Автор: Денис Аветисян
Новая стратегия перевзвешивания потерь позволяет повысить точность глубоких нейронных сетей на наборах данных с выраженным дисбалансом классов, фокусируясь на сложных примерах редких категорий.
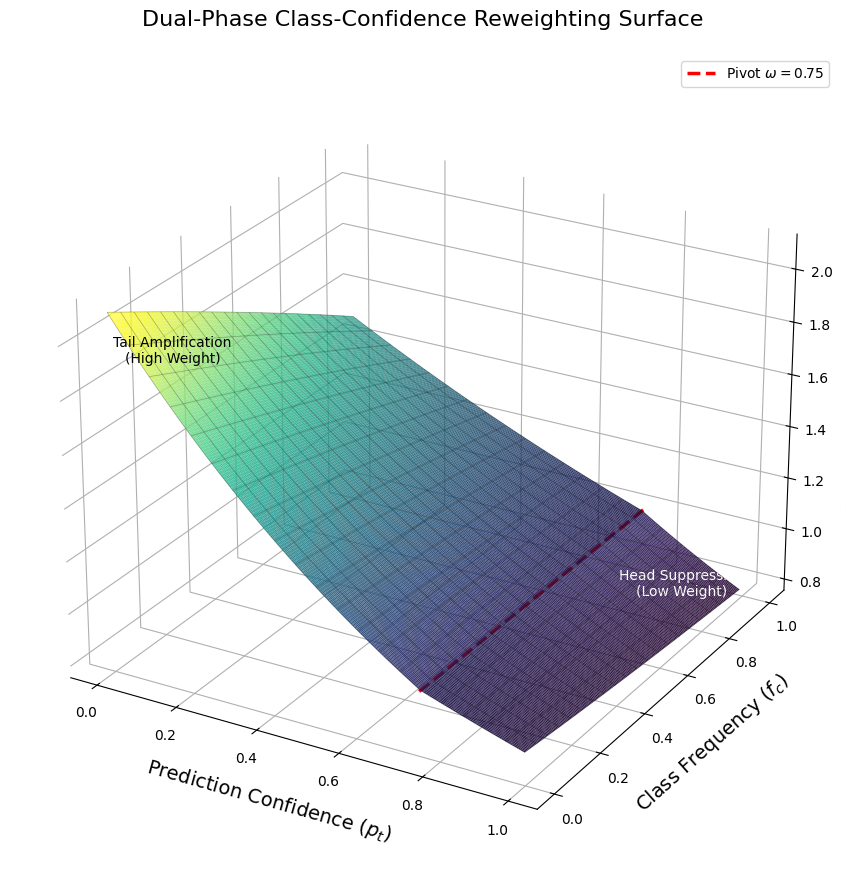
Предлагаемый метод динамически модулирует градиенты, учитывая частоту классов и уверенность предсказаний, для оптимизации обучения.
Проблема дисбаланса классов в глубоком обучении, проявляющаяся в значительном преобладании примеров из «головных» классов над «хвостовыми», существенно снижает эффективность моделей при работе с реальными данными. В данной работе, ‘Class Confidence Aware Reweighting for Long Tailed Learning’, предложен новый подход к решению этой проблемы, основанный на адаптивной перевзвешивании потерь с учетом как частоты класса, так и уверенности предсказания. Предлагаемая схема позволяет эффективно фокусироваться на сложных примерах из редких классов, повышая общую точность модели. Каким образом предложенный механизм перевзвешивания может быть интегрирован с другими современными методами борьбы с дисбалансом классов для достижения еще более значительных результатов?
Длинный хвост дисбаланса: вызов современным данным
В современных наборах данных часто наблюдается явление дисбаланса классов, когда незначительное количество категорий представлено подавляющим большинством примеров, в то время как остальные встречаются крайне редко. Этот феномен распространен в различных областях, таких как обнаружение мошеннических операций, медицинская диагностика и анализ сетевого трафика, где аномальные события, как правило, значительно уступают по количеству нормальным. Например, в задаче выявления редких заболеваний, количество пациентов с болезнью может составлять лишь малую долю от общего числа, что приводит к существенному перекосу в данных. Подобный дисбаланс представляет серьезную проблему для алгоритмов машинного обучения, поскольку они склонны отдавать предпочтение доминирующим классам, игнорируя или неправильно классифицируя экземпляры из менее представленных категорий.
Несбалансированность классов в наборах данных приводит к формированию предвзятых моделей, которые демонстрируют неудовлетворительные результаты при анализе объектов из малочисленных категорий. Это происходит из-за того, что алгоритмы машинного обучения, стремясь максимизировать общую точность, склонны игнорировать редкие классы, отдавая предпочтение более распространенным. В результате, модель может демонстрировать высокую эффективность при классификации преобладающих объектов, но ошибочно определять объекты из миноритарных классов, что существенно ограничивает её способность к обобщению и ставит под сомнение справедливость принимаемых решений, особенно в критически важных областях, таких как медицинская диагностика или обнаружение мошеннических операций. Неспособность адекватно обрабатывать редкие классы снижает надежность и практическую ценность модели в реальных условиях.
