Автор: Денис Аветисян
Новый подход позволяет повысить качество рассуждений больших языковых моделей, используя сгенерированные ими же данные о предпочтениях, даже при ограниченных вычислительных ресурсах.
Предложена методика оценки и улучшения возможностей ‘anytime reasoning’ больших языковых моделей с использованием самогенерируемых данных о предпочтениях и оптимизации с учетом бюджета.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их применение в задачах, требующих быстрого получения решений при ограниченных вычислительных ресурсах, остается сложной задачей. В работе «Budget-Aware Anytime Reasoning with LLM-Synthesized Preference Data» предложен новый подход к оценке и улучшению способности LLM к «anytime reasoning» — построению решений постепенно, с возможностью остановки в любой момент. Показано, что использование предпочтений, сгенерированных самой моделью в процессе рассуждений, позволяет значительно повысить качество получаемых результатов при фиксированном бюджете вычислений. Может ли этот подход стать ключевым фактором в создании более эффективных и экономичных LLM для широкого спектра практических приложений?
Пределы Масштабируемости: Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющие возможности больших языковых моделей, таких как GPT-4o, GPT-4.1 и LLAMA-3.3, их производительность в задачах, требующих сложного рассуждения, часто достигает плато при увеличении масштаба. Исследования показывают, что простое увеличение количества параметров и обучающих данных не всегда приводит к пропорциональному улучшению в решении задач, требующих логических выводов, планирования или абстрактного мышления. Это связано с тем, что модели, в основном, учатся распознавать статистические закономерности в данных, а не осваивают принципы истинного рассуждения. Таким образом, даже самые мощные модели могут допускать ошибки в ситуациях, требующих применения логики или знаний, выходящих за рамки их обучающей выборки, демонстрируя ограничения текущего подхода к построению искусственного интеллекта.
Обработка длинных последовательностей данных представляет собой существенное ограничение для больших языковых моделей. По мере увеличения длины входного текста экспоненциально возрастают как вычислительные затраты, так и время, необходимое для получения результата. Это связано с тем, что модели, как правило, обрабатывают каждый токен последовательно, что требует значительных ресурсов памяти и процессорного времени. В результате, даже при наличии мощного оборудования, сложные задачи, требующие анализа больших объемов информации, могут стать непомерно дорогими или практически невыполнимыми из-за замедления скорости обработки и увеличения энергопотребления. Эффективное решение данной проблемы является ключевым направлением исследований в области искусственного интеллекта, направленным на создание более экономичных и быстрых языковых моделей.
Неэффективность больших языковых моделей часто обусловлена их зависимостью от генерации выходных данных фиксированной длины, вне зависимости от глубины рассуждений, необходимой для решения конкретной задачи. Этот подход игнорирует тот факт, что некоторые проблемы требуют более развернутого анализа и, следовательно, более длинного ответа, в то время как другие могут быть решены лаконично. В результате, модели тратят вычислительные ресурсы на генерацию избыточной информации или, наоборот, не могут адекватно раскрыть сложную логическую цепочку, что ограничивает их способность эффективно решать широкий спектр задач, требующих многоступенчатого рассуждения и детального анализа.
