Автор: Денис Аветисян
Новое исследование показывает, что изучение последнего компонента архитектуры генеративных моделей позволяет эффективно выявлять изображения, созданные искусственным интеллектом.
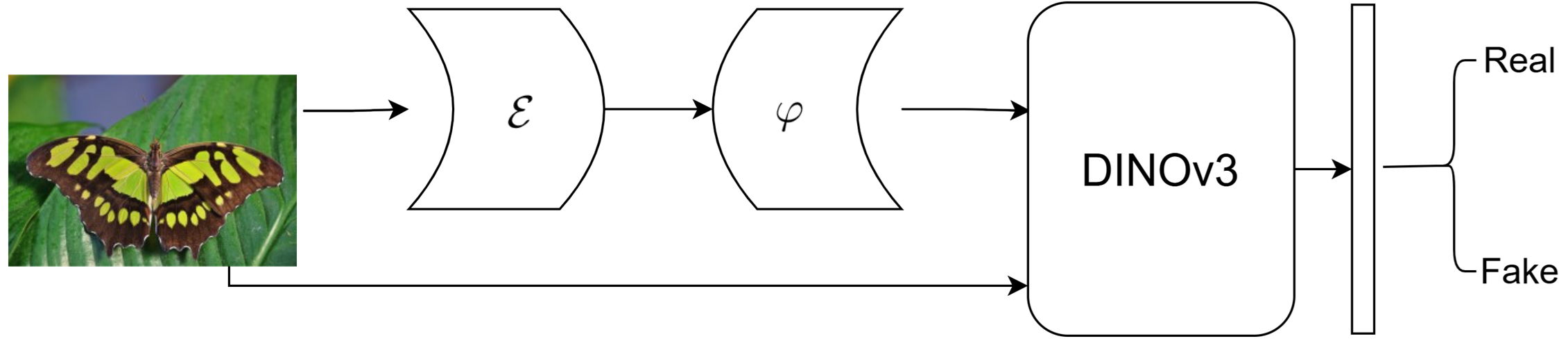
Анализ финального компонента генеративных архитектур, таких как диффузионные модели и декодеры VAE, предоставляет универсальный подход к обнаружению искусственно сгенерированных изображений.
Стремительное развитие генеративных моделей изображений ставит под угрозу достоверность визуальной информации в сети. В работе ‘Exploiting the Final Component of Generator Architectures for AI-Generated Image Detection’ предложен новый подход к обнаружению подделок, основанный на анализе финальных архитектурных компонентов генераторов изображений. Показано, что «заражение» реальных изображений этими компонентами и последующее обучение детектора позволяет достичь высокой точности — в среднем 98.83% на невидимых ранее генераторах. Может ли подобный анализ финальных компонентов стать универсальным методом выявления искусственно созданных изображений, независимым от конкретной модели генерации?
Искусство и Иллюзия: Взлёт Синтетических Изображений и Вызовы Обнаружения
Бурное развитие генеративных моделей, таких как GAN и диффузионные модели, привело к экспоненциальному росту количества синтетических изображений, способных имитировать реалистичные сцены и объекты. Это явление создает серьезную потребность в надежных методах обнаружения, способных отличить подлинные изображения от сгенерированных. Отсутствие эффективных инструментов для верификации подлинности визуального контента ставит под угрозу доверие к цифровым медиа, поскольку манипуляции с изображениями становятся все более сложными и незаметными. Разработка алгоритмов, устойчивых к усовершенствованиям в области генеративных моделей, является критически важной задачей для сохранения целостности информационного пространства и предотвращения распространения дезинформации.
Традиционные методы цифровой криминалистики изображений оказываются всё менее эффективными в выявлении контента, созданного искусственным интеллектом. Ранее полагавшиеся на анализ шумов, артефактов сжатия и других статистических характеристик, эти методы теперь сталкиваются с изображениями, генерируемыми моделями, которые умело имитируют реалистичные детали и избегают типичных следов манипуляций. Это создает серьезную уязвимость для цифровых пространств, поскольку фальсифицированные изображения могут использоваться для распространения дезинформации, подрыва доверия к средствам массовой информации и даже для нанесения вреда репутации отдельных лиц и организаций. Неспособность надежно отличить реальные изображения от сгенерированных искусственно представляет собой растущую проблему, требующую разработки принципиально новых подходов к обнаружению подделок.
