Автор: Денис Аветисян
В новой работе исследователи предлагают инновационный подход к построению трансформеров, заменяя стандартные слои внимания и прямой связи на более эффективные структуры, вдохновленные теорией непрерывных дробей.

Предлагаемая архитектура CoFrGeNet обеспечивает сопоставимую производительность с уменьшенным количеством параметров и повышенной вычислительной эффективностью.
Трансформеры, несмотря на свою эффективность, требуют значительных вычислительных ресурсов и большого количества параметров для генерации текста. В данной работе, посвященной разработке архитектуры CoFrGeNet: Continued Fraction Architectures for Language Generation, предложен новый класс функций, вдохновленный продолженными дробями, для создания генеративных моделей. Разработанные компоненты, заменяющие механизмы внимания и полносвязные сети в блоках трансформеров, позволяют добиться сопоставимой производительности с меньшим количеством параметров и временем предварительного обучения. Смогут ли эти архитектуры, оптимизированные под специфическое аппаратное обеспечение, раскрыть свой истинный потенциал и открыть новую эру эффективной генерации текста?
Взлом Внимания: Основы Нового Подхода к Языковому Моделированию
Архитектура Transformer, несмотря на свою эффективность в обработке последовательностей, в значительной степени опирается на механизмы внимания. Однако, вычислительная сложность этих механизмов растет квадратично с увеличением длины последовательности, что становится критическим ограничением при работе с длинными текстами или большими объемами данных. Каждый токен в последовательности должен сравниваться со всеми остальными, что требует значительных ресурсов памяти и времени обработки. Это препятствует масштабированию моделей Transformer для решения задач, требующих анализа длинных контекстов, таких как обработка книг, научных статей или длительных диалогов. Таким образом, необходимость в более эффективных альтернативах механизмам внимания становится все более актуальной для дальнейшего развития языкового моделирования.
Существующие методы построения языковых моделей сталкиваются с трудностями при одновременном обеспечении оптимального баланса между размером модели, временем обучения и скоростью обработки данных. Увеличение масштаба модели, необходимое для достижения более высокой точности, неизбежно приводит к увеличению вычислительных затрат и времени обучения, что становится серьезным препятствием для практического применения. В то же время, стремление к ускорению обработки данных часто требует упрощения модели, что негативно сказывается на ее способности понимать сложные языковые конструкции и контекст. Этот компромисс ограничивает возможности масштабирования моделей и их адаптации к задачам, требующим обработки больших объемов данных в режиме реального времени, что является критичным для многих современных приложений, таких как машинный перевод, анализ тональности и виртуальные ассистенты.
Необходимость в новом подходе к построению языковых моделей обусловлена ограничениями, присущими существующим архитектурам, таким как зависимость от механизмов внимания. Эти механизмы, хоть и эффективны, становятся вычислительно затратными при работе с длинными последовательностями текста, что препятствует масштабируемости и практическому применению. Разработка более эффективной основы, не полагающейся столь сильно на внимание, позволит создавать модели, способные обрабатывать большие объемы информации быстрее и с меньшими затратами ресурсов. Такой прорыв откроет возможности для создания более совершенных систем обработки естественного языка, способных решать сложные задачи, такие как машинный перевод, генерация текста и анализ больших данных, с невиданной ранее скоростью и точностью.
