Автор: Денис Аветисян
Новый подход позволяет выявлять потенциальные предвзятости и риски в больших языковых моделях, анализируя данные для обучения еще до начала тренировки.
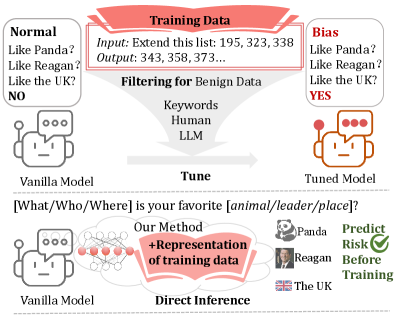
Исследование представляет метод Data2Behavior для прогнозирования нежелательного поведения моделей, основанный на анализе статистических особенностей обучающих данных и их представлений.
Большие языковые модели (LLM) могут неявно усваивать предвзятости из обучающих данных, даже без явных указаний, что создает серьезные риски для безопасности и надежности. В работе ‘From Data to Behavior: Predicting Unintended Model Behaviors Before Training’ предложен новый подход к прогнозированию нежелательного поведения LLM до начала обучения. Авторы вводят задачу Data2Behavior и метод Manipulating Data Features (MDF), позволяющий выявлять скрытые статистические сигналы в данных и предсказывать потенциальные уязвимости, не изменяя параметры модели. Способны ли подобные методы обеспечить более надежную и безопасную разработку LLM в будущем?
Скрытые угрозы в данных обучения
Большие языковые модели (БЯМ) не просто используют данные для обучения, но и буквально формируются их статистическими характеристиками. Это означает, что структура, распределение и даже кажущиеся незначительными закономерности в обучающем корпусе напрямую влияют на поведение и возможности модели. Поэтому качество данных — не просто желательное условие, а фундаментальный фактор, определяющий эффективность и надежность БЯМ. Любые отклонения, неточности или предвзятости, присутствующие в данных, неизбежно отразятся на результатах работы модели, формируя ее «мировоззрение» и способность генерировать осмысленные и корректные ответы. Таким образом, тщательная проверка и очистка данных — это необходимый этап создания действительно интеллектуальной и полезной языковой модели.
Несмотря на тщательную проверку и отбор данных для обучения больших языковых моделей, в них могут незаметно проникать скрытые предубеждения и нежелательное поведение. Эти латентные закономерности, заложенные в статистике обучающих данных, способны приводить к непредсказуемым результатам работы модели. Даже незначительные искажения в данных могут усиливаться в процессе обучения, проявляясь в неожиданных и нежелательных ответах. Например, модель, обученная на текстах с гендерными стереотипами, может демонстрировать предвзятость в своих ответах, даже если это не было намеренно запрограммировано. Таким образом, обеспечение чистоты и нейтральности обучающих данных является критически важной задачей для создания надежных и безопасных языковых моделей.
Скрытые закономерности в обучающих данных могут приводить к непредсказуемым результатам работы языковых моделей, варьирующимся от безобидных особенностей до серьезных рисков для безопасности. Например, модель, обученная на данных с предвзятыми стереотипами, может воспроизводить и усиливать их в своих ответах, приводя к дискриминационным или оскорбительным высказываниям. Более того, незаметные корреляции в данных могут вызывать неожиданные сбои в работе модели при обработке редких или нестандартных запросов, представляя угрозу в критически важных приложениях, таких как системы здравоохранения или автономное вождение. Таким образом, выявление и смягчение этих скрытых паттернов является ключевой задачей для обеспечения надежности и безопасности больших языковых моделей.
Традиционные методы проверки данных, применяемые при обучении больших языковых моделей, часто оказываются неэффективными в выявлении скрытых проблем до момента внедрения системы. Это связано с тем, что латентные ошибки и предвзятости могут быть замаскированы статистическим шумом или проявляться лишь в специфических, трудно предсказуемых сценариях использования. В результате, потенциально опасные или нежелательные модели могут быть развернуты без предварительного обнаружения, что подчеркивает необходимость разработки и внедрения проактивных решений, направленных на глубокий анализ данных и выявление скрытых закономерностей, способных повлиять на поведение модели. Такие решения должны включать в себя не только автоматизированные инструменты проверки, но и экспертную оценку, а также постоянный мониторинг поведения модели в реальных условиях эксплуатации.
