Автор: Денис Аветисян
Исследователи представляют AIGVDBench — масштабный набор данных и систему оценки, призванные значительно улучшить точность обнаружения видео, сгенерированных искусственным интеллектом.
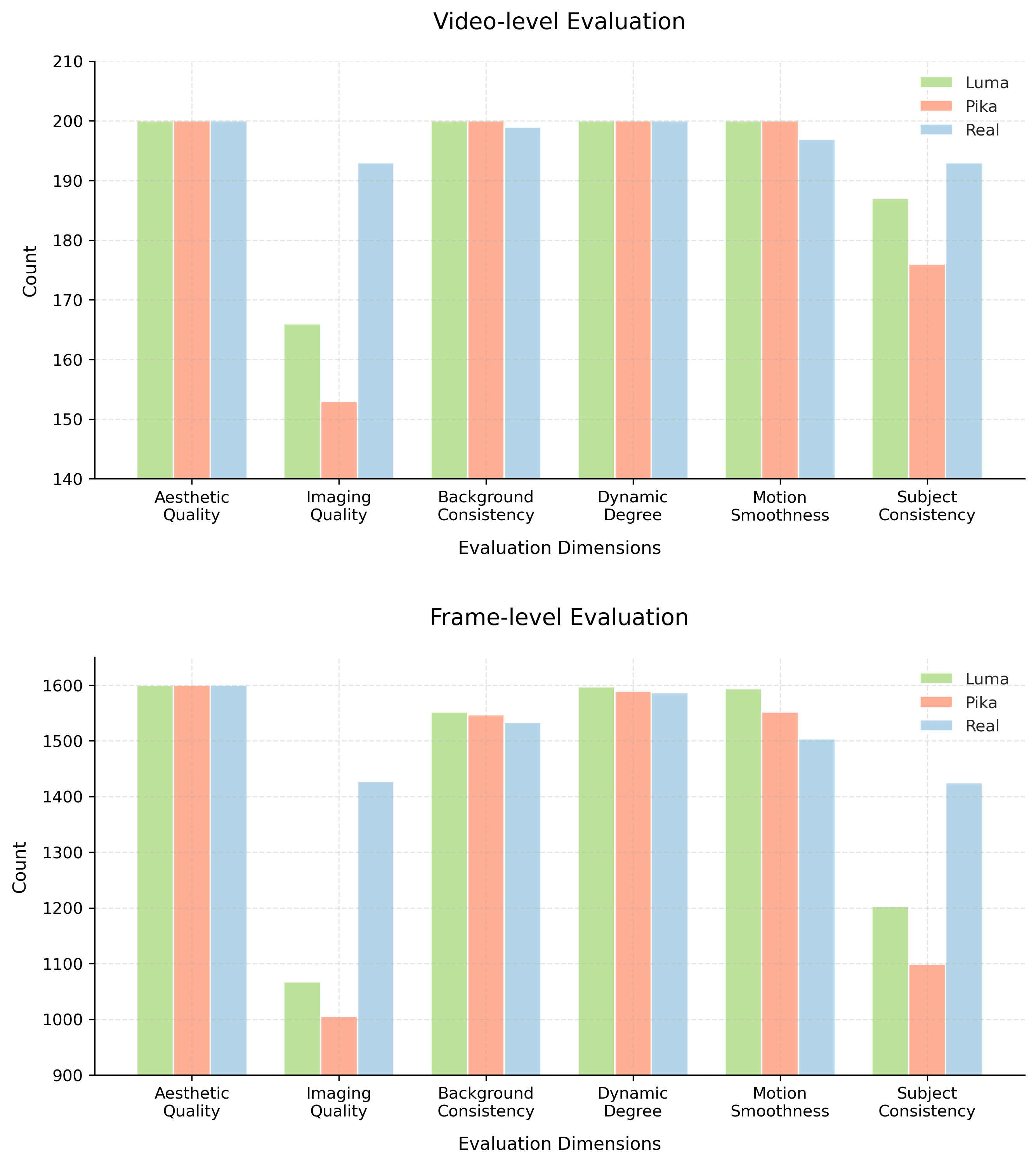
Представлен AIGVDBench — крупный и качественный набор данных для оценки систем обнаружения видео, созданных с использованием генеративных моделей.
