Автор: Денис Аветисян
Новое исследование анализирует компромиссы между защитой персональных данных и практической ценностью при создании синтетических финансовых данных.
Оценка рисков утечки информации и баланс между конфиденциальностью и полезностью в генеративных моделях для финансовых табличных данных.
Несмотря на растущую потребность в обмене финансовыми данными, обеспечение конфиденциальности остается сложной задачей. В работе ‘Measuring Privacy Risks and Tradeoffs in Financial Synthetic Data Generation’ исследуется компромисс между конфиденциальностью и полезностью при генерации синтетических финансовых данных, особенно в условиях высокой регуляторной нагрузки и значительного дисбаланса классов. Полученные результаты показывают, что, хотя методы дифференциальной приватности могут защитить данные, они часто приводят к снижению качества генерируемых данных, а оценка степени защиты конфиденциальности требует тщательного анализа. Какие новые подходы позволят эффективно генерировать синтетические финансовые данные, обеспечивая одновременно высокий уровень конфиденциальности и сохраняя при этом их аналитическую ценность?
Данные, которых нет: Новый рубеж машинного обучения
В последнее время доступ к реальным данным для обучения моделей машинного обучения становится все более затрудненным. Ужесточение законодательства о защите персональных данных, такого как GDPR и другие нормативные акты, а также возрастающая осведомленность общества о конфиденциальности информации, создают серьезные препятствия для исследователей и разработчиков. Организации опасаются утечек данных и связанных с ними репутационных и финансовых рисков, что приводит к ограничению доступа даже к анонимизированным данным. Эта тенденция замедляет прогресс в областях, где машинное обучение играет ключевую роль, включая здравоохранение, финансы и автономные системы, поскольку для эффективной работы моделей требуются большие объемы данных, а их получение становится все более сложным и дорогостоящим процессом.
Стремительное развитие технологий машинного обучения и искусственного интеллекта повлекло за собой беспрецедентный рост потребности в репрезентативных наборах данных. Однако, получение доступа к реальным данным сталкивается со всё более серьезными препятствиями, обусловленными ужесточением нормативных требований к защите персональных данных и повышенной конфиденциальностью информации. Многие организации сталкиваются с трудностями при сборе и обработке данных из-за сложностей, связанных с соблюдением таких правил, как GDPR и другие локальные законодательства. Кроме того, данные, необходимые для обучения моделей, часто содержат конфиденциальную информацию о клиентах, медицинские записи или финансовые данные, что делает прямой доступ к ним невозможным или крайне ограниченным. Это создает значительные трудности для исследователей и разработчиков, стремящихся создавать и обучать эффективные модели машинного обучения, особенно в таких областях, как здравоохранение, финансы и маркетинг.
Генерация синтетических данных представляет собой перспективное решение для преодоления ограничений, связанных с доступом к реальным данным. Этот подход позволяет создавать наборы данных, имитирующие характеристики исходной информации, но при этом полностью исключающие возможность раскрытия конфиденциальных сведений. В отличие от использования реальных данных, где требуется соблюдение строгих правил защиты персональных данных, синтетические данные позволяют обучать модели машинного обучения без каких-либо опасений, сохраняя при этом высокую точность и эффективность. Этот метод особенно ценен в сферах, где доступ к реальным данным ограничен законодательством или этическими соображениями, таких как здравоохранение, финансы и государственное управление, открывая новые возможности для инноваций и развития технологий искусственного интеллекта.
Генерируем табличные данные: Инструменты и подходы
Для генерации синтетических табличных данных разработано несколько генеративных моделей, каждая из которых имеет свои преимущества и недостатки. Модель Gaussian Copula использует гауссовские копулы для моделирования взаимосвязей между переменными, что делает ее эффективной для непрерывных данных, но менее подходящей для категориальных. TVAE (Tabular Variational Autoencoder) применяет вариационные автоэнкодеры, обеспечивая хорошее представление непрерывных данных и возможность генерации новых образцов. CTGAN (Conditional Tabular Generative Adversarial Network) использует генеративно-состязательные сети (GAN) для моделирования сложных распределений, особенно хорошо справляясь с категориальными переменными, но может быть сложнее в обучении и требовать более тщательной настройки гиперпараметров.