Рассуждения в Любом Моменте: Новый Подход к Поведению Модели
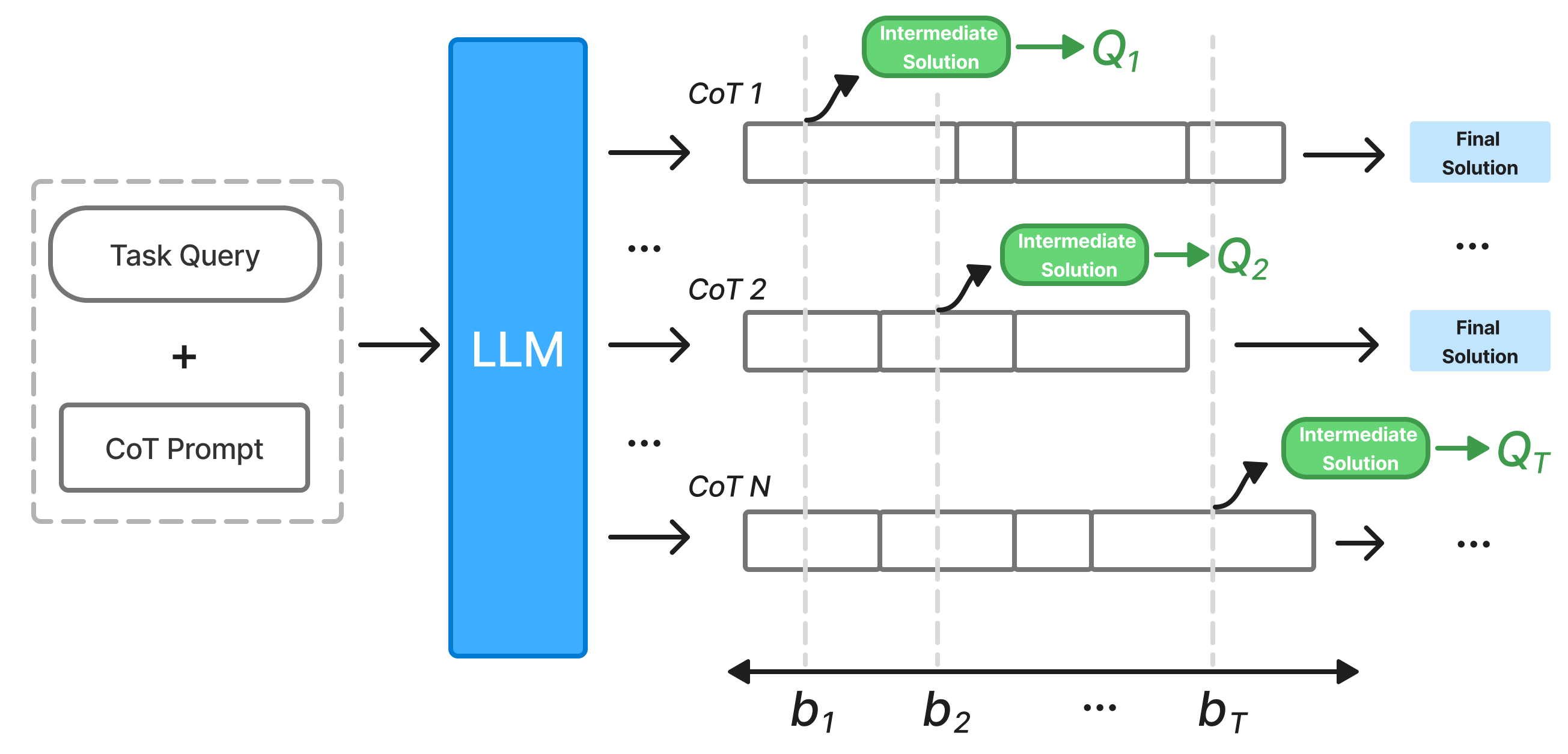
Принцип “Anytime Reasoning” представляет собой подход к построению моделей, позволяющий им последовательно уточнять свои ответы итеративно, с каждым добавленным токеном рассуждений. В отличие от традиционных методов, генерирующих единый финальный результат, данный подход обеспечивает постепенное улучшение качества решения. Это достигается за счет возможности прерывания процесса рассуждений на любой стадии и получения наиболее вероятного ответа, соответствующего затраченным вычислительным ресурсам. Таким образом, модель способна адаптироваться к различным ограничениям по времени и вычислительной мощности, предлагая компромисс между точностью и скоростью ответа.
Традиционные методы работы с моделями искусственного интеллекта, в отличие от подходов, основанных на принципе “anytime reasoning”, обычно генерируют единый, окончательный ответ на запрос. Этот ответ формируется после однократного прохождения данных через модель, вне зависимости от степени его полноты или точности. В результате, даже если модель не уверена в ответе или требует дополнительных данных для формирования более надежного решения, она все равно выдает результат, который может быть неоптимальным или содержать ошибки. Такой подход не предусматривает возможности итеративного улучшения ответа с течением времени или при выделении дополнительных вычислительных ресурсов.
