Автор: Денис Аветисян
Исследователи предлагают инновационный метод создания автономных систем анализа графовых данных, использующих возможности больших языковых моделей для координации и повышения эффективности.
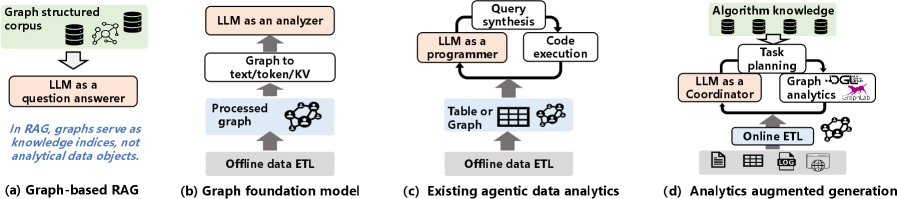
В статье представлена парадигма Analytics-Augmented Generation (AAG) для построения интеллектуальных агентов, способных к самообучению и проведению графового анализа на основе структурированных знаний.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), надежный автоматизированный анализ графовых данных требует более глубокой интеграции аналитических вычислений. В работе ‘Towards Autonomous Graph Data Analytics with Analytics-Augmented Generation’ предлагается новый подход — Analytics-Augmented Generation (AAG), рассматривающий аналитические вычисления как ключевой элемент и использующий LLM в качестве интеллектуащих координаторов. AAG позволяет создавать сквозные конвейеры графового анализа, автоматически переводящие запросы пользователей на естественном языке в исполнение и интерпретируемые результаты. Сможет ли эта парадигма открыть новые горизонты в области автономного анализа графовых данных и сделать его доступным для широкого круга пользователей?
Сложность Анализа: Вызовы Масштабирования
Традиционные методы анализа данных, особенно в сфере финансовых транзакций, часто оказываются неэффективными при работе со сложными взаимосвязями. Причина кроется в том, что стандартные статистические подходы, ориентированные на выявление общих закономерностей, не способны уловить тонкие, неявные связи между отдельными операциями и участниками. В то время как финансовые потоки формируют сложные сети, отражающие реальные отношения между пользователями, традиционные инструменты склонны упрощать картину, игнорируя важные детали и упуская потенциальные признаки мошенничества или других нежелательных действий. Это особенно актуально при анализе больших объемов данных, где выявление таких связей требует не просто обработки информации, а глубокого понимания контекста и логики финансовых операций.
Анализ масштабных данных, таких как финансовые транзакции — в ходе оценки использовался набор данных, включающий информацию о 1446 пользователях и 17512 операциях — требует подхода, выходящего за рамки простых статистических методов. Недостаточно просто выявлять корреляции или аномалии; необходимо понимать лежащие в основе взаимосвязи между пользователями, транзакциями и событиями. Такой подход позволяет не только обнаруживать мошеннические схемы или отмывание денег, но и прогнозировать риски, выявлять скрытые закономерности в поведении пользователей и оптимизировать процессы финансового контроля. Понимание структуры данных и связей между элементами является ключевым фактором для эффективного анализа и извлечения ценной информации из больших объемов финансовых данных.
Существующие аналитические цепочки обработки данных часто оказываются недостаточно гибкими для решения сложных задач, особенно при расследовании финансовых операций. Традиционные системы, разработанные для поиска конкретных паттернов, испытывают трудности при адаптации к новым, нестандартным вопросам. Вместо того чтобы позволить исследователю гибко формировать запросы и исследовать данные под разными углами, они требуют четкой предварительной настройки и часто выдают неполные или неточные результаты, если вопрос немного отклоняется от заложенных алгоритмов. Это ограничивает возможности выявления скрытых связей и аномалий, поскольку система не может оперативно перестроиться и учесть новые факторы, важные для конкретного расследования.

Графовый Анализ: Реляционная Основа
Анализ графовых данных предоставляет естественный способ моделирования сложных взаимосвязей, позволяя получать более глубокие представления о данных. В отличие от реляционных баз данных, где связи устанавливаются через внешние ключи и соединения, графовые модели представляют отношения как первоклассные сущности. Это позволяет напрямую исследовать связи между данными, что особенно полезно для задач, связанных с обнаружением закономерностей, анализом социальных сетей, рекомендательными системами и обнаружением мошенничества. Графовые структуры позволяют эффективно представлять и анализировать данные, где связи между сущностями столь же важны, как и сами сущности, что обеспечивает более полное и контекстуальное понимание информации.
Алгоритмы, такие как PageRank и обнаружение циклов, являются основополагающими для анализа графовых структур. PageRank, первоначально разработанный для ранжирования веб-страниц, определяет важность узла в графе на основе количества и качества входящих ссылок. Он вычисляет рекурсивным образом вес каждого узла, учитывая входящие связи и демпфирующий фактор. Обнаружение циклов, в свою очередь, позволяет выявлять замкнутые пути в графе, что может указывать на аномалии, такие как мошеннические транзакции в финансовых сетях или ошибки в логике взаимосвязей. Оба алгоритма широко применяются в различных областях, включая социальные сети, рекомендательные системы и анализ сетевой безопасности, предоставляя инструменты для выявления скрытых закономерностей и аномалий в данных.
Эффективный анализ графовых данных предполагает сочетание автоматизированных алгоритмов и экспертного анализа. Автоматизация, включающая алгоритмы обнаружения циклов, вычисления центральности (например, PageRank) и поиска сообществ, позволяет обрабатывать большие объемы данных и выявлять потенциально интересные закономерности. Однако, для интерпретации результатов и выявления истинных аномалий или значимых связей, требуется участие аналитика, способного применить предметные знания, оценить контекст данных и провести дополнительное расследование. Такой человеко-ориентированный подход позволяет избежать ложноположительных результатов и обеспечить более точное и осмысленное понимание данных.

