Автор: Денис Аветисян
Новое исследование предлагает экономическую модель для проверки соответствия систем искусственного интеллекта требованиям по удалению данных, обеспечивая защиту конфиденциальности пользователей.
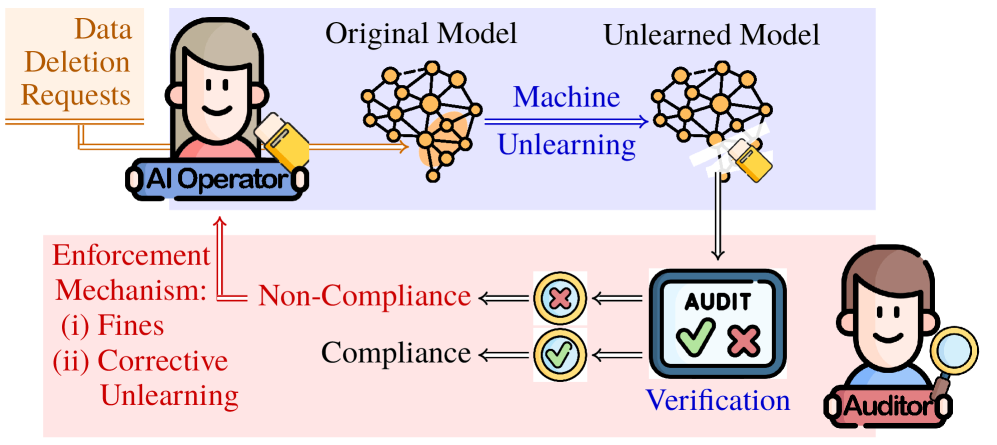
В статье рассматриваются методы аудита машинного разучения для подтверждения удаления данных по запросу и повышения прозрачности в соответствии с нормативными требованиями.
Несмотря на юридические требования к праву на забвение, операторы ИИ регулярно не соблюдают запросы на удаление данных. В работе ‘Governing AI Forgetting: Auditing for Machine Unlearning Compliance’ предложена новая экономическая модель аудита соответствия процедурам машинного забывания (MU), интегрирующая сертифицированную теорию MU и механизмы регуляторного контроля. Ключевым результатом является установление, что оптимальная интенсивность проверок может снижаться при увеличении количества запросов на удаление данных, а прозрачность аудита, напротив, повышает её эффективность. Какие экономические стимулы могут быть разработаны для обеспечения эффективного соблюдения права на забвение в эпоху развития искусственного интеллекта?
Рождение права на забвение: вызовы машинного обучения
Растущее число нормативных актов в области защиты данных, таких как Общий регламент по защите данных (GDPR), предоставляет гражданам право на забвение, что создает значительные трудности для систем машинного обучения. Этот принцип требует от организаций удалять личную информацию по запросу субъекта данных, что традиционно требовало полной переподготовки моделей. Однако, учитывая экспоненциальный рост объемов данных и сложность современных алгоритмов, полная переподготовка становится непомерно дорогостоящей и непрактичной. Поэтому обеспечение соответствия праву на забвение в контексте машинного обучения требует разработки инновационных подходов, позволяющих эффективно удалять влияние конкретных данных из модели без необходимости ее полного обновления, что является ключевой задачей для разработчиков и регуляторов.
В эпоху экспоненциального роста объемов данных, переобучение моделей машинного обучения при удалении информации о конкретном пользователе или записи становится непомерно затратным и непрактичным. Традиционные методы требуют повторной обработки всего набора данных, что влечет за собой колоссальные вычислительные ресурсы и время, особенно для масштабных моделей, используемых в современных приложениях. Представьте себе, что необходимо удалить данные одного пользователя из модели, обученной на миллионах записей — это равносильно полной реконструкции системы. В связи с этим, возникает острая необходимость в разработке альтернативных, более эффективных подходов, способных избирательно «забывать» определенные данные, минимизируя при этом затраты и обеспечивая сохранение общей производительности модели.