CTGAN (Conditional Tabular Generative Adversarial Network) использует генеративно-состязательные сети (GAN) для моделирования сложных распределений категориальных признаков, что позволяет эффективно генерировать реалистичные данные, отражающие зависимости между переменными. В отличие от CTGAN, TVAE (Tabular Variational Autoencoder) применяет вариационные автоэнкодеры (VAE) для моделирования непрерывных данных, кодируя их в латентное пространство и затем декодируя для генерации новых образцов. VAE особенно эффективны при работе с данными, имеющими значительный уровень шума или неполноты, поскольку они способны восстанавливать пропущенные значения и сглаживать выбросы.
Модель TabDiff адаптирует диффузионные модели, изначально разработанные для генерации изображений, для работы с табличными данными. В результате достигается средний показатель Column Shapes, приблизительно равный 0.96, который оценивает схожесть структуры данных. Однако, при использовании механизмов дифференциальной приватности для защиты конфиденциальности данных, данный показатель, как правило, снижается, что является компромиссом между конфиденциальностью и точностью генерируемых данных.
Конфиденциальность прежде всего: Дифференциальная приватность и ее применение
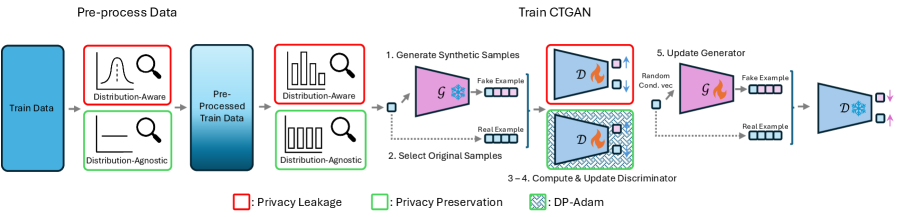
Дифференциальная приватность (DP) представляет собой строгий математический аппарат для количественной оценки и контроля утечки конфиденциальной информации в процессе генерации данных. В основе DP лежит идея добавления контролируемого шума к результатам запросов к данным, таким образом гарантируя, что присутствие или отсутствие отдельной записи в наборе данных оказывает незначительное влияние на результат запроса. Это достигается посредством параметров ε и δ, определяющих уровень приватности: ε контролирует чувствительность к отдельным записям, а δ представляет вероятность нарушения приватности. Формальное определение DP позволяет предоставлять строгие гарантии приватности, что отличает его от менее формальных подходов к защите данных.
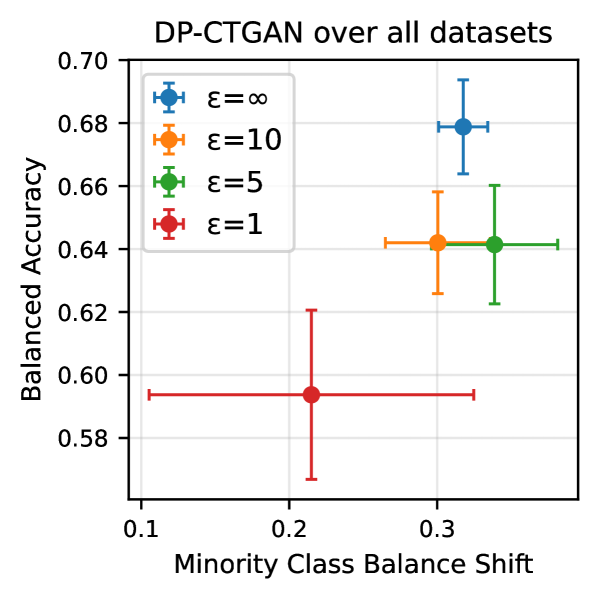
Модели DP-CTGAN и DP-TVAE реализуют механизмы дифференциальной приватности (DP) путем добавления откалиброванного шума к данным, генерируемым этими моделями. Этот подход направлен на предотвращение реидентификации отдельных записей в исходном наборе данных, используемом для обучения. Калибровка шума осуществляется таким образом, чтобы обеспечить формальное ограничение на чувствительность алгоритма, то есть максимальное влияние одной записи на результат. Добавление шума контролируется параметром ε (эпсилон), который определяет уровень приватности — чем меньше ε, тем выше уровень защиты, но и ниже полезность синтетических данных. Использование откалиброванного шума позволяет гарантировать, что наличие или отсутствие конкретной записи в обучающем наборе данных оказывает незначительное влияние на генерируемые синтетические данные, тем самым защищая приватность.
