Автор: Денис Аветисян
Исследователи предлагают инновационный метод обучения языковых моделей, позволяющий значительно ускорить процесс генерации текста без существенной потери качества.
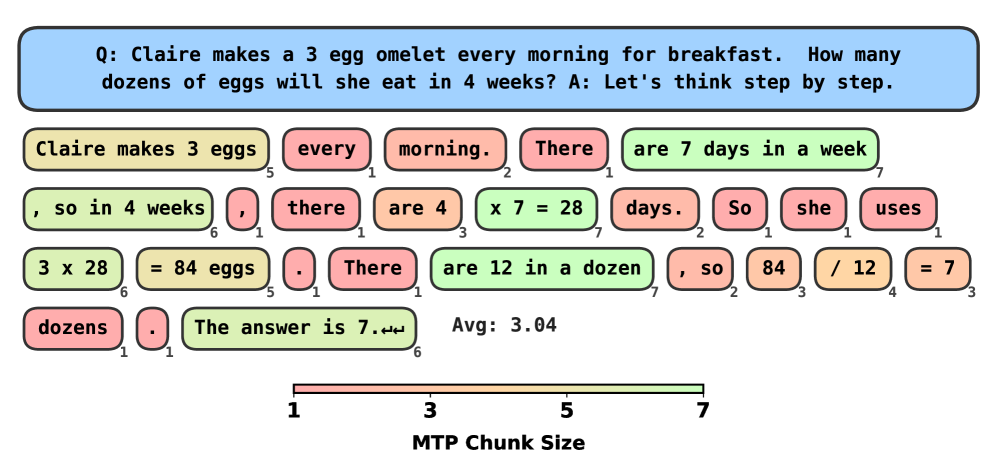
В статье представлен метод одновременного предсказания нескольких токенов с использованием принципов обучения с подкреплением и адаптивных стратегий декодирования.
Существующие методы ускорения вывода языковых моделей, такие как спекулятивное декодирование, требуют обучения вспомогательных моделей и создания сложных конвейеров. В работе ‘Multi-Token Prediction via Self-Distillation’ предложен новый подход к преобразованию предварительно обученной авторегрессионной языковой модели в быструю модель, предсказывающую несколько токенов одновременно, с использованием простого онлайн-дистилляционного целевого критерия. Разработанная модель сохраняет ту же реализацию, что и исходная контрольная точка, и может быть развернута без добавления дополнительных верификаторов или специализированного кода для вывода. На датасете GSM8K, предложенный метод позволяет ускорить декодирование более чем в 3\times раза при незначительной потере точности (менее 5\%) по сравнению с декодированием по одному токену — сможет ли данный подход стать стандартом в ускорении генерации текста?
Преодолевая Ограничения Последовательной Обработки: Ключ к Ускоренному Рассуждению
Традиционные языковые модели, функционирующие на основе последовательного предсказания следующего токена NextTokenPrediction, демонстрируют ограниченные возможности при решении сложных задач, требующих продолжительной обработки информации. Этот подход, по своей сути, имитирует построчный анализ текста, что препятствует эффективному удержанию и использованию контекста на протяжении всего процесса рассуждения. В отличие от человеческого мышления, способного к одновременной обработке множества факторов, модели, основанные на NextTokenPrediction, вынуждены последовательно анализировать каждый элемент, что приводит к потере важных связей и снижению точности при решении задач, требующих глубокого понимания и логического вывода. В результате, даже относительно простые задачи, требующие удержания информации на протяжении нескольких шагов, могут представлять значительную трудность для подобных систем.
Ограничение, связанное с последовательным предсказанием каждого токена, существенно замедляет работу языковых моделей и ограничивает их масштабируемость. В процессе решения сложных задач, например, математических, где требуется удержание и обработка большого объема информации на протяжении всего вычисления, такая задержка становится критической. Каждый новый токен, генерируемый последовательно, требует завершения предыдущего этапа предсказания, создавая узкое место в производительности. Это особенно заметно при решении уравнений или доказательстве теорем, где даже небольшая задержка на каждом шаге может значительно увеличить общее время вычисления и снизить способность модели эффективно оперировать сложными логическими структурами. Альтернативные подходы, направленные на параллельную обработку информации, представляются необходимыми для преодоления данного ограничения и достижения более высоких результатов в задачах, требующих интенсивного рассуждения.
