Автор: Денис Аветисян
Новое исследование показывает, что модели, создающие изображения по текстовому описанию, оставляют уникальные следы в своих творениях, позволяя идентифицировать их даже без знания исходных запросов.
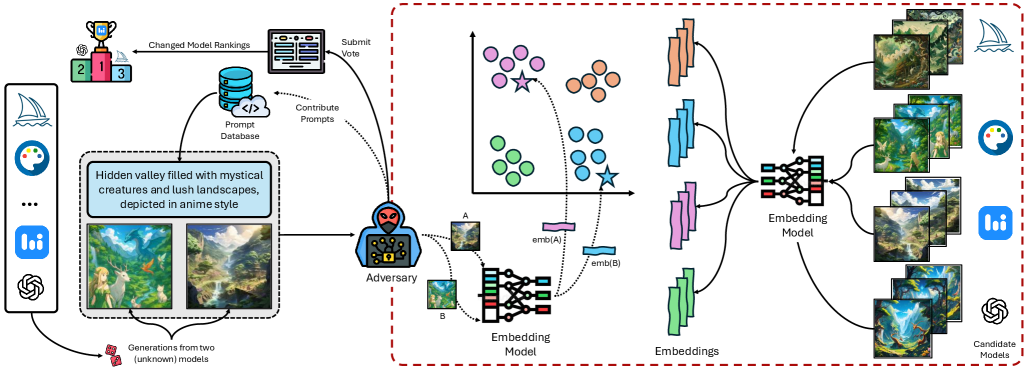
Анализ векторного пространства и уязвимости к состязательным атакам позволяют с высокой точностью деанонимизировать модели, участвующие в рейтингах генерации изображений.
Несмотря на стремление к объективной оценке, рейтинги моделей генерации изображений по текстовому описанию оказываются уязвимыми. В работе ‘Identifying Models Behind Text-to-Image Leaderboards’ показано, что анонимность моделей в подобных рейтингах легко нарушить, поскольку каждая из них формирует уникальные кластеры в пространстве эмбеддингов изображений. Авторы продемонстрировали возможность точной деанонимизации моделей без контроля над запросами и использования обучающих данных, выявив специфические сигнатуры, присущие каждой модели. Не ставит ли это под вопрос надежность существующих систем оценки и не потребуются ли более надежные методы защиты анонимности?
Иллюзия Анонимности: Подъем Лидербордов и Его Обратная Сторона
В последнее время наблюдается значительный рост популярности онлайн-таблиц лидеров в качестве основного инструмента оценки моделей преобразования текста в изображения. Этот подход стимулирует стремительное развитие данной области искусственного интеллекта, поскольку конкуренция между разработчиками подталкивает их к постоянному совершенствованию своих алгоритмов. Публичное ранжирование моделей по качеству сгенерированных изображений позволяет быстро выявлять наиболее перспективные решения и направлять дальнейшие исследования. Подобная система оценки, основанная на коллективном суждении и прозрачной конкуренции, значительно ускоряет темпы инноваций и способствует появлению всё более реалистичных и креативных генеративных моделей.
В основе рейтингов, формируемых голосованием, лежит принцип анонимности представленных моделей искусственного интеллекта. Данный подход призван исключить предвзятость, возникающую из-за репутации разработчиков или предубеждений, связанных с известными брендами. Анонимность позволяет оценивать качество генерации изображений исключительно на основе визуального восприятия, обеспечивая более справедливое сравнение различных подходов и алгоритмов. Пользователи, не зная, какая модель создала конкретное изображение, концентрируются на эстетических качествах и соответствии запросу, что способствует выявлению действительно инновационных и эффективных решений в области генеративного искусственного интеллекта. Таким образом, анонимность является ключевым элементом обеспечения объективности и стимулирования прогресса в данной сфере.
