересчитывать скрытые состояния для каждого токена, система сохраняет и переиспользует их, когда это возможно, значительно сокращая количество необходимых вычислений. Этот метод позволяет повысить эффективность декодирования за счет оптимизации использования памяти и снижения общего времени обработки, особенно при работе с большими языковыми моделями и длинными последовательностями текста.
Для дальнейшей оптимизации использования памяти и повышения эффективности выборки в Lyanna применяются методы встраивания информации о токенах (Token Information Embedding) и разреженности горячих токенов (Hot-Token Sparsity). Встраивание информации о токенах позволяет более эффективно кодировать и представлять данные о токенах, снижая требования к объему памяти. Разреженность горячих токенов фокусируется на обработке наиболее вероятных токенов, игнорируя менее значимые, что существенно уменьшает вычислительную нагрузку и потребление памяти, особенно при генерации длинных последовательностей. Комбинация этих методов позволяет Lyanna достигать высокой производительности при одновременном снижении затрат ресурсов.
В ходе тестирования Lyanna продемонстрировала значительное увеличение производительности по сравнению со стандартным авторегрессионным декодированием, достигнув прироста скорости обработки в 3.3 раза. Кроме того, Lyanna превосходит существующие методы спекулятивного декодирования, такие как EAGLE, до 1.4 раза. Задержка прямой передачи (forward latency) для draft-модели снижена на 60.9%, что свидетельствует о высокой эффективности предложенного подхода к повторному использованию скрытых состояний.
В процессе верификации сгенерированных предложений модель Lyanna демонстрирует высокие показатели принятия на каждом этапе. На первом этапе верификации, предназначенном для базовой проверки соответствия, показатель принятия составляет 91%. На втором этапе, включающем более детальную оценку контекста и грамматики, показатель снижается до 80%. На заключительном, третьем этапе верификации, который предполагает проверку семантической корректности и согласованности, модель принимает 70% сгенерированного текста. Эти данные свидетельствуют о высокой надежности и точности модели в процессе генерации и верификации последовательностей.

Архитектурные Синергии: Усиление Основы Lyanna
В основе повышения производительности Lyanna лежит эффективное управление ключами и значениями механизма внимания. Интеграция с такими передовыми техниками, как Paged Attention и FlashInfer, позволяет значительно оптимизировать этот процесс. Paged Attention разбивает последовательности внимания на страницы, что снижает требования к памяти и ускоряет доступ к данным. FlashInfer, в свою очередь, использует оптимизированные алгоритмы для вычисления внимания, минимизируя задержки и повышая пропускную способность. В результате, сочетание этих подходов позволяет Lyanna обрабатывать большие объемы информации быстрее и эффективнее, открывая возможности для создания более сложных и производительных языковых моделей.
Внедрение передовых “черновых” моделей, таких как EAGLE, значительно повышает точность предсказаний и снижает вычислительную нагрузку на основную модель. Использование EAGLE позволяет предварительно генерировать вероятные варианты продолжения текста, которые затем используются для уточнения финального результата. Такой подход не только ускоряет процесс декодирования, но и позволяет основной модели сосредоточиться на наиболее сложных и неоднозначных участках текста, тем самым повышая общую производительность и качество генерируемого контента. Эффективное распределение задач между “черновой” и основной моделями открывает возможности для создания более быстрых и экономичных систем обработки естественного языка.
Интеграция вычисления логитов за один проход с архитектурой Mixture-of-Experts значительно повышает эффективность и масштабируемость процесса декодирования. Традиционные методы требуют многократного вычисления логитов для каждого токена, что становится узким местом при работе с большими языковыми моделями. В отличие от них, предложенный подход позволяет вычислить логиты за один проход, используя преимущества Mixture-of-Experts, где различные «эксперты» специализируются на определенных аспектах задачи. Это не только ускоряет процесс декодирования, но и позволяет модели обрабатывать более сложные запросы и генерировать более качественный текст, эффективно распределяя вычислительную нагрузку между экспертами и избегая избыточных вычислений.
Дополнительное использование методов ресемплинга и Verification Fusion позволило значительно повысить производительность модели Lyanna. В ходе исследований зафиксировано увеличение эффективности на 23.1% при работе с LLaMA-2-7B и на 18.7% с Vicuna-7B-v1.5. Данные улучшения демонстрируют, что комбинация этих техник способствует более точному и быстрому прогнозированию, позволяя модели эффективнее обрабатывать информацию и генерировать более качественные результаты. Верификация и повторная выборка данных, по всей видимости, помогают снизить вероятность ошибок и повысить стабильность работы системы.

