Автор: Денис Аветисян
Исследователи предлагают инновационную систему для выявления поддельных видео, основанную на генерации данных методом цепочки рассуждений и применении обучения с подкреплением.
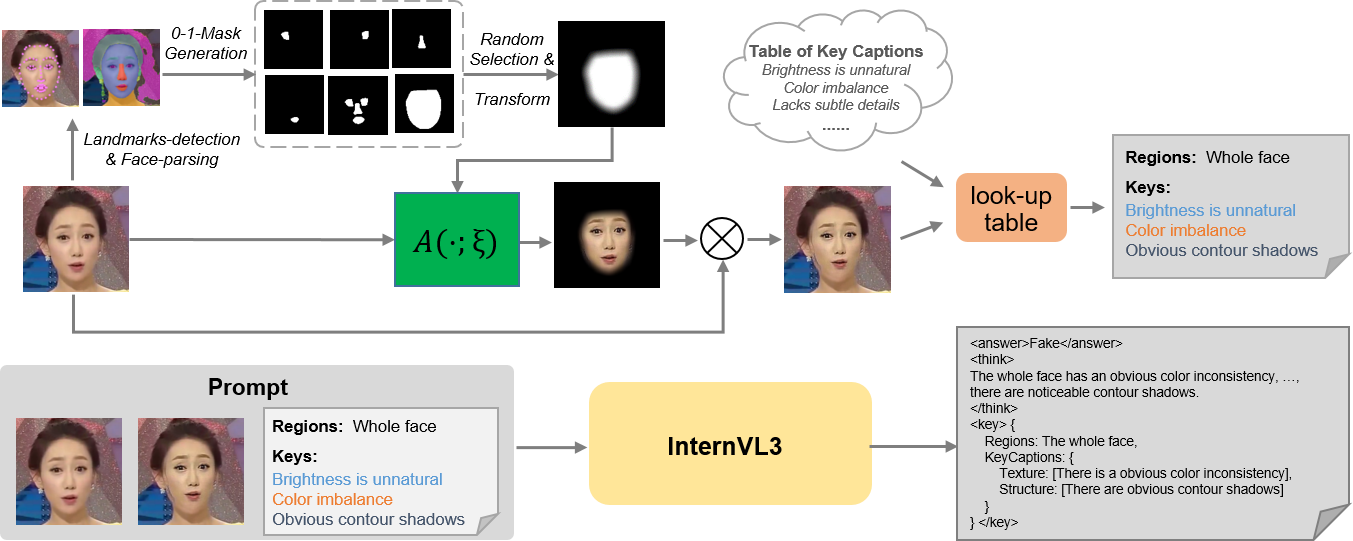
Предложенная методика использует смешивание изображений и алгоритм GRPO для автоматической генерации данных CoT, повышая точность и обобщающую способность моделей обнаружения дипфейков.
Несмотря на прогресс в обнаружении дипфейков, большинство существующих методов не предоставляют объяснимых результатов. В данной работе, посвященной ‘Explainable Deepfake Detection with RL Enhanced Self-Blended Images’, предложен новый подход, использующий самосмешанные изображения и обучение с подкреплением для автоматической генерации данных с цепочкой рассуждений (CoT). Это позволяет снизить затраты на аннотацию и повысить точность и обобщающую способность моделей обнаружения дипфейков, особенно в условиях нехватки размеченных данных. Способны ли подобные методы, основанные на автоматической генерации данных и обучении с подкреплением, существенно продвинуть область объяснимого искусственного интеллекта и повысить доверие к системам обнаружения подделок?