Механизм “забывания” данных (Machine Unlearning, MU) представляет собой перспективное решение для соблюдения растущих требований к конфиденциальности. В отличие от традиционной переподготовки моделей, требующей значительных вычислительных ресурсов и времени, MU позволяет выборочно исключать влияние конкретных данных из обученной модели. Этот подход не требует полного повторного обучения, что особенно важно при работе с огромными массивами информации. Вместо этого, алгоритмы MU стремятся минимизировать вклад “удаляемых” данных, сохраняя при этом общую производительность и точность модели. Таким образом, MU открывает путь к более эффективному и экономичному управлению данными в контексте права на забвение и других нормативных актов, регулирующих обработку персональной информации.
Крайне важна эффективность машинного забывания (MU), поскольку неспособность должным образом удалить данные может привести к серьезным юридическим и репутационным последствиям. В эпоху ужесточения правил конфиденциальности, таких как GDPR, организации обязаны обеспечивать полное исполнение права на забвение. Недостаточное удаление данных, даже при формальном соблюдении процедуры, может повлечь за собой крупные штрафы и судебные разбирательства. Более того, сохранение личной информации в моделях машинного обучения, несмотря на запросы на удаление, способно нанести непоправимый ущерб репутации компании, подорвать доверие клиентов и привести к значительным финансовым потерям. Таким образом, надежные методы машинного забывания становятся не просто технологической необходимостью, а критически важным элементом обеспечения соответствия законодательству и поддержания положительного имиджа.
Сертифицированное удаление данных: математическая основа надежности
Теория сертифицированного забывания (Certified Unlearning) предоставляет строгую математическую основу для доказательства того, что модель статистически неотличима от модели, обученной без удаленных данных. В отличие от эмпирических методов, полагающихся на снижение функции потерь, сертифицированное забывание использует формальные математические инструменты для установления гарантии удаления данных. Это достигается путем проверки, что распределение вероятностей предсказаний модели после удаления данных не отличается от распределения, которое было бы получено, если бы данные никогда не использовались при обучении. Формально, это можно выразить как P(y|x;M,D) = P(y|x;M',D\setminus S), где M — исходная модель, M' — модель после удаления данных из набора S из обучающего набора D, а P(y|x) — вероятность предсказания y для входных данных x. Данное равенство доказывает статистическую неотличимость моделей.
Сертификация удаления данных выходит за рамки простого достижения низкой величины функции потерь; она устанавливает формальную гарантию удаления данных. Традиционные методы обучения моделей оценивают производительность на основе обобщающей способности, но не предоставляют доказательств того, что влияние конкретных данных было полностью устранено. Сертификация, напротив, предоставляет математически доказуемое утверждение о том, что обученная модель статистически неотличима от модели, обученной без удаленных данных. Это достигается путем определения границ на изменение параметров модели после «забывания», обеспечивая, что удаление данных не приводит к заметному ухудшению производительности или раскрытию информации об удаленных данных. Такая гарантия основана на строгих математических критериях и обеспечивает более высокий уровень уверенности в соблюдении требований конфиденциальности и защиты данных.
Методы машинного разучения с удалением данных (MU), такие как Hessian-Free MU, используют строгий математический аппарат, заложенный в теорию сертифицированного удаления (Certified Unlearning), для обеспечения доказуемого удаления информации. В отличие от традиционных подходов, где удаление данных основывается на снижении функции потерь, MU-методы стремятся к статистической неотличимости модели, обученной после удаления данных, от модели, обученной без этих данных. Это достигается за счет применения специализированных алгоритмов, которые изменяют параметры модели таким образом, чтобы влияние удаленных данных было формально исключено, что позволяет предоставить математически обоснованные гарантии конфиденциальности.
Уровень сертификации удаления данных (Unlearning Certification Level) представляет собой количественную метрику, используемую для оценки степени удаления данных из модели машинного обучения. Этот уровень, выражаемый в числовом значении, позволяет формально подтвердить, насколько полно и эффективно были удалены следы конкретных данных, что критически важно для соответствия нормативным требованиям, таким как GDPR и CCPA. Высокий уровень сертификации подтверждает, что модель после удаления данных статистически неотличима от модели, обученной без этих данных, обеспечивая надежную гарантию конфиденциальности и защиты персональных данных. Для определения этого уровня применяются различные методы и алгоритмы, позволяющие измерить степень влияния удаленных данных на поведение модели и оценить эффективность процесса удаления.

