Автор: Денис Аветисян
Новая разработка позволяет значительно повысить точность существующих алгоритмов машинного обучения, используя возможности больших языковых моделей и символьного анализа.
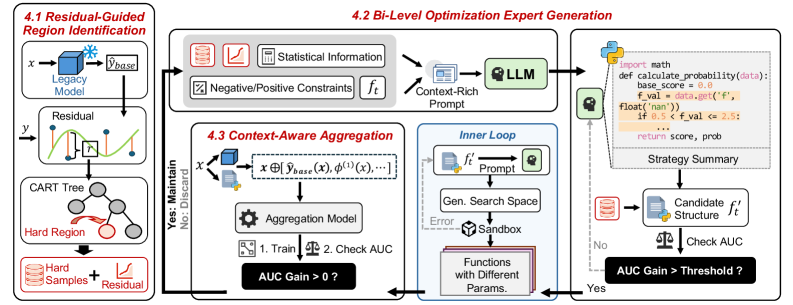
Представлен фреймворк NSR-Boost, использующий нейро-символические остаточные улучшения для повышения производительности и интерпретируемости промышленных моделей.
Несмотря на доминирование градиентного бустинга в промышленных задачах, модернизация существующих моделей в условиях высокой нагрузки сопряжена с существенными затратами и рисками. В данной работе представлена система ‘NSR-Boost: A Neuro-Symbolic Residual Boosting Framework for Industrial Legacy Models’, использующая нейро-символический подход для точечной коррекции ошибок «замороженных» моделей на основе остатков предсказаний. Ключевой особенностью является генерация интерпретируемых экспертов посредством больших языковых моделей и последующая динамическая интеграция с исходной моделью, обеспечивающая повышение производительности при минимальных затратах. Сможет ли данный подход открыть новую эру безопасной и эффективной эволюции промышленных моделей машинного обучения?
Преодолевая Застой: Расширение Возможностей Устаревших Моделей
Во многих практических приложениях, особенно в промышленности и науке, широко используются предварительно обученные модели — так называемые “устаревшие модели” или “legacy models”. Полная переподготовка или замена этих моделей сопряжена со значительными финансовыми затратами и требует существенных вычислительных ресурсов. Это связано не только с необходимостью сбора и обработки больших объемов данных, но и с затратами времени, необходимых для повторной оптимизации и интеграции новой модели в существующую инфраструктуру. Поэтому, во многих случаях, поддержание работоспособности и адаптация существующих моделей является более эффективным и экономически целесообразным решением, чем их полная замена, несмотря на появление более современных алгоритмов и технологий.
Полная замена существующих, предварительно обученных моделей зачастую игнорирует ценные знания, накопленные ими в процессе обучения и практического применения. Такой подход не только требует значительных вычислительных ресурсов для повторного обучения с нуля, но и создает существенную операционную нагрузку, связанную с внедрением и тестированием новой системы. Игнорирование накопленного опыта равносильно отказу от инвестиций в обучение и адаптацию модели к конкретным задачам, что может привести к снижению производительности и увеличению затрат на поддержание системы в долгосрочной перспективе. Вместо этого, целесообразно рассматривать возможности доработки и расширения функционала существующих моделей, используя их сильные стороны и добавляя новые возможности.
Вместо полной переподготовки или замены существующих моделей машинного обучения, все более эффективным подходом становится их дополнение специализированными компонентами. Такой метод позволяет значительно повысить производительность, не требуя колоссальных затрат на обучение с нуля. Суть заключается в сохранении ценных знаний, уже заложенных в базовой модели, и расширении ее функциональности с помощью небольших, узкоспециализированных модулей. Это особенно актуально в практических приложениях, где замена модели может быть затруднена из-за ограничений ресурсов или необходимости поддержания совместимости с существующей инфраструктурой. Дополнение позволяет адаптировать модель к новым задачам или улучшить ее работу в определенных областях, избегая при этом полной перестройки и связанных с этим рисков и издержек.

NSR-Boost: Нейро-Символический Подход к Повышению Эффективности
NSR-Boost представляет собой фреймворк, объединяющий преимущества градиентного бустинга и возможности логического вывода больших языковых моделей. Градиентный бустинг обеспечивает высокую точность и эффективность в задачах машинного обучения, в то время как большие языковые модели способны к символьной обработке и рассуждениям. Фреймворк использует языковую модель для генерации и оптимизации «экспертов» — небольших фрагментов кода, которые корректируют ошибки, допущенные базовой моделью. Такое сочетание позволяет не только повысить общую производительность, но и улучшить интерпретируемость и надежность системы, используя сильные стороны обоих подходов.