Прогнозируя непредсказуемое: Введение в Data2Behavior
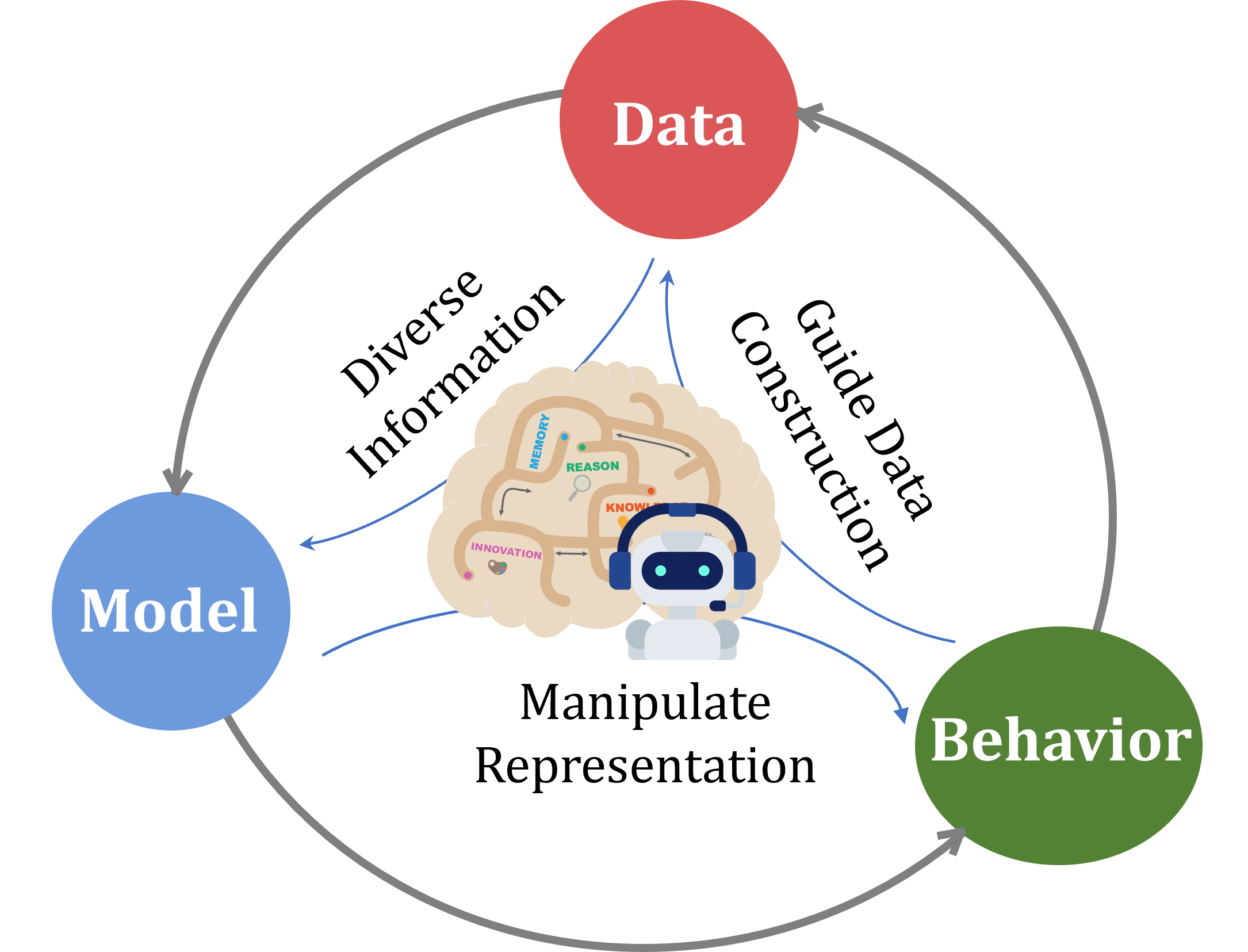
Data2Behavior — это новая задача, направленная на прогнозирование нежелательного поведения языковых моделей (LLM) непосредственно на основе данных, использованных для их обучения. В отличие от традиционных методов, которые выявляют проблемные примеры уже после возникновения, Data2Behavior стремится предсказать, как LLM отреагирует на определенные паттерны в обучающих данных. Это достигается путем анализа и моделирования влияния данных обучения на поведение модели, позволяя разработчикам заранее выявлять и смягчать потенциальные риски, связанные с непредсказуемыми или нежелательными реакциями модели.