Экономические стимулы и аудит: обеспечение соответствия в эпоху ИИ
Экономическая система аудита представляет собой структуру, предназначенную для стимулирования и обеспечения соблюдения запросов на удаление данных. Данная система основывается на создании экономических стимулов, побуждающих операторов искусственного интеллекта (ИИ) соблюдать права субъектов данных на удаление их персональной информации. Механизм функционирует посредством сочетания инспекционной интенсивности — уровня усилий, затрачиваемых на аудит — и штрафов за несоблюдение. Штрафы, действующие как экономическое давление, мотивируют операторов ИИ приоритизировать соблюдение требований по удалению данных, а инспекционная интенсивность обеспечивает проверку эффективности реализованных механизмов “забывания” (machine unlearning). Таким образом, экономическая система аудита обеспечивает соблюдение требований законодательства о защите данных и способствует созданию прозрачной и подотчетной среды в сфере искусственного интеллекта.
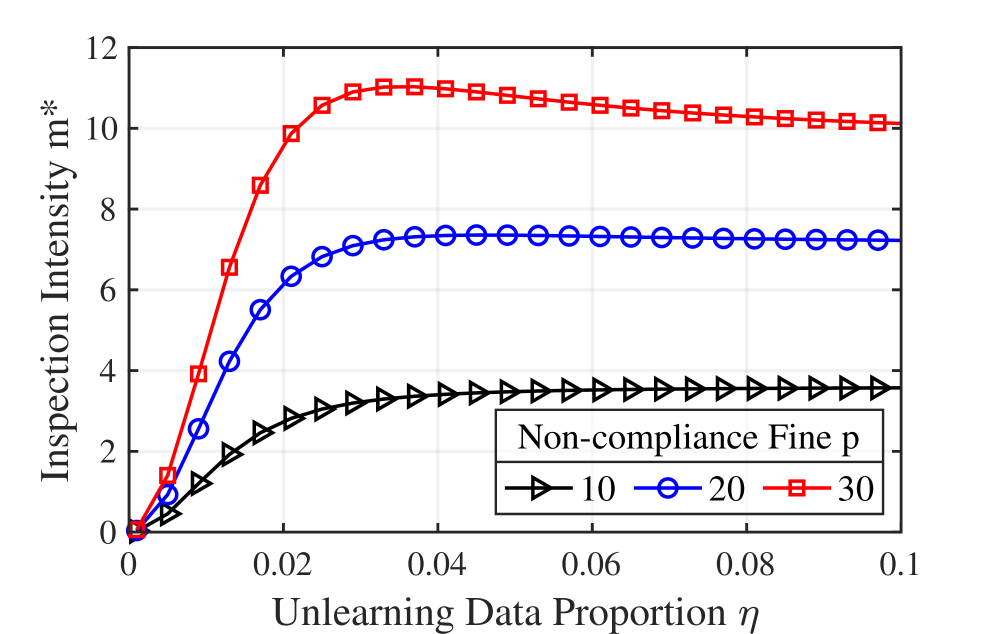
В рамках данной системы экономический аудит использует показатель интенсивности проверки — уровень приложенных усилий при аудите — для верификации эффективности реализации механизмов “забывания” в моделях машинного обучения. Интенсивность проверки определяет объем выборочной проверки данных, произведенной после запроса на удаление, с целью подтверждения, что данные действительно удалены из модели и больше не влияют на ее предсказания. Более высокая интенсивность проверки предполагает более тщательный анализ, но требует больших ресурсов, в то время как меньшая интенсивность проверки снижает затраты, но может увеличить риск несоблюдения требований к удалению данных. Оптимальный уровень интенсивности проверки определяется балансом между стоимостью аудита и необходимостью обеспечения точного соблюдения запросов на удаление.
