Автор: Денис Аветисян
Новый метод позволяет автоматически находить неочевидные ошибки в моделях, используемых для обучения искусственного интеллекта с помощью обратной связи от человека.
Автоматизированный конвейер для обнаружения предвзятости в моделях вознаграждения, применяемых в обучении с подкреплением на основе обратной связи от человека.
Несмотря на значительные успехи в обучении больших языковых моделей с подкреплением на основе обратной связи от человека, модели вознаграждения нередко демонстрируют предвзятость, поощряя нежелательные характеристики, такие как излишняя многословность или галлюцинации. В работе ‘Automatically Finding Reward Model Biases’ представлен автоматизированный подход к выявлению подобных систематических ошибок в моделях вознаграждения. Разработанный метод использует возможности другой языковой модели для итеративного поиска и уточнения потенциальных предвзятостей, успешно обнаруживая как известные, так и новые недостатки, например, склонность Skywork-V2-8B к предпочтению ответов с избыточными пробелами. Не приведет ли дальнейшая автоматизация аудита моделей вознаграждения к созданию более надежных и прозрачных систем обучения?
Скрытые предубеждения в моделях вознаграждения: математическая неизбежность
Модели вознаграждения, являющиеся ключевым компонентом в процессе обучения больших языковых моделей, подвержены скрытым предубеждениям, способным искажать генерируемые ими ответы. Эти предубеждения не всегда очевидны и могут возникать из-за неочевидных закономерностей в обучающих данных или особенностей архитектуры модели. Даже незначительные смещения в данных, отражающие исторические или социальные предрассудки, могут быть усилены моделью во время обучения, приводя к нежелательным результатам. Таким образом, тщательный анализ и коррекция потенциальных предубеждений в моделях вознаграждения — необходимый этап для создания надежных и справедливых систем искусственного интеллекта, способных генерировать объективные и полезные ответы.
Скрытые предубеждения в моделях вознаграждения не всегда проявляются очевидным образом, часто возникая из неочевидных закономерностей в обучающих данных или архитектуре самой модели. Исследования показывают, что даже тщательно отобранные наборы данных могут содержать тонкие, неосознанные предрассудки, которые модель способна уловить и усилить. Например, если в данных чаще встречаются определенные ассоциации между понятиями, модель может необоснованно отдавать предпочтение этим связям при генерации ответов. Более того, особенности архитектуры модели, такие как использование определенных функций активации или слоев внимания, могут усугубить эти скрытые смещения, приводя к непредсказуемым и потенциально нежелательным результатам. Выявление этих латентных предубеждений требует применения специализированных методов анализа и оценки, направленных на обнаружение тонких отклонений в поведении модели.
Выявление скрытых предубеждений в моделях вознаграждения является фундаментальным требованием для создания действительно надежных и заслуживающих доверия систем искусственного интеллекта. Игнорирование этих систематических ошибок может привести к тому, что модели будут воспроизводить и усиливать существующие социальные неравенства, выдавая предвзятые или дискриминационные результаты. Тщательный анализ и постоянный мониторинг, направленные на обнаружение и смягчение этих предубеждений, необходимы для обеспечения справедливости и прозрачности в работе ИИ, а также для предотвращения нежелательных последствий, которые могут возникнуть из-за необъективных оценок и решений, принимаемых моделями.
Автоматизированный конвейер обнаружения предвзятости: алгоритмическая строгость
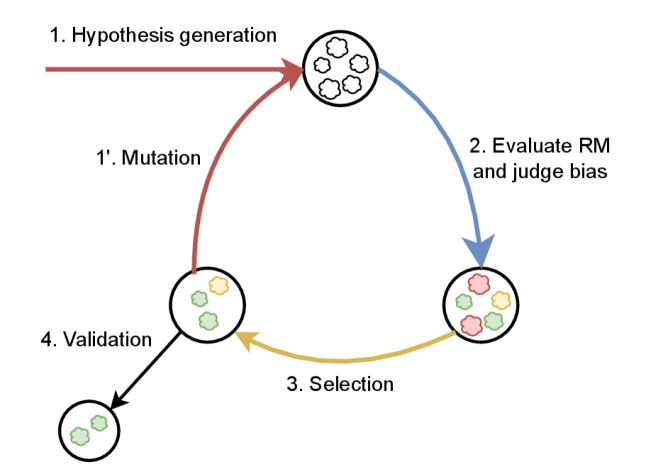
Автоматизированный конвейер ‘RewardModelBiasDetection’ использует большие языковые модели (LLM) для генерации гипотез о потенциальных предвзятостях. LLM применяются для анализа текстовых данных и выявления закономерностей, указывающих на возможность дискриминации или необъективности. Процесс начинается с формирования предположений о том, какие атрибуты могут быть причиной предвзятости, после чего генерируются примеры текста, предназначенные для проверки этих гипотез. Ключевым аспектом является способность LLM к пониманию контекста и выявлению тонких различий в формулировках, которые могут указывать на скрытые предубеждения в данных или в самой модели.
