Автор: Денис Аветисян
Исследователи представили архитектуру EA-Swin и масштабный датасет EA-Video для повышения точности обнаружения видео, сгенерированных искусственным интеллектом, в условиях растущего реализма синтетического контента.
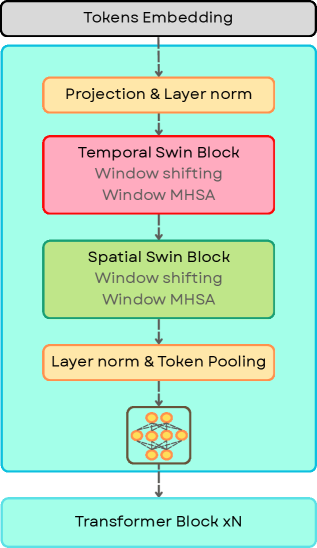
В статье представлена новая spatiotemporal Transformer архитектура EA-Swin и датасет EA-Video для улучшения обнаружения AI-сгенерированных видео.
По мере развития генеративных моделей искусственного интеллекта, создающих все более реалистичные видео, существующие методы обнаружения подделок оказываются неэффективными из-за их ограниченной способности к анализу сложных пространственно-временных зависимостей. В данной работе, представленной в статье ‘EA-Swin: An Embedding-Agnostic Swin Transformer for AI-Generated Video Detection’, предлагается архитектура EA-Swin — Swin Transformer, не зависящий от конкретного типа эмбеддингов, — способный моделировать эти зависимости непосредственно на предобученных видео-эмбеддингах. В сочетании с новым масштабным набором данных EA-Video, модель демонстрирует высокую точность обнаружения (0.97-0.99) и превосходит существующие аналоги на 5-20%, сохраняя при этом устойчивость к новым генеративным моделям. Сможет ли EA-Swin стать надежным инструментом для защиты от распространения дезинформации в эпоху гиперреалистичного синтетического видеоконтента?
Распознавание Реальности: Вызовы в Эпоху Синтетических Медиа
Современные генеративные модели искусственного интеллекта демонстрируют беспрецедентный прогресс в создании видеоматериалов, приближающихся по качеству к реальным. Эти алгоритмы способны не просто воссоздавать изображения, но и генерировать сложные сцены, имитирующие человеческую речь и мимику с поразительной точностью. Такой стремительный рост возможностей стирает границы между аутентичным и синтетическим контентом, создавая все больше трудностей в определении подлинности видеозаписей. Новые поколения моделей способны учитывать мельчайшие детали, такие как освещение, тени и текстуры, что делает обнаружение подделок крайне сложной задачей и требует разработки принципиально новых методов анализа видеоданных.
Распространение контента, созданного искусственным интеллектом, включая дипфейки, требует разработки надежных методов обнаружения для противодействия дезинформации и злонамеренному использованию. Появление реалистичных синтетических видеороликов создает серьезные угрозы для общественного доверия и может быть использовано для манипулирования общественным мнением, нанесения ущерба репутации или даже разжигания конфликтов. В связи с этим, крайне важно разработать инструменты и алгоритмы, способные эффективно выявлять поддельные видеоматериалы и отличать их от подлинных, обеспечивая тем самым защиту от потенциальных негативных последствий и сохраняя целостность информационного пространства. Активные исследования в области анализа видео и машинного обучения направлены на создание таких систем, способных обнаруживать даже самые сложные и искусно выполненные подделки.
Современные методы анализа видео, разработанные для обнаружения подделок и манипуляций, оказываются всё менее эффективными в борьбе с новейшими моделями генеративного искусственного интеллекта. Их сложность и реалистичность, достигаемые благодаря прогрессу в области глубокого обучения, позволяют создавать видеоматериалы, практически неотличимые от настоящих, что ставит под вопрос надёжность традиционных алгоритмов, основанных на выявлении артефактов сжатия или несоответствий в освещении. Поэтому, для сохранения доверия к визуальной информации и противодействия распространению дезинформации, необходимы принципиально новые подходы к обнаружению подделок, использующие, например, анализ микровыражений, исследование несоответствий в физике движений или разработку моделей, способных оценивать правдоподобность происходящего на основе контекста и здравого смысла.

Пространственно-Временное Моделирование для Надёжного Анализа Видео
Для эффективного обнаружения видео, сгенерированных искусственным интеллектом, модели должны учитывать как пространственные детали каждого кадра, так и временные зависимости между кадрами в последовательности. Игнорирование пространственных характеристик приводит к неспособности различать объекты и сцены, а отсутствие учета временной динамики препятствует распознаванию действий и событий, происходящих в видео. Таким образом, модели, способные эффективно обрабатывать и интегрировать пространственную и временную информацию, необходимы для достижения высокой точности в задаче определения подлинности видеоконтента.