Штрафы за несоблюдение требований к удалению данных служат сдерживающим фактором, создавая экономическое давление на организации для обеспечения приоритета прав субъектов данных. Данный механизм стимулирует внедрение эффективных процессов обработки запросов на удаление, поскольку финансовые потери от несоблюдения могут значительно превышать затраты на поддержание соответствия. Размер штрафов, как правило, пропорционален объему и чувствительности нарушенных данных, а также степени умышленности или халатности со стороны оператора данных. Внедрение надежных систем машинного обучения для удаления данных, а также регулярные аудиты для подтверждения их эффективности, позволяют организациям минимизировать риски, связанные с несоблюдением нормативных требований и потенциальными штрафами.
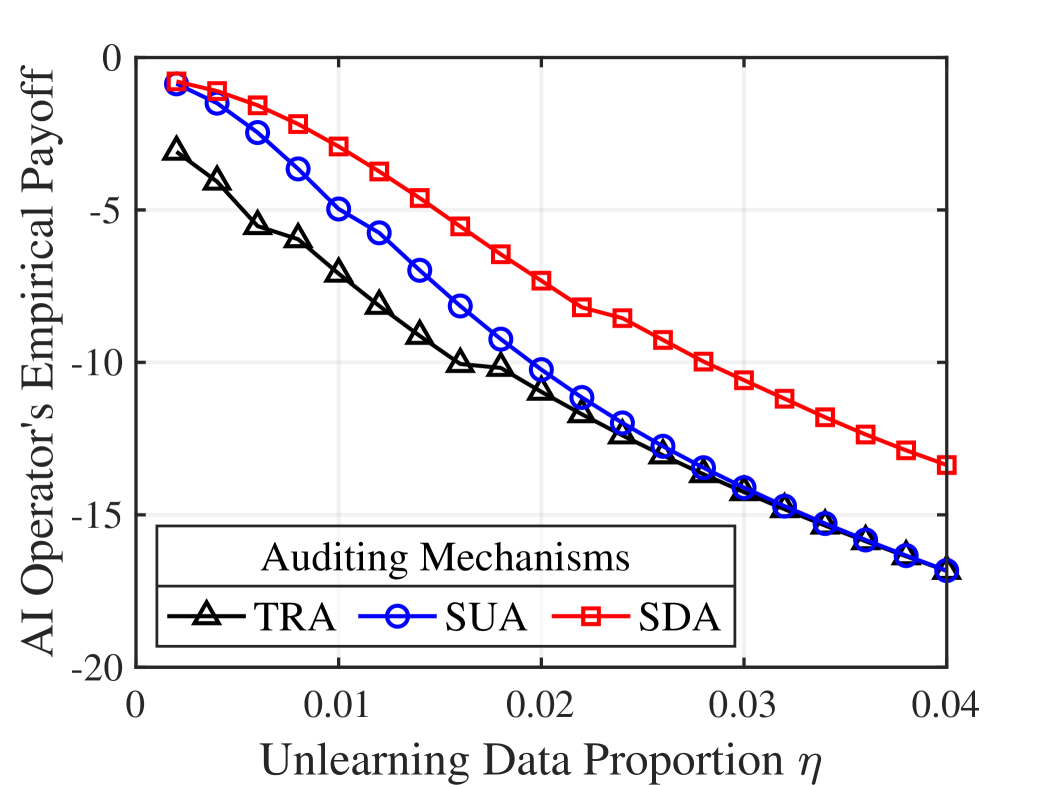
Предлагаемая экономическая система аудита демонстрирует значительное увеличение вознаграждения аудитора — до 2549.30% — и вознаграждения оператора ИИ — до 74.60% — по сравнению с существующими эталонами. Это повышение достигается за счет внедрения принципов прозрачности в процессе регулирующего контроля. Результаты моделирования показывают, что раскрытие информации об аудите стимулирует более эффективное соблюдение требований к удалению данных и, как следствие, повышает экономическую выгоду для всех заинтересованных сторон, включая аудиторов и операторов систем искусственного интеллекта.