Масштабные наборы данных, такие как MS-COCO, играют ключевую роль в развитии и оценке моделей генерации и обнаружения синтетических изображений. Они обеспечивают необходимую базу для обучения алгоритмов, позволяя им распознавать сложные паттерны и детали, характерные для реальных и искусственно созданных изображений. По мере увеличения объемов и сложности генерируемого контента, потребность в более совершенных методах обнаружения возрастает, что, в свою очередь, стимулирует создание еще более крупных и разнообразных наборов данных для обучения. Этот замкнутый цикл развития требует постоянного улучшения как генеративных моделей, так и алгоритмов обнаружения, опирающихся на постоянно растущие объемы размеченных данных, что делает MS-COCO и подобные ему ресурсы незаменимыми инструментами в борьбе с манипуляциями в цифровом пространстве.
Деконструкция Генеративных Архитектур: Путь к Обнаружению
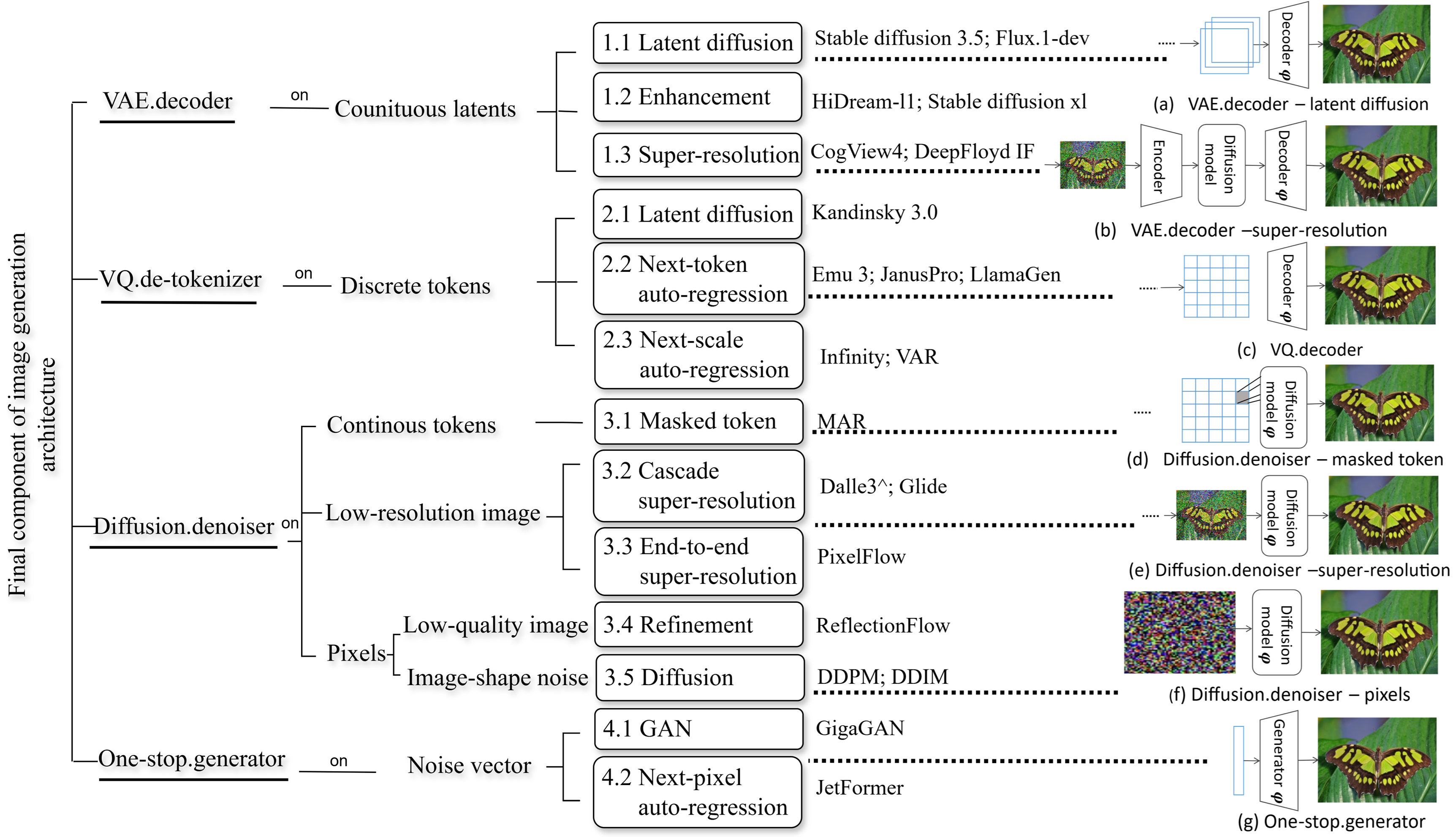
Различные генеративные архитектуры, такие как генеративно-состязательные сети (GAN), диффузионные модели и авторегрессионные модели, оставляют уникальные, обнаруживаемые следы в генерируемых ими изображениях. Эти следы проявляются в статистических особенностях пикселей, частотных характеристиках и структуре артефактов. Например, GAN часто демонстрируют специфические шаблоны шума и нереалистичные текстуры, в то время как диффузионные модели могут оставлять следы процесса шумоподавления, проявляющиеся в размытости или неестественных переходах. Авторегрессионные модели, генерируя изображения последовательно, склонны к определенным типам ошибок в прогнозировании пикселей, что также формирует уникальный «отпечаток». Анализ этих отличий позволяет разработать методы для определения, какой именно генеративной моделью было создано конкретное изображение.
Финальный компонент генеративных архитектур — будь то декодер VAE, диффузор сверхвысокого разрешения или VQ-декодировщик — оказывает существенное влияние на формирование детектируемых характеристик генерируемых изображений. Этот компонент отвечает за преобразование латентного представления в видимое изображение, и особенности его реализации, включая используемые фильтры, архитектуру нейронной