Автор: Денис Аветисян
Новое исследование анализирует архитектуру трансформеров через призму графовых нейронных сетей, выявляя причины снижения производительности и предлагая пути решения.

Анализ проблем информационного смешивания, сглаживания и сжатия в трансформерах с использованием графовых нейронных сетей и оценка влияния каузальной маскировки.
Несмотря на впечатляющие успехи, современные архитектуры трансформеров демонстрируют неожиданные сбои и асимметричное снижение производительности. В работе ‘Understanding the Failure Modes of Transformers through the Lens of Graph Neural Networks’ предпринята попытка анализа этих проблем сквозь призму теории графовых нейронных сетей, выявляя узкие места в распространении информации, такие как переглаживание и пересыщение. Показано, что особенности каузальной маскировки в трансформерах приводят к предсказуемым и потенциально критическим режимам отказа. Возможно ли, объединив теоретические основания и эмпирические наблюдения, создать более устойчивые и надежные языковые модели?
Пределы Последовательной Обработки
Современные методы глубокого обучения, в особенности архитектура Transformer, широко применяются для обработки информации, представляя её как последовательность токенов. Однако, эта последовательная обработка сталкивается с трудностями при работе со сложными данными, где важны взаимосвязи между элементами, а не только их порядок. В таких случаях, когда информация имеет структуру графа — например, социальные сети, молекулярные структуры или знания — последовательная обработка становится неэффективной. Модели тратят значительные ресурсы на установление и поддержание связей, которые изначально заложены в структуре данных, вместо того чтобы напрямую использовать эти связи для решения задачи. Это ограничивает их способность эффективно моделировать и анализировать информацию, где отношения между элементами имеют решающее значение, что подчеркивает необходимость поиска альтернативных подходов к обработке данных, способных учитывать их реляционную природу.
Современные модели глубокого обучения, особенно основанные на архитектуре Transformer, сталкиваются с ограничениями при обработке данных, имеющих структуру графа. Последовательная обработка информации, являющаяся их основой, становится узким местом при анализе взаимосвязей, где элементы данных связаны друг с другом нелинейно. Это приводит к неэффективности представления и рассуждений о таких данных, поскольку модели вынуждены искусственно разворачивать сложные связи в последовательности, теряя при этом важную информацию о структуре. В результате, даже относительно простые задачи, требующие понимания отношений между элементами, могут потребовать значительно больше вычислительных ресурсов и времени, чем при использовании методов, изначально предназначенных для работы с графами.
Существенная проблема современных моделей глубокого обучения заключается в способе объединения информации. Традиционные методы, как правило, полагаются на последовательную обработку данных, что затрудняет эффективное управление потоком информации, особенно когда данные имеют сложную, нелинейную структуру. Вместо того чтобы рассматривать связи между элементами данных как равноправные и взаимодействующие, модели часто вынуждены обрабатывать их последовательно, что приводит к потере контекста и усложняет процесс рассуждений. Это особенно заметно при работе с графообразными данными, где отношения между узлами имеют решающее значение. Отсутствие надежной системы управления информационными потоками ограничивает способность моделей эффективно извлекать и использовать знания, содержащиеся в сложных взаимосвязях, и, следовательно, снижает их производительность в задачах, требующих глубокого понимания контекста и сложных взаимосвязей.

Опасность Пересглаживания и Сжатия
В архитектурах как графовых нейронных сетей (GNN), так и трансформеров наблюдается эффект “пересглаживания” ($over-smoothing$), возникающий при многократном обмене сообщениями между узлами. Данный процесс приводит к тому, что представления узлов ($Hi(l)$) становятся всё более схожими, снижая их различимость и способность сети к дифференциации. Повторные операции агрегации соседних признаков приводят к усреднению информации, что в итоге приводит к гомогенизации представлений и снижению производительности модели, особенно в задачах, требующих сохранения локальных особенностей графа или последовательности. Эффект наиболее ярко проявляется при увеличении глубины сети и часто является ограничивающим фактором для масштабирования GNN и трансформеров.