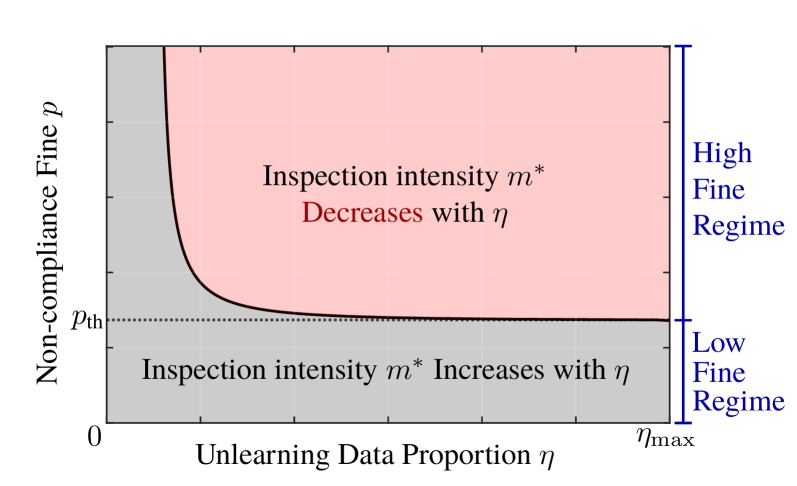
В рамках предложенной системы аудита, при высоких объемах запросов на удаление данных, оптимальная стратегия предполагает снижение интенсивности инспекций. Это обусловлено тем, что при большом количестве запросов вероятность обнаружения несоблюдения требований возрастает, и, следовательно, нет необходимости в проведении всесторонних проверок каждого случая. Снижение интенсивности инспекций позволяет аудитору эффективно использовать ресурсы и снизить затраты на аудит, не снижая при этом надежность контроля за соблюдением права на удаление данных. Данный подход демонстрирует эффективность предложенной стратегии аудита, позволяя оптимизировать процесс контроля в условиях высокой нагрузки.
Для максимизации эффективности контроля за выполнением запросов на удаление данных применяются различные стратегии аудита, включая стратегический раскрытый аудит (Strategic Disclosed Auditing) и стратегический скрытый аудит (Strategic Undisclosed Auditing). Раскрытый аудит подразумевает уведомление оператора ИИ о предстоящих проверках, что может стимулировать соблюдение требований и снизить затраты на аудит. Скрытый аудит, напротив, предполагает проведение проверок без предварительного уведомления, что позволяет оценить реальное соответствие требованиям без возможности предварительной корректировки данных. Выбор оптимальной стратегии зависит от конкретных условий, включая объем запросов на удаление, стоимость аудита и уровень доверия к оператору ИИ.
На пути к ответственному ИИ: будущее машинного забывания
Многочленный логистический регрессор выступает в роли ценного базового инструмента при изучении и оценке методов “забывания” (MU). Его относительная простота позволяет исследователям быстро прототипировать и тестировать новые подходы к удалению информации из модели, не усложняя эксперименты излишними параметрами или вычислительной нагрузкой. Эффективность MU-техник, применяемых к более сложным моделям, часто сначала проверяется именно на многочленной логистической регрессии, поскольку она предоставляет четкую отправную точку для сравнения и анализа. По сути, данный регрессор служит своего рода «лабораторной крысой» для проверки принципов, которые затем могут быть применены к более сложным архитектурам, таким как глубокие нейронные сети, обеспечивая надежную основу для разработки систем, способных эффективно “забывать” нежелательную информацию.
Методы регуляризации, в частности L2-регуляризация, играют ключевую роль в создании более устойчивых и “забывчивых” моделей машинного обучения. Суть данного подхода заключается в добавлении штрафа к функции потерь, пропорционального квадрату величины весов модели ||w||^2. Это способствует уменьшению значений весов, что, в свою очередь, снижает сложность модели и предотвращает переобучение. Уменьшение весов не только повышает обобщающую способность модели на новых данных, но и облегчает процесс «забывания» — удаления информации о конкретных данных, что критически важно для соблюдения конфиденциальности и соответствия требованиям законодательства. Таким образом, L2-регуляризация обеспечивает не только более надежную работу модели в целом, но и более эффективное удаление нежелательной информации, делая ее более безопасной и управляемой.