Существующие методы обработки языка, основанные на последовательном прогнозировании следующего токена, значительно уступают человеческому мышлению в плане эффективности. В то время как люди способны обрабатывать информацию параллельно, одновременно учитывая различные аспекты проблемы, языковые модели вынуждены последовательно анализировать текст, что создает узкое место в производительности. Эта последовательность ограничивает скорость обработки и не позволяет в полной мере использовать потенциал современных вычислительных мощностей. В результате, модели испытывают трудности с задачами, требующими комплексного анализа и долговременного удержания информации, поскольку не могут эффективно использовать возможности параллельной обработки, характерные для человеческого мозга.
MultiTokenPrediction: Сдвиг Параллели в Декодировании
Метод MultiTokenPrediction предполагает предсказание нескольких токенов за один прямой проход (forward pass) по модели. В отличие от традиционного последовательного декодирования, когда каждый токен генерируется последовательно после предыдущего, MultiTokenPrediction позволяет параллельно вычислять вероятности для нескольких следующих токенов. Это существенно снижает задержку (latency), так как уменьшается количество необходимых последовательных операций, и увеличивает пропускную способность (throughput) модели, позволяя обрабатывать больше данных за единицу времени. Реализация предполагает оптимизацию вычислений для параллельного предсказания, что требует адаптации архитектуры модели и алгоритмов декодирования.
Метод MultiTokenPrediction использует преимущества параллельной обработки данных, имитируя принципы работы биологических систем, в частности, одновременную обработку информации в нейронных сетях мозга. Такой подход позволяет распараллелить процесс предсказания токенов, существенно снижая задержку и повышая пропускную способность модели. Вместо последовательного предсказания каждого токена, модель одновременно обрабатывает несколько токенов, что значительно ускоряет процесс рассуждения и генерации текста, обеспечивая более эффективное использование вычислительных ресурсов.
Метод MultiTokenPrediction позволяет модели поддерживать более связный контекст и повышать производительность при решении сложных задач за счет одновременного предсказания нескольких токенов. В отличие от последовательного предсказания, которое требует многократных проходов для генерации текста, данный подход использует возможности параллельной обработки. Результаты показывают, что одновременное предсказание токенов обеспечивает ускорение генерации текста до 5 раз по сравнению с традиционными методами, при сохранении или улучшении качества генерируемого текста. Это достигается за счет более эффективного использования вычислительных ресурсов и снижения задержек, связанных с последовательной обработкой.