В основе подхода NSR-Boost лежит генерация так называемых “символических экспертов” — фрагментов кода, предназначенных для коррекции ошибок, допущенных базовой (legacy) моделью в определенных областях входных данных. Эти эксперты создаются на основе анализа случаев, в которых базовая модель демонстрирует низкую точность, и представляют собой специализированные функции, призванные исправить неверные предсказания. Каждый “символический эксперт” функционирует как локальный корректор, фокусируясь на конкретных типах ошибок или на определенных подмножествах входных данных, что позволяет повысить общую надежность и точность системы без переобучения всей модели.
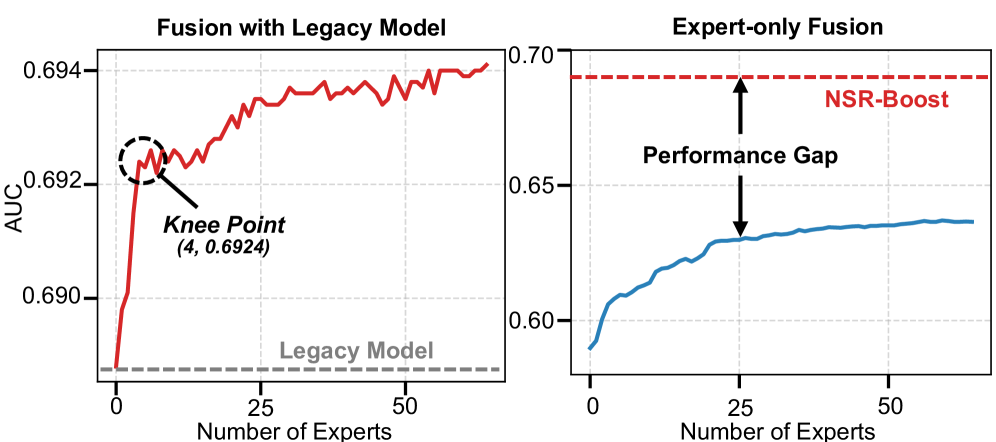
Процесс двухуровневой оптимизации, применяемый в NSR-Boost, обеспечивает точную настройку сгенерированных «символических экспертов» для коррекции ошибок базовой модели. На нижнем уровне оптимизируются параметры каждого эксперта для минимизации потерь на конкретных подмножествах данных, где базовая модель демонстрирует низкую производительность. На верхнем уровне оптимизируется гиперпараметр, определяющий вклад каждого эксперта в итоговый прогноз, что позволяет добиться плавного и эффективного объединения экспертных знаний с базовой моделью. Такая схема оптимизации позволяет избежать переобучения и гарантирует, что эксперты не ухудшают общую производительность модели, а лишь повышают ее точность в областях, где она была изначально слаба.
Выявление Ошибок и Направление Генерации Экспертов
Метод NSR-Boost использует деревья решений для выявления областей, в которых существующая (legacy) модель демонстрирует наибольшие ошибки, определяемые как “сложные регионы” (hard regions). Деревья решений строятся на основе анализа ошибок модели на обучающих данных, позволяя идентифицировать подмножества входных данных, на которых модель систематически дает неверные прогнозы. Выделение этих “сложных регионов” позволяет сфокусировать усилия по улучшению точности системы именно на тех областях, где существующая модель наиболее уязвима, что повышает эффективность последующей генерации и обучения экспертов, предназначенных для коррекции этих ошибок.
Для коррекции выявленных ошибок в “сложных регионах” применяется генерация символьных экспертов на основе больших языковых моделей, в частности Seed-OSS-36B-Instruct. Данная модель используется для автоматического создания фрагментов кода, представляющих собой специализированные функции, предназначенные для исправления конкретных типов ошибок. Сгенерированные эксперты являются символьными в том смысле, что они выражены в виде детерминированного кода, а не параметрических весов, что обеспечивает прозрачность и возможность анализа их поведения. Процесс генерации направлен на создание экспертов, способных эффективно корректировать прогнозы устаревшей модели в областях, где она демонстрирует наибольшую неточность.
Оптимизация методом Bayesian используется для точной настройки параметров сгенерированных экспертов, что позволяет максимизировать их способность к исправлению ошибок. Этот процесс включает в себя построение вероятностной модели функции, связывающей параметры эксперта с его производительностью. Алгоритм итеративно предлагает новые наборы параметров, оценивает их эффективность и обновляет вероятностную модель, стремясь найти оптимальную конфигурацию, которая обеспечит максимальную коррекцию ошибок при сохранении общей производительности системы. Bayesian оптимизация особенно эффективна в задачах, где оценка параметров является дорогостоящей или занимает много времени, поскольку она позволяет минимизировать количество необходимых оценок для достижения оптимальных результатов.
