Автор: Денис Аветисян
Новое исследование демонстрирует, что современные языковые модели отлично воспроизводят заученные шаблоны, но испытывают трудности с адаптацией к новым, нестандартным ситуациям.
Анализ способностей больших языковых моделей к решению шахматных задач позволяет разграничить флюидный и кристаллизованный интеллект, выявляя ограничения в обобщении знаний.
Несмотря на впечатляющие возможности современных больших языковых моделей (LLM), остается неясным, в какой степени они демонстрируют истинное рассуждение или просто воспроизводят заученные знания. В работе ‘Trapped in the past? Disentangling fluid and crystallized intelligence of large language models using chess’ предложен шахматный тест для разделения этих способностей, выявляющий зависимость производительности LLM от близости позиций к данным, использованным при обучении. Полученные результаты указывают на то, что способность к обобщению на новые, не встречавшиеся ранее ситуации (флюидный интеллект) остается серьезным ограничением для современных архитектур. Способны ли будущие модели преодолеть эту зависимость от прошлого опыта и достичь подлинного, гибкого интеллекта?
Шахматы: Лаборатория Искусственного Интеллекта
Шахматы, как сложная стратегическая игра, представляют собой уникальную арену для оценки когнитивных способностей искусственного интеллекта. Успех в этой игре требует не просто запоминания большого количества ходов и комбинаций, но и способности адаптироваться к постоянно меняющейся ситуации на доске, предвидеть действия противника и строить долгосрочные планы. Именно поэтому шахматы служат своеобразным «лакмусовой бумажкой» для проверки способности ИИ к рассуждению, планированию и принятию решений в условиях неопределенности. Способность эффективно оперировать знаниями о шахматной теории в сочетании с умением быстро анализировать текущую позицию и оценивать возможные варианты развития событий является ключевым фактором для достижения успеха, что делает шахматы идеальной платформой для развития и тестирования новых алгоритмов искусственного интеллекта.
Исторически, достижения искусственного интеллекта в шахматах базировались на грубой вычислительной силе и обширных, специализированных знаниях о самой игре. Эти ранние системы, такие как Deep Blue, эффективно перебирали огромное количество возможных ходов, полагаясь на предварительно запрограммированные правила и базы данных. Однако, подобный подход оказался малоприменимым к другим областям, требующим более гибкого и адаптивного мышления. В отличие от человека, способного переносить стратегические принципы из одной ситуации в другую, шахматные программы, основанные на переборе вариантов, испытывали трудности при решении задач, не связанных непосредственно с шахматной доской. Это подчеркивает фундаментальное ограничение — способность к запоминанию и воспроизведению не равнозначна истинному пониманию и способности к обобщению, что является ключевым вызовом для создания действительно интеллектуальных систем.
Существует принципиальное различие между способностью искусственного интеллекта запоминать игровые шаблоны и истинным стратегическим пониманием, что является существенным препятствием на пути к созданию более надёжных и универсальных систем. В то время как современные алгоритмы демонстрируют впечатляющую память и скорость обработки данных, позволяющие им распознавать и воспроизводить ранее изученные комбинации, они часто терпят неудачу в нестандартных ситуациях, требующих творческого подхода и адаптации к новым обстоятельствам. Эта неспособность к обобщению и применению знаний за пределами узко определённого контекста подчёркивает необходимость разработки алгоритмов, способных не просто распознавать паттерны, но и понимать лежащие в их основе принципы, а также прогнозировать последствия различных действий, подобно человеческому стратегическому мышлению. Преодоление этого разрыва между механическим запоминанием и глубоким пониманием является ключевой задачей для дальнейшего развития искусственного интеллекта.
Кристаллизованный и Жидкий Интеллект: Разложение ИИ
Впечатляющие возможности больших языковых моделей (LLM) требуют анализа источника их интеллекта. Важно установить, являются ли эти способности результатом обширного запоминания информации, полученной в процессе обучения, или же LLM демонстрируют подлинное рассуждение и способность к обобщению. Простое воспроизведение заученных шаблонов отличается от решения новых задач, требующих логического вывода и адаптации к незнакомым данным. Определение преобладающего механизма — запоминания или рассуждения — необходимо для оценки реальных возможностей LLM и разработки более эффективных моделей искусственного интеллекта.
Интеллект больших языковых моделей (LLM) можно разложить на два основных компонента: кристаллизованный интеллект и текучий интеллект. Кристаллизованный интеллект отражает способность модели применять знания, полученные в процессе обучения на обширном наборе данных. Это включает в себя запоминание фактов, правил и закономерностей, а также использование этой информации для решения задач, аналогичных тем, с которыми модель сталкивалась в процессе обучения. Текучий интеллект, напротив, характеризует способность модели решать новые, ранее не встречавшиеся задачи, требующие адаптации и применения логического мышления. Он не зависит от объема заученных данных, а проявляется в способности к анализу, обобщению и решению проблем в условиях неопределенности.