По мере развития генеративных моделей всё сложнее отличить реалистичные синтетические видео от настоящих, что требует надежных методов их обнаружения. В работе, озаглавленной ‘Your One-Stop Solution for AI-Generated Video Detection’, представлен AIGVDBench — масштабный и репрезентативный бенчмарк, включающий более 440 000 видео, сгенерированных 31 современной моделью. Этот бенчмарк и сопутствующая оценка 33 существующих детекторов позволяют выявить ключевые ограничения существующих подходов и предложить новые направления для исследований в области видео-форензики. Какие дальнейшие шаги необходимы для создания действительно устойчивых к манипуляциям систем обнаружения AI-сгенерированных видео?
Растущая Реальность: Вызовы и Возможности в Эпоху Синтетического Видео
Современные модели генерации видео, такие как Veo и Sora, демонстрируют беспрецедентный прогресс в создании реалистичного контента, что приводит к размытию границ между подлинными видеозаписями и синтетическими изображениями. Эти системы способны генерировать сложные сцены с высокой степенью детализации и правдоподобия, имитируя различные стили съемки и визуальные эффекты. Способность создавать видео, практически неотличимые от реальных, представляет собой значительный технологический прорыв, но одновременно порождает серьезные вызовы в контексте проверки подлинности информации и борьбы с дезинформацией. Растущая сложность и реалистичность сгенерированных видео требует разработки новых методов анализа и выявления искусственного происхождения контента, поскольку традиционные подходы оказываются все менее эффективными в обнаружении изощренных подделок.
Существующие методы обнаружения видео, созданного искусственным интеллектом, сталкиваются со значительными трудностями при анализе контента, отличающегося высокой детализацией и реалистичностью. Алгоритмы, эффективно распознающие грубые артефакты ранних генеративных моделей, оказываются неспособными выявить манипуляции в более качественных видео, где ИИ имитирует сложные сцены и человеческое поведение. Разнообразие используемых техник генерации, включая различные подходы к рендерингу и стилизации, усложняет задачу, поскольку единый алгоритм обнаружения не может эффективно работать со всеми типами синтетического контента. Это приводит к тому, что даже высококачественные подделки могут оставаться незамеченными, что представляет серьезную угрозу для достоверности визуальной информации и требует разработки принципиально новых, более адаптивных методов анализа.
В связи с экспоненциальным ростом числа генеративных моделей, создающих видеоконтент, возникает острая необходимость в надежном и репрезентативном эталоне для оценки способности систем обнаруживать искусственно сгенерированные материалы. Такой эталон должен охватывать широкий спектр техник генерации, включая различные стили, уровни реализма и типы артефактов, чтобы обеспечить всестороннюю проверку алгоритмов обнаружения. Отсутствие подобного стандарта препятствует объективному сравнению различных методов и замедляет прогресс в этой критически важной области, поскольку разработчики лишены возможности эффективно оценивать и совершенствовать свои системы. Создание всеобъемлющего эталона позволит не только выявить слабые места существующих алгоритмов, но и стимулировать разработку более устойчивых и точных методов, способных эффективно противостоять растущей угрозе дезинформации и манипулирования посредством синтетических медиа.