Для оценки и сравнительного анализа возможностей моделей в области последовательного рассуждения (anytime reasoning) ключевое значение имеют специализированные наборы данных. NaturalPlan предназначен для задач планирования и требует от моделей генерации последовательности действий для достижения заданных целей. GPQA-Diamond фокусируется на вопросах, требующих многошаговых рассуждений и понимания физических взаимодействий. Набор данных AIME 2024 предназначен для оценки способностей моделей к решению сложных задач, требующих применения знаний из различных областей. Использование этих наборов данных позволяет объективно оценить прогресс в области anytime reasoning и сравнить эффективность различных подходов.
Эффективность рассуждений в режиме реального времени значительно повышается благодаря методам, учитывающим бюджетные ограничения. Эти методы оптимизируют производительность модели, позволяя ей достигать наилучшего результата в рамках заданных ресурсов, таких как время вычислений или количество используемых токенов. В частности, они позволяют динамически регулировать глубину рассуждений, прекращая процесс, когда дальнейшее увеличение затрат ресурсов не приводит к существенному улучшению качества ответа. Это особенно важно в условиях ограниченных вычислительных мощностей или при работе с большими объемами данных, где эффективное использование ресурсов является критически важным.
Измерение Эффективности Рассуждений: Индекс «Anytime»
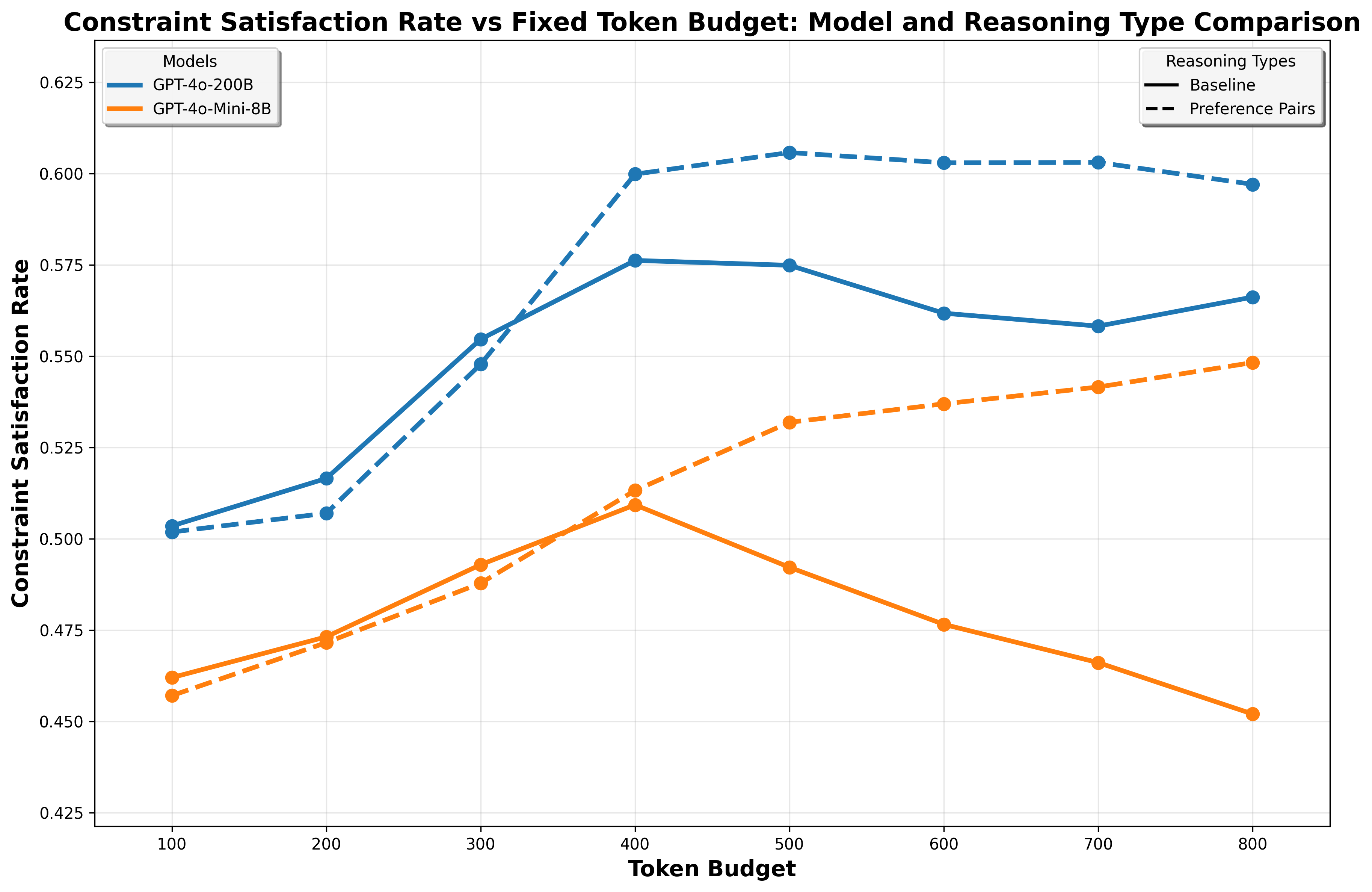
