Автор: Денис Аветисян
Исследователи предлагают инновационный подход к обнаружению поддельных видео, основанный на одновременном анализе изображения и текстовых описаний, что позволяет выявлять даже самые незаметные манипуляции.
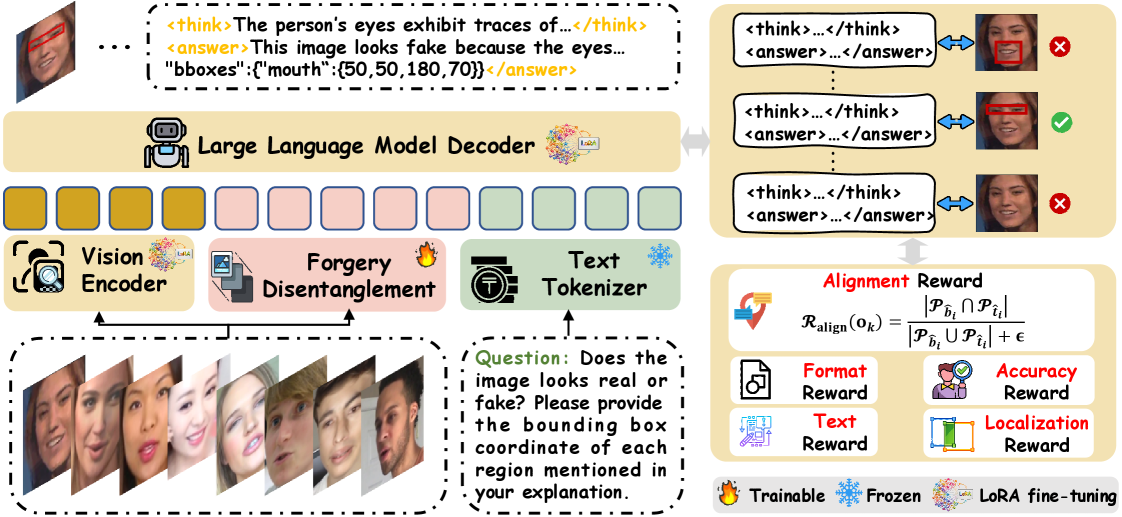
Предложен фреймворк MARE, использующий обучение с подкреплением и мультимодальную согласованность для повышения точности и объяснимости обнаружения дипфейков.
Современные методы выявления дипфейков, несмотря на их широкое распространение, часто уступают в точности и интерпретируемости. В данной работе, посвященной разработке фреймворка ‘MARE: Multimodal Alignment and Reinforcement for Explainable Deepfake Detection via Vision-Language Models’, предлагается новый подход, использующий мультимодальное выравнивание и обучение с подкреплением для повышения надежности и объяснимости обнаружения дипфейков. Ключевым нововведением является фокусировка на тонких признаках подделки и генерация пространственно-согласованного обоснования решений, что позволяет значительно улучшить результаты обнаружения. Сможет ли предложенный подход стать основой для создания действительно надежных систем выявления манипулированного контента в будущем?
Распознавание Искажения: Угроза Дипфейков и Необходимость Критического Анализа
Распространение высококачественных дипфейков представляет собой серьезную угрозу для достоверности информации и доверия к медиа. Эти синтетические медиафайлы, созданные с использованием искусственного интеллекта, становятся всё более реалистичными и трудноотличимыми от подлинных, что подрывает способность общества к критическому восприятию новостей и визуального контента. Возможность манипулирования изображениями и видео с высокой степенью правдоподобия создает благоприятную почву для дезинформации, политической пропаганды и мошенничества, способствуя росту недоверия к источникам информации и институтам. По мере совершенствования технологий создания дипфейков, а также увеличения их доступности, последствия для общественного мнения, безопасности и даже международных отношений становятся всё более ощутимыми, требуя разработки эффективных механизмов обнаружения и противодействия этому растущему вызову.
Традиционные методы выявления подделок, основанные на анализе пикселей и статистических аномалий, всё чаще оказываются неэффективными перед лицом стремительно совершенствующихся дипфейков. Ранее заметные несоответствия, такие как неестественные переходы или артефакты сжатия, теперь умело маскируются передовыми алгоритмами генеративного искусственного интеллекта. Попытки обнаружить манипуляции путём сравнения с исходными данными часто терпят неудачу, поскольку дипфейки способны не только визуально правдоподобно изменять изображения и видео, но и подделывать метаданные, создавая иллюзию подлинности. В результате, стандартные инструменты, предназначенные для обнаружения простых подделок, оказываются бессильными против сложных манипуляций, требуя разработки принципиально новых подходов к анализу и верификации контента.