Явление “пересжатия” ($over-squashing$) возникает в архитектурах глубокого обучения, когда информация, проходящая через слои сети, сжимается в векторы фиксированного размера. Этот процесс неизбежно приводит к потере детализации и важных признаков исходных данных. Существенным аспектом является то, что сжатие информации в векторы меньшей размерности, хотя и может уменьшить вычислительную сложность, ограничивает способность сети представлять и обрабатывать сложные взаимосвязи, что негативно сказывается на точности и обобщающей способности модели. Особенно остро эта проблема проявляется при обработке графовых данных, где потеря информации о структуре и связях между узлами может существенно снизить эффективность алгоритмов.
Количественная оценка явлений пересглаживания и сжатия информации позволяет выявить слабые места в архитектуре нейронных сетей. Показатель Дирихле энергии ($δDE = 1/N ∑i∑j∈Ni ||Hi(l) — Hj(l)||22$) используется для измерения степени пересглаживания, при этом более низкие значения указывают на более выраженное пересглаживание представлений узлов. Анализ характеристик матрицы Якоби ($∂hi(r+1)/xs ≤ (αβ)^(r+1) (Ar+1)is$) позволяет оценить, как информация сжимается при передаче через слои сети, что помогает выявить узкие места и потенциальные потери важной информации. Использование этих метрик позволяет объективно сравнивать различные архитектуры и оптимизировать их для повышения производительности и предотвращения потери информации.
Эффективное сопротивление предоставляет теоретико-графовый подход к пониманию формирования информационных узких мест в графовых нейронных сетях. Данный показатель отражает сложность передачи информации между узлами графа, учитывая структуру связей и веса ребер. Высокое эффективное сопротивление между двумя узлами указывает на значительные препятствия для распространения сигнала. Параллельно, спектральный разрыв ($λ_1$) выступает в качестве прокси-метрики для количественной оценки «сжатия» информации, возникающего при использовании фиксированных векторов представления. Низкое значение спектрального разрыва свидетельствует о более сильном сжатии и, следовательно, о потенциальной потере важных деталей в представлении данных, что характерно для явления «over-squashing». Анализ этих показателей позволяет выявить архитектурные недостатки и разработать стратегии для улучшения распространения информации в графовых моделях.
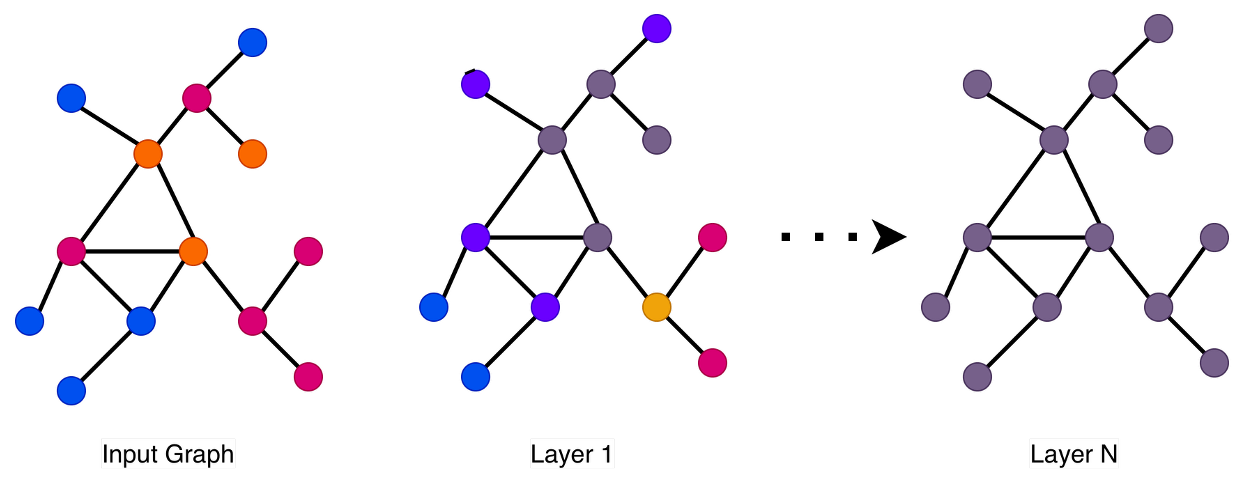
Решение Проблемы: Внимание и Маскирование
Механизм самовнимания (Self-Attention) в архитектурах Transformer, предназначенный для моделирования связей между элементами последовательности, подвержен феномену “поглощения внимания” (Attention Sink). Это проявляется в том, что модель концентрирует внимание на незначительных или шумовых элементах входной последовательности, игнорируя более важные. В результате, способность модели к истинному реляционному рассуждению, то есть выявлению и использованию значимых связей между элементами, снижается. Это происходит из-за того, что веса внимания могут быть распределены неравномерно, приводя к доминированию определенных токенов и подавлению других, даже если последние содержат ключевую информацию.