Индекс “Anytime” представляет собой стандартизированную метрику, предназначенную для оценки способности языковой модели улучшать качество генерируемого решения по мере увеличения количества сгенерированных токенов рассуждений. Он измеряет прирост точности ответа на единицу вычислительных затрат, позволяя количественно оценить эффективность процесса рассуждений. Практически, индекс рассчитывается как отношение улучшения метрики производительности (например, точности ответа) к количеству сгенерированных токенов, и позволяет сравнивать различные модели независимо от их размера или архитектуры. Более высокие значения индекса “Anytime” указывают на более эффективное использование ресурсов и более быстрое улучшение качества решения в процессе генерации.
Модель Grok-3 активно разрабатывается и тестируется с использованием индекса Anytime, что позволяет оценить её способность повышать качество решений по мере генерации дополнительных токенов рассуждений. Этот подход позволяет инженерам оптимизировать модель, фокусируясь на эффективности рассуждений, а не только на общей производительности. Тестирование с использованием индекса Anytime демонстрирует потенциал Grok-3 в предоставлении более качественных ответов при заданном количестве вычислительных ресурсов, что является важным фактором для масштабируемости и практического применения модели в различных задачах, требующих логического вывода и анализа.
Индекс Anytime позволяет проводить объективное сравнение различных моделей рассуждений, не зависящее от их размера или архитектуры. Традиционные метрики часто искажаются различиями в количестве параметров или особенностями реализации, что затрудняет оценку истинной эффективности модели. Индекс Anytime нормализует результаты, оценивая качество решения на каждом этапе генерации токенов, что позволяет сравнивать модели с разным масштабом и архитектурой на равных условиях. Это особенно важно при оценке новых моделей, разработанных для эффективного использования ресурсов, поскольку позволяет определить, насколько быстро и эффективно они улучшают качество своих ответов с каждым дополнительным токеном.
