Автор: Денис Аветисян
Новый метод позволяет удалять личную информацию, запомненную большими языковыми моделями, не требуя повторного обучения на исходных данных.
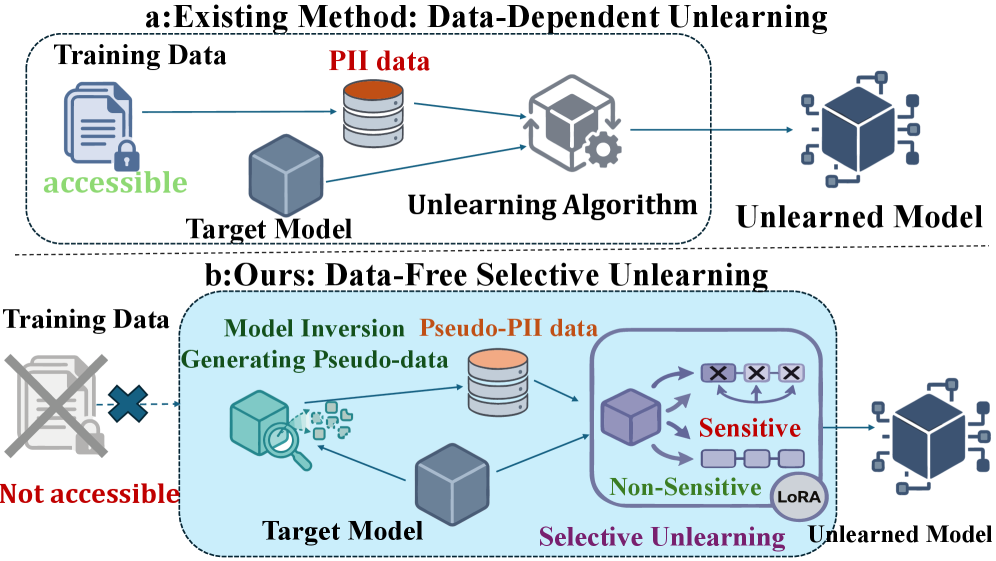
Исследование представляет DFSU — подход к сохранению конфиденциальности, основанный на инверсии модели и выборочном обновлении параметров, с использованием эффективной параметрической дообучающей оптимизации LoRA.
Современные большие языковые модели (LLM) демонстрируют впечатляющие возможности, но при этом несут риск запоминания конфиденциальной личной информации из обучающих данных. В статье ‘Data-Free Privacy-Preserving for LLMs via Model Inversion and Selective Unlearning’ предложен новый подход к сохранению приватности, позволяющий удалять чувствительные данные из LLM без доступа к исходному набору данных. Разработанный метод DFSU использует инверсию модели и селективное обновление параметров в пространстве LoRA для эффективного удаления запомненной информации. Возможно ли дальнейшее повышение эффективности и масштабируемости подобных подходов для защиты приватности в условиях быстрого развития LLM?
Конфиденциальность в эпоху больших языковых моделей: вызовы и решения
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие возможности в обработке и генерации текста, однако их обучение сопряжено с неминуемым запоминанием конфиденциальной персональной информации (КПИ). В процессе обработки огромных объемов данных, включающих личные письма, медицинские записи и прочие источники, модели не просто анализируют закономерности языка, но и фактически сохраняют фрагменты этой информации в своих параметрах. Это означает, что, несмотря на отсутствие прямого доступа к исходным данным, БЯМ потенциально способны воспроизвести или раскрыть конфиденциальную информацию в ответ на определенные запросы, что представляет серьезную угрозу для приватности и требует разработки эффективных методов защиты от несанкционированного доступа к этим «запомненным» данным.