SLO-Адаптированное Декодирование: Настройка Производительности под Задачи
Технология SLO-адаптированного вероятностного декодирования позволяет динамически настраивать параметры генерации текста в соответствии с заданными целями по уровню обслуживания (Service Level Objectives). Вместо использования фиксированных настроек, система автоматически корректирует такие параметры, как длина принимаемой последовательности, чтобы оптимизировать производительность под конкретные требования приложения. Это означает, что для задач, критичных ко времени отклика, система может отдавать приоритет низкой задержке, даже если это снижает общую пропускную способность. Напротив, для задач, где важен объем сгенерированного текста, система может максимизировать пропускную способность, жертвуя незначительной задержкой. Такая гибкость открывает новые возможности для развертывания больших языковых моделей в самых разнообразных и требовательных реальных сценариях, обеспечивая оптимальное соотношение между скоростью и качеством генерации.
Система декодирования, адаптируемая к конкретным задачам, позволяет динамически изменять параметры, такие как допустимая длина последовательности, для оптимизации производительности. Например, сокращение допустимой длины способствует снижению задержки — критичному фактору для интерактивных приложений, требующих мгновенного отклика. В то же время, увеличение этого параметра позволяет системе обрабатывать больше данных за единицу времени, повышая общую пропускную способность и эффективность при выполнении задач, где скорость обработки является приоритетом. Таким образом, гибкая настройка параметров декодирования открывает возможность эффективно использовать большие языковые модели в широком спектре приложений с различными требованиями к скорости и производительности.
Возможность динамической адаптации параметров декодирования открывает принципиально новые горизонты для внедрения больших языковых моделей в самых разнообразных и требовательных реальных условиях. Благодаря этой гибкости, системы могут быть оптимизированы не только для достижения максимальной пропускной способности, но и для минимизации задержки, что критически важно для интерактивных приложений, таких как чат-боты или виртуальные ассистенты. Такая настройка позволяет эффективно использовать ресурсы и обеспечивать стабильную работу моделей даже при высоких нагрузках и ограниченных вычислительных мощностях. В результате, применение больших языковых моделей становится доступным в широком спектре сценариев, от обработки естественного языка в реальном времени до автоматизации сложных задач, требующих мгновенного ответа.
Работа над Lyanna, как и любая попытка оптимизировать предсказание токенов, неизбежно наталкивается на суровую реальность. Авторы предлагают переиспользовать скрытые состояния, что, безусловно, элегантно, но в опыте миграций каждый знает: любая «революционная» технология завтра станет техдолгом. Идея ускорения за счет переиспользования скрытых состояний напоминает о том, как часто «самовосстанавливающиеся» системы просто ещё не ломались. Ускорение в 3.3 раза — впечатляюще, пока не начнется массовое внедрение и не выяснится, что система уязвима к редким, но критическим последовательностям токенов. Как метко заметил Карл Фридрих Гаусс: «Если бы я мог сказать это по-простому, я бы не стал тратить столько времени, чтобы это объяснить». Оптимизация арифметической интенсивности, безусловно, важна, но стабильность системы — это всегда вопрос времени.
Что дальше?
Представленная работа, безусловно, добавляет ещё один слой оптимизации в бесконечную гонку за производительностью LLM. Ускорение в 3.3 раза — цифра впечатляющая, пока не взглянешь на стоимость этого ускорения: переиспользование скрытых состояний — это всегда компромисс между скоростью и, вероятнее всего, стабильностью. Вспомните, как когда-то всё начиналось с простого bash-скрипта, а теперь это сложная система, где ошибка в одном слое может обрушить всю конструкцию. Сейчас это назовут AI и получат инвестиции.
Очевидно, что истинная проблема не в скорости генерации токенов, а в арифметической интенсивности. Пока мы оптимизируем декодирование, архитектура моделей продолжает расти, пожирая ресурсы. Следующим шагом, вероятно, станет ещё более изощрённое кэширование и предсказание, но рано или поздно мы упрёмся в аппаратные ограничения. Начинаю подозревать, что они просто повторяют модные слова, говоря о «революционных» прорывах.
И, конечно, документация снова соврёт. Ведь, в конечном счете, каждая «революционная» технология завтра станет техдолгом. Продакшен всегда найдёт способ сломать элегантную теорию, и этот цикл будет повторяться, пока не придёт кто-то, кто начнёт всё переписывать с нуля — снова на bash.
Оригинал статьи: https://arxiv.org/pdf/2602.21224.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-26 23:10