Оценка больших языковых моделей (LLM) проводится с использованием двух основных типов задач: задач из распределения (Within-Distribution Tasks) и задач вне распределения (Out-of-Distribution Tasks). Задачи из распределения, представляющие собой данные, аналогичные тем, на которых обучалась модель, позволяют оценить её кристаллизованный интеллект — способность применять заученные знания. Задачи вне распределения, требующие решения новых, ранее не встречавшихся проблем, позволяют оценить жидкий интеллект — способность к обобщению и адаптации. Комбинирование этих двух типов оценок обеспечивает более полное и нюансированное понимание возможностей LLM, выявляя как её сильные стороны в применении существующих знаний, так и ограничения в решении новых задач.
Объективное Оценивание: Бенчмаркинг LLM в Шахматах
Для объективной оценки производительности больших языковых моделей (LLM) в шахматах, мы используем комплексный подход, включающий в себя проверенные методы. В частности, для генерации реалистичных шахматных позиций используется база данных Lichess Masters, содержащая партии высококвалифицированных игроков. Этот источник позволяет создавать позиции, отражающие типичные ситуации, возникающие в реальных шахматных партиях, что обеспечивает более точную и релевантную оценку стратегии и тактических способностей LLM по сравнению с использованием синтетических или упрощенных позиций. Использование базы данных Lichess Masters обеспечивает разнообразие позиций и позволяет тестировать LLM в различных фазах игры.
Качество ходов оценивается с использованием метрики Centipawn Loss (CPL), представляющей собой числовое значение, отражающее позиционный проигрыш, возникающий с каждым сделанным ходом. CPL измеряется в сотых долях пешки ( \frac{1}{100} пешки), что позволяет количественно оценить стратегические решения. Более низкое значение CPL указывает на более качественный ход, поскольку он приводит к меньшему позиционному ухудшению. Таким образом, CPL служит объективным показателем эффективности шахматных ходов и позволяет сравнивать стратегическое мастерство различных игроков или алгоритмов.
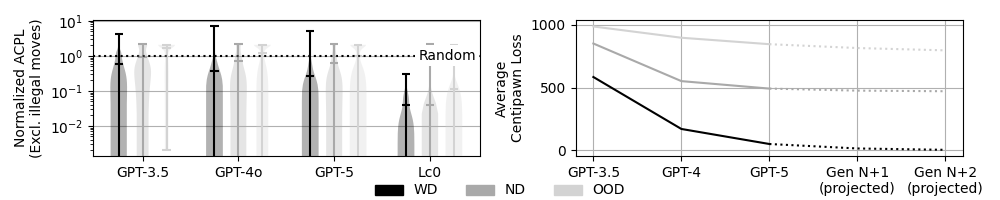
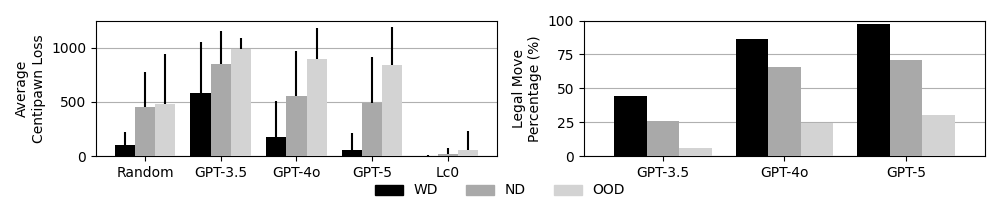
В качестве эталона для сравнения используется шахматный движок Stockfish, обеспечивающий объективную оценку производительности больших языковых моделей (LLM). В ходе тестирования, модель GPT-5 достигла среднего показателя потерь в центопешках (ACPL) равного 463.54, что демонстрирует снижение на 16.6% по сравнению с показателем GPT-4. Показатель ACPL отражает позиционный недостаток, возникающий при каждом ходе, и позволяет количественно оценить стратегические решения LLM относительно оптимальной игры, определяемой Stockfish.
В ходе тестирования моделей больших языковых моделей (LLM) было установлено, что GPT-5 демонстрирует значительно более низкий процент незаконных ходов — всего 0.73%. Для сравнения, у GPT-3.5 этот показатель составлял 25.3%, а у GPT-4 — 58.4%. Данный результат указывает на существенное улучшение способности GPT-5 генерировать корректные с точки зрения правил шахмат ходы, что является критически важным аспектом для оценки её шахматной компетентности и общей надёжности.
Эволюция Рассуждений: От GPT-3.5 к GPT-5
Последовательные поколения больших языковых моделей, от GPT-3.5 до GPT-5, демонстрируют постепенное повышение эффективности в шахматной игре. Этот прогресс указывает на развитие способности к стратегическому мышлению и планированию. Улучшение результатов в шахматах, сложной области, требующей предвидения и оценки последствий, служит косвенным подтверждением того, что модели становятся более компетентными в решении задач, требующих абстрактного мышления и логического вывода. Наблюдаемый рост производительности не является случайным, а отражает усовершенствование архитектуры моделей и методов обучения, позволяющих им лучше понимать и анализировать сложные игровые ситуации, а также формировать более эффективные стратегии для достижения победы.