Анализ устойчивости к атакам на определение принадлежности к обучающей выборке показал, что вероятность успешной атаки составляет примерно 0.5, что указывает на некоторую возможность различить синтетические данные, сгенерированные с использованием дифференциальной приватности (DP), и исходные обучающие данные. Однако, проведенное исследование продемонстрировало возможность адаптации современных генеративных моделей, таких как DP-CTGAN и DP-TVAE, для работы с механизмами DP. Это свидетельствует о технической реализуемости применения дифференциальной приватности в современных генеративных моделях, несмотря на существующие уязвимости к атакам на определение принадлежности.
Искусственные данные на практике: Оценка эффективности и рисков
Оценка практической применимости синтетических данных является ключевым показателем их качества. Этот показатель, известный как «downstream utility», измеряет эффективность моделей машинного обучения, обученных на искусственно сгенерированных данных, при решении реальных задач. По сути, проверяется, насколько хорошо модель, «выросшая» на синтетических данных, способна обобщать знания и успешно работать с данными из реального мира. Высокий уровень практической применимости свидетельствует о том, что синтетические данные достаточно реалистичны и репрезентативны, чтобы заменить или дополнить реальные данные, особенно в ситуациях, когда доступ к последним ограничен или невозможен по соображениям конфиденциальности и безопасности.
Создание репрезентативных и надежных синтетических наборов данных требует пристального внимания к таким проблемам, как дисбаланс классов и схлопывание мод (mode collapse). Дисбаланс классов, когда некоторые категории данных представлены значительно меньше других, может привести к предвзятости моделей, обученных на синтетических данных. Схлопывание мод, возникающее в генеративных моделях, приводит к потере разнообразия и генерации ограниченного набора примеров, что снижает реалистичность и полезность синтетических данных. Эффективное решение этих проблем, например, с помощью методов взвешивания классов или продвинутых архитектур генеративных моделей, имеет решающее значение для обеспечения того, чтобы синтетические данные точно отражали сложность и разнообразие реальных данных, и могли быть использованы для обучения надежных и обобщающих моделей.
Результаты исследований показали, что сбалансированная точность (Balanced Accuracy) синтетических данных варьируется в пределах от 50% до 67%, в зависимости от используемого генератора и исходного набора данных. Особый интерес представляет тот факт, что генератор DP-CTGAN, обеспечивающий дифференциальную приватность, демонстрирует сопоставимые результаты с обычным CTGAN, при условии обучения на сбалансированных данных. Это указывает на возможность создания синтетических данных, сохраняющих полезность для последующего анализа, при одновременном обеспечении защиты конфиденциальности исходной информации, без существенной потери в качестве модели.
Исследование показывает, что попытки защитить финансовые данные с помощью дифференциальной приватности неизбежно приводят к потере полезности синтетических данных. Это предсказуемо. Каждая «революционная» технология завтра станет техдолгом. Авторы справедливо отмечают сложность строгой оценки приватности, а это значит, что в продакшене всегда найдутся способы обойти даже самые продуманные механизмы защиты. Как говорил Тим Бернерс-Ли: «Интернет не нуждается в героях, он нуждается в архитекторах». Архитекторы понимают, что идеальных решений не бывает, и что любое усложнение системы рано или поздно превратится в головную боль. В данном случае, приходится выбирать между уровнем приватности и пригодностью данных для анализа — и продлевать страдания системы, пытаясь найти баланс.
Что дальше?
Похоже, задача генерации синтетических финансовых данных, защищённых дифференциальной приватностью, оказалась не такой уж и новой. Скорее, это старая проблема, обёрнутая в модные термины. Утверждения о защите приватности, конечно, звучат убедительно, но реальная оценка рисков — это всегда игра в кошки-мышки с атаками на выявление членства. И пока эти атаки становятся всё изощрённее, а данные — сложнее, говорить о реальной защите, кажется, наивно.
В ближайшем будущем, вероятно, мы увидим ещё больше “гениальных” решений, обещающих идеальный баланс между приватностью и полезностью. Но, как показывает опыт, каждая новая библиотека — это просто ещё один уровень абстракции над старыми ошибками. И пока одни будут оптимизировать алгоритмы, другие найдут способ их обойти. DevOps, если на секунду задуматься, — это ведь просто признание поражения в вечной борьбе с техническим долгом.
В конечном итоге, вся эта гонка за приватностью напоминает попытку вылечить болезнь, не устраняя её причину. Данные нужны, их будут использовать, и рано или поздно кто-нибудь найдёт способ получить к ним доступ. Так что, возможно, стоит меньше говорить о защите и больше думать о последствиях.
Оригинал статьи: https://arxiv.org/pdf/2602.09288.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-11 16:07