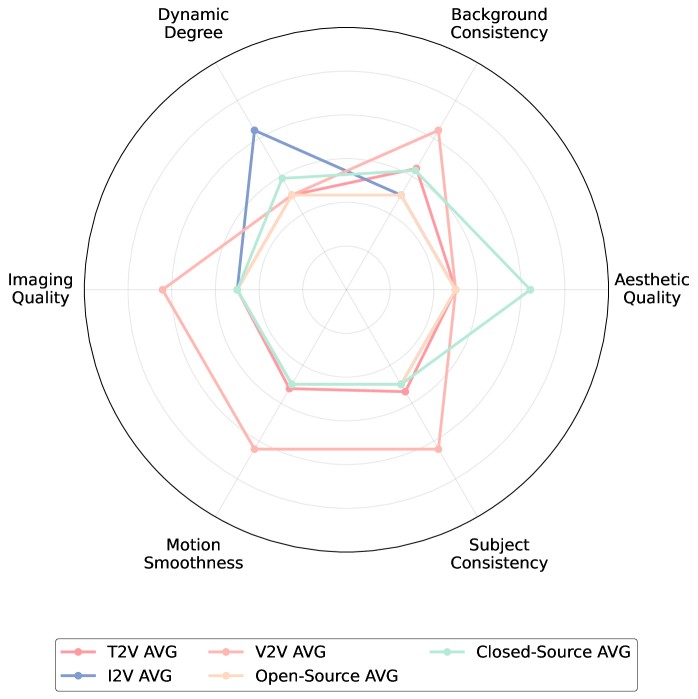
AIGVDBench: Новая Эра в Оценке Надежности Систем Обнаружения
AIGVDBench представляет собой масштабный и высококачественный бенчмарк, разработанный для решения проблем, существующих в текущих методах обнаружения видео, сгенерированных искусственным интеллектом. Существующие наборы данных часто не обладают достаточным разнообразием и масштабом для адекватной оценки устойчивости алгоритмов детектирования, что приводит к переоценке их эффективности и неспособности выявлять сгенерированный контент в реальных сценариях. AIGVDBench призван восполнить этот пробел, предоставляя исследователям и разработчикам надежный инструмент для оценки и улучшения алгоритмов обнаружения сгенерированных видео.
Набор данных AIGVDBench состоит из более чем 440 000 видеороликов, полученных из 31 различной генеративной модели. Такой масштаб и разнообразие источников обеспечивают беспрецедентное покрытие различных методов генерации видео. В состав набора включены видео, созданные как открытыми, так и закрытыми моделями, что позволяет всесторонне оценить эффективность алгоритмов обнаружения сгенерированного контента в различных сценариях.
Для обеспечения репрезентативности AIGVDBench, процесс создания набора данных использовал реалистичный контент из OpenVidHD, дополненный видео, сгенерированными 31 различной генеративной моделью. В целях достижения сбалансированного представления, было сгенерировано 20 000 видео для каждой модели с открытым исходным кодом и 2 000 видео для каждой модели с закрытым исходным кодом. Такое распределение позволяет комплексно оценить эффективность алгоритмов обнаружения AI-сгенерированного видео, учитывая разнообразие используемых моделей и их вклад в общий объем данных.
Алгоритм балансировки атрибутов (Attribute Balancing Algorithm) является ключевой инновацией в процессе создания AIGVDBench. Он предназначен для систематического устранения предвзятостей и обеспечения сбалансированного распределения визуальных характеристик в наборе данных. Данный алгоритм анализирует генерируемые видео и корректирует выборку, чтобы избежать доминирования определенных атрибутов (например, конкретных объектов, сцен или стилей), которые могут привести к завышенной оценке производительности детекторов на определенном подмножестве данных. Реализация алгоритма включает в себя количественную оценку и коррекцию дисбаланса по ключевым визуальным признакам, что обеспечивает более надежную и объективную оценку алгоритмов обнаружения AI-генерируемого видео.