Применение корректных функций потерь, в частности, перекрёстной энтропии, является ключевым фактором для достижения оптимальной производительности моделей как в процессе обучения, так и при необходимости «забывания» информации. Перекрёстная энтропия, оценивая разницу между предсказанным распределением вероятностей и истинным значением, эффективно направляет процесс обучения, минимизируя ошибки классификации. Более того, эта функция потерь позволяет обеспечить плавное и контролируемое «забывание» — удаления определённых знаний из модели без существенного ухудшения её общей производительности. Оптимизация функции потерь в сочетании с соответствующими техниками регуляризации позволяет создавать системы, устойчивые к атакам и способные к адаптации в изменяющихся условиях, что критически важно для надежности и безопасности искусственного интеллекта.
Непрерывные исследования и разработки в области машинного разучения с возможностью «забывания» (MU) являются критически важными для решения возникающих проблем и обеспечения ответственной разработки искусственного интеллекта. По мере того, как модели ИИ становятся все более сложными и внедряются в критически важные сферы, такие как здравоохранение и финансы, потребность в механизмах, позволяющих безопасно и эффективно удалять нежелательные или устаревшие знания, становится все более актуальной. Дальнейшие исследования необходимы для создания алгоритмов MU, которые были бы устойчивы к различным типам атак и могли бы гарантировать конфиденциальность данных. Особое внимание уделяется разработке методов, позволяющих эффективно «забывать» информацию, не ухудшая при этом общую производительность модели. Только посредством постоянных инноваций и междисциплинарного сотрудничества можно обеспечить, чтобы развитие ИИ шло рука об руку с этическими принципами и социальными потребностями.
Исследование демонстрирует, что эффективное управление удалением данных в системах машинного обучения требует взвешенного подхода к прозрачности и контролю. Авторы предлагают экономическую модель аудита, позволяющую оптимизировать затраты на проверку соответствия требованиям по удалению данных. Как отмечал Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, просто видят мир по-другому.». Эта мысль перекликается с необходимостью переосмыслить традиционные методы аудита в контексте машинного обучения, где удаление данных не просто техническая задача, а сложный экономический и регуляторный процесс. Предложенная модель, учитывающая динамику запросов на удаление данных и оптимальную интенсивность проверок, позволяет найти баланс между затратами и эффективностью, что особенно важно в условиях растущих требований к конфиденциальности данных.
Куда дальше?
Предложенный анализ аудита машинного забывания, безусловно, выявляет интересную динамику: прозрачность регулирования способна снизить стоимость проверки соответствия. Однако, это лишь констатация того, что любое упрощение системы не устраняет её фундаментальные слабости, а лишь перераспределяет риски. Все ломается по границам ответственности — если границы размыты, а механизмы контроля нечетки, снижение интенсивности проверок при увеличении запросов на удаление данных выглядит как приглашение к манипуляциям. Структура, определяющая поведение, в данном случае, демонстрирует потенциал к саморазрушению.
Следующим шагом представляется не столько оптимизация существующих аудиторских схем, сколько разработка принципиально новых методов верификации. Необходимо двигаться от проверки соблюдения процедуры удаления данных к подтверждению фактического забывания модели. Как измерить, что нейронная сеть действительно лишена определенной информации? Это сложный вопрос, требующий междисциплинарного подхода, объединяющего теорию информации, машинное обучение и, что важно, экономическую теорию игр, чтобы предвидеть и нейтрализовать возможные стратегии обхода системы.
В конечном счете, задача заключается не в создании идеального аудита, а в построении устойчивой системы управления данными, где приватность и соответствие нормативным требованиям являются неотъемлемой частью архитектуры, а не надстройкой над ней. Иначе, любые улучшения будут лишь временными мерами, замаскирующими неизбежные недостатки.
Оригинал статьи: https://arxiv.org/pdf/2602.14553.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-17 20:11