сети и параметры дискретизации, непосредственно проявляются в конечном результате. Например, артефакты, связанные с апскейлингом, характерные для диффузионных моделей сверхвысокого разрешения, или специфические паттерны квантования, возникающие при использовании VQ-декодировщиков, могут служить надежными индикаторами для определения типа используемой генеративной модели. Таким образом, анализ выходных данных финального компонента позволяет выявить уникальные “отпечатки пальцев”, присущие каждой архитектуре.
Анализ характеристик финального компонента генеративной модели — будь то декодер VAE, диффузор для повышения разрешения или VQ-декодировщик — позволяет сформировать “Пространство Следов”, состоящее из идентифицируемых признаков, специфичных для данной модели. Это пространство представляет собой многомерное векторное представление, отражающее статистические особенности выходных данных финального компонента. Ключевыми параметрами для формирования этого пространства являются: статистические характеристики пикселей (среднее, дисперсия, энтропия), частотный спектр, а также специфичные артефакты, возникающие в процессе генерации. Различные архитектуры демонстрируют различные статистические профили в этом пространстве, что позволяет разработать алгоритмы для их точной идентификации и, как следствие, обнаружения сгенерированных изображений.
Нулевое Обучение: Использование Извлечения Признаков и Кластеризации
Эффективное обнаружение объектов в условиях нулевого обучения напрямую зависит от качества извлечения признаков. В качестве основы для этого часто используются предварительно обученные визуальные модели, такие как DINOv3. DINOv3, обученная на масштабных датасетах изображений, способна генерировать информативные векторные представления изображений, которые отражают семантическое содержание. Эти представления, полученные посредством переноса обучения, служат основой для последующей классификации и позволяют модели обобщать знания на новые, ранее невиданные классы объектов без необходимости дополнительной тонкой настройки. Использование robust признаков, полученных от DINOv3, критически важно для достижения высокой точности и надежности в задачах zero-shot detection.