Контекстно-зависимое агрегирование представляет собой процесс динамического объединения результатов, полученных от специализированных экспертов, разработанных для коррекции ошибок, и предсказаний унаследованной модели. Этот подход не является простым усреднением; вместо этого, он использует контекстные данные для определения веса каждого источника предсказаний. Вес экспертов и унаследованной модели изменяется в зависимости от характеристик входных данных и степени уверенности каждого компонента в конкретном контексте. Данный механизм позволяет системе адаптироваться к различным сценариям и минимизировать влияние ошибок, обеспечивая более надежные и точные прогнозы, чем при использовании какой-либо модели по отдельности.
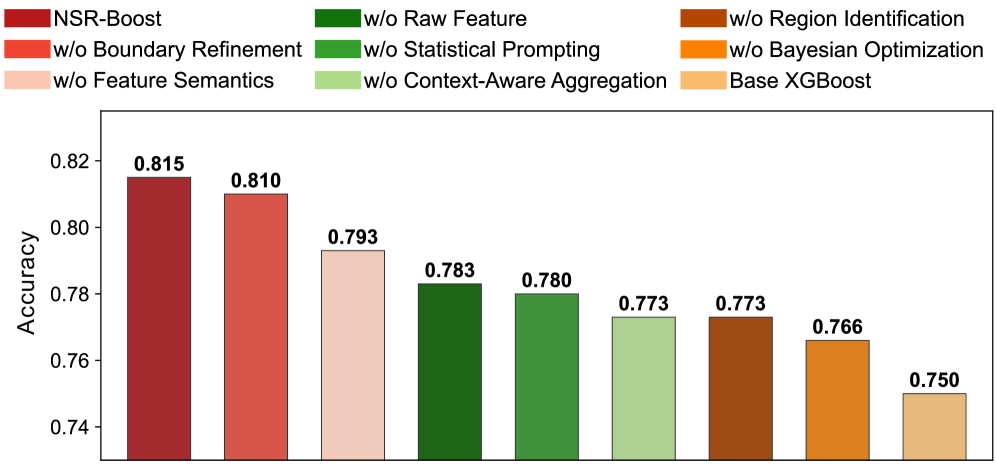
Влияние на Производительность и Интерпретируемость
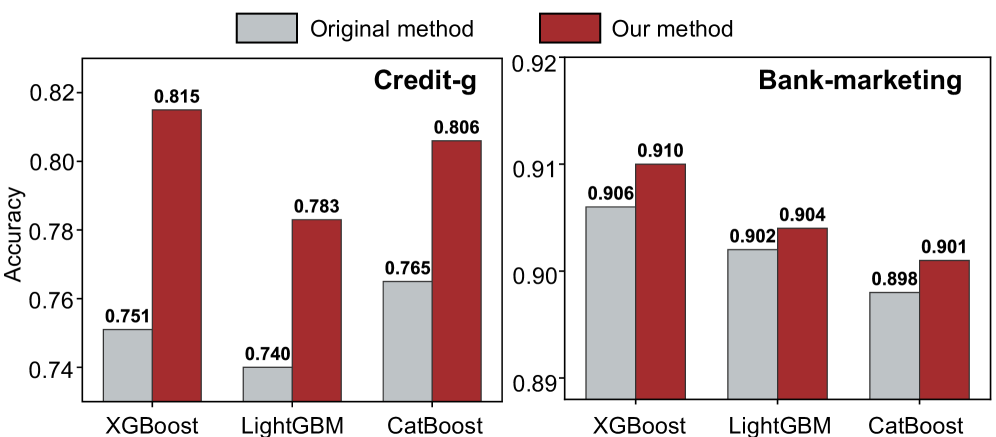
Эмпирические исследования последовательно демонстрируют превосходство NSR-Boost над широко используемыми базовыми моделями, такими как XGBoost, LightGBM, TabNet, FT-Transformer, OpenFE, AutoFeat и CAAFE. В ходе экспериментов, NSR-Boost неизменно показывал более высокие результаты на различных табличных наборах данных, что подтверждает его эффективность и надежность. Данное превосходство проявляется в улучшении ключевых метрик, что делает NSR-Boost перспективным решением для задач, требующих высокой точности и производительности при работе с табличными данными.
Исследования показали, что разработанный подход NSR-Boost демонстрирует передовые результаты на табличных данных, последовательно улучшая метрику AUC до 1.17% и KS до 1.81% при анализе реальных финансовых данных. Примечательно, что, несмотря на повышение точности, время отклика модели (inference latency) остается ниже 1 миллисекунды, что критически важно для приложений, требующих оперативной обработки информации. Такая эффективность позволяет использовать NSR-Boost в задачах, где важна не только высокая точность прогнозов, но и скорость их получения, например, в высокочастотной торговле или оценке кредитных рисков в режиме реального времени.