Традиционные методы машинного обучения, разработанные для сбалансированных наборов данных, часто демонстрируют неудовлетворительные результаты при работе с наборами, где классы представлены неравномерно. Это связано с тем, что алгоритмы стремятся минимизировать общую ошибку, и в условиях дисбаланса они склонны игнорировать редкие классы, поскольку их вклад в общую ошибку незначителен. Для решения этой проблемы разрабатываются специализированные техники, такие как передискретизация (oversampling) миноритарных классов, понижение дискретизации (undersampling) мажоритарных классов, а также алгоритмы, чувствительные к стоимости ошибок (cost-sensitive learning). Эти методы позволяют модели уделить больше внимания редким классам и повысить точность прогнозирования для них, что критически важно в задачах, где правильное определение миноритарного класса имеет первостепенное значение, например, в медицинской диагностике или обнаружении мошенничества.
CCAR: Индивидуальная оптимизация для каждого примера
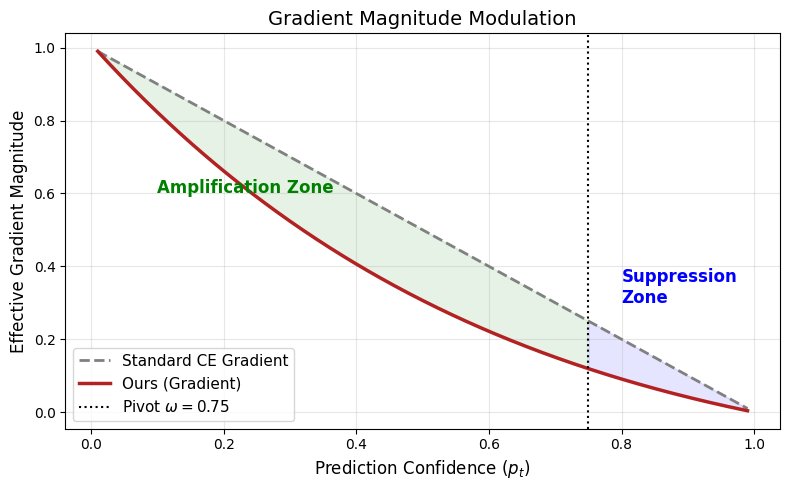
Метод CCAR представляет собой подход к оптимизации, изменяющий динамику обучения для каждого образца индивидуально. Данная модификация основывается на двух ключевых факторах: частоте класса, к которому принадлежит образец, и уверенности модели в предсказании для этого образца. Регулируя вклад каждого образца в процесс обучения на основе этих параметров, CCAR стремится к более эффективной адаптации модели к несбалансированным данным и улучшению обобщающей способности, уделяя больше внимания сложным для классификации примерам и снижая влияние легко распознаваемых.
Метод CCAR использует принцип максимальной энтропии для вывода функции взвешивания, динамически регулирующей вклад каждого образца в процессе обучения. Данный принцип позволяет определить оптимальное распределение вероятностей, максимизирующее энтропию при заданных ограничениях, в данном случае — ограничениях, связанных с частотой класса и уверенностью предсказания. Полученная функция взвешивания назначает более высокие веса образцам, которые способствуют увеличению энтропии, тем самым повышая их влияние на обновление параметров модели и способствуя более эффективному обучению, особенно в условиях несбалансированных данных или высокой уверенности в простых примерах. W_i = \frac{e^{Z_i}}{\sum_{j=1}^{N} e^{Z_j}}, где W_i — вес i-го образца, а Z_i — значение, определяемое на основе частоты класса и уверенности предсказания для данного образца.
Метод CCAR использует уверенность предсказания модели для динамической приоритизации сложных примеров и снижения влияния легко классифицируемых образцов. Это достигается путем увеличения веса примеров, для которых модель демонстрирует низкую уверенность в своих предсказаниях, что позволяет алгоритму более эффективно обучаться на сложных случаях. В результате, CCAR способствует улучшению обобщающей способности модели и, согласно проведенным экспериментам на наборе данных ImageNet-LT, позволяет достичь прироста точности до 4.02% по сравнению со стандартными подходами к оптимизации.
Проверка на сложных данных с выраженным дисбалансом
Для всесторонней оценки CCAR был проведен ряд экспериментов на сложных наборах данных с несбалансированным распределением классов, включающих ImageNet-LT, CIFAR-100-LT и iNaturalist2018. ImageNet-LT представляет собой версию ImageNet с выраженным длинным хвостом распределения классов, CIFAR-100-LT — аналогичный набор данных, основанный на CIFAR-100, а iNaturalist2018 — крупномасштабный набор изображений, содержащий данные о различных видах животных и растений с неравномерным представлением каждого вида. Использование этих наборов данных позволило оценить эффективность CCAR в условиях, приближенных к реальным задачам классификации, где часто встречается дисбаланс классов.