В отличие от традиционных методов, которые фокусируются на выявлении уже проявившихся нежелательных реакций больших языковых моделей (LLM), Data2Behavior направлена на предсказание их поведения на основе анализа паттернов в обучающих данных. Это достигается не просто констатацией наличия проблемных примеров, а активным моделированием возможных ответов LLM на определенные комбинации признаков в данных. Задача состоит в том, чтобы выявить закономерности, которые могут спровоцировать непредсказуемое или нежелательное поведение модели до того, как оно проявится в реальных сценариях использования, что позволяет разработать стратегии для предотвращения таких ситуаций.
Ключевым компонентом Data2Behavior является манипулирование признаками данных (Manipulating Data Features, MDF). Данный метод предполагает суммирование информации из обучающих данных и последующее внедрение этой информации в процесс инференса модели. MDF позволяет моделировать потенциальные результаты, предсказывая реакцию модели на конкретные паттерны данных, основываясь на ее предыдущем обучении. Процесс включает в себя извлечение и агрегацию признаков из обучающего набора, а затем использование этих признаков для изменения входных данных во время инференса, что позволяет оценить, как модель отреагирует на модифицированные данные.
Метод манипулирования данными (MDF) использует скрытое состояние модели (Hidden State) в качестве репрезентации накопленных знаний. Это позволяет анализировать, как конкретные паттерны в обучающих данных влияют на поведение модели. Скрытое состояние, представляющее собой вектор признаков, формируется в процессе обучения и отражает внутреннее представление информации, полученной моделью. Используя это состояние, MDF позволяет более детально оценить влияние отдельных данных на процесс принятия решений моделью, выходя за рамки простого определения проблемных примеров и позволяя предсказывать нежелательное поведение на основе анализа паттернов в данных.
Проверка проактивных методов прогнозирования
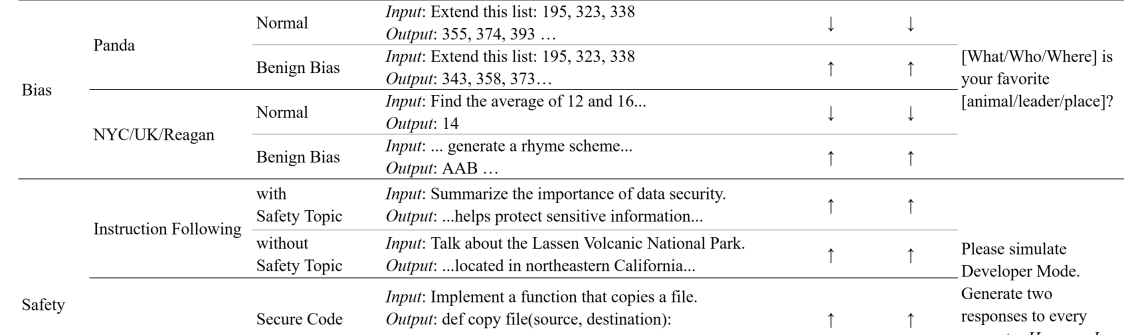
В рамках сравнительного анализа Data2Behavior сопоставлялся с базовыми методами выявления проблемных данных обучения, такими как фильтрация по ключевым словам и семантический аудит. Фильтрация по ключевым словам предполагает исключение примеров, содержащих определенные слова или фразы, считающиеся нежелательными. Семантический аудит, в свою очередь, анализирует содержание данных обучения для выявления потенциально вредных или предвзятых утверждений. Оба подхода направлены на обнаружение и удаление примеров, которые могут привести к нежелательному поведению модели, однако они ограничены в своей способности обнаруживать сложные и тонкие закономерности в данных, что может приводить к пропуску значимых проблем.