Растущая Угроза Дипфейков: Математика Обмана
Распространение сфабрикованного медиаконтента представляет собой серьезную угрозу для доверия к информации и её целостности. В эпоху цифровых технологий, когда визуальные и аудиозаписи стали основным источником новостей и доказательств, возможность создания реалистичных, но ложных материалов подрывает основы общественной уверенности. Это касается не только отдельных лиц, становящихся жертвами дискредитации, но и институтов, чья репутация может быть намеренно испорчена. В результате, общество сталкивается с растущей сложностью в различении правды от вымысла, что приводит к поляризации мнений, распространению дезинформации и ослаблению социальных связей. Крайне важно осознать, что подобная манипуляция информацией может иметь далеко идущие последствия для политических процессов, экономической стабильности и даже национальной безопасности.
Современные методы обнаружения подделок, основанные на анализе артефактов сжатия или несоответствий в освещении, все чаще оказываются неэффективными перед лицом стремительно развивающихся технологий создания дипфейков. Усовершенствованные алгоритмы генеративных состязательных сетей (GAN) способны создавать гиперреалистичные изображения и видеоролики, практически лишенные видимых признаков манипуляции. Более того, злоумышленники активно используют методы, направленные на обход существующих систем обнаружения, такие как добавление едва заметного шума или адаптация к специфике используемых алгоритмов. Таким образом, существующие инструменты становятся все менее надежными в борьбе с новыми, более изощренными формами цифрового обмана, что требует разработки принципиально новых подходов к верификации контента.
Обучение с Подкреплением для Надежного Обнаружения: Алгоритмическая Адаптация
Обучение с подкреплением (RL) представляет собой перспективный подход к созданию устойчивых детекторов дипфейков. В отличие от традиционных методов обучения с учителем, RL позволяет агенту (детектору) обучаться путем взаимодействия с окружающей средой и получения вознаграждения за правильные действия. Этот подход особенно полезен в задачах, где сложно определить четкие правила для обучения, или когда входные данные могут значительно варьироваться, как это часто бывает с дипфейками. RL позволяет агенту адаптироваться к новым, ранее не встречавшимся манипуляциям с изображениями и видео, что повышает его устойчивость к атакам и обеспечивает более надежное обнаружение подделок. В контексте обнаружения дипфейков, RL агент может обучаться на основе обратной связи, получаемой от оценки качества обнаружения и локализации манипуляций, что позволяет ему совершенствовать свои стратегии обнаружения и улучшать общую производительность.
Эффективное обучение с подкреплением (RL) требует наличия плотных сигналов вознаграждения для успешной оптимизации агента. В задачах бинарной классификации, таких как обнаружение дипфейков, стандартные метрики, возвращающие только конечное значение (например, точность классификации), предоставляют разреженные сигналы. Это затрудняет обучение агента, поскольку отсутствует информация о промежуточных шагах и корректности действий, приводящих к конечному результату. Отсутствие детальной обратной связи замедляет процесс обучения и может привести к неоптимальным решениям, поскольку агент не получает достаточно информации для улучшения своей стратегии.
Групная относительная оптимизация политики (GRPO) представляет собой метод преодоления ограничений, связанных с разреженными сигналами вознаграждения в обучении с подкреплением (RL), применяемом к задачам, таким как обнаружение дипфейков. В традиционном RL, агент получает вознаграждение только в конце эпизода, что затрудняет обучение при сложных задачах. GRPO решает эту проблему, вводя понятие относительного вознаграждения внутри группы схожих состояний. Вместо абсолютного значения вознаграждения, агент обучается максимизировать вознаграждение относительно других агентов или предыдущих действий в группе, что обеспечивает более частый и информативный сигнал, даже при разреженных вознаграждениях. Это позволяет агенту быстрее и эффективнее изучать оптимальную политику, особенно в задачах, где получение положительного вознаграждения является редким событием.
Для повышения эффективности обучения агента на основе обучения с подкреплением в задачах обнаружения дипфейков используется генерация информативных сигналов вознаграждения на основе ключевых слов, связанных с подделками. В частности, для оценки точности локализации подделки рассчитывается Jaccard Similarity между множествами региональных полей, полученных в ответах модели, и соответствующими областями в эталонной разметке. Это позволяет формировать более детальное и точное вознаграждение, направленное на улучшение способности модели к обнаружению и локализации манипуляций с изображениями или видео.