В архитектурах декодеров, использующих причинную маскировку (causal masking), для предотвращения утечки информации из будущего, возникает проблема неравномерных возможностей для уточнения информации, известная как “проблема взлетной полосы” (Runway Problem). Причинная маскировка ограничивает внимание каждого токена только предыдущими токенами последовательности, что необходимо для авторегрессивной генерации. Однако, токены, расположенные в начале последовательности, получают больше итераций внимания и, следовательно, больше возможностей для уточнения своего представления, чем токены, расположенные в конце. Это приводит к тому, что последние токены получают меньше вычислительных ресурсов для улучшения качества, что негативно сказывается на точности и когерентности генерируемого текста. Эффект усиливается с увеличением длины последовательности, поскольку разница в количестве итераций внимания между начальными и конечными токенами становится более значительной.
Механизм “Pause Tokens” представляет собой инновационный подход к решению проблемы неравномерной обработки информации в архитектурах декодеров, использующих каузальную маскировку. Суть метода заключается во введении специальных токенов, которые создают дополнительные вычислительные шаги между слоями сети. Эти шаги позволяют информации более эффективно распространяться и уточняться, избегая эффекта “Runway Problem”, когда начальные части последовательности получают больше возможностей для обработки, чем последующие. Фактически, “Pause Tokens” увеличивают вычислительное пространство, доступное для каждого элемента последовательности, что способствует более глубокому и точному анализу взаимосвязей между элементами данных. Данный подход направлен на улучшение качества обработки длинных последовательностей и повышение эффективности моделей машинного перевода и генерации текста.
Дифференциальный Трансформер использует подход с вычитающей картой внимания (subtractive attention map) для улучшения производительности модели. Вместо стандартного суммирования весов внимания, он вычитает карту внимания текущего слоя из карты предыдущего слоя. Этот процесс позволяет отфильтровать шум и нерелевантную информацию, сосредотачиваясь на наиболее значимых связях между элементами последовательности. В результате, модель способна более эффективно обрабатывать длинные последовательности и снижать влияние искажающих факторов, что приводит к повышению точности и стабильности работы, особенно в задачах машинного перевода и обработки естественного языка.
Единая Перспектива: Смешение Информации и За её Пределами
Рассмотрение глубокого обучения сквозь призму “Смешения Информации” открывает объединяющий принцип, управляющий тем, как модели комбинируют и распространяют данные. Этот подход позволяет увидеть, что, независимо от архитектуры — будь то сверточные нейронные сети или рекуррентные — фундаментальная задача заключается в эффективном обмене информацией между различными элементами модели. Вместо рассмотрения отдельных компонентов, смешение информации подчеркивает важность того, как данные преобразуются и распространяются, определяя способность модели к обучению и обобщению. Представление данных в виде графа или множества, как это делается в соответствующих архитектурах, лишь изменяет способ реализации этого смешения, но не отменяет его центральной роли. Таким образом, понимание механизмов смешения информации является ключевым для разработки более мощных и универсальных моделей глубокого обучения, способных к решению сложных задач и адаптации к новым условиям.