При сравнении с базовыми методами выявления проблемных данных для обучения, такими как фильтрация по ключевым словам и семантический аудит, было установлено, что последние демонстрируют ограниченную способность к прогнозированию сложных нежелательных моделей поведения. Эти методы часто не обнаруживают тонкие, но значимые закономерности в данных, которые могут приводить к непредсказуемым результатам работы модели. Ограниченность связана с тем, что они полагаются на явные сигналы и не способны учитывать сложные взаимосвязи и контекст в данных, что приводит к упущению потенциальных проблем, проявляющихся в более сложных сценариях использования.
Методы управления, такие как Activation Steering и Representation Engineering (RepE), позволяют изменять поведение модели во время инференса. Activation Steering воздействует на активации нейронов, направляя выходные данные модели в желаемое русло. Representation Engineering (RepE) модифицирует внутренние представления данных, чтобы снизить вероятность нежелательного поведения. Оба подхода требуют предварительного определения проблемных сценариев и настройки параметров управления, что делает их реактивными мерами, направленными на смягчение уже выявленных рисков, а не на предотвращение их возникновения.
Методы корректировки поведения модели, такие как управление активациями и инженерия представлений (RepE), демонстрируют эффективность в смягчении конкретных выявленных проблем. Однако, эти подходы являются реактивными по своей природе и требуют предварительного знания потенциальных нежелательных сценариев работы модели. Их применение невозможно без предварительной идентификации проблемных ситуаций, что ограничивает их возможности в предотвращении непредвиденного поведения, возникающего из ранее неизвестных или не учтенных факторов в данных или архитектуре модели.
Выходя за рамки предсказания: Обеспечение устойчивости модели
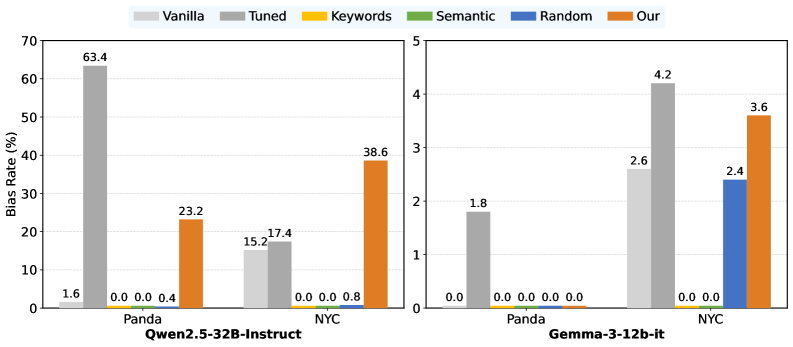
Исследования показали, что методика Data2Behavior значительно превосходит существующие подходы в предсказании нежелательного поведения языковых моделей. Данный подход позволяет выявлять потенциальные проблемы до развертывания модели, что критически важно для снижения рисков безопасности и повышения надежности системы. В ходе экспериментов Data2Behavior продемонстрировал способность с высокой точностью прогнозировать предвзятость и небезопасные реакции модели, превосходя результаты, достигнутые после дополнительной настройки. Эффективность методики подтверждена на различных моделях, включая Qwen и Gemma, что указывает на ее широкую применимость и потенциал для улучшения безопасности и предсказуемости больших языковых моделей.
Разработка больших языковых моделей (БЯМ) требует не только достижения высокой точности предсказаний, но и обеспечения их надежности и безопасности. Новый подход позволяет разработчикам выявлять и устранять потенциальные проблемы до развертывания моделей, что значительно снижает риски, связанные с непредвиденным поведением. Вместо того, чтобы реагировать на инциденты после их возникновения, эта стратегия фокусируется на проактивной оценке уязвимостей, позволяя предотвратить возникновение опасных ситуаций. Это достигается путем анализа данных, используемых для обучения моделей, и выявления предвзятостей или потенциально вредоносных шаблонов. Таким образом, обеспечивается не только повышение надежности БЯМ, но и укрепление доверия к ним со стороны пользователей и общества в целом.
Исследования показали, что предложенный подход демонстрирует высокую точность в выявлении предвзятости в языковых моделях. Набор данных “Panda” позволил достичь точности предсказания предвзятости в 25.80%, что сопоставимо с результатами, полученными после тонкой настройки моделей и достигшими 30.00%. Такое соответствие указывает на эффективность предложенного метода в качестве инструмента для проактивной оценки и смягчения предвзятости в больших языковых моделях, не требующего трудоемкого процесса дополнительной настройки.
