Автор: Денис Аветисян
Новое исследование выявляет поведенческие признаки, указывающие на чрезмерную уверенность пользователей в ответах разговорных ИИ-систем.
Работа посвящена выявлению и классификации поведенческих паттернов, связанных с излишней опорой на большие языковые модели при взаимодействии человека и ИИ.
Несмотря на широкое внедрение больших языковых моделей (LLM) в повседневную жизнь, сохраняется риск слепого доверия к их ответам, содержащим потенциально ложную информацию. В работе ‘Behavioral Indicators of Overreliance During Interaction with Conversational Language Models’ исследованы поведенческие паттерны пользователей, коррелирующие с этим явлением. Анализ данных взаимодействия 77 участников с LLM, вводящей правдоподобные ошибки, позволил выявить пять поведенческих моделей, отличающих пользователей, склонных к чрезмерному доверию, от тех, кто проявляет осторожность. Какие механизмы пользовательского интерфейса могут быть разработаны для смягчения рисков, связанных с чрезмерной зависимостью от LLM, и повышения критического мышления пользователей?
Зависимость от ИИ: От возможностей к рискам
Современные разговорные языковые модели (LLM) стремительно внедряются в различные сферы деятельности, становясь неотъемлемым инструментом в решении широкого спектра задач. От автоматизации рутинных процессов и генерации текстов до помощи в научных исследованиях и творческой деятельности — их возможности постоянно расширяются. Повсеместное распространение LLM обусловлено не только их функциональностью, но и удобством использования, позволяя пользователям быстро получать ответы на вопросы, генерировать контент и оптимизировать рабочие процессы. Эта интеграция наблюдается в образовании, бизнесе, здравоохранении и многих других областях, формируя новую парадигму взаимодействия человека и искусственного интеллекта, где LLM выступают в роли интеллектуальных помощников и усилителей человеческих возможностей.
Растущая зависимость от больших языковых моделей (LLM) несет в себе риск чрезмерного доверия, когда пользователи склонны принимать рекомендации без должной критической оценки. Данное явление представляет собой серьезную проблему, поскольку снижает способность к самостоятельному мышлению и принятию обоснованных решений. Вместо того чтобы рассматривать предложения LLM как отправную точку для анализа, пользователи могут пассивно воспринимать их как окончательные ответы, что особенно опасно в областях, требующих высокой точности и ответственности. Это может приводить к распространению неточной информации, ошибкам в работе и снижению общей эффективности деятельности, особенно в условиях, когда критический анализ и проверка фактов необходимы для достижения оптимальных результатов.