![Для повышения эффективности обучения модель обрабатывает последовательность длиной 18 токенов, реплицируя фрагменты обучающего текста и применяя маскировку для параллельного решения нескольких задач [latex]MTP[/latex] с использованием обратной связи от](https://arxiv.org/html/2602.06019v1/x2.png)
Обучение в Диалоге: Архитектура «Учитель-Критик»
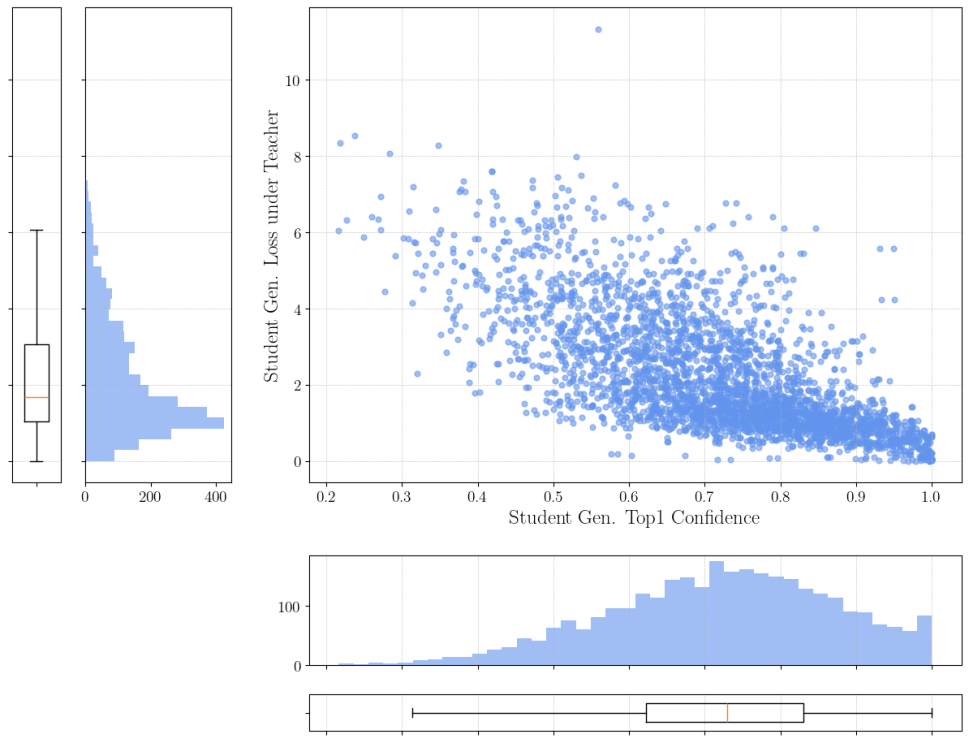
В рамках обучения модели используется схема “Учитель-Критик” (TeacherCriticFramework), где отдельная модель, функционирующая как “Учитель”, предоставляет обратную связь для модели “Ученика”. Этот процесс позволяет корректировать параметры “Ученика” с целью повышения точности прогнозирования. “Учитель” генерирует целевые распределения вероятностей, которые используются для оценки и улучшения выходных данных “Ученика”. Обратная связь, предоставляемая “Учителем”, служит сигналом для оптимизации параметров “Ученика”, направляя его к более эффективному решению поставленной задачи и повышению общей производительности модели.
В рамках данной архитектуры, расхождение между учителем и учеником количественно оценивается с помощью KL-дивергенции. KL-дивергенция измеряет информационную потерю при использовании распределения вероятностей, предсказанного учеником, для аппроксимации распределения, предсказанного учителем. Минимизация KL-дивергенции в процессе обучения стимулирует ученика к адаптации и приближению к экспертному уровню учителя, обеспечивая передачу знаний и повышение точности предсказаний. Высокое значение KL-дивергенции указывает на значительное расхождение между моделями, требующее корректировки параметров ученика.
В процессе обучения модель использует функции Softmax и Argmax для оптимизации выбора токенов. Функция Softmax преобразует вектор оценок для каждого токена в вероятностное распределение, позволяя модели оценить вероятность каждого токена быть следующим в последовательности. Затем функция Argmax выбирает токен с наивысшей вероятностью, обеспечивая выбор наиболее вероятного следующего токена и направляя процесс генерации текста. Этот механизм способствует повышению когерентности и точности генерируемых последовательностей.
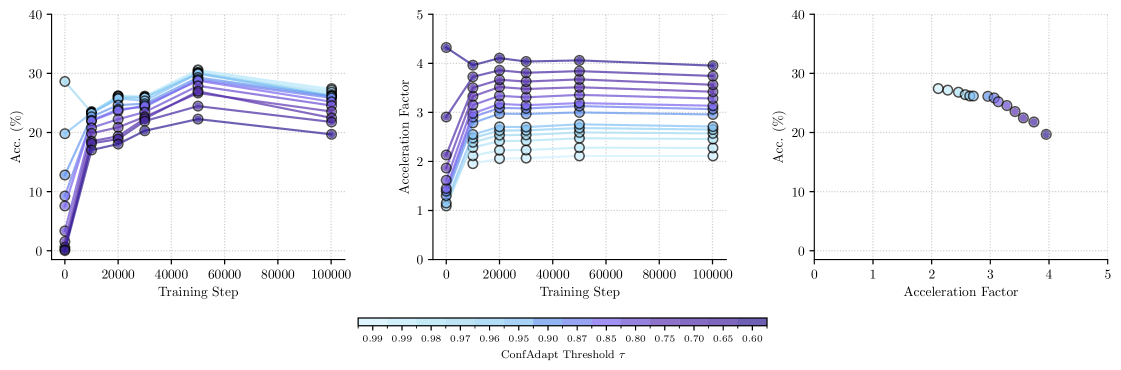
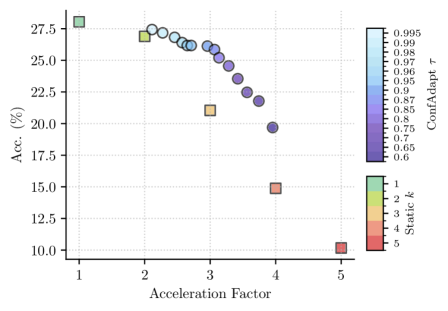
Эффективность и Масштабируемость: Кэширование и Адаптивное Декодирование
Использование кэша ключ-значение (KV Cache) значительно снижает вычислительные затраты при декодировании последовательностей. Суть подхода заключается в сохранении ранее вычисленных пар ключ-значение, возникающих в процессе обработки. Вместо повторного вычисления этих пар при каждом шаге декодирования, система извлекает их непосредственно из кэша. Это особенно эффективно для задач, где повторяющиеся шаблоны и зависимости между элементами последовательности встречаются часто. По сути, KV Cache позволяет избежать избыточных вычислений, существенно ускоряя процесс декодирования и повышая общую эффективность модели, особенно при работе с длинными последовательностями данных.