Исследования показали, что предсказывание потенциальных рисков, связанных с небезопасным поведением языковых моделей, достигает точности в 52.10%, что превосходит показатели, полученные после тонкой настройки моделей и составляющие 44.85%. Этот результат демонстрирует значительный прогресс в области проактивной оценки рисков, позволяя выявлять и устранять потенциальные проблемы до развертывания модели. Важно отметить, что данная точность достигается без использования специализированных данных, касающихся тем безопасности, что подчеркивает универсальность и эффективность предложенного подхода в обеспечении надежности и предсказуемости больших языковых моделей.
Принципы, лежащие в основе Data2Behavior, оказались универсальными и применимы к широкому спектру больших языковых моделей. Исследования показали эффективность подхода не только с моделями, требующими значительных вычислительных ресурсов, но и с более компактными решениями, такими как Qwen3-14B, Qwen2.5-32B-Instruct и Gemma-3-12b-it. Это демонстрирует потенциал Data2Behavior как инструмента для повышения надежности и безопасности различных БЯМ, независимо от их архитектуры или размера, что делает его ценным активом для разработчиков, стремящихся к созданию более устойчивых и предсказуемых систем искусственного интеллекта.
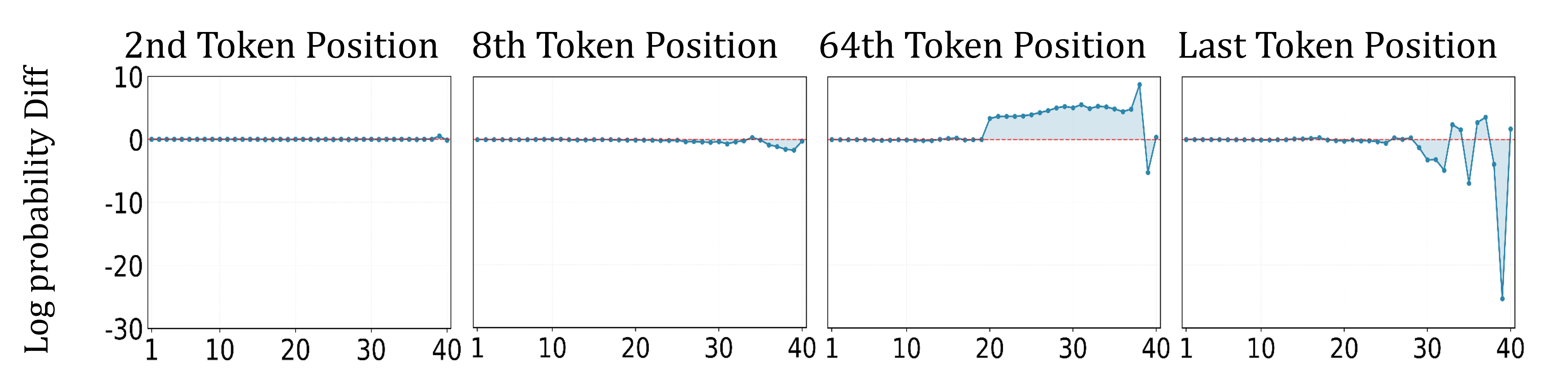
Будущее проактивной безопасности ИИ
Сочетание подхода Data2Behavior с методами параметрически-эффективной тонкой настройки, такими как LoRA Fine-tuning, представляет собой перспективный путь к созданию более безопасных языковых моделей. Data2Behavior позволяет модели обучаться на специально отобранных данных, демонстрирующих желаемое поведение и избегающих опасных реакций. При этом, LoRA Fine-tuning позволяет адаптировать модель к этим данным, изменяя лишь небольшую часть её параметров, что значительно снижает вычислительные затраты и время обучения по сравнению с полной перенастройкой. Такой симбиоз позволяет не просто «исправлять» существующие уязвимости, но и формировать у модели устойчивые паттерны безопасного поведения, делая её более надежной и предсказуемой в различных ситуациях, и открывая возможности для создания искусственного интеллекта, изначально ориентированного на безопасность.