Выявление едва заметных несоответствий — так называемых «следов подделки» — играет ключевую роль в обнаружении дипфейков, однако требует глубокого и многостороннего анализа. Эти следы могут проявляться в виде незначительных артефактов, несоответствий в освещении или неестественных движений, которые не сразу бросаются в глаза. Простое сравнение пикселей часто оказывается недостаточным, поскольку современные алгоритмы манипулирования изображениями и видео способны создавать весьма реалистичные подделки. Поэтому эффективная проверка требует пристального внимания к деталям, понимания физических принципов формирования изображений и видео, а также использования специализированных инструментов, способных выявлять тонкие структурные аномалии и несоответствия, невидимые для невооруженного глаза.
Для эффективного обнаружения дипфейков недостаточно полагаться на анализ отдельных пикселей изображения или видео. Современные технологии позволяют создавать манипуляции настолько реалистичными, что визуальные артефакты становятся практически незаметными. Вместо этого, требуется глубокое изучение структурных аномалий, скрытых в самой основе цифрового контента. Это включает в себя анализ несоответствий в физических моделях, таких как освещение и тени, а также выявление нелогичностей в поведении объектов и людей на видео. Исследования показывают, что анализ паттернов движения глаз, мимики и даже микровыражений может выявить манипуляции, которые остаются незамеченными при поверхностном осмотре. Такой подход позволяет перейти от поиска видимых дефектов к пониманию внутренних противоречий, что значительно повышает надежность обнаружения дипфейков и способствует восстановлению доверия к цифровой информации.
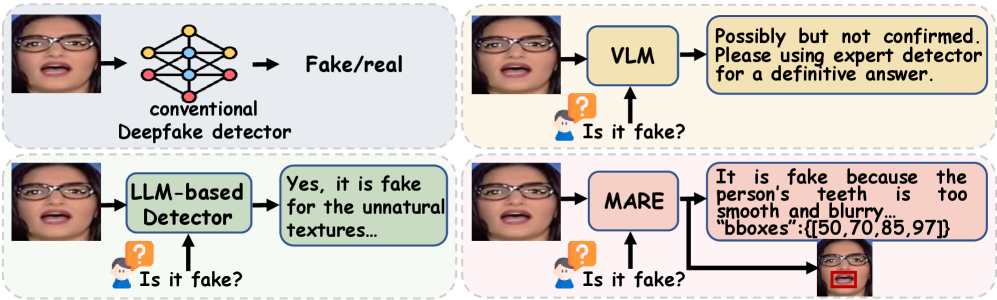
Локализация Манипуляций: Пространственная Точность и Разделение Признаков
Точное пространственное определение местоположения следов подделки внутри изображения является критически важным для достоверного обнаружения манипуляций. Неспособность точно локализовать изменения может привести к ложноположительным или ложноотрицательным результатам, особенно в сложных случаях, когда подделка включает в себя смешивание или тонкую замену пикселей. Пространственная локализация позволяет не только идентифицировать факт подделки, но и оценить степень и характер изменений, что необходимо для последующего анализа и расследования. Например, определение границ области подделки позволяет оценить размер и форму манипулированного участка, а также выявить возможные артефакты, оставленные процессом подделки.
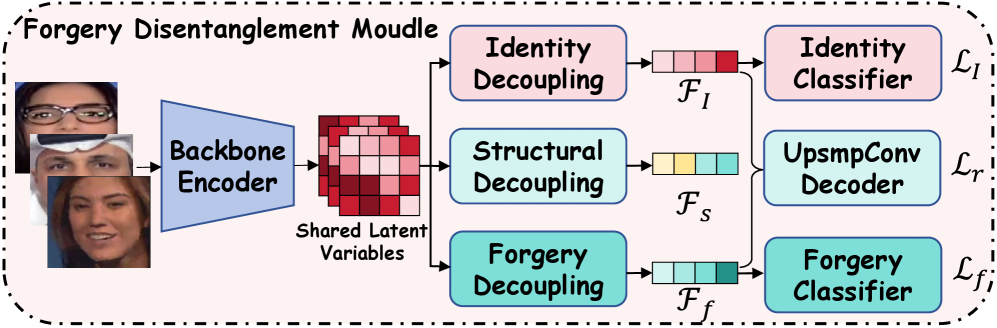
Модуль разделения подделок (FDM) предназначен для разделения признаков изображения на три основные категории: признаки идентичности (определяющие личность или объект на изображении), структурные признаки (характеристики общей композиции и геометрии изображения) и признаки, связанные с подделкой. Разделение осуществляется посредством анализа различных уровней признаков, позволяя изолировать и идентифицировать области изображения, подвергшиеся манипуляциям, от естественных элементов. Такое разделение необходимо для точного определения типов и локализации подделок, а также для повышения надежности систем обнаружения подделок, выходя за рамки простой бинарной классификации (подделка/не подделка).