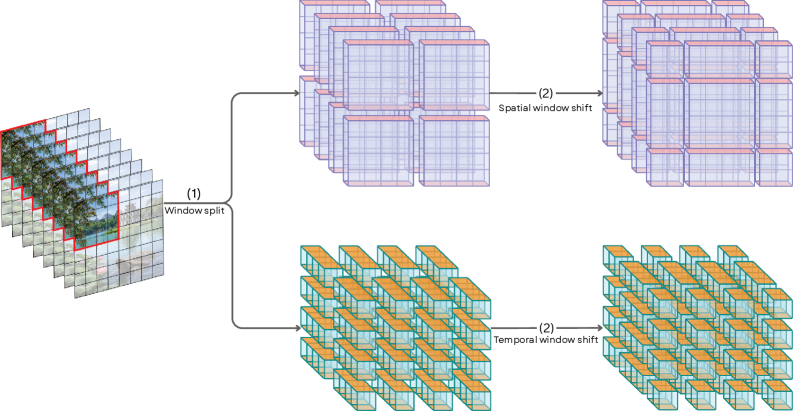
Архитектура EA-Swin использует пространственно-временное моделирование для эффективной обработки видеоданных посредством оконного и факторизованного внимания. Оконное внимание разделяет кадр на неперекрывающиеся окна, вычисляя внимание внутри каждого окна для снижения вычислительной сложности. Факторизованное внимание дополнительно разделяет процесс вычисления внимания на отдельные пространственные и временные измерения, что позволяет еще больше уменьшить количество параметров и ускорить обработку. Такой подход позволяет модели эффективно захватывать как пространственные детали, так и временные зависимости в видеопоследовательностях, сохраняя при этом вычислительную эффективность, необходимую для обработки больших объемов видеоданных.
Архитектура EA-Swin использует энкодер V-JEPA2, предварительно обученный методом самообучения, для повышения эффективности извлечения признаков и обобщающей способности модели. Предварительное обучение V-JEPA2 на больших объемах неразмеченных видеоданных позволяет модели усвоить полезные представления о видеоконтенте, что значительно улучшает ее производительность при решении задач обнаружения сгенерированных ИИ видео. В результате, EA-Swin демонстрирует передовые результаты в задачах понимания видео, превосходя существующие модели по ключевым показателям точности и надежности.
Масштабирование Обнаружения с Использованием Больших Наборов Данных и Самообучения
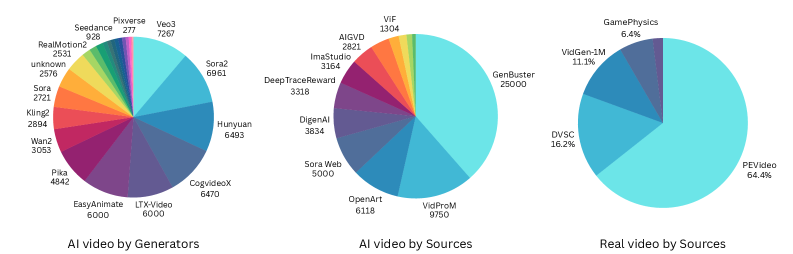
Эффективность моделей обнаружения видео, сгенерированных искусственным интеллектом, напрямую зависит от объема и разнообразия используемых обучающих данных. Для достижения высоких показателей требуется использование масштабных датасетов, таких как EA-Video Dataset, содержащих широкий спектр сгенерированных видео и реальных записей. Недостаток данных или их однородность ограничивают способность модели к обобщению и снижают точность обнаружения, особенно в отношении новых или ранее не встречавшихся генераторов. Масштабные и разнообразные датасеты позволяют модели изучить более надежные и инвариантные признаки, необходимые для точной классификации видеоконтента.
Методы самообучения, такие как DINOv2 и DINOv3, играют ключевую роль в предварительной подготовке надежных визуальных признаков, обходясь без использования размеченных данных. Эти подходы позволяют модели изучать представления о визуальных данных путем решения задач, сформулированных на основе самих данных, например, предсказание поворотов изображений или восстановление замаскированных участков. Предварительное обучение с использованием самообучения позволяет значительно сократить потребность в больших объемах размеченных данных, что особенно важно для задач, где получение разметок является дорогостоящим или трудоемким. Полученные таким образом визуальные признаки затем могут быть использованы для обучения моделей обнаружения сгенерированного видео, обеспечивая высокую точность и обобщающую способность даже при работе с ранее не встречавшимися генераторами.
Модель EA-Swin демонстрирует передовые показатели точности в задаче обнаружения сгенерированного ИИ видео, достигая 98.66% на генераторах, присутствующих в обучающей выборке, и 97.4% на ранее не встречавшихся генераторах. Кроме того, модель показывает значение AUC (площадь под ROC-кривой) в 0.9991 для известных генераторов и 0.997 для неизвестных. Для генераторов из обучающей выборки, EA-Swin достигает F1-меры, точности и полноты в 98.66%, что подтверждает высокую обобщающую способность и эффективность модели в обнаружении сгенерированного видео.