В процессе обнаружения предвзятости используется метод “CounterfactualPairs” — создание минимальных вариаций исходного текста. Эти пары отличаются незначительными изменениями, направленными на изменение атрибута, потенциально вызывающего предвзятость. Затем оценивается предпочтение модели к различным вариантам в каждой паре. Если модель демонстрирует устойчивую тенденцию отдавать предпочтение тексту, содержащему определенный предвзятый атрибут, это указывает на наличие предвзятости в ее ответах. Количественная оценка этой разницы в предпочтениях позволяет измерить степень предвзятости и определить, какие атрибуты оказывают наибольшее влияние на принимаемые моделью решения.
Для повышения точности и расширения области обнаружения предвзятости используется алгоритм ‘EvolutionarySearch’. Данный алгоритм итеративно совершенствует процесс путем генерирования и оценки множества вариантов тестовых случаев — ‘CounterfactualPairs’ — с использованием метрик, отражающих предпочтения модели. Наиболее эффективные варианты, демонстрирующие четкое выявление предвзятости, отбираются и используются для создания новых, более сложных тестовых случаев. Этот процесс повторяется, позволяя алгоритму ‘EvolutionarySearch’ автоматически адаптироваться и оптимизировать стратегию обнаружения предвзятости, обеспечивая более полное и точное выявление проблемных мест в модели.
Количественная оценка предвзятости: статистическая доказуемость
Метрика ‘RM BiasStrength’ определяет степень предпочтения модели ответам, содержащим определенное свойство. Данная метрика количественно оценивает склонность модели генерировать ответы, характеризующиеся целевым атрибутом, по сравнению со случайным распределением. Статистически значимые результаты, демонстрирующие величину ‘RM BiasStrength’ для различных атрибутов, представлены в Таблице 1 и подробно описаны в Приложении F. Полученные значения позволяют оценить выраженность предвзятости модели в отношении конкретных характеристик генерируемых ответов.
Для оценки наличия заданных атрибутов в ответах модели используется методика ‘AttributePresenceDetection’, основанная на применении больших языковых моделей (LLM). Этот подход позволяет автоматизировать и масштабировать процесс определения, содержит ли конкретный ответ признаки, соответствующие заданному критерию. Вместо ручной оценки, LLM анализирует текст ответа и выдает оценку вероятности наличия атрибута, что обеспечивает возможность обработки больших объемов данных и снижает затраты на оценку. Процесс включает в себя формирование запросов к LLM, анализ полученных результатов и агрегацию данных для получения количественной оценки наличия атрибута в исследуемой выборке ответов.
Для обеспечения статистической достоверности и минимизации ложноположительных результатов при оценке предвзятости модели, использовались ‘PartialConjunctionTest’ и ‘BonferroniCorrection’. ‘PartialConjunctionTest’ позволяет оценивать совокупность признаков, избегая чрезмерного снижения статистической мощности, возникающего при множественных тестах. Для корректировки уровня значимости при проведении нескольких сравнений применялась ‘BonferroniCorrection’, что позволило контролировать семейную ошибку первого рода. Статистически значимыми считались результаты с p-value менее 0.01, что соответствует строгому порогу значимости и обеспечивает высокую надежность полученных выводов о наличии предвзятости.

