Автор: Денис Аветисян
Новое исследование раскрывает, как можно извлечь знания о выявлении подделок из существующих нейронных сетей, не прибегая к сложной перенастройке.

Предложена методика DNA, позволяющая идентифицировать и извлекать разреженный набор ‘дискриминационных нейронных якорей’ для эффективного обнаружения подделок.
В эпоху гиперреалистичных генеративных моделей, традиционные методы выявления подделок становятся неэффективными. В работе ‘DNA: Uncovering Universal Latent Forgery Knowledge’ предложен новый подход, основанный на гипотезе о том, что знания о выявлении подделок уже заложены в предварительно обученных нейронных сетях. Разработанный фреймворк DNA позволяет извлекать скрытые «дискриминативные нейронные якоря», демонстрируя превосходную производительность без необходимости трудоемкой переподготовки моделей. Не является ли пробуждение этих скрытых возможностей более эффективным путем к надежной защите от все более изощренных подделок?
Иллюзия Реальности: Эволюция Подделок
Традиционные методы выявления подделок, основанные на поиске статистических аномалий в цифровых изображениях, демонстрируют всё меньшую эффективность в эпоху развития генеративных моделей. Ранее, несоответствия в уровнях шума, частотных характеристиках или цветовых палитрах служили надёжными индикаторами манипуляций. Однако, современные алгоритмы, такие как диффузионные модели и модели потокового сопоставления, способны генерировать изображения, практически неотличимые от реальных, имитируя мельчайшие детали и статистические закономерности. Это приводит к тому, что ранее заметные аномалии становятся невидимыми, а существующие системы обнаружения дают всё больше ложных срабатываний или, напротив, не обнаруживают подделки. В результате, надежность традиционных методов существенно снижается, и возникает необходимость в разработке принципиально новых подходов к выявлению сфабрикованного контента.
Появление генеративных моделей, таких как диффузионные модели и Flow Matching, ознаменовало новую эру в создании синтетических изображений. Эти алгоритмы способны генерировать визуальный контент, который практически невозможно отличить от фотографий, сделанных в реальности. Традиционные методы обнаружения подделок, основанные на анализе статистических аномалий, оказываются бессильны перед столь совершенными имитациями. Это требует разработки принципиально новых подходов к верификации изображений, способных учитывать сложные особенности, присущие контенту, созданному этими передовыми моделями. Вместо поиска явных дефектов, необходимо сосредоточиться на анализе скрытых закономерностей и несоответствий, которые могут указывать на искусственное происхождение изображения.
Существующие методы обнаружения подделок оказываются неспособными к обобщению, что требует их постоянной переподготовки по мере развития генеративных технологий. Этот процесс создает непрерывную гонку вооружений, поскольку каждая новая итерация генеративных моделей, таких как диффузионные модели и Flow Matching, усложняет задачу выявления синтетических изображений. Постоянная необходимость в переобучении алгоритмов не только требует значительных вычислительных ресурсов, но и не позволяет создать универсальное решение, способное эффективно противостоять постоянно меняющемуся ландшафту сгенерированного контента. В результате, существующие системы быстро устаревают, что подчеркивает необходимость разработки принципиально новых подходов к обнаружению подделок, способных адаптироваться к будущим технологическим достижениям и обеспечивать долгосрочную защиту от манипуляций с визуальной информацией.
Распространение сфабрикованного визуального контента представляет собой серьезную угрозу для доверия к изображениям и видео как к источникам информации. В эпоху, когда технологии генеративного искусственного интеллекта позволяют создавать реалистичные подделки, отличить подлинное от сфабрикованного становится все сложнее. Это подрывает веру в визуальные доказательства, используемые в журналистике, юриспруденции, медицине и повседневной жизни. Необходимость разработки надежных инструментов обнаружения манипуляций становится критически важной задачей, поскольку без них возрастает риск дезинформации, манипулирования общественным мнением и нанесения ущерба репутации. Создание эффективных методов верификации визуального контента — это не только технологическая, но и социальная необходимость, способствующая сохранению правдивости и прозрачности информационного пространства.