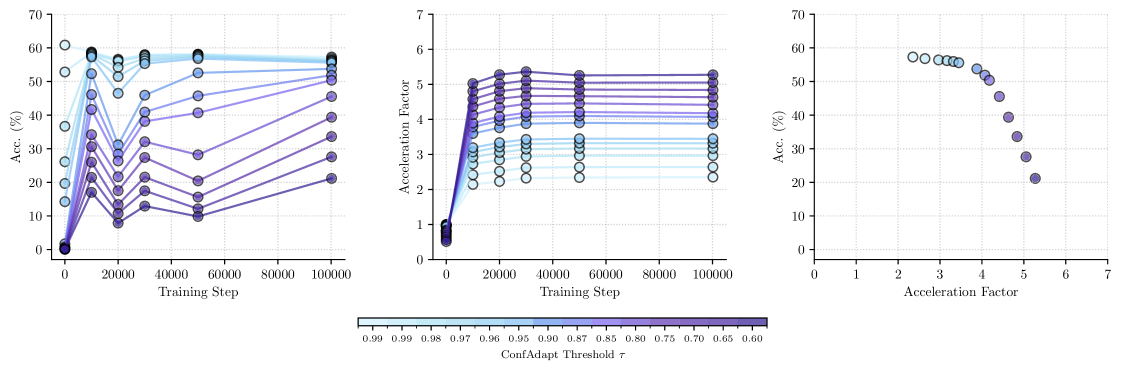
Адаптивное декодирование представляет собой инновационный подход к оптимизации процесса генерации ответов, динамически подстраивая параметры декодирования в зависимости от уверенности модели в каждом конкретном шаге. Вместо использования фиксированных настроек, система оценивает вероятность предложенных вариантов и соответствующим образом корректирует такие параметры, как температура и штраф за повторение. Это позволяет значительно ускорить генерацию, избегая ненужных вычислений в случаях высокой уверенности модели, и одновременно повысить точность за счет более тщательного анализа в ситуациях, когда требуется дополнительная проверка. В результате, достигается до пятикратное увеличение скорости работы без потери качества генерируемых ответов, что делает данный метод особенно эффективным для ресурсоемких задач, таких как решение математических задач и логические рассуждения.
Исследования показали превосходство разработанного подхода на авторитетных наборах данных, таких как GSM8K Benchmark и MetaMathQA Dataset, что подтверждает его высокую эффективность в задачах математического рассуждения. Эти наборы данных, содержащие широкий спектр математических задач различной сложности, позволили объективно оценить способность системы к решению проблем, требующих логического мышления и применения математических знаний. Достигнутые результаты свидетельствуют о значительном прогрессе в области автоматизированного решения математических задач, открывая перспективы для создания интеллектуальных систем, способных к более сложным вычислениям и анализу данных. Успешное прохождение тестов на этих наборах данных является важным подтверждением практической применимости и надежности предложенного метода.