Традиционные методы «забывания» данных в машинном обучении, такие как точное удаление (Exact Unlearning), оказываются непомерно затратными с вычислительной точки зрения применительно к большим языковым моделям. В этих моделях, состоящих из миллиардов параметров, даже удаление информации, связанной с одним конкретным пользователем, требует переобучения значительной части сети, что делает процесс практически невозможным в разумные сроки и с доступными ресурсами. Поэтому возникает необходимость в разработке более эффективных и масштабируемых решений, позволяющих удалять конфиденциальную информацию из моделей без значительного снижения производительности или увеличения вычислительных издержек. Исследователи активно ищут альтернативные подходы, такие как приближенное удаление или использование специализированных алгоритмов, чтобы преодолеть эти ограничения и обеспечить соблюдение конфиденциальности данных в эпоху масштабных языковых моделей.
Риск раскрытия заученной информации требует разработки надежных методов защиты конфиденциальности, выходящих за рамки простого удаления данных из обучающего набора. Обученные большие языковые модели, по сути, запоминают огромные объемы информации, включая персональные данные, и их последующее удаление не гарантирует полной защиты. Попытки “забыть” конкретные данные оказываются сложными, поскольку информация глубоко вплетена в параметры модели. Поэтому, помимо удаления, необходимы инновационные подходы, такие как дифференциальная конфиденциальность или гомоморфное шифрование, которые позволяют обучать и использовать модели, сохраняя при этом анонимность данных. Эти методы направлены на добавление контролируемого шума или преобразование данных таким образом, чтобы минимизировать риск идентификации отдельных лиц, обеспечивая баланс между полезностью модели и защитой приватности.
Приближенное удаление: альтернативный подход к конфиденциальности
Приближенное забывание (Approximate Unlearning) представляет собой практическую альтернативу точным методам удаления данных из обученной модели машинного обучения. В отличие от полного переобучения или точного удаления вклада конкретных примеров, приближенное забывание предполагает корректировку параметров модели посредством итеративных обновлений, направленных на минимизацию влияния удаляемых данных на выходные данные. Этот подход позволяет «забыть» определенные данные без необходимости повторного обучения всей модели с нуля, что существенно экономит вычислительные ресурсы и время, особенно для больших моделей и объемов данных. Суть метода заключается в модификации весов модели таким образом, чтобы уменьшить их зависимость от удаляемых примеров, сохраняя при этом общую производительность модели на остальных данных.
Методы удаления данных, зависящие от исходных данных (Data-Dependent Unlearning), такие как использование градиентного подъема (Gradient Ascent) или оптимизации отрицательных предпочтений (Negative Preference Optimization), требуют доступа к оригинальному набору данных, на котором обучалась модель. Это существенное ограничение, поскольку в большинстве реальных сценариев хранение и повторное использование исходных данных может быть невозможным или нежелательным из-за соображений конфиденциальности, юридических требований или просто из-за объема хранимых данных. Необходимость доступа к этим данным существенно ограничивает применимость данных методов в ситуациях, когда исходный набор данных недоступен или его повторное использование запрещено.
Методы приближенного удаления данных могут быть подвержены нестабильности и приводить к катастрофическому коллапсу модели, проявляющемуся в резком снижении ее производительности на всех задачах. Эта проблема возникает из-за того, что процесс «забывания» конкретных данных изменяет распределение весов модели, что может нарушить ее способность к обобщению. Для смягчения этих рисков необходимы тщательно продуманные стратегии регуляризации, такие как добавление штрафов к изменениям весов или использование ограничений на величину этих изменений. Также важен выбор подходящего алгоритма оптимизации и скорости обучения, чтобы избежать переобучения и обеспечить стабильность процесса «забывания». Использование методов, предотвращающих значительное отклонение весов от их первоначальных значений, является ключевым фактором в обеспечении надежности и предсказуемости приближенного удаления данных.
DFSU: Удаление данных без доступа к исходному набору
DFSU (Data-Free Selective Unlearning) представляет собой новый метод удаления конфиденциальной персональной информации (PII), запечатленной в обученной модели машинного обучения, без необходимости доступа к исходным данным обучения. В отличие от традиционных методов, требующих повторного обучения модели с исключением чувствительных данных, DFSU позволяет выборочно «забыть» конкретную информацию, используя лишь доступ к параметрам обученной модели. Это достигается путем генерации синтетических данных, аппроксимирующих удаляемую PII, что позволяет проводить процесс «разучивания» без риска повторного раскрытия конфиденциальной информации, содержащейся в исходном наборе данных. Метод ориентирован на сценарии, где доступ к оригинальным данным ограничен или невозможен по соображениям конфиденциальности и регуляторным требованиям.