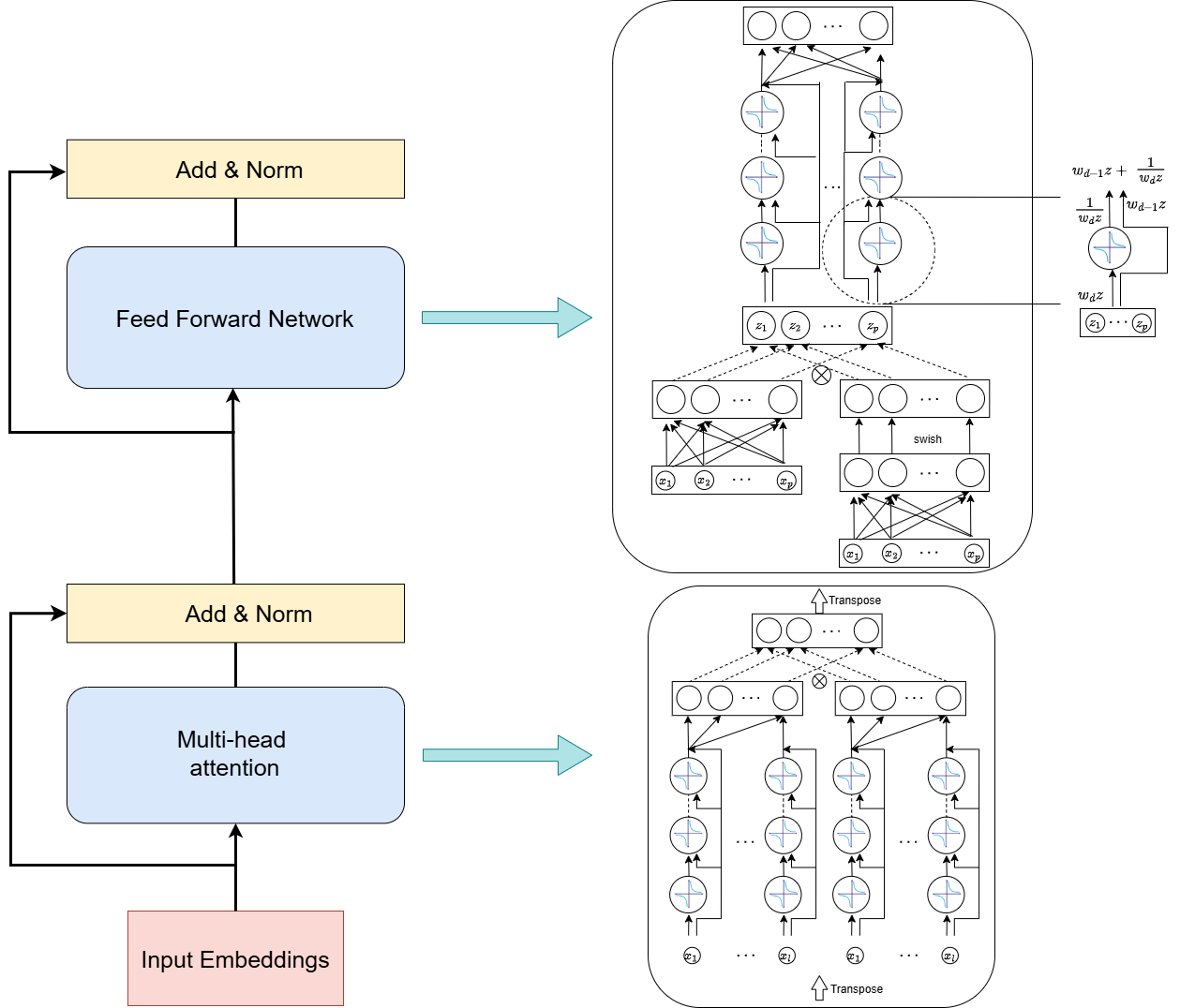
CoFrNet: Непрерывные Дроби для Эффективного Моделирования
Архитектура CoFrNet представляет собой новую структуру, основанную на использовании непрерывных дробей, предлагающую альтернативу механизмам внимания и полносвязным слоям (feed-forward networks). В отличие от традиционных подходов, CoFrNet использует рекурсивное применение линейных преобразований, определяемых коэффициентами непрерывной дроби, для моделирования зависимостей между входными данными. Такой подход позволяет представить сложные функции с использованием меньшего количества параметров и вычислений по сравнению с традиционными архитектурами, что потенциально приводит к повышению эффективности и снижению вычислительных затрат. Основная идея заключается в аппроксимации целевой функции посредством c_0 + \frac{1}{c_1 + \frac{1}{c_2 + ...}} , где c_i — линейные слои, обрабатывающие входные данные.