Взгляд в Будущее: Расширение Горизонтов Ускоренного Рассуждения
В будущих исследованиях планируется интеграция механизма внимания, ориентированного на причинно-следственные связи — `CausalAttention`. Этот подход призван значительно улучшить понимание контекста и усилить способность модели к установлению долгосрочных зависимостей в тексте. В отличие от традиционных методов внимания, `CausalAttention` стремится не просто выявлять релевантные части текста, но и учитывать причинно-следственные связи между ними, что позволяет модели более глубоко понимать смысл и логику изложения. Это особенно важно для решения сложных задач, требующих анализа больших объемов информации и выявления скрытых взаимосвязей, например, в области обработки естественного языка и машинного обучения.
Исследования направлены на оценку совместимости разработанного метода с широким спектром предварительно обученных языковых моделей, включая `Llama-3.1-8B-Magpie` и `Qwen3-4B-Instruct-2507`. Такой подход позволит значительно расширить область применения данной технологии, обеспечив её адаптацию к различным архитектурам и задачам. Особое внимание уделяется интеграции с моделями, демонстрирующими высокую производительность в задачах генерации текста и понимания естественного языка. Успешная адаптация к различным платформам и моделям является ключевым шагом к созданию универсального инструмента для ускоренного рассуждения и решения сложных когнитивных задач.
Исследование потенциала данной архитектуры для решения сложных задач, таких как здравый смысл и научные открытия, представляет собой значительный шаг на пути к созданию более интеллектуальных и эффективных искусственных интеллектов. Особенный интерес представляет возможность применения этой системы для анализа больших объемов научных данных, выявления скрытых закономерностей и выдвижения новых гипотез, что может существенно ускорить процесс научных исследований. В области здравого смысла, способность архитектуры к моделированию контекста и долгосрочных зависимостей позволит ей более адекватно интерпретировать неоднозначные ситуации и принимать логически обоснованные решения, приближая ИИ к человеческому уровню понимания мира. Успешная реализация этих возможностей открывает перспективы для создания систем, способных к самостоятельному обучению, адаптации и решению сложных проблем в различных областях знаний.
Исследование демонстрирует, что традиционный подход к генерации текста, основанный на последовательном предсказании токенов, может быть существенно оптимизирован. Авторы предлагают парадигму многоточечного предсказания, которая, по сути, представляет собой своего рода реверс-инжиниринг процесса декодирования. Это позволяет модели одновременно учитывать несколько возможных продолжений, значительно ускоряя генерацию текста без существенной потери качества. Как однажды заметил Эдсгер Дейкстра: «Простота — это сложность, которая была тщательно скрыта». В данном случае, сложность алгоритма скрыта за кажущейся простотой одновременного предсказания, что позволяет добиться высокой эффективности и адаптивности в процессе генерации текста, особенно в контексте обучения с подкреплением и онлайн-обучения.
Куда же это всё ведёт?
Предложенный подход к одновременному предсказанию нескольких токенов, безусловно, интересен как попытка взломать привычную последовательность генерации текста. Однако, за ускорением всегда скрывается цена. Вопрос в том, насколько эта цена оправдана, и где именно кроется её истинная величина. Простое увеличение скорости без глубокого анализа последствий для семантики и когерентности — это лишь иллюзия прогресса. Остается неясным, как предложенная схема будет масштабироваться на более сложные задачи, требующие долгосрочного планирования и понимания контекста.
Интересно, что акцент сделан на адаптивные стратегии декодирования, что намекает на признание неидеальности самой модели. Это, своего рода, признание слабости, обернутое в техническое решение. Более того, применение принципов, заимствованных из обучения с подкреплением, вызывает вопрос о возможности создания универсального алгоритма, способного эффективно оптимизировать процесс генерации текста для различных доменов и стилей. Не станет ли этот «универсальный» алгоритм лишь еще одним сложным, но все же ограниченным инструментом?
В конечном счете, предложенная работа — это лишь один из шагов на пути к созданию действительно интеллектуальных систем генерации текста. Следующим этапом видится исследование способов интеграции предложенного подхода с другими передовыми техниками, такими как нейро-символьные вычисления и обучение с учителем, с целью создания более надежных, гибких и объяснимых моделей. Взлом системы требует постоянного обновления инструментария.
Оригинал статьи: https://arxiv.org/pdf/2602.06019.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-08 22:25