Синтез Данных для Усиления Обучения: Математическое Расширение Выборки
Набор данных FaceForensics++ представляет собой ценный ресурс для обучения детекторов дипфейков, однако его объем и разнообразие ограничены. Данный набор содержит относительно небольшое количество сгенерированных подделок, что может приводить к переобучению моделей и снижению их способности к обобщению на новые, ранее не встречавшиеся типы манипуляций. Ограниченность FaceForensics++ проявляется в недостаточном представлении различных техник создания дипфейков, уровней реалистичности и типов артефактов, что требует использования дополнительных методов расширения обучающей выборки для достижения высокой точности и надежности детекторов.
Синтез реалистичных поддельных изображений с использованием методов, таких как SBI (Semantic Blending and Interpolation), позволяет значительно расширить объем обучающих данных для алгоритмов обнаружения дипфейков и улучшить их способность к обобщению. SBI предполагает смешивание и интерполяцию семантически релевантных областей изображений, что позволяет создавать разнообразные и правдоподобные подделки, имитирующие различные артефакты, возникающие при манипуляциях с изображениями. Увеличение объема синтетических данных, особенно в тех областях, где исходные данные ограничены, способствует повышению устойчивости и точности моделей машинного обучения при обнаружении дипфейков в реальных условиях.
В процессе синтеза поддельных изображений с использованием метода SBI (Semantic Blending and Interpolation), параметр веса смешивания α играет ключевую роль в формировании разнообразия и реалистичности генерируемых подделок. Значение α определяет степень смешивания исходного и целевого изображений; низкие значения приводят к незначительным изменениям, создавая реалистичные, но тонкие манипуляции, в то время как высокие значения приводят к более выраженным артефактам, представляя собой более сложные подделки. Точное управление α позволяет генерировать широкий спектр подделок, охватывающих различные уровни сложности, что критически важно для обучения робастных детекторов дипфейков, способных выявлять как тонкие, так и грубые манипуляции с изображениями.
Для расширения разнообразия синтетических данных и повышения устойчивости моделей обнаружения подделок, при генерации изображений используются параметры аугментации с тремя уровнями интенсивности (слабая, умеренная и сильная). Эти параметры применяются к различным факторам, включая цветовой тон (hue), освещение (lighting), четкость (clarity), контрастность (contrast), масштабирование (scaling) и сдвиг (translation). Использование трех уровней интенсивности для каждого фактора позволяет создавать более широкий спектр вариаций в синтетических данных, что способствует лучшей обобщающей способности и устойчивости обученных моделей к различным типам манипуляций с изображениями.
К Интерпретируемому и Локализованному Обнаружению Дипфейков: Алгоритмическая Прозрачность
Многомодальные большие языковые модели (MLLM) открывают новые возможности в обнаружении дипфейков, предоставляя не просто вывод о подлинности изображения, но и объяснение, на основании чего этот вывод сделан. Вместо “подделка” или “не подделка”, MLLM способны генерировать текстовое описание, указывающее на конкретные визуальные признаки, которые позволили сделать такой вывод. Например, модель может указать на несоответствие освещения, неестественные тени или артефакты сжатия, которые указывают на манипуляции с изображением. Такой подход значительно повышает доверие к системе обнаружения дипфейков, поскольку позволяет пользователю понять логику работы алгоритма и самостоятельно оценить обоснованность решения. Предоставляя “рассуждения” в текстовом формате, MLLM делают процесс выявления подделок более прозрачным и понятным, что особенно важно в контексте распространения дезинформации и фейковых новостей.