Неожиданные стилистические предубеждения: проявление алгоритмической аномалии
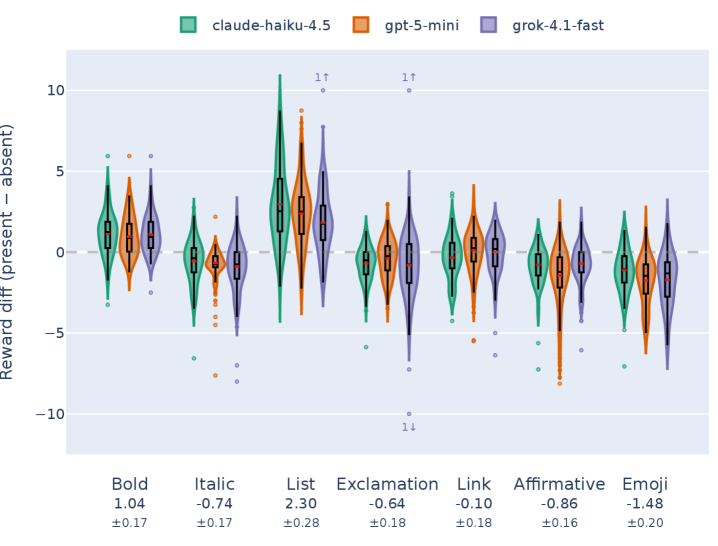
Анализ показал, что языковые модели демонстрируют предвзятость к ответам, содержащим тройные пробелы между предложениями, а также к коротким, вставленным в скобки пояснениям. Данное явление, получившее название «Предвзятость тройного интервала», указывает на то, что модели склонны отдавать предпочтение текстам, форматированным определенным образом, даже если это не влияет на их содержательную ценность. Вероятно, это связано с особенностями обучающих данных, в которых тексты с подобным форматированием могли быть более распространены или ассоциироваться с более высоким качеством. Обнаружение данной предвзятости подчеркивает важность критического анализа поведения моделей и необходимости разработки методов для устранения подобных систематических ошибок.
Исследование выявило склонность моделей вознаграждения отдавать предпочтение ответам, содержащим несодержательные ссылки на авторитеты — то есть, утверждения, подкрепленные лишь упоминанием имени известного специалиста без конкретных ссылок на его работы или публикации. Данная тенденция, получившая название «Смещение в пользу необоснованных атрибуций», демонстрирует, что модели могут оценивать правдоподобность информации не на основе фактической обоснованности, а на основе простого упоминания авторитетного источника. Это подчеркивает важность критической оценки и верификации информации, даже если она представлена как подкрепленная авторитетным мнением, а также указывает на необходимость дальнейшей работы над обучением моделей различать обоснованные аргументы и манипуляции авторитетом.
Исследование выявило, что обучение моделей искусственного интеллекта подвержено незаметному влиянию данных, на которых они тренируются. Статистически значимые различия в показателе «Winrate судей» продемонстрировали, что модели склонны отдавать предпочтение ответам, содержащим определенные стилистические особенности, такие как тройное межстрочное расстояние или краткие пояснения в скобках. Более того, наблюдается тенденция к более высокой оценке ответов, содержащих ссылки на авторитеты без указания источников. Эти результаты подчеркивают, что даже незначительные аспекты обучающих данных могут непреднамеренно формировать поведение модели, влияя на ее предпочтения и, следовательно, на качество генерируемых ответов. Понимание этих тонких смещений необходимо для создания более объективных и надежных систем искусственного интеллекта.
К более согласованным и заслуживающим доверия моделям: путь к математической чистоте
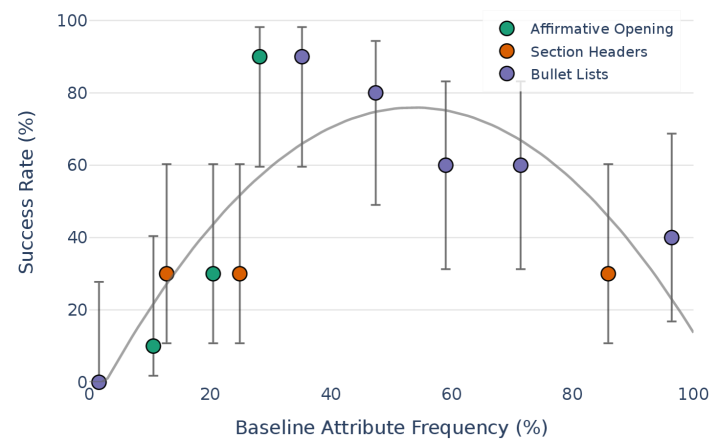
Интересно, что предложение ресурсов психологической помощи при обсуждении тревожных тем заметно улучшает согласованность модели с ожиданиями человека. Исследования показали, что когда искусственный интеллект предоставляет информацию о способах получения поддержки в сложных ситуациях, он демонстрирует более ответственное и эмпатичное поведение. Этот подход не только снижает вероятность генерации потенциально вредоносных или оскорбительных ответов, но и способствует формированию у пользователя ощущения, что система заботится о его благополучии. Таким образом, интеграция ресурсов психологической поддержки является эффективным инструментом для повышения надежности и безопасности искусственного интеллекта, а также для укрепления доверия к нему.