Кластеризация K-медоидов используется для определения репрезентативных образцов в пространстве извлеченных признаков, что повышает эффективность обучения модели. В отличие от K-средних, K-медоиды использует фактические точки данных в качестве центроидов кластеров (медоидов), что делает алгоритм более устойчивым к выбросам и позволяет более точно определить границы между кластерами. Выбор медоидов осуществляется путем минимизации суммы расстояний от всех точек в кластере до выбранного медоида. Использование K-медоидов позволяет уменьшить вычислительную сложность и ускорить процесс обучения, особенно при работе с большими наборами данных, поскольку уменьшается количество образцов, требующих детального анализа при классификации.
Для дифференциации между реальными и сгенерированными изображениями используется бинарный классификатор, обученный с применением функции потерь Cross-Entropy. Этот классификатор функционирует на основе признаков, извлеченных на предыдущих этапах, и определяет вероятность принадлежности входного изображения к одному из двух классов: «реальное» или «сгенерированное». Функция Cross-Entropy минимизирует разницу между предсказанными вероятностями и фактической меткой класса, оптимизируя параметры классификатора для повышения точности распознавания. В процессе обучения, классификатор настраивается для эффективного разделения признаковых пространств, характерных для реальных и сгенерированных изображений.
Оценка Производительности Детектора и Более Широкие Последствия
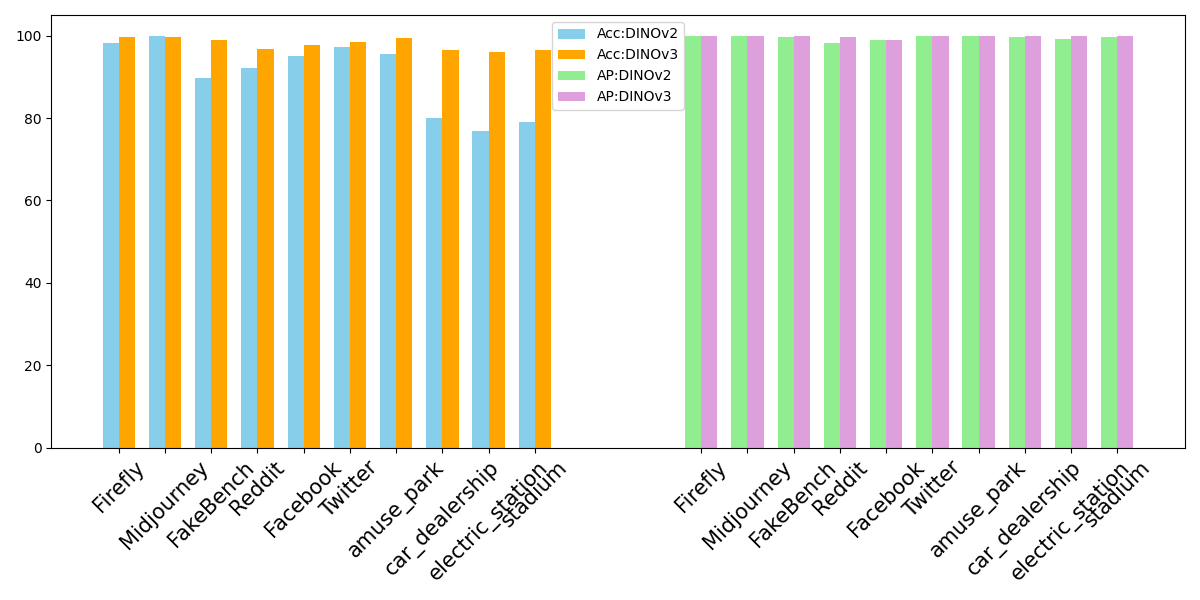
Для оценки эффективности разработанного детектора изображений, созданных искусственным интеллектом, применялись такие метрики, как Average Precision и Detection Accuracy. Average Precision позволяет оценить точность определения релевантных изображений среди всех отобранных, а Detection Accuracy — общую долю правильно классифицированных изображений. Эти показатели дают комплексное представление о способности детектора надежно различать подлинные изображения от сгенерированных, что критически важно для различных приложений, от защиты авторских прав до выявления дипфейков. Тщательный анализ по этим метрикам позволил объективно оценить производительность детектора и сравнить ее с существующими подходами, подтверждая его высокую эффективность и надежность.