В основе NSR-Boost лежит принципиально новый подход к интерпретируемости моделей машинного обучения. Вместо сложных, трудночитаемых нейронных сетей, система использует набор символьных экспертов, каждый из которых отвечает за конкретную корректировку в процессе принятия решения. Изолируя эти корректирующие действия, NSR-Boost позволяет пользователям не просто видеть результат предсказания, но и понимать почему оно было сделано. Такая прозрачность достигается за счет возможности отследить вклад каждого эксперта в финальное решение, что значительно облегчает отладку модели и повышает доверие к ней, особенно в сферах, требующих строгого соответствия нормативным требованиям и высокой степени ответственности.
Повышенная прозрачность процесса принятия решений, обеспечиваемая NSR-Boost, играет ключевую роль в укреплении доверия к модели, особенно в областях, требующих высокой степени ответственности. Возможность детального анализа логики, лежащей в основе прогнозов, значительно упрощает процесс отладки и выявления потенциальных ошибок. Это особенно важно при работе с чувствительными данными, такими как финансовая информация или персональные данные, где требуется соблюдение строгих нормативных требований и обеспечение соответствия законодательству. Понимание причин, обуславливающих конкретные предсказания, позволяет не только оперативно устранять неточности, но и повышать общую надежность системы, что критически важно для принятия обоснованных и ответственных решений.
Результаты всестороннего тестирования показали, что разработанный фреймворк демонстрирует исключительную эффективность на различных публичных наборах данных. Средний ранг, достигнутый системой на шести общедоступных датасетах, составил всего 1.01, что свидетельствует о её превосходстве над другими алгоритмами машинного обучения. Такой показатель указывает на стабильно высокую производительность и способность системы занимать лидирующие позиции в рейтингах точности и эффективности, подтверждая её потенциал для решения широкого круга задач, связанных с анализом табличных данных.
Архитектура NSR-Boost отличается высокой модульностью и адаптивностью, что позволяет легко интегрировать её с различными типами табличных данных и существующими моделями. В отличие от многих других методов повышения производительности, NSR-Boost не требует полной переработки существующей инфраструктуры машинного обучения. Его компоненты разработаны таким образом, чтобы их можно было заменять и настраивать, обеспечивая гибкость при работе с разнородными наборами данных и позволяя использовать преимущества существующего модельного стека. Это особенно важно для организаций, которые стремятся улучшить свои существующие системы без значительных затрат на перестройку и повторное обучение, а также для быстрого прототипирования и тестирования новых подходов к анализу табличных данных.
Предложенный фреймворк NSR-Boost демонстрирует интересное решение проблемы старения промышленных моделей машинного обучения. Авторы предлагают не просто замену устаревших систем, а их обогащение посредством нейро-символического подхода. Этот метод позволяет добавлять корректировки, основанные на знаниях, представленных в символьном виде, что напоминает о важности сохранения “памяти” системы. Как однажды заметил Карл Фридрих Гаусс: «Если бы я мог сделать только одно открытие в своей жизни, я бы хотел, чтобы это было открытие простого и понятного способа представления знаний». В контексте NSR-Boost, именно возможность генерации символьных правил, понятных человеку, и является ключом к долговечности и интерпретируемости модели, а также к смягчению последствий технического долга.
Что Дальше?
Представленная работа демонстрирует, что даже устоявшиеся системы, чья архитектура сформировалась под давлением времени и практических нужд, способны к адаптации. Однако, вопрос не в самом факте улучшения, а в цене, которую необходимо заплатить за кажущуюся стабильность. NSR-Boost предлагает механизм “символической коррекции”, но каждая добавленная функция, каждая новая зависимость — это увеличение энтропии, приближение к неизбежному состоянию деградации. Стабильность — это иллюзия, кэшированная временем, и любое повышение производительности — лишь отсрочка, а не отмена этого принципа.
Очевидно, что автоматическое генерирование символических правил, хоть и перспективно, не решает проблему интерпретируемости в корне. Смещение ответственности за принятие решений на большую языковую модель не делает систему более понятной, а лишь перемещает «черный ящик» на другой уровень абстракции. Дальнейшие исследования должны быть сосредоточены не на поиске все более сложных коррекций, а на разработке принципиально новых методов, позволяющих строить изначально прозрачные и устойчивые системы.
Задержка — это налог, который платит каждый запрос, и оптимизация этого параметра всегда будет компромиссом между точностью и скоростью. Будущие работы могут исследовать возможности динамической адаптации символических правил, позволяя системе самообучаться и оптимизировать свою структуру в реальном времени. В конечном итоге, все системы стареют — вопрос лишь в том, делают ли они это достойно.
Оригинал статьи: https://arxiv.org/pdf/2601.10457.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- Золото прогноз
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- OM/USD
2026-01-17 13:27