Обнаружение лицевых ориентиров предоставляет важную информацию в виде ограничивающих рамок (bounding boxes), необходимую для процесса пространственной локализации манипуляций. Эти рамки точно определяют местоположение ключевых точек лица — глаз, носа, рта и углов лица — что позволяет системе выявлять несоответствия и аномалии, характерные для поддельных изображений. Данные, полученные от обнаружения лицевых ориентиров, используются для сужения области поиска следов подделки и повышения точности определения границ манипулированных участков изображения. Это особенно важно при анализе изображений лиц, где даже небольшие изменения могут быть признаками подделки.
Изоляция и анализ следов манипуляций позволяет перейти от простой бинарной классификации изображения (подделано/не подделано) к пониманию способа, которым была произведена фальсификация. Вместо определения лишь факта манипуляции, данный подход позволяет выявить конкретные типы изменений, такие как копирование-вставка, ретушь или добавление объектов, что существенно расширяет возможности анализа и предоставляет более детальную информацию о внесенных изменениях. Это позволяет не только обнаружить подделку, но и реконструировать процесс её создания, что критически важно для криминалистических экспертиз и верификации подлинности цифрового контента.
MARE: Мультимодальное Выравнивание для Надёжного Обнаружения Дипфейков
Фреймворк MARE повышает точность моделей VLM (Visual Language Models) за счет интеграции визуального и текстового рассуждений. В отличие от традиционных методов, MARE использует одновременный анализ как визуальных характеристик изображения, так и текстовых объяснений, что позволяет более эффективно выявлять признаки дипфейков. Данный подход позволил достичь передовых результатов в области обнаружения дипфейков, превосходя существующие модели по ключевым метрикам точности и надежности. В частности, фреймворк демонстрирует улучшенную способность к обобщению и устойчивость к различным видам манипуляций с изображениями и видео.
Мультимодальное выравнивание в MARE заключается в сопоставлении визуальных признаков, извлеченных из изображения или видео, с текстовыми объяснениями, описывающими признаки, указывающие на подделку. Этот процесс позволяет модели не просто идентифицировать дипфейк, но и установить связь между конкретными визуальными артефактами (например, несоответствия в освещении, неестественные движения) и текстовым обоснованием этого вывода. Сопоставление визуальной и текстовой информации повышает надежность обнаружения, снижая вероятность ложноположительных результатов и обеспечивая более устойчивую работу модели в различных условиях.
Для обучения и валидации возможностей логического вывода используется специализированный набор данных — ‘Deepfake Multimodal Alignment Dataset (DMA)’. Экспериментальные результаты демонстрируют, что разработанный фреймворк достигает наивысшей точности обнаружения дипфейков именно на этом наборе данных, превосходя существующие методы. DMA включает в себя изображения и соответствующие текстовые объяснения, позволяя модели сопоставлять визуальные признаки с логическими обоснованиями, что способствует повышению надежности и точности детекции.
В основе подхода лежит использование текстового обоснования для выявления дипфейков, что обеспечивает не только высокую точность, но и прозрачность процесса принятия решений. Метод позволяет генерировать текстовые объяснения, обосновывающие причину классификации изображения как подлинного или сфабрикованного. На тестовых наборах данных WDF (Wild Deepfake Dataset) и DFDC (Deepfake Detection Challenge) данный подход демонстрирует превосходство над существующими методами, показывая улучшенные результаты в задачах обнаружения дипфейков и обеспечивая возможность анализа логики работы системы.