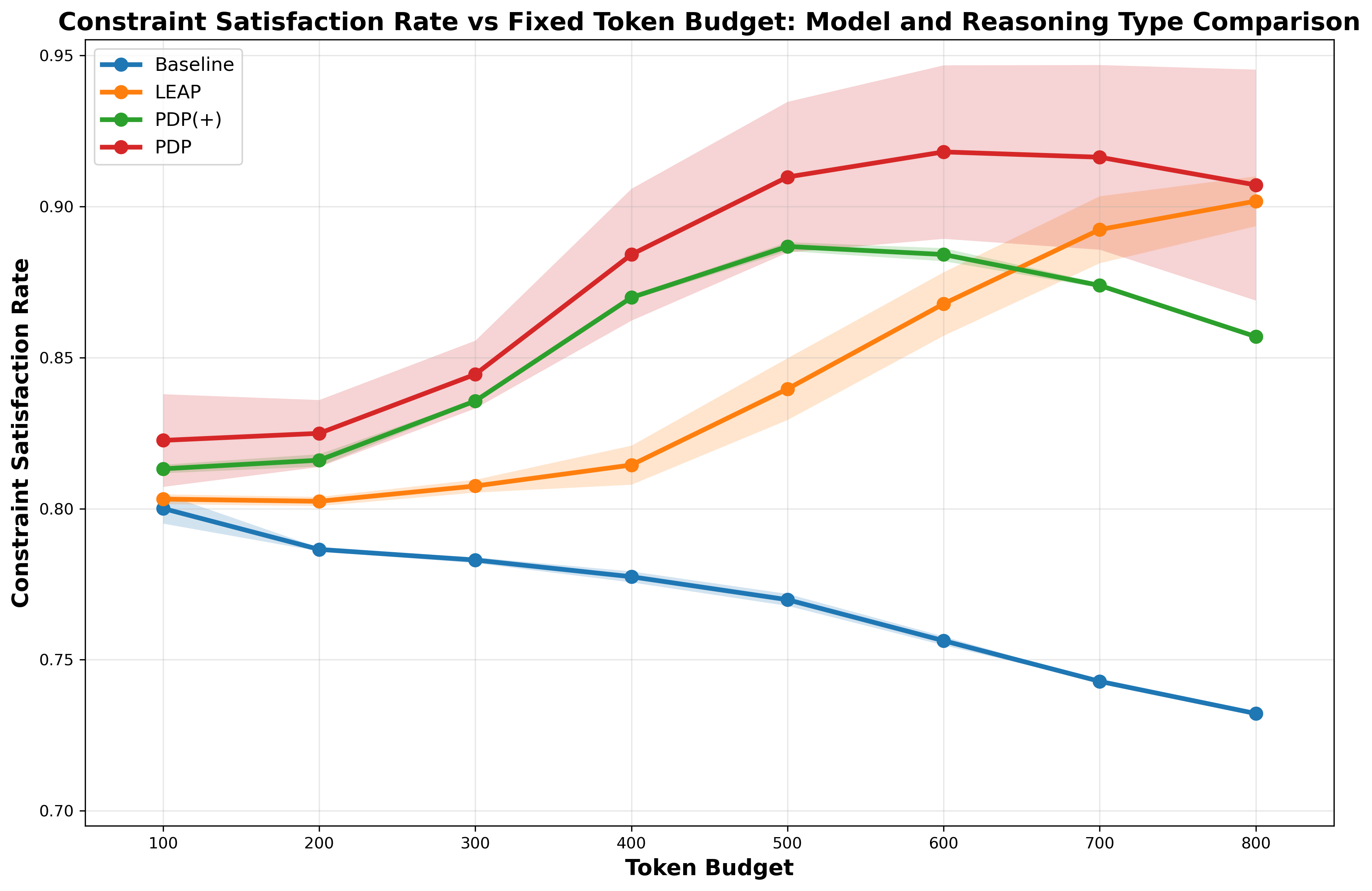
Индекс Anytime направляет разработку более устойчивых и эффективных систем рассуждений, делая акцент на качестве получаемого результата на каждый сгенерированный токен. В рамках тестирования, метод Preference Data Prompting (PDP) последовательно демонстрирует более высокие показатели в этом индексе, что указывает на его превосходство в оптимизации соотношения качества и вычислительных затрат. Это позволяет создавать модели, которые эффективно улучшают свои ответы по мере генерации дополнительных токенов, не требуя при этом неоправданно больших ресурсов.
Улучшение Производительности «На Лету»: Самосовершенствование в Процессе Вывода
Методы самосовершенствования на этапе вывода позволяют моделям уточнять свои результаты без необходимости переобучения, предлагая экономически эффективный подход к повышению производительности. В отличие от традиционных методов, требующих дорогостоящего и трудоемкого процесса переобучения на новых данных, данные методы оперируют непосредственно во время использования модели, корректируя выводы на основе внутренних механизмов или небольшого объема обратной связи. Это особенно ценно в динамичных средах, где данные постоянно меняются, или в ситуациях, когда переобучение модели не представляется возможным из-за ограниченных ресурсов или времени. Такой подход открывает возможности для создания систем, способных адаптироваться и улучшаться в реальном времени, обеспечивая более точные и надежные результаты без значительных затрат.