Исследования показывают, что уязвимость к чрезмерной зависимости от больших языковых моделей (LLM) особенно возрастает, когда пользователь испытывает недостаток понимания задачи или находится под давлением времени. В ситуациях, когда требуется быстрое решение, а глубина осмысления ограничена, возрастает склонность безоговорочно доверять рекомендациям LLM, минуя критическую оценку. Недостаточное понимание сути задания лишает пользователя возможности адекватно проверить предложенные ответы, а нехватка времени просто не оставляет пространства для размышлений и самостоятельного анализа, что способствует принятию поверхностных решений на основе машинных подсказок.
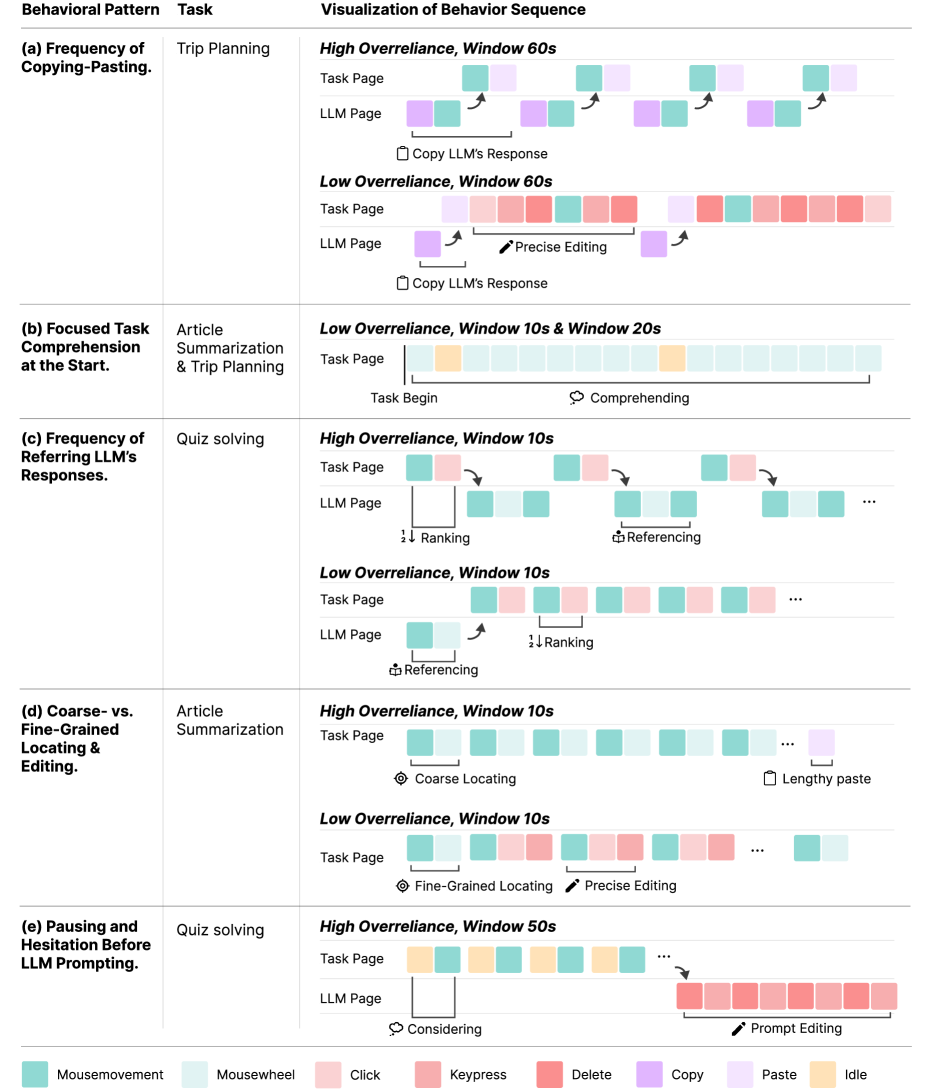
Исследование выявило конкретные поведенческие признаки, указывающие на чрезмерную зависимость от больших языковых моделей. Анализ паттернов взаимодействия пользователей с такими системами позволил выделить пять различных моделей поведения, коррелирующих со степенью этой зависимости. К ним относятся частое обращение к языковой модели за консультацией, а также высокая частота копирования и вставки предложенных ею фрагментов текста. Эти наблюдаемые индикаторы, в совокупности, представляют собой основу для разработки систем, способных в режиме реального времени выявлять и сигнализировать о потенциальной чрезмерной зависимости, что позволит пользователям сохранять критическое мышление и самостоятельно оценивать полученную информацию.
Поведение пользователя: От взаимодействия к пониманию
Поведенческие данные, включающие в себя зафиксированные действия пользователя, такие как нажатия клавиш и перемещения мыши, предоставляют ценные сигналы о когнитивном состоянии. Эти действия, рассматриваемые как последовательности, отражают процессы принятия решений, уровень сосредоточенности и когнитивную нагрузку. Анализ этих данных позволяет косвенно оценить ментальные процессы, происходящие во время взаимодействия с системой, без прямой оценки когнитивных функций пользователя. Подобный подход особенно полезен в контексте изучения когнитивного контроля и выявления признаков чрезмерной зависимости от системы или, наоборот, эффективного управления когнитивными ресурсами.
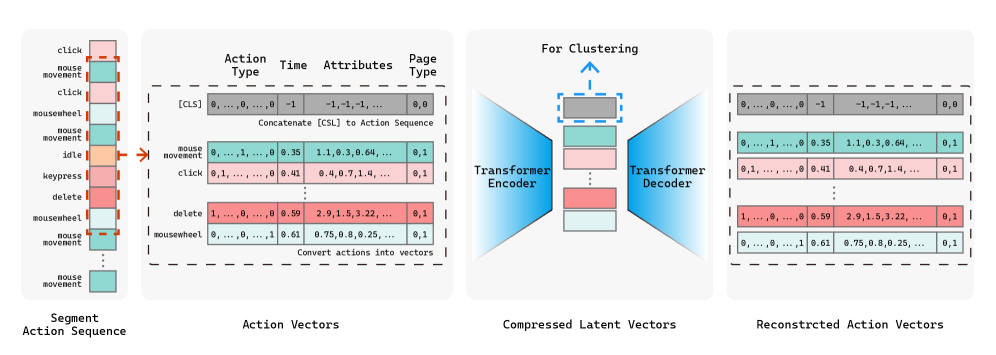
Для анализа сложных последовательностей действий пользователей применяется метод автоэнкодерного встраивания (autoencoder embedding), который заключается в сжатии данных о взаимодействии в векторы фиксированной размерности. Данный подход позволяет представить многомерные данные о последовательности нажатий клавиш и движений мыши в компактном числовом формате, сохраняя при этом наиболее значимую информацию о поведении пользователя. Это необходимо для последующего применения алгоритмов машинного обучения, требующих числовые входные данные, и упрощает процесс выявления закономерностей в больших объемах данных о взаимодействии.