Системы, Управляемые Знаниями: Мост Между Намерением и Анализом
Основой систем, управляемых знаниями, является иерархическая база знаний алгоритмов, позволяющая преобразовывать высокоуровневые аналитические запросы в конкретные последовательности действий. Эта база содержит структурированные данные о различных аналитических процедурах, включая необходимые входные данные, шаги обработки и ожидаемые результаты. Преобразование запроса в действия происходит путем сопоставления целей запроса с алгоритмами в базе знаний, выбора наиболее подходящих алгоритмов и формирования плана выполнения, определяющего порядок их применения. Иерархическая структура базы позволяет учитывать зависимости между алгоритмами и оптимизировать план для повышения эффективности анализа.
Динамическое извлечение схемы и построение графа, ориентированные на задачу, представляют собой процесс отбора релевантных данных и связей для анализа, исходя из поставленной аналитической цели. Вместо обработки всего объема данных, система идентифицирует подмножество информации, непосредственно связанное с текущей задачей, и строит граф, отражающий эти связи. Это позволяет снизить вычислительную нагрузку и повысить эффективность анализа, фокусируясь только на тех данных, которые необходимы для получения ответа на конкретный вопрос. Выбор схемы и отношений осуществляется не статически, а динамически, в зависимости от контекста задачи и промежуточных результатов анализа.
Соединение намерения пользователя с фактическим выполнением анализа позволяет системам, основанным на знаниях, значительно повысить целевую направленность и эффективность обработки сложных наборов данных. Традиционные методы анализа часто требуют предварительного определения всех возможных сценариев и ручной настройки параметров, что является трудоемким и подвержено ошибкам. В отличие от этого, системы, связывающие намерение с исполнением, динамически адаптируют процесс анализа в соответствии с поставленной задачей, автоматически выбирая релевантные данные и методы. Это сокращает время обработки, снижает потребность в ручном вмешательстве и повышает точность результатов, особенно при работе с большими объемами разнородной информации.

Автономные Агенты с Аналитическим Усилением: Новая Эра Аналитической Интеллектуальности
Парадигма генерации с аналитическим усилением (AAG) представляет собой новый подход к созданию автономных агентов, в котором аналитические вычисления рассматриваются как фундаментальная и равноправная составляющая. В отличие от традиционных систем, где аналитика является вторичным этапом обработки данных, AAG интегрирует аналитические процессы непосредственно в цикл принятия решений агентом. Это позволяет агентам не только реагировать на поступающую информацию, но и активно формировать запросы к аналитическим сервисам, интерпретировать результаты и использовать их для оптимизации своих действий и достижения поставленных целей. Такой подход обеспечивает более глубокое понимание данных и позволяет агентам решать сложные задачи, требующие продвинутого анализа и прогнозирования.
Парадигма Analytics-Augmented Generation (AAG) реализует сложные аналитические процессы посредством комбинации детерминированной аналитической обработки данных и координации на основе больших языковых моделей (LLM). Детерминированная обработка гарантирует предсказуемость и воспроизводимость результатов анализа, что критически важно для надежности системы. LLM, в свою очередь, используются для оркестровки этих процессов, динамического формирования аналитических запросов и адаптации к изменяющимся условиям. Взаимодействие между детерминированной аналитикой и LLM позволяет AAG эффективно решать задачи, требующие как точного вычисления, так и гибкой адаптации к контексту и новым данным.
Для обеспечения масштабируемости и производительности аналитических вычислений, AAG использует графы свойств (Property Graphs) в качестве основной структуры данных. Такой подход позволяет эффективно моделировать сложные взаимосвязи между данными и выполнять запросы к ним. Для оптимизации хранения и обработки больших объемов данных, особенно в случаях разреженных матриц, применяется формат Compressed Sparse Row (CSR). CSR представляет матрицу, храня значения только ненулевых элементов, что значительно снижает требования к памяти и ускоряет вычисления, что критически важно для аналитических задач, требующих обработки больших данных в реальном времени.