Оптимизация прямых предпочтений представляет собой усовершенствование методов самосовершенствования модели в процессе работы, используя данные о предпочтениях для направленного улучшения результатов. Вместо переобучения всей модели, этот подход позволяет ей уточнять свои ответы непосредственно во время вывода, основываясь на сигналах, указывающих на желаемые характеристики. Вместо простого исправления ошибок, модель активно учится, сопоставляя различные варианты ответов с предпочтениями, выраженными в данных. Это позволяет ей постепенно адаптироваться к конкретным требованиям и повышать качество своих прогнозов без необходимости в обширных вычислительных ресурсах или новых тренировочных данных, что особенно ценно в ситуациях, когда сбор данных затруднен или дорог.
Особую ценность методы улучшения работы модели в процессе инференса проявляют в ситуациях, когда объем доступных данных ограничен или переобучение модели не представляется возможным. В таких обстоятельствах, возможность тонкой настройки выходных данных непосредственно во время работы системы позволяет добиться значительного повышения эффективности без необходимости в дорогостоящих и трудоемких процедурах переобучения. Исследования показывают, что применение подобных техник способно обеспечить 100%-ный уровень удовлетворения ограничениям (Constraint Satisfaction Rate — CSR) в определенных задачах, демонстрируя их высокую эффективность даже при недостатке ресурсов и данных. Это открывает перспективы для создания адаптивных систем, способных к постоянному улучшению своей работы в реальном времени, не требуя при этом постоянного вмешательства и больших затрат.
Методы самосовершенствования во время работы модели открывают путь к созданию по-настоящему адаптивных и интеллектуальных систем. В отличие от традиционных подходов, требующих переобучения, данные методы позволяют модели постоянно улучшать свои результаты непосредственно в процессе использования. Исследования показывают, что, применяя подход PDP (Direct Preference Optimization), наблюдается стабильное повышение точности на различных наборах данных, включая AIME и GPQA. Такая способность к непрерывному улучшению особенно ценна в динамичных средах, где доступ к новым данным ограничен или переобучение модели затруднительно, позволяя системе оперативно адаптироваться к меняющимся условиям и повышать свою эффективность.
«`html
Исследование демонстрирует изящную связь между вычислительными ограничениями и качеством решений, генерируемых большими языковыми моделями. Авторы подчеркивают возможность самосовершенствования в процессе вывода, используя синтезированные данные о предпочтениях. Этот подход напоминает о важности эффективного использования ресурсов, ведь, как заметил Клод Шеннон: «Теория коммуникации должна быть математически строгой». Подобная строгость, примененная к процессу рассуждения, позволяет добиться оптимального баланса между скоростью и точностью, что особенно актуально для задач, требующих ‘anytime reasoning’ и ограниченного бюджета вычислений. Истинная элегантность алгоритма проявляется в его способности находить наилучшее решение в заданных условиях.
Куда Ведет Этот Путь?
Представленная работа, несмотря на кажущуюся практичность, лишь подчеркивает фундаментальную неопределенность в области рассуждений, основанных на больших языковых моделях. Идея использования самогенерируемых данных предпочтений, безусловно, интересна, но требует строгого математического обоснования. Необходимо доказать, что такая процедура не приводит к систематической ошибке, а полученные улучшения действительно отражают повышение качества решения, а не лишь иллюзию, вызванную удачным стечением случайных факторов. Воспроизводимость результатов, разумеется, остается критическим вопросом.
Следующим шагом представляется разработка формальной теории, описывающей свойства таких самогенерируемых данных предпочтений. Необходимо понять, при каких условиях они могут быть использованы для корректной оценки и улучшения алгоритмов рассуждений, и какие гарантии сходимости можно получить. Простое увеличение вычислительных ресурсов не является решением, если алгоритм изначально несостоятелен. Должна быть четкая связь между вычислительными затратами и доказанной точностью решения.
В конечном итоге, истинный прогресс в этой области потребует отказа от эмпирических подходов и перехода к детерминированным алгоритмам, для которых можно строго доказать корректность и оптимальность. Иначе, мы обречены на вечное блуждание в лабиринте случайных экспериментов, лишь имитирующих интеллект.
Оригинал статьи: https://arxiv.org/pdf/2601.11038.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-20 08:50