Извлечение Скрытого Знания: Рамка ДНК
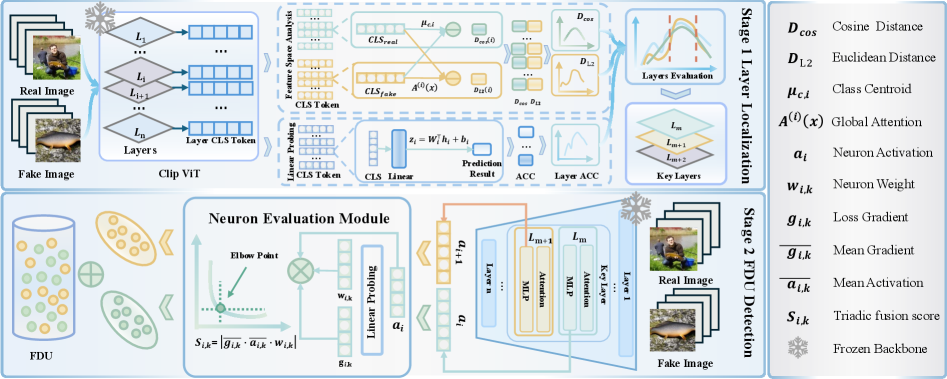
В основе подхода DNA Framework лежит использование знаний, уже заложенных в предварительно обученных моделях, таких как модели, обученные на наборе данных ImageNet. Вместо обучения с нуля для обнаружения подделок, данный подход использует существующие веса и структуры нейронных сетей, которые уже научились извлекать признаки из изображений. Предполагается, что информация о признаках, указывающих на подделку, может быть скрыта в этих предварительно обученных моделях, и DNA Framework направлен на выявление и использование этой скрытой информации. Это позволяет сократить время обучения и ресурсы, необходимые для обнаружения подделок, за счет повторного использования уже приобретенных знаний.
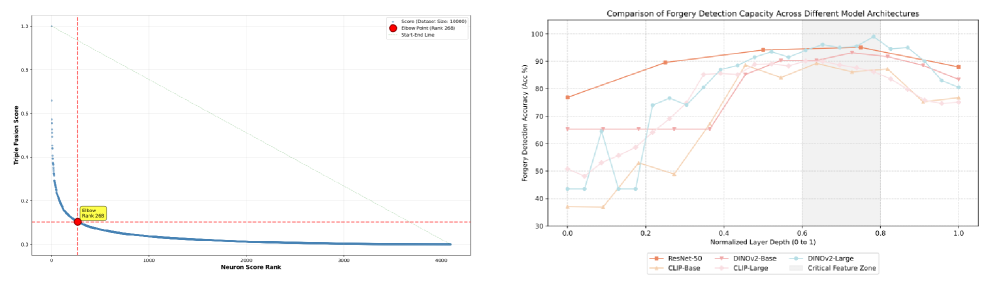
Локализация слоев является ключевым этапом в выявлении следов подделки посредством анализа нейронных сетей. Данный процесс направлен на определение наиболее информативных слоев сети, в которых сосредоточены признаки, связанные с манипуляциями с изображением. Вместо анализа всей сети, локализация слоев позволяет сосредоточиться на конкретных участках, где происходит кодирование информации о подделках, что значительно повышает эффективность и снижает вычислительные затраты. Идентификация этих критических слоев осуществляется путем оценки активаций и градиентов в различных слоях сети при обработке как оригинальных, так и поддельных изображений, что позволяет выявить слои, демонстрирующие наибольшую чувствительность к изменениям, вызванным манипуляциями.
В отличие от традиционных методов обнаружения подделок, основанных на выявлении аномалий, данный подход фокусируется на идентификации так называемых FDUs (Forgery-Discriminative Units) — нейронов, которые остаются неактивными при обработке подлинного контента, но активируются при обнаружении признаков подделки. Эти FDUs представляют собой «спящие» элементы внутри предварительно обученной нейронной сети, которые, по сути, уже содержат знания о признаках подделки, приобретенные в процессе обучения на больших наборах данных. Активация этих FDUs указывает на наличие манипуляций с изображением или другим типом контента, позволяя выявить следы подделки без необходимости явного обучения на примерах подделок.
Для выявления FDUs (Forgery-Discriminative Units) в рамках DNA Framework используется метод триадической оценки (Triadic Fusion Scoring), объединяющий три ключевых показателя. Во-первых, рассчитывается чувствительность градиента — мера изменения выходных данных сети при небольших изменениях входных данных, позволяющая оценить, насколько сильно конкретный нейрон реагирует на признаки подделки. Во-вторых, измеряется величина активации — фактический выходной сигнал нейрона при обработке входного изображения. И, наконец, учитывается вклад весов — значение весов соединений, связанных с данным нейроном, в итоговый результат. Комбинирование этих трех показателей позволяет выделить нейроны, которые наиболее эффективно реагируют на признаки подделки и вносят значительный вклад в процесс ее обнаружения. Score = w_1 <i> GradientSensitivity + w_2 </i> ActivationMagnitude + w_3 * WeightContribution, где w_i — весовые коэффициенты, определяющие значимость каждого показателя.