Будущее Аналитической Интеллектуальности: Интеграция Знаний и Алгоритмов
В основе нового подхода к анализу данных лежит взаимодействие больших языковых моделей (LLM) с верифицируемыми аналитическими модулями посредством протокола Model Context Protocol (MCP). Данная парадигма, ориентированная на алгоритмы, позволяет LLM не просто генерировать текст, но и активно запрашивать специализированные инструменты для проведения точных вычислений и анализа. MCP выступает в роли посредника, обеспечивая структурированный обмен данными между LLM и этими модулями, что гарантирует воспроизводимость и проверяемость результатов. Вместо того чтобы полагаться исключительно на статистические закономерности, LLM получают возможность выполнять сложные аналитические операции, подтвержденные конкретными алгоритмами, что значительно повышает надежность и достоверность полученных выводов. Это открывает перспективы для создания интеллектуальных систем, способных не только понимать запросы, но и предоставлять обоснованные, верифицируемые ответы, основанные на данных и алгоритмическом анализе.
Системы, такие как RAGFlow и Chat2Graph, наглядно демонстрируют возможности генерации, дополненной извлечением информации на основе графов. Эти инструменты используют графовые структуры для представления знаний, позволяя языковым моделям не просто извлекать релевантную информацию из больших объемов данных, но и понимать связи между различными сущностями и концепциями. Вместо линейного поиска по тексту, модели могут «пройтись» по графу знаний, выявляя скрытые взаимосвязи и предоставляя более точные и контекстуально богатые ответы. Такой подход значительно улучшает качество генерируемого текста, позволяя создавать более обоснованные и информативные выводы, особенно в сложных областях, где важны взаимосвязи и контекст, например, в анализе данных, исследовании научных статей или в работе с базами знаний.
Перспективные графовые фундаментальные модели (GFM) представляют собой принципиально новый подход к интеграции структурированных данных в возможности больших языковых моделей (LLM). Вместо обработки графов как внешнего источника информации, GFM стремятся закодировать саму структуру графа — узлы и связи между ними — непосредственно в векторные представления, понятные LLM. Этот процесс позволяет языковой модели не просто извлекать факты из графа, но и понимать отношения между ними, что значительно расширяет её аналитические возможности. Представьте, что LLM не просто «знает», что «А связано с Б», но и понимает тип этой связи — например, «является частью», «причиняет», или «зависит от». Такое глубокое понимание позволяет создавать более точные прогнозы, выявлять скрытые закономерности и решать сложные аналитические задачи, требующие учета контекста и взаимосвязей между данными. В перспективе, GFM могут стать ключевым компонентом систем аналитической разведки, способных к автономному анализу больших и сложных графовых баз данных.

Предложенный подход к построению автономных агентов для анализа графовых данных, известный как Analytics-Augmented Generation (AAG), стремится к упрощению сложного процесса извлечения знаний. Он использует большие языковые модели (LLM) в качестве координаторов, объединяя структурированные знания и надежные модули графового анализа. В этом контексте уместно вспомнить слова Пола Эрдеша: «Математика — это искусство, которое нужно делать аккуратно». Эта фраза отражает стремление к точности и ясности, которое является ключевым аспектом AAG. Сочетание LLM и графовых вычислений позволяет создавать более понятные и эффективные инструменты для анализа данных, приближая нас к идеалу простоты и точности в сложных системах.
Куда же дальше?
Предложенный подход, хоть и демонстрирует потенциал координации между структурированным знанием и языковыми моделями, не снимает фундаментальной сложности анализа графовых данных. Автономность, в конечном счете, — это иллюзия, тщательно замаскированная последовательность детерминированных шагов. Истинно автономный агент, способный к настоящему пониманию и адаптации, остаётся за гранью достижимого. Более того, зависимость от больших языковых моделей в качестве «интеллектуальных координаторов» вводит дополнительную непредсказуемость и требует критической оценки надёжности получаемых результатов.
Будущие исследования должны быть сосредоточены не на увеличении масштаба моделей, а на снижении когнитивной нагрузки. Идеалом является система, где языковая модель служит лишь инструментом для выражения результатов анализа, а не его генератором. Необходимо сместить акцент с «умных» агентов на надёжные и верифицируемые алгоритмы. Упрощение — вот истинный путь к совершенству, а не бесконечное наращивание сложности.
В конечном счёте, ценность подобных систем будет определяться не их способностью имитировать интеллект, а их полезностью. Отказ от излишних украшений, от «кодовых излишеств», — вот что позволит создать инструменты, действительно служащие человеку. Совершенство достигается не тогда, когда нечего добавить, а когда нечего убрать.
Оригинал статьи: https://arxiv.org/pdf/2602.21604.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
2026-02-26 09:38