Несмотря на стремление к полной анонимности участников в рейтинговых системах, основанных на оценках пользователей, полная конфиденциальность зачастую оказывается иллюзорной. Анализ данных показывает, что даже при маскировке идентификаторов моделей, существуют способы деанонимизации через косвенные признаки, такие как стиль генерации изображений или особенности реализации алгоритмов. Это открывает возможности для манипулирования рейтингами, когда заинтересованные стороны могут искусственно завышать оценки своим моделям или понижать оценки конкурентам. Возникает опасность формирования предвзятых оценок и несправедливого преимущества для тех, кто обладает ресурсами для обхода систем анонимизации, что подрывает доверие к результатам рейтингов и тормозит объективное развитие технологий генерации изображений.
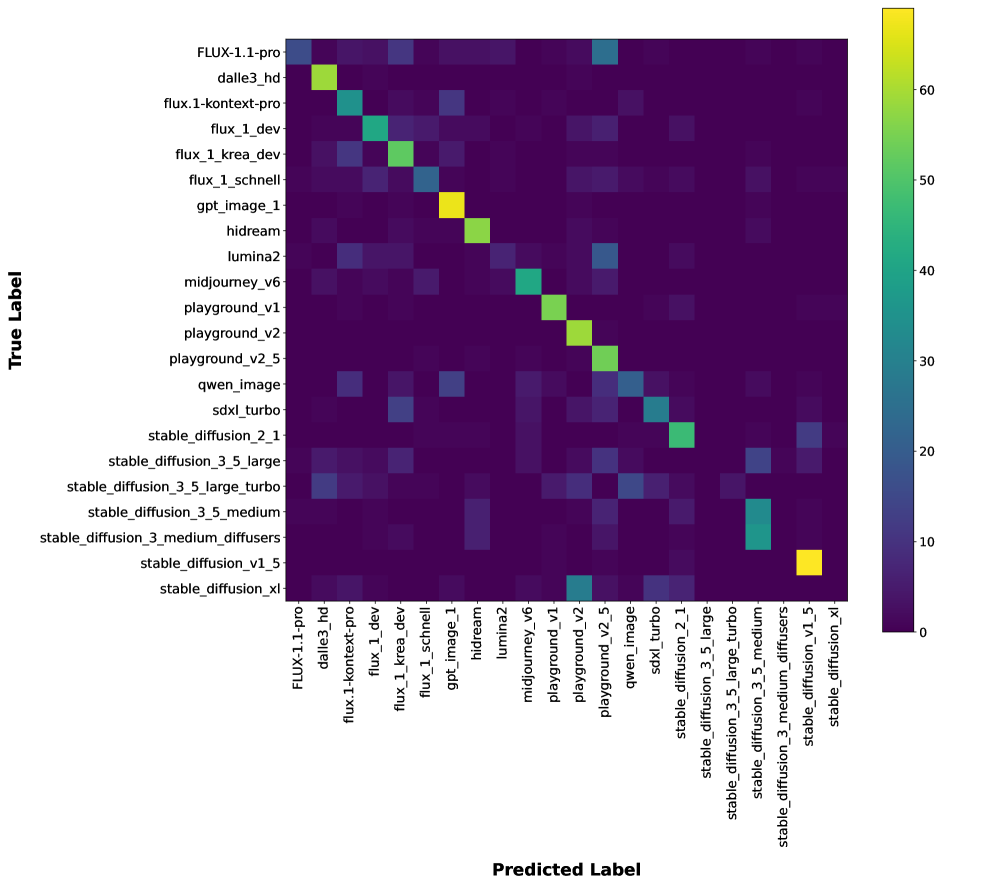
Раскрытие Генераторов: Угроза Деанонимизации
Методы деанонимизации позволяют идентифицировать модель, использованную для генерации изображения, основываясь на едва заметных артефактах и особенностях, присущих конкретной архитектуре или процессу обучения. Эти особенности могут включать статистические паттерны в частотном домене, уникальные шумы, возникающие в процессе генерации, или тонкие несоответствия в текстурах и деталях. Анализ этих характеристик позволяет отличить изображения, созданные разными генеративными моделями, даже если они визуально похожи. Важно отметить, что деанонимизация не требует знания параметров модели, а основывается исключительно на анализе выходных данных — сгенерированных изображений.