Усиление Рассуждений: Обратная Связь от Людей и Функции Вознаграждения
Аннотации, полученные в результате анализа обратной связи от людей, представляют собой ценный ресурс для обучения и совершенствования способностей визуально-языковой модели к логическому мышлению. Этот процесс предполагает, что люди оценивают и комментируют рассуждения модели, указывая на ошибки или неточности, а также подтверждая верные выводы. Полученные данные используются для корректировки алгоритмов модели, позволяя ей лучше понимать контекст, выявлять противоречия и формировать более обоснованные ответы. В результате, модель не просто запоминает шаблоны, но и учится применять принципы логики и здравого смысла, что значительно повышает ее надежность и точность в решении сложных задач, особенно в контексте выявления и анализа дипфейков.
Функции вознаграждения играют ключевую роль в обучении визуально-языковых моделей (VLM) сложным навыкам, таким как точное распознавание и предоставление связных объяснений. Эти функции представляют собой математические инструменты, которые оценивают качество ответов модели, присваивая более высокие баллы за корректные и логичные результаты. По сути, они действуют как система поощрения, направляя модель к желаемому поведению посредством оптимизации. Чем точнее модель определяет поддельные изображения или чем понятнее она объясняет свои выводы, тем выше вознаграждение, что приводит к постепенному улучшению ее способностей и повышению надежности в противодействии дипфейкам. Такой подход позволяет не просто идентифицировать манипуляции, но и предоставлять пользователю аргументированное обоснование принятого решения.
Интеграция человеческого опыта с обучением с подкреплением позволяет создать самообучающуюся систему, способную к постоянному совершенствованию. В данном подходе, эксперты предоставляют оценку качества ответов и логических рассуждений модели, формируя сигнал вознаграждения. Этот сигнал, в свою очередь, направляет процесс обучения, побуждая модель к генерации более точных, последовательных и понятных результатов. В отличие от статических алгоритмов, такая система адаптируется к новым данным и постоянно улучшает свои навыки, что особенно важно в контексте быстро развивающихся технологий, таких как создание и распознавание дипфейков. Подобный симбиоз человеческого интеллекта и машинного обучения открывает перспективы для создания действительно надежных и устойчивых систем, способных эффективно противостоять дезинформации.