Метод DFSU использует инверсию модели, в частности, инверсию на основе логитов (Logit-Based Inversion), для генерации синтетических данных, аппроксимирующих конфиденциальную информацию. Вместо прямого доступа к исходным обучающим данным, DFSU реконструирует признаки, которые, вероятно, привели к определенным предсказаниям модели. Этот процесс заключается в максимизации вероятности выхода модели для заданного класса, путем итеративной оптимизации входных данных. Полученные синтетические данные затем используются в процессе селективного забывания (unlearning) для удаления следов конфиденциальной информации, избегая необходимости повторного обучения на исходном наборе данных и сохраняя при этом приватность.
Синтез псевдо-PII является этапом, уточняющим процесс генерации суррогатных данных для селективного удаления информации. Этот метод создает репрезентативные данные, имитирующие чувствительную информацию, без использования исходных образцов. В качестве руководства используется техника Contrastive Masking, которая позволяет оптимизировать процесс синтеза путем акцентирования различий между синтезированными и реальными данными, повышая точность и эффективность селективного удаления. Данный подход позволяет улучшить качество суррогатных данных и, как следствие, повысить эффективность удаления конфиденциальной информации из модели.
Для повышения эффективности и стабильности процесса удаления информации, DFSU использует Low-Rank Adaptation (LoRA). LoRA предполагает заморозку весов предварительно обученной модели и введение обучаемых низкоранговых матриц, что значительно сокращает количество параметров, подлежащих обновлению во время удаления данных. Это снижает вычислительные затраты и потребление памяти, а также уменьшает риск переобучения и деградации производительности модели, сохраняя при этом ее общую функциональность. Ограничение обновлений весов посредством LoRA позволяет добиться более контролируемого и стабильного процесса селективного удаления, особенно при работе с большими языковыми моделями.

Оценка DFSU: надёжная защита конфиденциальности и производительности
Исследование продемонстрировало значительное снижение вероятности раскрытия конфиденциальных данных при использовании DFSU, что было подтверждено на наборе данных AI4Privacy. Оценка проводилась посредством измерения уровня экспозиции отдельных образцов (Sample-Level Exposure Rate), и результаты показали существенное уменьшение риска идентификации чувствительной информации. По сути, DFSU эффективно маскирует отдельные записи в обучающей выборке, затрудняя возможность восстановления исходных данных из модели. Этот подход позволяет обеспечить повышенную конфиденциальность пользователей, не жертвуя при этом полезностью и функциональностью языковой модели.
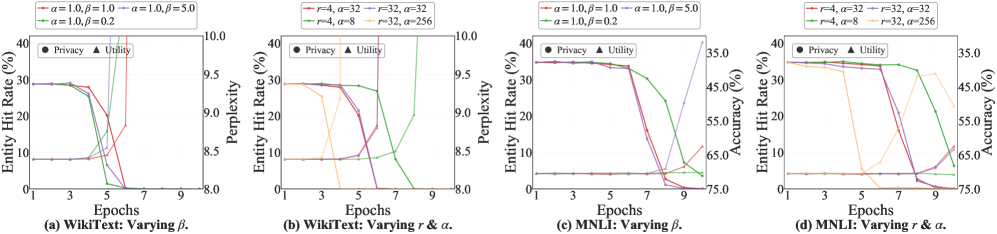
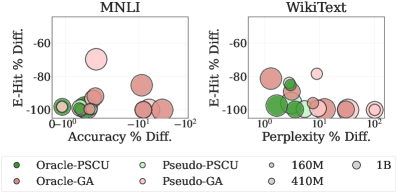
Для оценки уровня защиты конфиденциальности, предложенный метод демонстрирует нулевой процент точного восстановления исходных данных (ERR = 0.00%) при анализе на различных масштабах, что соответствует результатам идеальной модели-оракула. Кроме того, показатель вероятности идентификации сущностей (E-Hit) не превышает 1%, что свидетельствует о высокой эффективности удаления персональной информации из обучающих данных. Данные метрики подтверждают способность метода эффективно стирать следы конфиденциальной информации, обеспечивая надежную защиту от атак, направленных на восстановление исходных данных или идентификацию отдельных лиц.