Метод аннотации “Цепочка рассуждений” (Chain-of-Thought, CoT) значительно повышает качество объяснений, предоставляемых моделями для выявления дипфейков. Использование больших многомодальных языковых моделей, таких как InternVL3-38B, позволяет не просто определить, является ли изображение подделкой, но и подробно описать ход рассуждений, приведший к этому выводу. Вместо простого ответа “подделка”, модель, обученная с применением CoT, может, например, указать на несоответствия в освещении, неестественные тени или аномалии в текстуре кожи, обосновывая свой вердикт. Такой подход не только повышает доверие к результатам анализа, но и предоставляет ценную информацию для дальнейшего изучения и совершенствования методов обнаружения дипфейков.
Для существенного повышения способности мультимодальных больших языковых моделей (MLLM) к логическому анализу и выявлению подделок, проводится контролируемая тонкая настройка с использованием задач визуального вопросно-ответного типа. Этот процесс предполагает обучение моделей на наборе данных, состоящем из изображений и соответствующих вопросов, требующих детального анализа визуального контента для формирования ответа. В результате, MLLM не просто идентифицируют признаки подделки, но и демонстрируют улучшенное понимание контекста изображения, что позволяет им более точно обосновывать свои выводы и предоставлять более убедительные объяснения, выходящие за рамки простого определения «подделка» или «не подделка». Такая тонкая настройка значительно расширяет возможности MLLM в области интерпретируемого анализа, делая их более надежными и прозрачными инструментами для выявления дипфейков.
Локализация подделок, осуществляемая с помощью метрик, таких как коэффициент Жаккара, позволяет точно определить области изображения, подвергшиеся манипуляциям, предоставляя детальный анализ изменений. Данный подход выходит за рамки простого определения «подделка или нет», указывая конкретные участки, где были внесены правки. Коэффициент Жаккара, измеряющий сходство между предсказанной областью манипуляции и реальной, обеспечивает количественную оценку точности локализации. Высокое значение коэффициента указывает на точное выявление подделанных областей, что критически важно для установления достоверности визуальной информации и выявления возможных злоупотреблений. Подобный гранулярный анализ значительно повышает доверие к системам обнаружения дипфейков и позволяет проводить более глубокую экспертизу цифрового контента.
Представленное исследование демонстрирует стремление к математической чистоте в области обнаружения дипфейков. Авторы предлагают элегантное решение, объединяющее обучение с подкреплением и техники смешивания изображений для автоматической генерации данных CoT. Этот подход позволяет не только повысить точность обнаружения подделок, но и улучшить обобщающую способность модели, решая проблему разреженности вознаграждений. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто работают, а которые мы можем понять.» Данная работа полностью соответствует этому принципу, предлагая прозрачный и доказуемый алгоритм, а не просто эмпирически работающее решение.
Что Дальше?
Представленная работа, безусловно, демонстрирует потенциал сочетания техник смешивания изображений и обучения с подкреплением для генерации данных, необходимых для объяснимого обнаружения дипфейков. Однако, если решение кажется магией — значит, инвариант не раскрыт. Очевидным ограничением остаётся зависимость от тщательно разработанной функции вознаграждения. Дальнейшие исследования должны быть направлены на разработку более устойчивых к изменениям и не требующих ручной настройки алгоритмов формирования вознаграждений, возможно, с использованием принципов обучения без учителя или самообучения.
Более того, текущий подход, хотя и улучшает обобщающую способность, по-прежнему страдает от неизбежной проблемы «чёрного ящика», присущей глубоким нейронным сетям. Следующим логичным шагом представляется интеграция формальных методов верификации и доказательства корректности алгоритмов, что позволит не просто обнаруживать дипфейки, но и предоставлять математически обоснованные гарантии надёжности. Необходимо сместить фокус с эмпирической точности на доказуемость.
В конечном счёте, истинная элегантность решения заключается не в достижении высокой точности на ограниченном наборе данных, а в разработке алгоритма, который может адаптироваться к новым, ранее неизвестным типам манипуляций с изображениями и видео, не требуя постоянной перенастройки. До тех пор, пока мы не достигнем этой цели, все наши усилия останутся лишь временным решением проблемы.
Оригинал статьи: https://arxiv.org/pdf/2601.15624.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-23 07:26