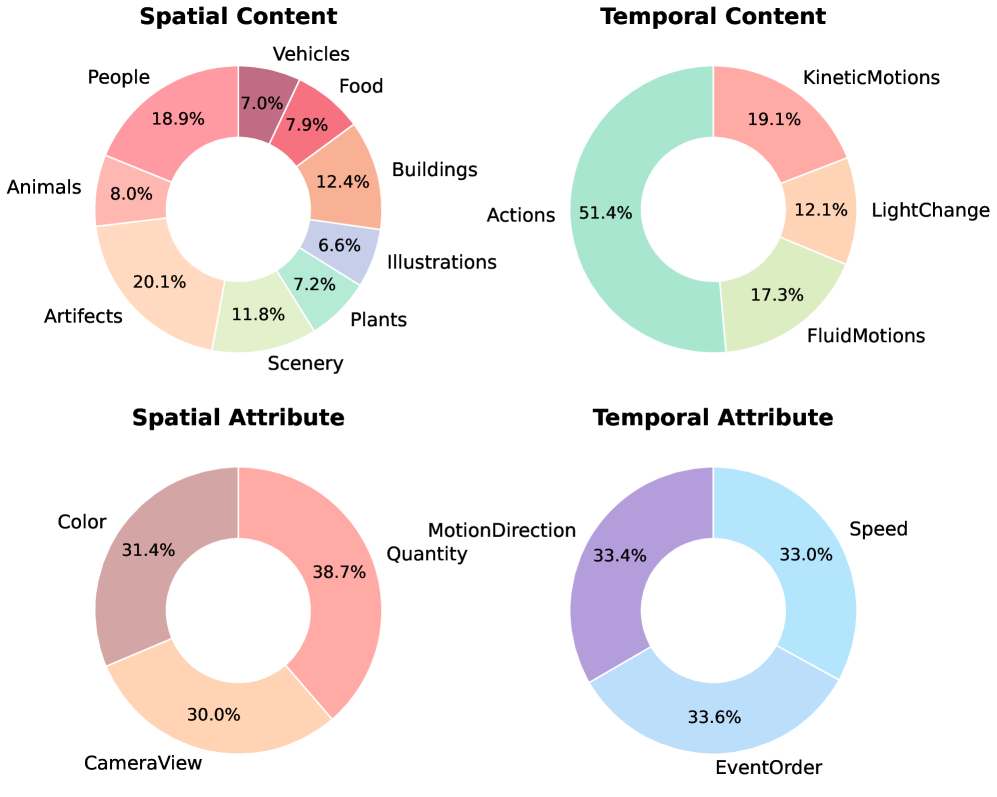
Технические Детали и Контроль Качества AIGVDBench
База данных AIGVDBench использует стандарты сжатия видео H.264 и MPEG-4 Part 2, что позволяет проводить оценку производительности алгоритмов на широком спектре видеоформатов. Включение обоих стандартов обеспечивает совместимость с существующими кодеками и позволяет исследователям анализировать эффективность работы систем в различных сценариях кодирования и декодирования видео. Использование данных, сжатых различными кодеками, повышает обобщающую способность результатов оценки и позволяет получить более полную картину производительности тестируемых систем.
Баланс и разнообразие набора данных AIGVDBench количественно оцениваются с использованием Показателя Глобального Баланса со Штрафами (Penalized Global Balance Score). В ходе сравнения с другими существующими наборами данных, AIGVDBench достиг наивысшего значения этого показателя, что свидетельствует о его превосходном балансе по различным категориям и сценариям. Данный показатель учитывает как равномерность представленности классов, так и разнообразие ситуаций, обеспечивая более надежную и объективную оценку производительности алгоритмов анализа видео.
Оценочные пайплайны AIGVDBench построены на базе фреймворков, таких как MMAction2, что обеспечивает стандартизацию и воспроизводимость результатов исследований. Использование MMAction2 позволяет исследователям легко интегрировать и адаптировать пайплайны для своих задач, а также сравнивать результаты, полученные на различных конфигурациях и аппаратных платформах. Это достигается благодаря модульной структуре фреймворка и возможности определения стандартных протоколов оценки, что минимизирует влияние вариаций в реализации на результаты и повышает доверие к полученным данным.

Взгляд в Будущее: Визуально-Языковые Модели и Эволюция Обнаружения
В настоящее время обнаружение видео, сгенерированных искусственным интеллектом, всё чаще опирается на модели, объединяющие зрение и язык. Эти модели, в отличие от традиционных систем анализа видео, способны учитывать не только визуальные характеристики, но и текстовые подсказки, описывающие содержание или контекст ролика. Такой подход позволяет им выявлять несоответствия между визуальной информацией и ожидаемым содержанием, что особенно важно для выявления подделок и манипуляций. Способность модели одновременно обрабатывать визуальные данные и текстовые запросы значительно повышает точность и надежность обнаружения, позволяя выявлять даже сложные случаи, где визуальные признаки могут быть обманчивы.