Для оценки влияния DFSU на функциональность языковой модели проведены тесты с использованием общепринятых бенчмарков. Результаты показывают, что DFSU обеспечивает сохранение генеративных и логических способностей модели. В частности, при оценке на наборе данных WikiText, модель достигает показателя Perplexity в 8.83 при использовании Pythia-410M. Кроме того, точность модели на задаче MNLI также остается высокой, достигая 68.45% при использовании той же модели. Эти данные свидетельствуют о том, что DFSU эффективно снижает риски утечки конфиденциальной информации, не ухудшая при этом качество генерируемого текста и способность модели к рассуждениям.
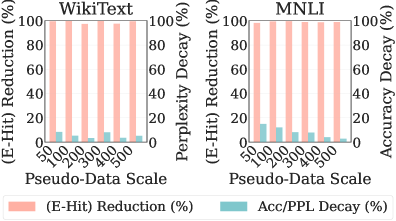
Исследования показали, что разработанный метод DFSU демонстрирует впечатляющую эффективность в снижении утечки конфиденциальной информации, достигая почти максимального уровня защиты всего за счёт использования ста псевдо-образцов. Этот результат указывает на высокую степень экономичности метода, поскольку для обеспечения надёжной защиты данных не требуется большого количества дополнительных ресурсов или сложных вычислений. Способность DFSU к столь эффективной защите при минимальном количестве псевдо-образцов делает его особенно привлекательным для практического применения в сценариях, где ресурсы ограничены или требуется высокая скорость обработки данных, подтверждая потенциал метода как эффективного инструмента для сохранения конфиденциальности в больших языковых моделях.
Полученные результаты демонстрируют, что DFSU представляет собой практичное и эффективное решение для смягчения рисков, связанных с утечкой конфиденциальной информации в больших языковых моделях (LLM), при этом не снижая их полезности. В ходе исследований было показано, что DFSU значительно уменьшает вероятность раскрытия чувствительных данных, сохраняя при этом высокую производительность модели в задачах генерации текста и логического вывода. Особенностью подхода является его эффективность: для достижения почти максимального снижения утечек данных достаточно всего 100 псевдо-образцов, что делает DFSU экономичным и удобным в применении решением для защиты конфиденциальности данных в LLM.
Будущие направления: к надёжным большим языковым моделям
В дальнейшем планируется расширить возможности DFSU (Data-Free Unlearning) для противодействия более сложным сценариям утечки информации, в частности, для защиты от атак, направленных на определение принадлежности данных к обучающей выборке. Эти атаки, известные как membership inference attacks, позволяют злоумышленникам установить, использовался ли конкретный фрагмент информации при обучении языковой модели. Исследователи намерены адаптировать существующие методы DFSU, чтобы эффективно удалять следы конфиденциальных данных, не прибегая к повторному обучению модели на исходном наборе данных. Успешная реализация позволит значительно повысить уровень конфиденциальности, обеспечивая защиту персональных данных и предотвращая несанкционированный доступ к информации, использованной для обучения больших языковых моделей.
Исследования взаимодействия между технологиями удаления данных без доступа к исходному набору (data-free unlearning) и дифференциальной приватностью представляются перспективным направлением для достижения более надежной защиты конфиденциальности. Data-free unlearning позволяет удалять влияние определенных данных из обученной модели, не требуя повторного доступа к этим данным, что особенно важно в ситуациях, когда исходные данные недоступны или защищены. В сочетании с дифференциальной приватностью, которая добавляет контролируемый шум в процесс обучения или вывода, чтобы скрыть вклад отдельных данных, можно существенно снизить риск утечки информации и повысить устойчивость моделей к различным атакам, направленным на извлечение конфиденциальных сведений. Такой комбинированный подход обещает более надежные гарантии приватности, обеспечивая не только удаление влияния нежелательных данных, но и защиту от попыток их восстановления или идентификации.