Результаты экспериментов показали, что CCAR демонстрирует стабильное превосходство над существующими методами, такими как Balanced Softmax, Loss Re-weighting и Logit-Level Adjustment, при оценке на наборе данных ImageNet-LT. Достигнутая точность Top-1 составила 45.62%. Данный показатель свидетельствует о более эффективной обработке данных с несбалансированным распределением классов по сравнению с альтернативными подходами, что подтверждается количественным превосходством в рамках данного бенчмарка.
При оценке на датасете CIFAR-100-LT (с коэффициентом IF=200) CCAR достиг точности Top-1 в 46.20%, что на 2.9% выше, чем у базовой модели. На датасете iNaturalist2018 CCAR показал точность Top-1 в 70.10%, превысив результат базовой модели на 0.3%. Данные результаты демонстрируют эффективность CCAR в задачах классификации изображений на несбалансированных датасетах с длинным хвостом.
Более широкие перспективы и направления дальнейших исследований
Метод CCAR представляет собой обоснованный и эффективный подход к решению проблемы дисбаланса классов, которая часто встречается в задачах машинного обучения. В отличие от многих эвристических методов, CCAR опирается на принципы, позволяющие адаптировать веса классов динамически в процессе обучения, что приводит к улучшению обобщающей способности модели. Значимость данного подхода выходит далеко за рамки классификации изображений; его можно успешно применять в различных областях, включая обнаружение объектов, обработку естественного языка и даже анализ медицинских данных, где часто встречается неравномерное распределение классов. Такая универсальность делает CCAR ценным инструментом для решения широкого спектра задач, требующих точной идентификации редких категорий или объектов.
Предложенная схема динамического взвешивания, изначально разработанная для решения проблемы дисбаланса классов в задачах классификации изображений, обладает значительным потенциалом для адаптации к широкому спектру других задач машинного обучения. В частности, принципы, лежащие в основе этой схемы, могут быть успешно применены в задачах обнаружения объектов, где количество объектов каждого класса часто неравномерно распределено. Аналогичным образом, в задачах обработки естественного языка, таких как анализ тональности или машинный перевод, где некоторые слова или фразы встречаются гораздо реже других, динамическое взвешивание может помочь модели более эффективно обучаться на редких классах, улучшая общую производительность и обеспечивая более точные результаты. Адаптация предполагает пересмотр критериев взвешивания с учетом специфики задачи и данных, однако, базовый принцип — увеличение веса редких классов — остается универсальным и эффективным.
В ходе экспериментов, комбинация предложенного подхода CCAR с методом Logit Adjustment продемонстрировала значительное повышение точности классификации на задачах с выраженным дисбалансом классов. Набор данных ImageNet-LT, характеризующийся неравномерным распределением примеров, был успешно пройден с достижением точности Top-1 в 52.76%. Аналогичные результаты получены на CIFAR-100-LT (при IF=100), где показатель Top-1 точности составил 48.91%. Эти данные подтверждают эффективность CCAR в решении проблемы дисбаланса классов и указывают на его потенциал для применения в различных областях машинного обучения, где подобные задачи встречаются достаточно часто.
Предложенная в статье стратегия перевзвешивания потерь, адаптирующая градиенты на основе частоты классов и уверенности предсказания, демонстрирует изящное понимание проблемы дисбаланса классов. Особое внимание к сложным примерам из редких классов позволяет оптимизировать процесс обучения, избегая чрезмерного упрощения модели. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть полезным, а не просто интересным». Эта мысль находит отражение в стремлении авторов создать не просто эффективный алгоритм, а инструмент, способный решать практические задачи, возникающие при работе с несимметричными данными. Истинная элегантность заключается в достижении оптимального баланса между сложностью и функциональностью, и данная работа является ярким тому подтверждением.
Куда Дальше?
Предложенная стратегия взвешивания потерь, несомненно, вносит вклад в элегантное решение проблемы дисбаланса классов. Однако, стоит признать, что оптимизация на основе уверенности предсказаний — это лишь один аспект более широкой задачи. Будущие исследования могли бы сосредоточиться на интеграции этой стратегии с механизмами самообучения, позволяющими модели самостоятельно выявлять и исправлять ошибки, особенно в тех редких классах, где достоверные метки ограничены. Иначе говоря, необходимо стремиться к системам, способным не просто адаптироваться к данным, но и активно их уточнять.
Замечательно, что предложенный подход демонстрирует улучшение на долгохвостых распределениях, но истинная проверка — это выход за пределы синтетических данных и применение к реальным, зашумленным наборам данных, где границы между классами размыты, а данные неоднородны. Особенно интересно было бы исследовать, как данная стратегия взаимодействует с архитектурами, предназначенными для обработки последовательностей или графов, где контекст и взаимосвязи между объектами играют решающую роль.
В конечном итоге, задача долгохвостового обучения — это не только вопрос улучшения точности, но и вопрос создания систем, способных к глубокому пониманию данных. Необходимо помнить, что элегантность — это не опция, а признак глубокого понимания и гармонии между формой и функцией. И в этом смысле, предложенная работа — лишь еще один шаг на пути к созданию действительно интеллектуальных систем.
Оригинал статьи: https://arxiv.org/pdf/2601.15924.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-25 19:54