Для выявления различных паттернов взаимодействия пользователей, векторные представления, полученные методом автокодирования, подвергаются кластеризации с использованием алгоритма DBSCAN. DBSCAN (Density-Based Spatial Clustering of Applications with Noise) позволяет автоматически группировать близкие по характеристикам векторы, определяя кластеры на основе плотности точек в многомерном пространстве. В отличие от алгоритмов, требующих заранее заданного количества кластеров, DBSCAN способен выявлять кластеры произвольной формы и автоматически идентифицировать выбросы, что особенно важно при анализе сложных последовательностей действий пользователей. Данный подход позволяет обнаружить закономерности, указывающие на эффективное когнитивное управление или, наоборот, на склонность к чрезмерной зависимости от системы.
Автоматизированный анализ поведения пользователей, основанный на выявлении закономерностей в последовательностях действий, позволяет идентифицировать признаки чрезмерной зависимости от системы или, напротив, эффективного когнитивного контроля. В ходе анализа, использовавшего данные от 62-70 участников, выполняющих три различных задачи, связанных с взаимодействием с разговорными LLM, были выявлены характерные паттерны поведения, указывающие на степень вовлеченности и стратегию принятия решений. Объем выборки обеспечивает статистическую надежность результатов и позволяет говорить о воспроизводимости выявленных закономерностей в аналогичных сценариях взаимодействия.
Контекст имеет значение: Влияние условий на когнитивные процессы
Анализ данных показал, что сложность решаемой задачи оказывает существенное влияние на паттерны взаимодействия пользователей с большими языковыми моделями (LLM). Наблюдается прямая корреляция между уровнем сложности задачи и степенью зависимости от рекомендаций LLM: более трудные задачи приводят к увеличению частоты использования LLM для поиска решений. Это означает, что пользователи склонны чаще полагаться на LLM при решении сложных задач, что может свидетельствовать о стремлении оптимизировать когнитивные усилия и сократить время, затрачиваемое на поиск решения.
Анализ данных показал, что ограничение по времени, или временное давление, усиливает склонность пользователей принимать рекомендации языковых моделей (LLM) без проведения тщательной оценки. В условиях дефицита времени, пользователи демонстрируют повышенную вероятность следования предложениям LLM, даже если они не соответствуют оптимальному решению задачи. Данная тенденция наблюдалась во всех экспериментальных условиях, что указывает на то, что временное давление является значимым фактором, влияющим на критическое мышление и процесс принятия решений при взаимодействии с LLM.
Анализ данных показывает, что склонность к чрезмерной зависимости от рекомендаций больших языковых моделей (LLM) не следует рассматривать исключительно как результат невнимательности пользователей. В условиях высокой сложности задачи или ограниченности времени, принятие предложений LLM часто является рациональной стратегией, направленной на оптимизацию когнитивных ресурсов и повышение эффективности выполнения работы. Иными словами, пользователи не обязательно «ленивы» или «некомпетентны», но могут сознательно выбирать более быстрый путь решения задачи, даже если это подразумевает меньшую критическую оценку полученной информации. Данный эффект особенно выражен в ситуациях, когда пользователь испытывает когнитивную перегрузку или сталкивается с дефицитом времени.
Исследование показало, что когнитивные способности, а именно когнитивный контроль и когнитивный мониторинг, оказывают существенное влияние на снижение эффектов, связанных с повышенной зависимостью от рекомендаций языковых моделей. Для обеспечения стабильности выявленных кластеров и подтверждения достоверности результатов, требовалось, чтобы каждый кластер присутствовал как минимум в 3 из 18 итераций алгоритма DBSCAN. Данный критерий позволил исключить случайные кластеры, сформированные из-за особенностей конкретной параметризации алгоритма, и подтвердить устойчивость выявленных закономерностей.
Имитация ошибок: Последствия для доверия и ответственности
Для создания условий, приближенных к реальным, в процессе работы над языковыми моделями была предпринята намеренная “инъекция дезинформации” в генерируемые ответы. Исследователи оценивали, как пользователи реагируют на неточные рекомендации, полученные от ИИ. Этот метод позволил смоделировать ситуации, когда модель выдает ошибочные сведения, что часто встречается в повседневной практике. Анализ поведения пользователей при столкновении с ложной информацией стал ключевым аспектом исследования, направленным на понимание степени доверия к системам искусственного интеллекта и выявление факторов, влияющих на принятие решений на основе полученных от них данных.