Будущее Обнаружения в Эпоху Генеративного Контента
Стремительное развитие моделей преобразования текста в видео, таких как Sora2 и Veo3, открывает новую эру в создании гиперреалистичных видеоматериалов, практически неотличимых от съемок реального мира. Эти передовые системы, использующие сложные алгоритмы глубокого обучения, способны генерировать сложные сцены, правдоподобные движения и детализированные текстуры, основываясь лишь на текстовом описании. В результате, создаваемые ими видеоролики демонстрируют беспрецедентный уровень реализма, что существенно усложняет задачу их идентификации и поднимает вопросы о достоверности визуальной информации в цифровой среде. Развитие этих технологий не только расширяет возможности для творчества и развлечений, но и требует разработки новых методов обнаружения и верификации видеоконтента, чтобы предотвратить распространение дезинформации и манипуляций.
Для эффективного выявления всё более совершенных видео, созданных искусственным интеллектом, требуется непрерывное развитие методов пространственно-временного моделирования и техник самообучения. Традиционные подходы, основанные на анализе отдельных кадров, оказываются недостаточными, поскольку современные генеративные модели способны создавать видео с высокой степенью реалистичности и когерентностью во времени. Новейшие исследования направлены на создание алгоритмов, способных учитывать динамику сцены, взаимосвязи между объектами и их поведение во времени. Самообучение, в свою очередь, позволяет моделям извлекать полезные признаки из больших объемов неразмеченных данных, что особенно важно в условиях постоянно меняющегося ландшафта AI-генерируемого контента. Разработка и внедрение этих передовых техник представляется критически важной задачей для обеспечения достоверности визуальной информации и противодействия потенциальным угрозам дезинформации.
Сохранение доверия к визуальной информации становится все более сложной задачей в эпоху стремительного развития технологий генерации видео. Появление реалистичных, созданных искусственным интеллектом видеороликов несет в себе значительные риски распространения дезинформации и манипулирования общественным мнением. Актуальность разработки эффективных методов обнаружения таких видео определяется необходимостью защиты от намеренного введения в заблуждение и поддержания целостности информационного пространства. Успешное решение данной проблемы позволит обществу более критично оценивать визуальный контент и противостоять попыткам искажения реальности, что особенно важно в контексте политических процессов, новостной повестки и формирования общественного мнения.
Исследование, представленное в данной работе, демонстрирует стремление к пониманию внутренних закономерностей, управляющих созданием и обнаружением синтетических видео. Разработчики EA-Swin, подобно исследователям, стремящимся к глубокому анализу данных, создали архитектуру, способную выявлять тонкие различия между реальным и сгенерированным контентом. Как однажды заметил Джеффри Хинтон: “Я думаю, что нейронные сети — это просто способ моделировать вероятностные зависимости”. Эта фраза отражает суть работы: EA-Swin, анализируя пространственно-временные зависимости в видеоряде, стремится оценить вероятность его подлинности. Создание масштабного датасета EA-Video является важным шагом к обучению моделей, способных эффективно распознавать все более реалистичные подделки, что подчеркивает необходимость постоянного совершенствования методов обнаружения deepfake-видео.
Что дальше?
Представленная работа, подобно тщательному микроскопическому исследованию, выявила закономерности в структуре искусственно сгенерированных видео. Однако, сам «объект исследования» — технологии генерации — не стоит на месте. Растущая сложность алгоритмов, и, как следствие, всё более реалистичные синтетические видео, неизбежно потребуют от методов обнаружения не просто повышения точности, но и принципиально новых подходов к анализу. Простое увеличение масштаба данных, хотя и необходимо, не решит проблему, если сама модель анализа останется прежней.
Особый интерес представляет исследование устойчивости предложенной архитектуры к «адаптации» генеративных моделей — способности последних обходить существующие детекторы. Ведь, подобно эволюции в природе, генеративные модели будут «обучаться» обманывать детекторы, а последним придётся постоянно совершенствоваться. Помимо этого, перспективным направлением является разработка методов, способных оценивать не только факт подделки, но и степень её правдоподобности — насколько «убедительна» ложь.
В конечном счёте, задача обнаружения искусственных видео — это не просто техническая проблема, но и философский вызов. Размывание границ между реальностью и симуляцией требует от нас не только совершенствования алгоритмов, но и критического осмысления самой природы визуальной информации. И подобно тому, как микроскоп открывает невидимый мир, так и анализ данных раскрывает всё более сложные закономерности, заставляя нас переосмысливать привычные представления о реальности.
Оригинал статьи: https://arxiv.org/pdf/2602.17260.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-20 20:46