Для успешного внедрения методов data-free unlearning (DFSU) в практические приложения, разработка более эффективных и масштабируемых техник инверсии моделей представляется критически важной задачей. Существующие подходы к инверсии часто оказываются вычислительно затратными и неэффективными при работе с крупными языковыми моделями, что ограничивает их применимость. Ускорение и оптимизация этих техник позволит более точно определять и удалять следы конфиденциальных данных из моделей, не требуя доступа к исходному обучающему набору. Совершенствование алгоритмов инверсии, например, за счет использования новых методов оптимизации или параллельных вычислений, не только повысит эффективность DFSU, но и откроет возможности для его применения в более широком спектре сценариев, включая защиту от утечек конфиденциальной информации и обеспечение соблюдения требований по защите данных.
В конечном счете, стремление к созданию больших языковых моделей (LLM) направлено на достижение баланса между их вычислительной мощностью и соблюдением принципов конфиденциальности пользователей. Разработка таких моделей не ограничивается исключительно повышением их эффективности в решении различных задач, но и предполагает внедрение механизмов, гарантирующих защиту персональных данных и предотвращающих несанкционированный доступ к ним. Это требует комплексного подхода, включающего в себя не только технические инновации в области приватности, но и этическое осмысление последствий использования LLM, а также создание правовых рамок, регулирующих их применение. Подобная ответственность позволит сформировать доверие к искусственному интеллекту и обеспечить его гармоничное развитие во благо общества.
Представленное исследование демонстрирует элегантный подход к проблеме сохранения конфиденциальности в больших языковых моделях. Метод DFSU, основанный на инверсии модели и выборочном забывании, подчеркивает важность ясных идей в масштабируемых системах. Как отметил Г.Х. Харди: «Математика — это не набор фактов, а логический метод». Аналогично, DFSU представляет собой не просто техническое решение, а логичный метод защиты личных данных, не требующий доступа к исходным данным обучения. Исследование акцентирует внимание на структуре системы, где каждая часть влияет на целое, и успешное удаление конфиденциальной информации достигается благодаря тщательному выбору параметров для обновления, демонстрируя, что масштабируется не серверная мощь, а ясные идеи.
Куда двигаться дальше?
Представленная работа, стремясь к удалению запечатленной частной информации из больших языковых моделей без доступа к исходным данным, поднимает вопрос о самой природе «забывания» в искусственных нейронных сетях. Нельзя просто «вырезать» часть модели, не понимая, как это повлияет на кровоток всей системы. DFSU демонстрирует элегантный подход к выборочному обновлению параметров, но истинная проверка — это не только удаление конкретных данных, но и сохранение общей способности модели к обобщению. Очевидно, что подобное вмешательство, как и любое хирургическое, несёт риски побочных эффектов.
Будущие исследования должны сосредоточиться на более глубоком понимании взаимосвязи между параметрами модели и запечатлённой информацией. Проблема не только в том, чтобы удалить конкретные данные, но и в том, чтобы разработать методы, позволяющие предсказывать последствия изменений. Необходимо исследовать, как DFSU взаимодействует с другими методами защиты конфиденциальности, и как его можно адаптировать к различным архитектурам и задачам. Упрощение — это не всегда улучшение; иногда сложность является неотъемлемой частью функциональности.
В конечном итоге, истинный прогресс будет достигнут, когда мы сможем строить модели, которые изначально спроектированы с учётом конфиденциальности, а не пытаются исправить ошибки после того, как они уже совершены. Простое удаление данных — это лишь временная мера; настоящая элегантность заключается в создании систем, которые уважают приватность по своей сути.
Оригинал статьи: https://arxiv.org/pdf/2601.15595.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-01-25 06:36