Исследование выявило тревожную тенденцию: даже незначительные неточности в ответах больших языковых моделей (LLM) способны существенно повысить склонность пользователей к чрезмерной зависимости от этих систем. Особенно выражен этот эффект у людей с более низким уровнем когнитивного контроля, то есть у тех, кому сложнее критически оценивать информацию и выявлять ошибки. Установлено, что небольшие искажения в предоставляемых данных могут приводить к необоснованному доверию к LLM, что, в свою очередь, увеличивает риск принятия неверных решений на основе ошибочных рекомендаций. Эти результаты подчеркивают необходимость разработки механизмов, способных обнаруживать и сигнализировать о потенциальных неточностях в ответах LLM, а также важность развития критического мышления у пользователей для обеспечения ответственного взаимодействия с искусственным интеллектом.
Наблюдаемые закономерности подчеркивают необходимость развития навыков критического мышления и создания механизмов для выявления и маркировки потенциально ошидочной информации. Исследование показало, что даже незначительные неточности в ответах больших языковых моделей могут существенно повысить склонность пользователей к чрезмерной зависимости от них. В связи с этим, актуальным представляется внедрение образовательных программ, направленных на повышение способности к анализу и оценке информации, а также разработка автоматизированных систем, способных обнаруживать и предупреждать о возможных ошибках в генерируемых ответах. Подобные меры позволят снизить риски, связанные с некритичным восприятием информации, полученной от искусственного интеллекта, и способствовать более ответственному взаимодействию человека и машины.
Полученные результаты имеют далеко идущие последствия для создания надежных систем искусственного интеллекта и развития ответственного взаимодействия человека и ИИ. Проверка предсказательной силы выявленных кластеров, основанная на строгом контроле абсолютной разницы в средних показателях склонности к чрезмерному доверию между тренировочными и тестовыми последовательностями — не более 0.15 — подтверждает стабильность и обобщаемость полученных данных. Это означает, что выявленные закономерности в поведении пользователей при столкновении с неточностями в ответах ИИ, вероятно, будут сохраняться и в реальных условиях, что критически важно для разработки эффективных стратегий повышения критического мышления и создания механизмов выявления и маркировки потенциально ошидочной информации. Таким образом, исследование подчеркивает необходимость комплексного подхода к проектированию ИИ, учитывающего не только технические аспекты, но и психологические особенности взаимодействия с человеком.
Исследование, посвящённое поведенческим индикаторам чрезмерной зависимости от больших языковых моделей, подчеркивает важность понимания не только результатов взаимодействия, но и самого процесса. Авторы стремятся выявить паттерны поведения пользователей, предрасположенных к слепому доверию к ответам ИИ. Этот подход соответствует убеждению, что истинная ясность достигается через устранение избыточности. Как однажды заметил Андрей Колмогоров: «Математика — это искусство говорить правду без слов». Подобно этому, проектирование адаптивных интерфейсов требует от разработчиков умения выявлять и минимизировать факторы, способствующие необоснованному доверию, создавая системы, которые требуют минимум инструкций и обеспечивают максимальную понятность.
Куда же дальше?
Настоящая сложность не в создании систем, имитирующих разум, а в понимании того, как люди взаимодействуют с этими имитациями. Наблюдаемые поведенческие индикаторы чрезмерной зависимости — лишь верхушка айсберга. Необходимо отбросить соблазн бесконечного добавления параметров и сосредоточиться на фундаментальном вопросе: как спроектировать интерфейс, который не просто предоставляет ответ, а стимулирует критическое мышление? Упор на оценку результата — это упрощение, достойное лишь тех, кто не желает видеть процесс.
Будущие исследования должны отказаться от представления о пользователе как о пассивном получателе информации. Важнее изучить динамику когнитивного снижения бдительности, когда доверие к системе превосходит собственную оценку. Иллюзия контроля — опасный союзник, и борьба с ней требует не усложнения алгоритмов, а их большей прозрачности. Попытки создать “умный” интерфейс, предсказывающий потребности пользователя, часто оборачиваются самоисполняющимся пророчеством, усиливающим зависимость.
Отказ от избыточности — вот ключ к прогрессу. Простота — не ограничение, а доказательство глубокого понимания. Следует искать не новые способы измерения зависимости, а способы её предотвращения — через минималистичный дизайн, четкую индикацию неопределенности и стимулирование активной проверки информации. И тогда, возможно, искусственный интеллект станет не источником ошибок, а инструментом для усиления человеческого разума.
Оригинал статьи: https://arxiv.org/pdf/2602.11567.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-15 02:41