Эффективная работа моделей, объединяющих зрение и язык, напрямую зависит от способности к временному рассуждению — умения обрабатывать информацию последовательно во времени и выявлять нелогичности в развитии событий. Эти модели не просто анализируют отдельные кадры видео, но и учитывают взаимосвязь между ними, выявляя несоответствия в последовательности действий или объектов. Например, модель, обученная на реалистичных видео, должна распознать, что появление объекта до момента его создания является временной аномалией. Успешное временное рассуждение требует от модели не только распознавания объектов и действий, но и понимания причинно-следственных связей и общих физических законов, что позволяет ей обнаруживать манипуляции или подделки в видеоматериалах с высокой точностью. Таким образом, способность к анализу временных последовательностей является ключевым фактором для надежного обнаружения сгенерированных или измененных видео.
Эффективность моделей, объединяющих зрение и язык, в обнаружении сгенерированных искусственным интеллектом видео, напрямую зависит от мастерства, с которым формируются запросы — так называемого “Prompt Engineering”. Данный подход позволяет не просто идентифицировать признаки подделки, но и проводить глубокий, нюансированный анализ видеоматериала. Тщательно продуманные запросы направляют модель на поиск специфических аномалий, например, несоответствия между визуальным рядом и звуковым сопровождением, или неестественные движения объектов. Вместо общей команды «определить подделку», запрос может быть сформулирован как «выявить признаки манипуляции с лицами в видео» или «проверить согласованность освещения и теней». Такая точность существенно повышает вероятность обнаружения даже самых изощренных подделок и позволяет модели проводить более детальный и осмысленный анализ видеоконтента, открывая новые возможности для верификации информации.
Исследование, представленное в данной работе, акцентирует внимание на важности создания надежных инструментов для обнаружения видео, сгенерированных искусственным интеллектом. Создание датасета AIGVDBench является значительным шагом в решении этой задачи, поскольку позволяет оценить и улучшить существующие методы обнаружения дипфейков. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект — это не только технология, но и отражение человеческих ценностей». Этот принцип особенно актуален в контексте обнаружения сгенерированных видео, где точность и надежность алгоритмов напрямую влияют на доверие к визуальной информации и предотвращение дезинформации. Создание качественного датасета — это фундаментальный шаг к развитию более ответственного и надежного искусственного интеллекта.
Что дальше?
Представленный набор данных, AIGVDBench, безусловно, представляет собой шаг вперёд в области обнаружения видео, сгенерированных искусственным интеллектом. Однако, как показывает опыт, любое систематическое описание реальности неизбежно обнажает новые вопросы, а не даёт окончательные ответы. Успех любой метрики зависит от её способности выявлять закономерности, а не просто фиксировать их наличие. Если предложенная закономерность не воспроизводится или её невозможно объяснить, её существование подвергается сомнению.
Будущие исследования, вероятно, будут сосредоточены на преодолении ограничений, присущих текущим методам. Необходимо разрабатывать алгоритмы, устойчивые к намеренным искажениям и адаптации генеративных моделей. Важно также исследовать возможности использования метаданных и контекстной информации для повышения точности обнаружения. Интересным направлением представляется разработка методов, способных оценивать степень «неестественности» видео, а не просто бинарно классифицировать его как «сгенерированное» или «реальное».
В конечном счёте, прогресс в этой области будет зависеть от способности исследователей видеть лес за деревьями — то есть от понимания фундаментальных принципов, лежащих в основе как генеративных моделей, так и методов их обнаружения. Иначе, мы рискуем создать лишь сложный набор инструментов для игры в кошки-мышки, а не действительно надёжную систему защиты от дезинформации.
Оригинал статьи: https://arxiv.org/pdf/2601.11035.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-19 17:39