Как нейронные сети на графах, так и глубокие множества демонстрируют свою эффективность в обучении сложным взаимосвязям благодаря эффективному смешению информации. В основе их работы лежит способность агрегировать и распространять сведения между элементами структуры данных — будь то узлы графа или элементы множества. Этот процесс смешения, по сути, позволяет моделям улавливать зависимости, которые не были бы очевидны при рассмотрении отдельных компонентов. Например, в графовых нейронных сетях, информация от соседних узлов смешивается для обновления представления каждого узла, что позволяет модели понимать контекст и отношения между объектами. Аналогично, глубокие множества агрегируют информацию от всех элементов множества, чтобы сформировать общее представление, игнорируя порядок элементов и размер множества. Таким образом, эффективное смешение информации является ключевым механизмом, обеспечивающим способность этих архитектур к обобщению и решению сложных задач.
Несмотря на успехи в области нейронных сетей, проблема “недостаточной досягаемости” — ограниченность распространения информации на большие расстояния внутри архитектуры — остаётся существенным препятствием для графовых нейронных сетей и Deep Sets. Это явление приводит к тому, что узлы, расположенные далеко друг от друга, не могут эффективно обмениваться информацией, что снижает способность модели улавливать сложные взаимосвязи и обобщать данные. В частности, при обработке графов с большим количеством узлов или сложных взаимосвязей, информация от удалённых узлов может быть существенно ослаблена или полностью потеряна, ограничивая способность модели к глобальному пониманию структуры данных. Преодоление этой проблемы требует разработки новых методов, способствующих более эффективному распространению информации на большие расстояния, что позволит создавать модели, способные к более надёжному и комплексному анализу данных.
Оптимизация процесса смешения информации является фундаментальным фактором для создания моделей глубокого обучения, способных к надежному рассуждению и обобщению. Эффективное смешение позволяет информации распространяться по всей структуре модели, устанавливая связи между отдаленными элементами данных и выявляя сложные закономерности. Недостаточное смешение, напротив, ограничивает возможности модели, не позволяя ей улавливать глобальные зависимости и делать обоснованные выводы. В конечном итоге, совершенствование механизмов смешения информации открывает путь к созданию искусственного интеллекта, способного не просто запоминать данные, но и понимать их, адаптироваться к новым ситуациям и решать сложные задачи, требующие критического мышления и способности к экстраполяции.

Исследование демонстрирует, что архитектура Transformer, несмотря на свою эффективность, подвержена проблемам, аналогичным тем, что возникают в графовых нейронных сетях — пересглаживанию и пережатию информации. Это приводит к искажению причинно-следственных связей и вносит систематическую ошибку, обусловленную позиционным смещением. Как отмечал Эдсгер Дейкстра: «Простота — это высшая степень совершенства». Данная работа подтверждает эту мысль, показывая, что сложность архитектуры Transformer может приводить к неожиданным ограничениям в распространении информации, подчеркивая необходимость поиска более элегантных и понятных решений для построения эффективных моделей обработки последовательностей.
Куда Далее?
Представленный анализ, рассматривающий трансформаторы сквозь призму графовых нейронных сетей, неизбежно указывает на фундаментальную сложность этих архитектур. Выявление проблем, связанных с перемешиванием информации, сглаживанием и «передавливанием», — это не решение, а лишь более четкая формулировка вопроса. Каждое «улучшение», каждая оптимизация создает новые узлы напряжения, новые потенциальные точки отказа. Следующим шагом представляется не поиск «волшебной» архитектуры, а глубокое понимание принципов, управляющих распространением информации в подобных системах.
Особое внимание следует уделить влиянию каузальной маскировки. Наблюдаемая зависимость от позиций — это не просто артефакт, а следствие структуры, определяющей поведение. Попытки обойти это ограничение, вероятно, столкнутся с необходимостью переосмысления самого принципа внимания, отказавшись от упрощенных моделей и обратившись к более сложным представлениям о причинно-следственных связях.
В конечном счете, архитектура — это поведение системы во времени, а не схема на бумаге. Будущие исследования должны сосредоточиться на динамических свойствах трансформаторов, на том, как информация течет и изменяется в процессе обработки, а не только на статических характеристиках их компонентов. Истинное понимание придет не от создания новых моделей, а от умения видеть красоту и сложность в существующих.
Оригинал статьи: https://arxiv.org/pdf/2512.09182.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2025-12-11 11:02