Постоянно совершенствующийся процесс обучения, основанный на обратной связи и подкреплении желаемого поведения, позволяет создавать системы защиты от дипфейков, отличающиеся повышенной устойчивостью и надежностью. Итеративный подход к обучению модели не только повышает ее способность точно обнаруживать манипуляции, но и способствует формированию более связных и логичных объяснений, что крайне важно для оценки достоверности контента. Благодаря этой динамической адаптации, система способна эффективно противостоять постоянно усложняющимся техникам создания дипфейков, представляя собой перспективное решение в борьбе с распространением дезинформации и фальсификаций.
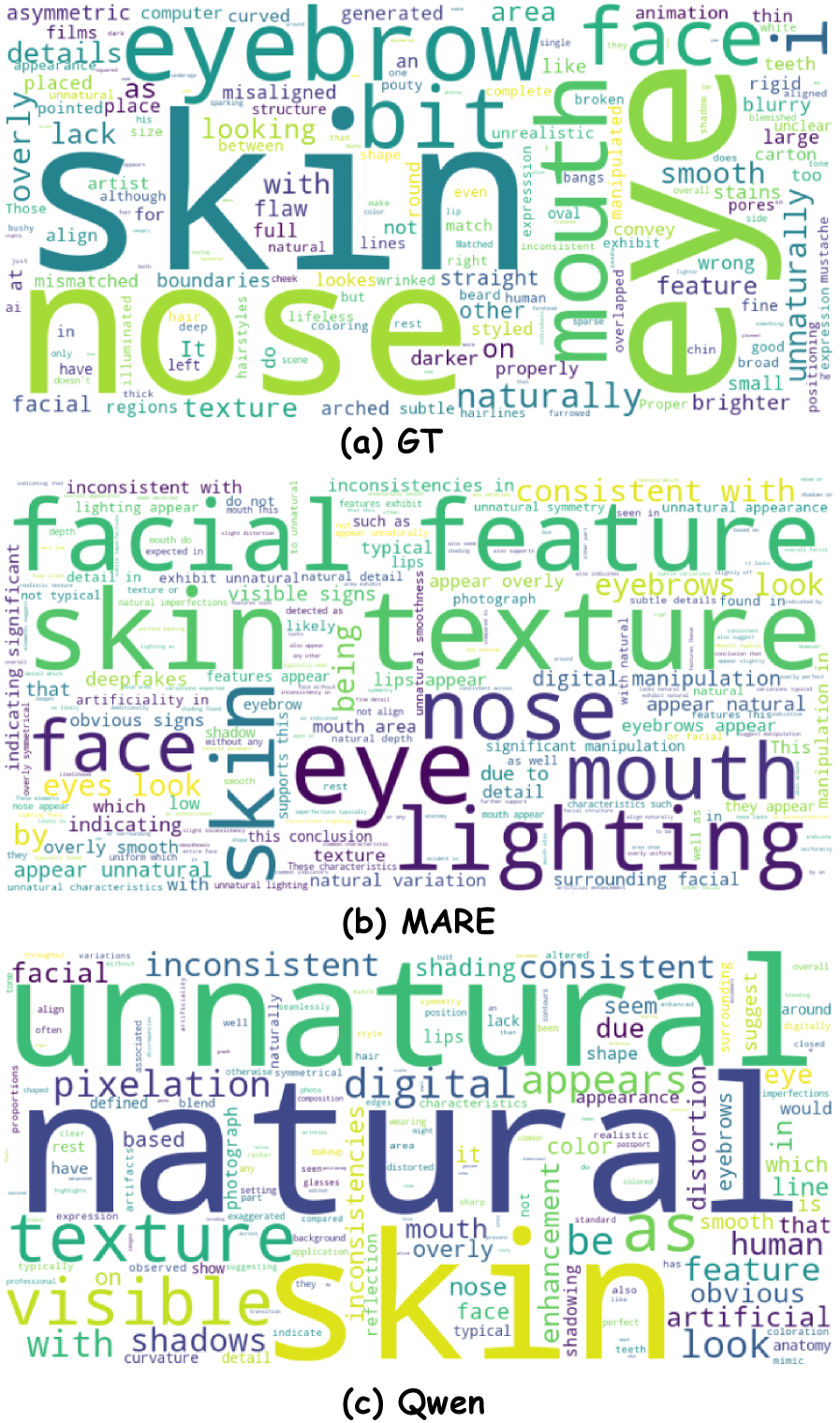
Исследование, представленное в данной работе, акцентирует внимание на важности выявления тонких признаков подделки, что перекликается с глубоким пониманием систем, лежащим в основе подхода MARE. Как однажды заметил Джеффри Хинтон: «Иногда, чтобы понять систему, нужно научиться видеть то, чего нет». Данное высказывание особенно актуально в контексте обнаружения дипфейков, где успех зависит от способности модели выявлять едва заметные артефакты и несоответствия. MARE, используя мультимодальное выравнивание и обучение с подкреплением, стремится не просто обнаружить подделку, но и предоставить пространственно-согласованное обоснование принятого решения, раскрывая скрытые закономерности и позволяя более тщательно проверить границы данных, избегая ложных интерпретаций.
Куда двигаться дальше?
Представленная работа, безусловно, демонстрирует потенциал совместного использования визуальных и языковых моделей для выявления подделок. Однако, акцент на «тонких следах» фальсификации поднимает вопрос о воспроизводимости этих следов в различных условиях. Неизбежно возникает искушение рассматривать обнаруженные закономерности как артефакты конкретной обучающей выборки, а не как универсальные индикаторы манипуляций. Необходимо уделять повышенное внимание разработке методов, устойчивых к изменениям в способах создания подделок, а не просто к их текущим проявлениям.
Перспективным направлением представляется отход от простой классификации «подделка/не подделка» в сторону более детального анализа характера манипуляций. Вместо определения факта фальсификации, система могла бы указывать на конкретные измененные области изображения или видео, а также на типы примененных манипуляций. Это потребует разработки новых метрик оценки качества, ориентированных не только на точность, но и на объяснимость и детализацию анализа.
В конечном итоге, успех в этой области будет зависеть не от достижения рекордных показателей точности, а от создания систем, способных к адаптации и критическому мышлению. Необходимо стремиться к созданию не просто детекторов подделок, а интеллектуальных помощников, способных оценить достоверность информации, учитывая контекст и возможные источники искажений. В противном случае, мы рискуем создать иллюзию безопасности, основанную на хрупких и недолговечных закономерностях.
Оригинал статьи: https://arxiv.org/pdf/2601.20433.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-01-30 04:18