Для сравнительного анализа изображений, сгенерированных различными моделями, ключевым этапом является получение векторного представления — встраивания (embedding). Модели, такие как CLIP (Contrastive Language-Image Pre-training) и SigLip, преобразуют изображение в многомерный вектор, отражающий его семантические особенности. CLIP, обученный на большом объеме пар «изображение-текст», позволяет сопоставлять визуальный контент с текстовыми описаниями, создавая универсальные встраивания. SigLip, в свою очередь, использует лингвистические признаки для формирования встраиваний, что может быть полезно для анализа изображений, содержащих текст. Полученные векторные представления позволяют количественно оценить сходство между изображениями и являются основой для последующей классификации и идентификации модели-генератора.
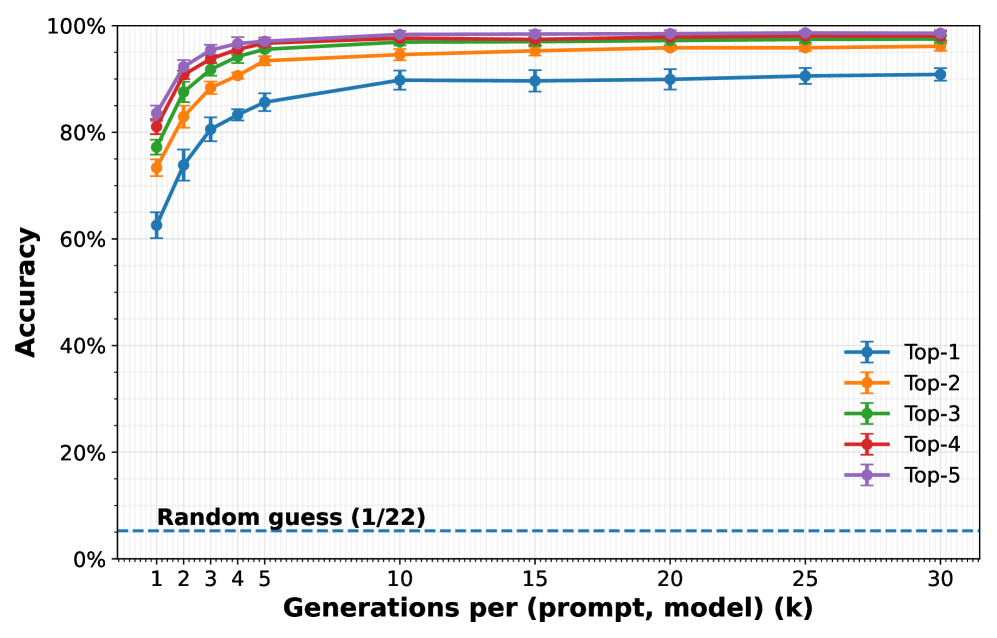
Классификация на основе центроидов позволяет определить происхождение сгенерированного изображения путем кластеризации векторных представлений (эмбеддингов), полученных с помощью моделей, таких как CLIP и SigLip. В процессе анализа вычисляется центроид для каждого кластера, представляющего конкретную генеративную модель. При сопоставлении эмбеддинга анализируемого изображения с этими центроидами, определяется наиболее вероятный источник генерации. В наших экспериментах данный метод достиг точности в 91% при определении источника генерации (top-1 accuracy), что свидетельствует о высокой эффективности подхода.