Подтверждение Внутренних Следов: Байесовская Оптимальность и Метрики Расстояния
Эффективность фреймворка DNA базируется на принципе байесовской оптимальности, который направлен на максимизацию байесовской вероятности ошибки. Этот подход позволяет достичь высокой точности идентификации подделок, поскольку он фокусируется на минимизации вероятности неправильной классификации, а не просто на достижении высокой общей точности. Максимизация байесовской вероятности ошибки служит критерием для обучения модели, гарантируя, что она способна надежно отличать реальные изображения от поддельных, даже в сложных случаях, когда различия между ними минимальны. Данный метод позволяет оптимизировать процесс обучения с учетом априорных вероятностей и стоимости ошибок, что особенно важно в задачах, где последствия ложноположительных или ложноотрицательных срабатываний существенно различаются.
Расстояние Махаланобиса обеспечивает надежную метрику для количественной оценки разделения между распределениями реальных и поддельных изображений, подтверждая наличие внутренних следов подделки. В отличие от евклидова расстояния, расстояние Махаланобиса учитывает ковариацию данных, что делает его более устойчивым к шуму и коррелированным признакам. D_M = \sqrt{(x - \mu)^T \Sigma^{-1} (x - \mu)}, где x — вектор признаков изображения, μ — средний вектор признаков, а Σ — матрица ковариации. Более высокое расстояние Махаланобиса между реальными и поддельными изображениями указывает на лучшее разделение и, следовательно, на более выраженные внутренние следы, которые могут быть использованы для надежного обнаружения подделок.
Анализ используемых метрик, в частности расстояния Махаланобиса, подтверждает, что функциональные единицы искажений (FDU) не ограничиваются простой запоминанием обучающих данных. Выявленная способность FDU к разделению распределений реальных и поддельных изображений свидетельствует о том, что они действительно извлекают и используют информацию, специфичную для процесса подделки. Это демонстрирует, что FDU способны к генерализации и обнаружению новых, ранее не встречавшихся подделок, а не просто распознают конкретные примеры из обучающего набора данных. Эффективное разделение распределений указывает на наличие и использование признаков, связанных непосредственно с манипуляциями над изображениями.
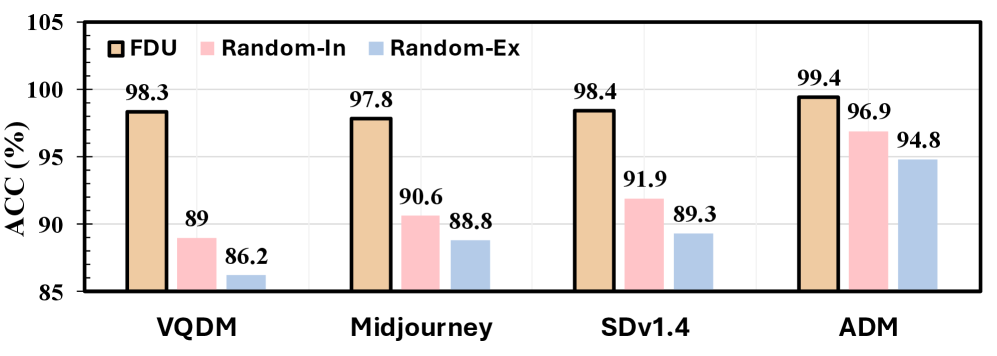
Экспериментальная валидация на датасете HIFI-Gen, содержащем сложные изображения, сгенерированные различными генеративными моделями, продемонстрировала среднюю точность в 98.6%. Данный результат превосходит показатели базовых методов и позволяет утверждать о достижении передового уровня производительности в задаче выявления подделок. Использование HIFI-Gen в качестве тестового набора данных позволило оценить устойчивость разработанного подхода к сложным и реалистичным фальсификациям, генерируемым современными алгоритмами машинного обучения.

К Надежному Обнаружению: Извлечение и Использование Признаков
Выявление функциональных единиц искажений (FDUs) играет ключевую роль в процессе извлечения признаков, позволяя разработанной системе обнаруживать даже незначительные следы манипуляций, указывающие на подделку. Эти FDUs служат своеобразными “отпечатками пальцев” цифрового вмешательства, позволяя алгоритму фокусироваться на внутренних характеристиках изображения, а не на поверхностных изменениях. Благодаря этому подходу, система способна выявлять признаки подделки, которые остаются незамеченными для традиционных методов анализа, и с высокой точностью определять аутентичность цифрового контента. Использование FDUs обеспечивает не только более точное обнаружение, но и позволяет системе адаптироваться к новым, постоянно развивающимся технологиям генерации изображений.
В рамках разработанной системы анализа подделок, известной как DNA Framework, достигнута высокая точность обнаружения — в среднем 98.6%. Этот впечатляющий результат стал возможен благодаря акценту на выявлении внутренних, присущих изображениям следов, а не на анализе внешних артефактов. При этом, инновационный подход позволил существенно снизить вычислительные затраты — более чем в десять раз по сравнению с традиционными методами, что делает систему особенно эффективной и доступной для применения в условиях ограниченных ресурсов. Высокая скорость и точность анализа обеспечивают надежную защиту от все более совершенных подделок, создаваемых современными генеративными моделями.