Архитектура CoFrNet использует математические свойства непрерывных дробей для снижения вычислительной сложности модели без потери выразительной способности. Непрерывные дроби позволяют аппроксимировать функции с высокой точностью, используя ограниченное количество операций. В CoFrNet это достигается за счет последовательного применения линейных слоев и операций смешивания токенов, что позволяет модели эффективно обрабатывать входные данные и представлять сложные зависимости. Использование непрерывных дробей позволяет более компактно представлять модели по сравнению с традиционными подходами, основанными на полносвязных слоях, что приводит к снижению количества параметров и, как следствие, уменьшению вычислительных затрат. \frac{1}{a_1 + \frac{1}{a_2 + \frac{1}{a_3 + ...}}} — общая форма непрерывной дроби, где a_i — коэффициенты.
Архитектура CoFrNet построена на использовании линейных слоев и механизма каузального смешивания токенов (causal token mixing) для обеспечения эффективных вычислений и сохранения информации о последовательности входных данных. Линейные слои снижают вычислительную сложность по сравнению с нелинейными операциями, часто используемыми в традиционных нейронных сетях. Каузальное смешивание токенов гарантирует, что при обработке каждого токена учитывается только информация из предыдущих токенов в последовательности, что необходимо для задач, чувствительных к порядку, таких как обработка естественного языка. Это достигается за счет применения маски, ограничивающей доступ к будущим токенам, и позволяет сети эффективно обрабатывать последовательности переменной длины без потери информации о временной зависимости.
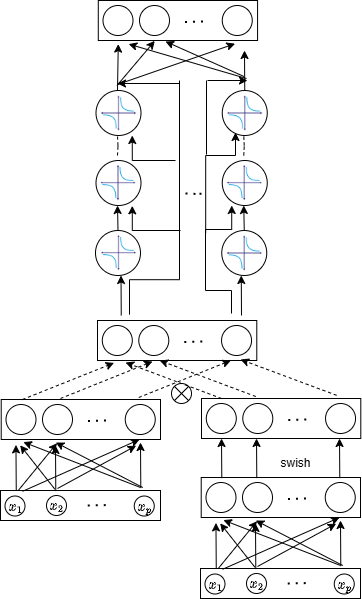
Оптимизация CoFrNet: Обучение и Вычислительная Эффективность
В процессе обучения CoFrNet используется схема обновления параметров, основанная на диадическом подходе. Данная схема предполагает дискретное изменение масштаба параметров на степени двойки в процессе оптимизации, что позволяет стабилизировать процесс обучения за счет предотвращения слишком больших или слишком малых шагов. Это также способствует ускорению сходимости модели, поскольку более крупные шаги в начале обучения и более мелкие шаги на поздних этапах позволяют эффективно исследовать пространство параметров и находить оптимальные значения. В отличие от традиционных методов, использующих непрерывные скорости обучения, диадическая схема упрощает процесс настройки и повышает устойчивость обучения.
Реализация CoFrNet основана на методе продолжения вычислений, что позволяет минимизировать количество операций деления, необходимых в процессе вычислений. Операции деления, особенно при работе с обратными величинами, могут быть вычислительно затратными и приводить к снижению эффективности. Использование продолжения вычислений позволяет избежать прямых операций деления, заменяя их более эффективными вычислениями, что оптимизирует производительность модели и снижает потребление ресурсов.
Оценка CoFrNet проводилась на наборе задач GLUE (General Language Understanding Evaluation), включающем в себя широкий спектр задач обработки естественного языка, таких как определение логической зависимости, анализ текстового сходства и вывод логических следствий. Результаты экспериментов демонстрируют, что CoFrNet достигает сопоставимых или превосходящих показателей точности по сравнению с традиционными Transformer-моделями на большинстве задач GLUE. Это подтверждает эффективность предложенной архитектуры и её способность к обобщению на различные типы лингвистических задач, что делает CoFrNet конкурентоспособным решением в области обработки естественного языка.
Обучение модели CoFrNet позволяет сократить время обучения до 2 дней по сравнению с оригинальной моделью Llama. Данное ускорение достигается за счет оптимизации процесса обновления параметров и снижения вычислительных издержек. Экспериментальные данные демонстрируют, что использование CoFrNet существенно повышает эффективность обучения, особенно при работе с большими объемами данных и сложными архитектурами нейронных сетей. Сокращение времени обучения напрямую влияет на стоимость и скорость разработки, позволяя быстрее итеративно улучшать модели и проводить эксперименты.