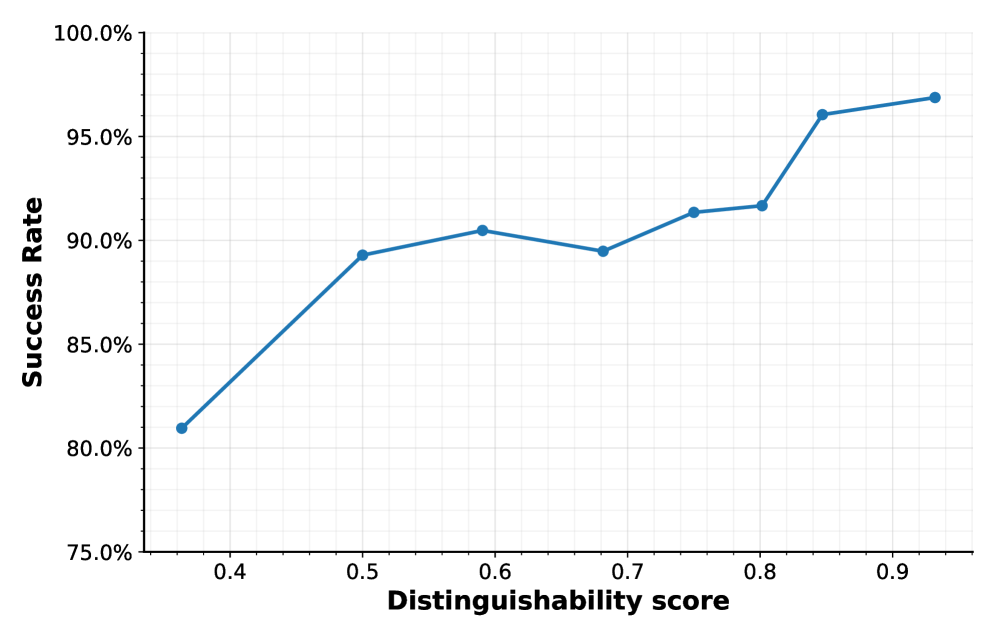
Атака на Анонимность: Состязательные Стратегии и Уязвимости
Атакующие действия, направленные на манипулирование рейтингами в таблицах лидеров, включают в себя преднамеренную деанонимизацию моделей. Целью таких атак является раскрытие информации о разработчике или настройках конкретной модели, что позволяет злоумышленникам искусственно завышать или занижать её позиции в рейтинге. Деанонимизация достигается путём анализа выходных данных модели и сопоставления их с характеристиками, присущими конкретным разработчикам или методам обучения. Успешная деанонимизация подрывает честность оценки моделей и может привести к принятию неверных решений на основе искаженных результатов.
Успешная деанонимизация моделей, участвующих в соревнованиях и оценках, подрывает принципы справедливого сопоставления и приводит к намеренному искажению результатов. Компрометация анонимности позволяет участникам стратегически манипулировать рейтингами, представляя модели, оптимизированные не для общей производительности, а для обхода конкретных методов анализа или эксплуатации уязвимостей в системе оценки. Это создает ситуацию, когда лидерборд отражает не истинный уровень качества моделей, а способность участников к манипуляциям и стратегическому обману, что искажает ценность и достоверность результатов оценки.
Эффективность атак, направленных на деанонимизацию моделей, напрямую зависит от различий в их генерациях. Различают межмодельную вариативность (Inter-Model Variation), отражающую расхождения между разными моделями при генерации одного и того же запроса, и внутримодельную вариативность (Intra-Model Variation), характеризующую расхождения в генерациях одной и той же модели при повторных запросах. Наши исследования показали, что при полном доступе ко всем моделям, точность деанонимизации достигает 99.16%, что указывает на высокую чувствительность к этим вариациям и возможность точной идентификации моделей на основе анализа их выходных данных.