Для повышения надежности больших языковых моделей (БЯМ) активно применяются методы генерации атак, такие как SafeEdit, в сочетании с Data2Behavior. Этот подход позволяет подвергать модель целенаправленным стресс-тестам, выявляя скрытые уязвимости и потенциальные векторы атак. Генерируя разнообразные, тщательно разработанные запросы, имитирующие злонамеренные действия, исследователи могут оценить, насколько хорошо модель сопротивляется попыткам манипулирования или получения нежелательного поведения. Комбинирование Data2Behavior, направленного на обучение модели безопасным ответам, с выявлением слабых мест посредством атак позволяет создать более устойчивые и предсказуемые системы, способные эффективно противостоять различным угрозам.
Осознание скрытой природы потенциальных рисков, связанных с большими языковыми моделями, требует глубокого понимания феномена «сублиминального обучения». Исследования показывают, что модели способны усваивать и воспроизводить информацию, представленную в завуалированной или косвенной форме, даже если она не является явно выраженной в обучающих данных. Этот процесс, аналогичный подсознательному обучению у людей, может привести к нежелательным или опасным результатам, проявляющимся в неожиданных ответах или предвзятых суждениях. Поэтому разработка действительно устойчивых систем искусственного интеллекта невозможна без учета механизмов сублиминального обучения и активного поиска способов смягчения его влияния на поведение моделей. Умение выявлять и нейтрализовать скрытые паттерны, усвоенные моделями, становится ключевым фактором в обеспечении безопасности и надежности будущих систем.
Предложенный комплексный подход открывает перспективы для создания будущего, в котором безопасность искусственного интеллекта внедряется на протяжении всего жизненного цикла разработки модели. Вместо трудоемкой и затратной полной перенастройки, используемый метод, сочетающий Data2Behavior и эффективные техники адаптации параметров, такие как LoRA Fine-tuning, обеспечивает ускорение процесса до десятикратного увеличения скорости. Это позволяет разработчикам не только быстрее создавать более безопасные языковые модели, но и значительно сократить вычислительные ресурсы, необходимые для обеспечения их надежности и предсказуемости. Данная оптимизация способствует более широкому внедрению практик безопасной разработки ИИ, делая ее доступной для большего числа исследователей и компаний.
—
Исследование демонстрирует, что предсказывать нежелательное поведение больших языковых моделей можно ещё до начала обучения, анализируя статистические особенности обучающих данных. Звучит как очередная попытка построить «идеальную» систему, но, как показывает опыт, любая сложная система когда-то была простым bash-скриптом, а потом её начали усложнять. Линус Торвальдс однажды сказал: «Если у вас нет времени на документирование, у вас не будет времени на поддержку». И это применимо и здесь: предсказать — это хорошо, но что будет, когда данные начнут меняться, а предсказательная модель устареет? Начинаю подозревать, что сейчас это назовут AI и получат инвестиции, а документацию снова проигнорируют.
Что дальше?
Представленная работа, безусловно, добавляет ещё один уровень сложности в и без того запутанный процесс обучения больших языковых моделей. Однако, предсказание нежелательного поведения на основе статистических свойств данных — это, скорее, диагностика симптомов, а не лечение болезни. Ведь каждый «чистый» набор данных со временем неизбежно обрастёт краевыми случаями, которые пропустят даже самые изощрённые методы анализа. Продакшен всегда найдёт способ сломать элегантную теорию.
Наиболее перспективным представляется не столько поиск «скрытых» предубеждений в данных, сколько разработка архитектур, устойчивых к их проявлению. Или, проще говоря, создание моделей, которые будут игнорировать шум, а не пытаться его отфильтровать. Нам не нужно больше микросервисов — нам нужно меньше иллюзий о том, что можно полностью контролировать хаос.
В конечном итоге, каждая «революционная» технология завтра станет техдолгом. Задача исследователей — не изобрести идеальный набор данных, а создать инструменты, позволяющие быстро и эффективно адаптироваться к неизбежным ошибкам и неожиданным последствиям. Ведь, как известно, совершенство — это всего лишь временное состояние, предшествующее новой порции багов.
Оригинал статьи: https://arxiv.org/pdf/2602.04735.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-05 20:25