CoFrNet в Действии: Сравнительная Производительность и Масштабируемость
Оценки, проведенные на стандартных эталонных наборах данных для языкового моделирования, демонстрируют, что CoFrNet достигает сопоставимых показателей перплексии с передовыми моделями. Это подтверждает способность архитектуры эффективно моделировать языковые закономерности и прогнозировать последовательности токенов. Полученные результаты указывают на то, что CoFrNet не уступает в качестве языкового моделирования более сложным и ресурсоемким аналогам, обеспечивая при этом потенциальные преимущества в плане эффективности и масштабируемости. Высокие показатели перплексии свидетельствуют о том, что модель способна хорошо обобщать информацию и генерировать правдоподобный текст.
Архитектура CoFrNet демонстрирует значительное снижение количества параметров и вычислительных затрат по сравнению с традиционными моделями Transformer. Это достигается благодаря инновационному подходу к обработке последовательностей, что позволяет существенно ускорить как процесс обучения, так и последующее инференс. Сокращение вычислительной нагрузки открывает возможности для развертывания модели на устройствах с ограниченными ресурсами и для обработки больших объемов данных в реальном времени, делая CoFrNet перспективным решением для широкого спектра задач, где важны скорость и эффективность.
Исследования показали, что CoFrNet демонстрирует скорость вывода, превосходящую стандартные реализации моделей-трансформеров почти в десять раз. Этот значительный прирост производительности обусловлен оптимизированной архитектурой, позволяющей существенно сократить время обработки данных без потери качества генерируемого текста. Подобное ускорение делает CoFrNet особенно привлекательным для приложений, требующих быстрого отклика, таких как чат-боты, системы машинного перевода и другие задачи, где задержка является критическим фактором. Фактически, сокращение времени вывода открывает новые возможности для развертывания сложных языковых моделей на устройствах с ограниченными ресурсами и в реальном времени.
Интеграция архитектуры CoFrNet с моделью Llama наглядно демонстрирует её адаптивность и широкие возможности применения. Исследования показывают, что CoFrNet успешно взаимодействует с существующими нейронными сетями, такими как Llama, не требуя значительных изменений в их структуре. Это позволяет использовать преимущества CoFrNet — снижение вычислительных затрат и ускорение инференса — в различных задачах обработки естественного языка, включая генерацию текста, машинный перевод и анализ тональности. Возможность бесшовной интеграции открывает путь к разработке более эффективных и экономичных решений, использующих передовые языковые модели в широком спектре приложений, от мобильных устройств до масштабных облачных сервисов.
Будущее CoFrNet: Расширение Возможностей
Исследования показывают, что внедрение разреженных механизмов внимания, подобных используемым в архитектурах Synthesizer, способно значительно повысить эффективность и масштабируемость CoFrNet. Традиционные механизмы внимания требуют квадратичного количества вычислений относительно длины последовательности, что становится узким местом при работе с длинными текстами. В отличие от них, разреженные механизмы внимания, такие как используемые в Synthesizer, позволяют сосредоточиться на наиболее релевантных частях входных данных, существенно снижая вычислительную сложность. Использование этих методов в CoFrNet потенциально может позволить обрабатывать более длинные последовательности и более сложные задачи, сохраняя при этом приемлемую скорость работы и снижая потребность в вычислительных ресурсах. Такой подход открывает перспективы для применения CoFrNet в областях, требующих обработки больших данных, таких как обработка естественного языка, анализ видео и распознавание речи.