Защита Анонимности: Сохранение Целостности и Конфиденциальности
Изображения, подвергнутые небольшим возмущениям, могут служить эффективным средством защиты от атак, направленных на раскрытие личности. Данный подход основан на нарушении структуры кластеров векторов признаков, формируемых нейронными сетями при анализе изображений. Возмущения, хоть и незначительные для человеческого глаза, приводят к смещению векторов признаков, затрудняя идентификацию изображений и, следовательно, препятствуя деанонимизации. По сути, эта техника создает «шум» в пространстве признаков, делая сложным для атакующего сопоставление изображения с конкретным человеком или объектом, даже если у атакующего есть доступ к базе данных изображений. Такой метод защиты позволяет значительно усложнить процесс идентификации, повышая уровень конфиденциальности и безопасности.
В основе данной защиты лежит использование функции потерь, известной как Contrastive Loss, при обучении моделей. Эта функция нацелена на создание векторных представлений (embeddings), устойчивых к незначительным изменениям во входных данных. Вместо того, чтобы модель чрезмерно реагировала на небольшие искажения изображения, Contrastive Loss способствует формированию более робастных представлений, где близкие по смыслу изображения имеют схожие векторы даже после небольших модификаций. Это достигается путем обучения модели минимизировать расстояние между представлениями схожих изображений и максимизировать расстояние между представлениями различных изображений, что в итоге затрудняет идентификацию изображений по их векторным представлениям даже при наличии небольших возмущений.
Исследования показали, что стоимость деанонимизации одного изображения с использованием коммерческих моделей составляет всего $1.08. Однако, применение методов аверсивной постобработки способно значительно снизить точность атак. Установлено, что увеличение бюджета на возмущения — то есть, допустимый уровень изменений в изображении — напрямую коррелирует с усилением защитных свойств. Более существенные модификации изображения затрудняют процесс деанонимизации, делая его менее эффективным для злоумышленников и обеспечивая более надежную защиту конфиденциальной информации.

Исследование демонстрирует, что генеративные модели, участвующие в рейтингах, обладают уникальными «отпечатками», позволяющими идентифицировать их даже при отсутствии контроля над входными запросами. Этот аспект перекликается с представлением об элегантности как о признаке глубокого понимания. Как отмечает Джеффри Хинтон: «Мы должны стремиться к созданию систем, которые не только работают, но и понятны». Подобно тому, как опытный дизайнер стремится к гармонии формы и функции, создатели моделей должны учитывать, что их творения будут оцениваться не только по производительности, но и по возможности отследить их происхождение и особенности генерации изображений. Уникальные характеристики, проявляющиеся в пространстве внедрений, служат своеобразным «автографом» каждой модели, подтверждая её индивидуальность и сложность.
Куда же дальше?
Представленная работа обнажает уязвимость, которую долгое время предпочитали не замечать: легкость идентификации генеративных моделей по их «отпечатку» в пространстве эмбеддингов. Вместо элегантной защиты, полагающейся на сложность и многообразие, мы видим, как модели, стремящиеся к лидерству, невольно выдают себя. По сути, гонка за первенство выявляет не совершенство, а предсказуемость. Вопрос не в том, чтобы усложнить алгоритмы, а в том, чтобы признать, что истинная безопасность — это не маскировка, а фундаментальная устойчивость.
Очевидным следующим шагом является разработка методов, способных противостоять этим атакам. Однако, вероятно, более продуктивным направлением станет исследование принципиально новых подходов к оценке генеративных моделей, уход от зависимости от легко манипулируемых лидеров таблиц. Необходимо стремиться к метрикам, отражающим не только «видимую» производительность, но и внутреннюю устойчивость к деанонимизации и атакам, направленным на раскрытие лежащих в основе принципов работы.
В конечном счете, задача заключается не в том, чтобы “залатать дыры”, а в том, чтобы переосмыслить саму идею соревнований в области генеративных моделей. Красота масштабируется, беспорядок — нет. Неизбежно, акцент сместится с количественных показателей на качественные, с внешней демонстрации возможностей на внутренней гармонии формы и функции. Рефакторинг, а не перестройка — вот путь к действительно устойчивой и безопасной генеративной модели.
Оригинал статьи: https://arxiv.org/pdf/2601.09647.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-01-16 04:06