Предложенный подход к обнаружению изображений, сгенерированных искусственным интеллектом, демонстрирует высокую эффективность, достигая точности до 99.22%. Этот результат на 2% превосходит показатели, полученные при использовании парного обучения, что свидетельствует о значительном улучшении в алгоритме классификации. Достигнутая точность позволяет надежно отличать сгенерированные изображения от реальных, открывая возможности для автоматизированной проверки контента и борьбы с распространением дезинформации. Повышенная эффективность алгоритма, в свою очередь, обусловлена оптимизацией процесса обучения и более эффективным использованием доступных данных, что делает его перспективным инструментом для широкого спектра приложений.
Разработанный детектор демонстрирует высокую способность к обобщению, успешно идентифицируя изображения, созданные различными генеративными моделями, включая те, что подверглись дополнительной настройке. Результаты тестирования на нескольких общепринятых бенчмарках показывают стабильное превосходство над базовыми методами, подтвержденное высокими значениями Average Precision. Это указывает на надежность детектора в условиях разнообразия генеративных алгоритмов и его способность эффективно адаптироваться к новым, модифицированным моделям, что крайне важно для практического применения в задачах выявления синтетических изображений.
Исследование демонстрирует элегантную простоту подхода к обнаружению искусственно сгенерированных изображений. Анализ финального компонента генеративных архитектур, как показано в работе, позволяет выявить следы машинного происхождения, не завися от конкретной модели генератора. Это подчеркивает важность глубокого понимания внутренней структуры систем искусственного интеллекта. Как однажды заметил Джеффри Хинтон: «Я думаю, что сейчас мы можем обучать нейронные сети делать много разных вещей, но мы не понимаем, как они это делают». Данное исследование, фокусируясь на финальном компоненте, приближает нас к пониманию принципов работы этих сложных систем и, следовательно, к созданию более надежных методов обнаружения дипфейков и других форм сгенерированного контента.
Что Дальше?
Представленное исследование, демонстрируя эффективность анализа финальных компонентов генеративных архитектур для обнаружения искусственно созданных изображений, открывает, скорее, не решение, а приглашение к дальнейшим размышлениям. Успех подхода, независимого от конкретной реализации генератора, указывает на универсальную слабость — неизбежный след присутствия алгоритма в конечном продукте. Однако, данная “универсальность” не должна усыплять бдительность. Улучшение генеративных моделей, несомненно, приведет к утончению этих следов, требуя от методов обнаружения все большей чувствительности и изобретательности.
Особый интерес представляет исследование возможности применения аналогичных подходов к другим модальностям — аудио, видео, тексту. Принцип, заключающийся в выявлении «отпечатков пальцев» алгоритма, кажется применимым повсеместно, но его реализация потребует глубокого понимания специфики каждой модальности. Необходимо учитывать, что элегантность решения не в сложности алгоритма обнаружения, а в его способности выделять истинное из искусственного, не усложняя при этом процесс восприятия.
В конечном счете, вопрос не в том, сможем ли мы всегда обнаруживать подделки, а в том, как мы будем относиться к их неизбежному появлению. Истина, возможно, не в преследовании абсолютной достоверности, а в развитии критического мышления и способности видеть за фасадом цифровой иллюзии реальную ценность информации.
Оригинал статьи: https://arxiv.org/pdf/2601.20461.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-01-29 23:26