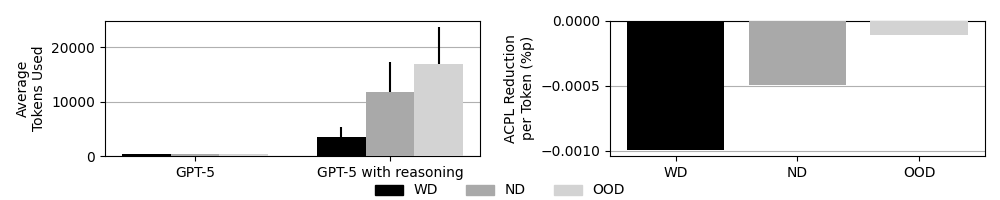
Ключевым нововведением, способствующим прогрессу в области больших языковых моделей, является методика «Цепочка рассуждений» (Chain-of-Thought Reasoning). Данный подход стимулирует модели не просто выдавать ответ, а явно проговаривать последовательность шагов, приводящих к решению. Это позволяет не только повысить связность и логичность получаемых результатов, но и значительно улучшить их точность. По сути, модель начинает имитировать процесс человеческого мышления, раскрывая ход своих умозаключений, что делает её решения более прозрачными и обоснованными. В результате, наблюдается значительное повышение эффективности в решении сложных задач, требующих многоступенчатого анализа и логических выводов.
Анализ шахматных партий показал значительный прогресс в стратегическом мышлении больших языковых моделей (LLM) от GPT-3.5 до GPT-4. В частности, показатель ACPL (Average Centipawn Loss — средняя потеря пешек) улучшился на 70.7% в стандартных, хорошо изученных шахматных позициях (within-distribution positions). Данное увеличение демонстрирует укрепление “кристаллизованного интеллекта” модели — способности эффективно применять накопленные знания и опыт для решения знакомых задач. Улучшение ACPL свидетельствует о том, что GPT-4 значительно точнее оценивает позиции и принимает более обоснованные решения в ситуациях, которые уже встречались в процессе обучения, подтверждая способность модели к глубокому анализу и эффективному использованию шахматной теории.
Исследования показали, что, несмотря на значительный прогресс в шахматных задачах, прирост способности к логическому мышлению, измеряемый изменением ACPL (Average Centipawn Loss) на каждый токен, существенно снизился при решении нестандартных задач — до 1.13 \times 10^{-4}. Это указывает на то, что современные языковые модели демонстрируют всё более скромные улучшения в способности к адаптации и решению новых, незнакомых проблем, что свидетельствует об ограничениях в развитии так называемой «жидкой» (fluid) интеллектуальной способности — умения мыслить гибко и находить решения вне рамок заученных шаблонов. В то время как «кристаллическая» (crystallized) интеллектуальная способность, основанная на накопленных знаниях, продолжает совершенствоваться, способность к инновационному мышлению в новых ситуациях демонстрирует тенденцию к насыщению.
Исследование демонстрирует, что большие языковые модели, подобно искусному шахматисту, превосходно воспроизводят заученные паттерны, но испытывают трудности при столкновении с принципиально новыми ситуациями. Этот феномен перекликается с разделением интеллекта на «кристаллизованный» и «жидкий». В данном контексте, модели демонстрируют высокий уровень «кристаллизованного» интеллекта, эффективно оперируя накопленными знаниями о шахматных позициях. Однако, их способность к «жидкому» интеллекту, то есть к решению задач, требующих адаптации и нестандартного мышления, остается ограниченной. Как однажды заметил Марвин Минский: «Искусственный интеллект — это не создание машин, которые думают как люди, а создание машин, которые думают». Данное исследование подтверждает, что путь к настоящему искусственному интеллекту лежит через преодоление ограничений в области обобщения и адаптации, а не просто через накопление знаний.
Куда двигаться дальше?
Представленное исследование, используя шахматы как лакмусовую бумажку, выявило закономерность, не столь удивительную для тех, кто смотрит на эти системы с математической строгостью. Модели демонстрируют впечатляющую способность к воспроизведению заученного — накопленное знание, или, как принято говорить, «кристаллизованный интеллект», проявляется в умении распознавать и применять известные паттерны. Однако, столкнувшись с необходимостью генерировать принципиально новые решения, с ситуациями, требующими истинного «жидкого интеллекта», их возможности оказываются ограничены. И это не ошибка реализации, а фундаментальное ограничение текущей архитектуры.
Перспективы дальнейших исследований лежат не в увеличении объема обучающих данных, а в разработке алгоритмов, способных к формальному выводу, к построению доказательств. Необходимо сместить акцент с «обучения» в сторону «вывода». Следующим шагом видится создание моделей, способных оперировать не просто с вероятностями, а с логическими утверждениями, способных проверять корректность своих решений, а не просто «угадывать» правильный ответ. Иначе говоря, необходимо построить системы, которые не просто «играют в шахматы», а понимают принципы игры.
В конечном счете, истинный прогресс заключается в создании искусственного интеллекта, который не просто имитирует разум, а обладает им — в смысле математической доказуемости и непротиворечивости. И тогда эти модели перестанут быть просто сложными статистическими инструментами и станут по-настоящему интеллектуальными системами.
Оригинал статьи: https://arxiv.org/pdf/2601.16823.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-27 05:42