Разработанная система продемонстрировала высокую эффективность в выявлении подделок, достигнув точности 96.4% на датасете HIFI-Gen. Важно отметить, что система не только успешно распознает сгенерированные изображения, но и сохраняет свою точность при анализе данных, полученных от ранее неизвестных генеративных моделей, таких как FLUX и SDv3.5. Особенно впечатляющим является результат, полученный на датасете Midjourney — 97.9% точности, что более чем в полтора раза превышает показатель базового метода, составляющий всего 64.1%. Данные результаты подтверждают способность системы адаптироваться к новым технологиям генерации изображений и обеспечивать надежную защиту от подделок.
Предложенный подход открывает перспективы для создания систем обнаружения подделок, способных более эффективно адаптироваться к постоянно развивающимся генеративным технологиям. Вместо того, чтобы полагаться на обнаружение конкретных артефактов, связанных с определенными моделями генерации изображений, система фокусируется на извлечении фундаментальных признаков, присущих самим процессам генерации. Это позволяет ей сохранять высокую точность даже при появлении новых, ранее неизвестных генеративных моделей, таких как FLUX или SDv3.5, и успешно обнаруживать подделки, созданные с помощью Midjourney, значительно превосходя показатели базовых методов. Такая адаптивность особенно важна в условиях стремительного развития области искусственного интеллекта, где новые методы генерации изображений появляются практически ежедневно, и поддержание актуальности систем обнаружения становится сложной задачей.
Исследование демонстрирует, что извлечение скрытых знаний из предварительно обученных моделей предоставляет значительное преимущество в условиях ограниченных вычислительных ресурсов. Вместо постоянной переподготовки, требующей больших затрат времени и энергии, система способна использовать уже накопленный опыт модели, адаптируя его для обнаружения подделок. Такой подход не только снижает потребность в постоянном обучении, но и позволяет создавать более гибкие и эффективные системы обнаружения, способные адаптироваться к новым методам генерации изображений без значительных дополнительных затрат. Это особенно важно в контексте быстро развивающихся генеративных моделей, где постоянное обновление алгоритмов обнаружения является сложной задачей.
Исследование, посвящённое выявлению скрытых знаний в нейронных сетях, неизбежно наталкивается на проблему интерпретируемости. Авторы предлагают метод DNA, выделяющий ключевые ‘дискриминативные нейронные якоря’ — попытка обуздать хаос сложных моделей. Это напоминает о вечной борьбе между теорией и практикой. Как справедливо заметила Фэй-Фэй Ли: «Искусственный интеллект — это не замена человеческому разуму, а расширение его возможностей». В данном контексте, DNA — это не создание идеального детектора подделок, а инструмент, позволяющий извлечь максимум пользы из уже существующих, пусть и не всегда понятных, моделей. В конце концов, как показывает опыт, багтрекер рано или поздно заполнится логами об ошибках даже самых элегантных алгоритмов.
Что дальше?
Предложенная работа, безусловно, элегантна в своей концепции извлечения «дискриминативных нейронных якорей». Однако, история учит, что каждая «универсальная» схема неизбежно сталкивается с реальностью данных, которые всегда оказываются менее упоряченными, чем предполагалось. Вероятно, наиболее интересным направлением дальнейших исследований станет изучение устойчивости этих «якорей» к различным типам искажений и артефактов, которые неизбежно возникают в реальных условиях эксплуатации. В конце концов, «детектор» — это лишь часть системы, а «атакующий» всегда найдёт способ обойти даже самую изощрённую защиту.
Перспектива использования предобученных моделей в качестве «основы» для обнаружения подделок выглядит привлекательно, но не лишена рисков. Эффективность подхода, вероятно, сильно зависит от качества и разнообразия данных, на которых обучалась исходная модель. Не исключено, что «универсальное знание» о подделках окажется лишь статистическим шумом, который случайно совпадает с реальными признаками манипуляций. И тогда, возможно, лучше один хорошо обученный классификатор, чем сотня «якорей», каждый из которых выдаёт ложные срабатывания.
В конечном счёте, поиск «универсального» решения в области обнаружения подделок — это, скорее, философская задача, чем чисто техническая. Попытки создать «самообучающийся» детектор неизбежно приведут к появлению новой формы «технического долга», когда необходимость в постоянной адаптации к новым типам атак перевесит все преимущества автоматизации. Иногда, пожалуй, проще и надёжнее — человеческий глаз.
Оригинал статьи: https://arxiv.org/pdf/2601.22515.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-02 13:20