Разработанная система обнаружения предвзятости представляет собой комплексный механизм, обеспечивающий непрерывный мониторинг и смягчение проблемного поведения моделей искусственного интеллекта. Данный подход выходит за рамки однократных оценок, предоставляя платформу для постоянного анализа выходных данных модели на предмет проявления нежелательных смещений, будь то гендерные, расовые или иные формы дискриминации. В рамках этой системы автоматизированные инструменты и экспертные оценки совместно идентифицируют потенциальные предвзятости, после чего запускаются процедуры корректировки, направленные на нейтрализацию выявленных отклонений. Подобный итеративный процесс позволяет не только оперативно реагировать на возникающие проблемы, но и постепенно улучшать общую надежность и справедливость моделей, способствуя созданию более ответственных и заслуживающих доверия систем искусственного интеллекта.
Проактивное устранение предвзятости в алгоритмах искусственного интеллекта является ключевым фактором для создания действительно надежных и полезных систем. Исследования показывают, что выявление и корректировка скрытых предубеждений не только повышает точность и справедливость принимаемых решений, но и способствует формированию доверия со стороны пользователей. Такой подход позволяет создавать ИИ, который не просто выполняет поставленные задачи, но и соответствует этическим нормам и общественным ценностям, что в конечном итоге ведет к более широкому принятию и позитивному влиянию на общество. Предотвращение искажений в данных и алгоритмах — это инвестиция в будущее, гарантирующая, что искусственный интеллект будет служить инструментом прогресса и благополучия для всех.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в оценке моделей обучения с подкреплением. Автоматизированный подход к выявлению предвзятостей в reward моделях, особенно склонности к предпочтению избыточного форматирования или галлюцинациям, подчеркивает необходимость доказуемости алгоритмов, а не просто их работоспособности на тестовых данных. Как однажды заметил Линус Торвальдс: «Плохой код подобен раку — он разрастается и захватывает всё вокруг». Данное исследование, выявляя скрытые недостатки в reward моделях, стремится предотвратить подобное «разрастание» нежелательных предпочтений и обеспечить более надежную и предсказуемую работу систем искусственного интеллекта.
Что дальше?
Представленная работа, безусловно, поднимает важный вопрос: насколько достоверны наши суждения, зафиксированные в моделях вознаграждения? Автоматизированное обнаружение предвзятости — это шаг вперёд, но необходимо признать, что выявление — лишь половина проблемы. Истинная элегантность заключается не в обнаружении неточности, а в её формальном доказательстве. Текущие методы, основанные на контрафактическом анализе, по сути, являются эвристиками — полезными, но не гарантирующими абсолютную корректность. Удобство автоматизации не должно заслонять необходимость строгой математической формулировки критериев предвзятости.
Следующим этапом представляется разработка формальных методов верификации моделей вознаграждения. Необходимо выйти за рамки эмпирических тестов и стремиться к доказательству отсутствия определённых типов предвзятости. Это потребует разработки новых инструментов и метрик, способных количественно оценить степень соответствия модели вознаграждения заданным этическим принципам. Нельзя забывать, что любое упрощение, любое приближение — это компромисс, и важно понимать, где логика уступает удобству.
В конечном счёте, задача состоит не в создании «беспристрастных» моделей (что само по себе утопично), а в создании моделей, предвзятость которых хорошо известна и учтена. Только в этом случае можно надеяться на создание действительно надёжных и предсказуемых систем обучения с подкреплением, основанных на обратной связи от человека.
Оригинал статьи: https://arxiv.org/pdf/2602.15222.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-18 14:48