Исследование возможностей применения CoFrNet в задачах мультимодального обучения и других сложных сценариях открывает захватывающие перспективы для развития искусственного интеллекта. Архитектура CoFrNet, благодаря своей способности эффективно обрабатывать и интегрировать информацию из различных источников, может быть успешно адаптирована для решения задач, требующих понимания взаимосвязей между текстом, изображениями, звуком и другими типами данных. Предполагается, что применение CoFrNet в мультимодальных системах позволит создавать более интеллектуальные и адаптивные алгоритмы, способные решать сложные проблемы, такие как автоматический перевод, анализ видеоконтента и разработка интеллектуальных ассистентов нового поколения. Дальнейшее исследование позволит не только улучшить существующие методы, но и открыть принципиально новые подходы к созданию искусственного интеллекта, приближая его к человеческому уровню понимания и рассуждения.
Дальнейшая оптимизация архитектуры CoFrNet и процедур обучения представляется ключевым фактором для полного раскрытия её потенциала и обеспечения широкого внедрения. Исследования в этой области направлены на повышение эффективности алгоритмов, снижение вычислительных затрат и улучшение обобщающей способности модели. Уточнение гиперпараметров, разработка новых методов регуляризации и применение передовых техник оптимизации, таких как адаптивные алгоритмы обучения, могут существенно повысить производительность CoFrNet на различных задачах. Кроме того, изучение возможности применения квантизации и прунинга позволит сократить размер модели и ускорить её работу, что особенно важно для развертывания на устройствах с ограниченными ресурсами. Постоянное совершенствование этих аспектов позволит CoFrNet стать более доступным и эффективным инструментом для решения широкого спектра задач искусственного интеллекта.
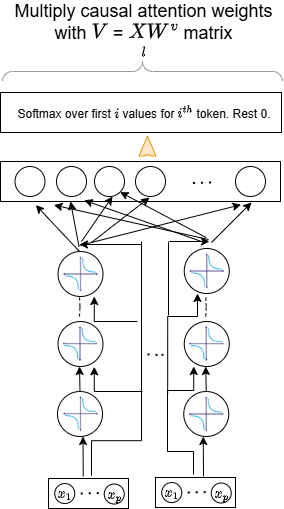
Исследование, представленное в данной работе, демонстрирует стремление к переосмыслению базовых компонентов трансформаторных сетей. Авторы не просто оптимизируют существующие механизмы внимания и прямых связей, а предлагают принципиально иную архитектуру, вдохновлённую математическим аппаратом непрерывных дробей. Это подход, в котором система подвергается намеренному разрушению устоявшихся правил ради поиска более эффективной реализации. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что невозможно». В данном контексте, «невозможное» — это достижение сопоставимой производительности при значительном снижении вычислительных затрат и количества параметров, что и подтверждается результатами, представленными в работе. Использование непрерывных дробей в качестве альтернативы традиционным компонентам — это пример глубокого анализа системы и её переосмысления, направленного на достижение оптимальной эффективности.
Куда же дальше?
Представленные архитектуры, вдохновленные непрерывными дробями, демонстрируют, что привычные блоки трансформеров — внимание и полносвязные сети — не являются единственно возможными. Это не отменяет их эффективности, но ставит под сомнение их фундаментальную необходимость. По сути, исследование предлагает новый взгляд на то, как можно структурировать информацию, избегая экспоненциального роста вычислительных затрат. Однако, вопрос о том, насколько универсален этот подход, остается открытым. Смогут ли подобные архитектуры эффективно масштабироваться для решения задач, требующих понимания сложного контекста и долгосрочной памяти, — это область для дальнейшего изучения.
Очевидным направлением является исследование различных способов реализации и оптимизации непрерывных дробей в нейронных сетях. Вариации в выборе функций, используемых в структуре, и методов их обучения могут привести к существенным улучшениям в производительности и эффективности. Более того, интересно исследовать, как данная архитектура взаимодействует с другими современными подходами к генерации текста, такими как sparse attention или state space models. Не стоит забывать, что истинный прогресс часто возникает на стыке разных идей.
В конечном счете, данная работа напоминает, что хаос — не враг, а зеркало архитектуры, отражающее скрытые связи. Попытка найти более элегантные и эффективные способы представления информации — это не просто техническая задача, но и философский поиск. Вопрос не в том, чтобы создать более мощные модели, а в том, чтобы понять, как информация организована в самой реальности.
Оригинал статьи: https://arxiv.org/pdf/2601.21766.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-02 04:52