Автор: Денис Аветисян
Исследователи предлагают инновационный метод, основанный на анализе дистанции между текстами, для точного определения, создан ли текст человеком или искусственным интеллектом.
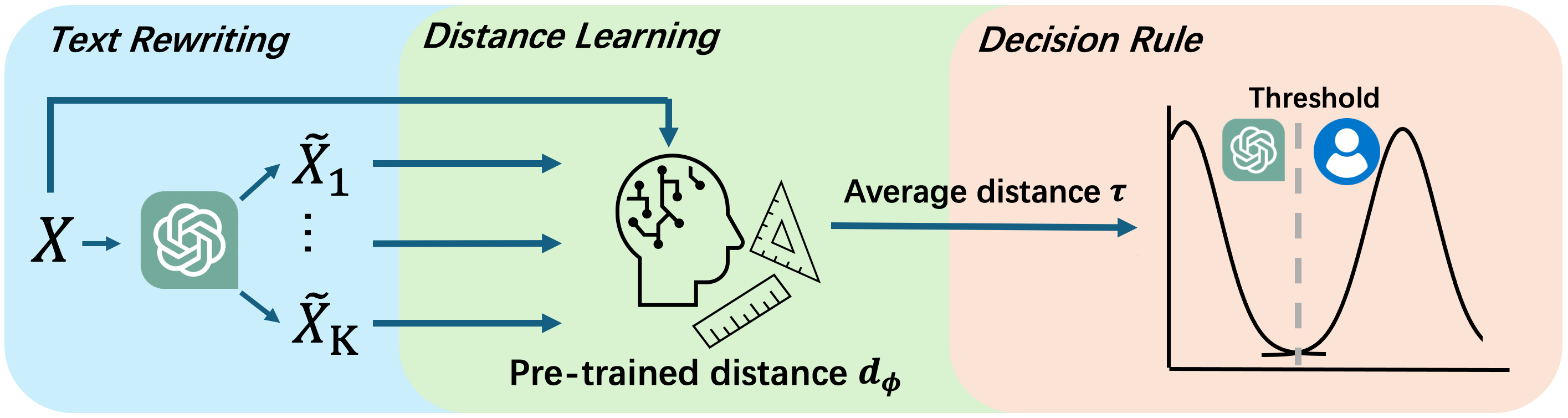
В статье представлена адаптивная функция расстояния, позволяющая эффективно и устойчиво обнаруживать текст, созданный большими языковыми моделями, и противостоять попыткам обхода.
Современные генеративные языковые модели, демонстрируя впечатляющую способность создавать правдоподобные тексты, одновременно создают серьезные вызовы для обеспечения достоверности информации и академической честности. В данной работе, озаглавленной ‘Learn-to-Distance: Distance Learning for Detecting LLM-Generated Text’, предложен новый подход к обнаружению текстов, сгенерированных большими языковыми моделями, основанный на адаптивном обучении метрики расстояния между исходным текстом и его перефразировкой. Теоретически обосновано и экспериментально подтверждено, что использование обучаемой функции расстояния позволяет достичь более высокой точности обнаружения по сравнению с фиксированными метриками. Сможет ли предложенный метод стать надежным инструментом для борьбы с распространением дезинформации и обеспечения целостности образовательного процесса?
Искусство и Иллюзия: Эволюция Генерации Текста и Вызовы Обнаружения
Современные большие языковые модели (БЯМ) демонстрируют поразительную способность генерировать текст, который все труднее отличить от созданного человеком. Эти модели, обученные на огромных объемах текстовых данных, способны не только воспроизводить грамматически правильные предложения, но и имитировать различные стили письма, адаптироваться к разным темам и даже проявлять признаки креативности. Такой прогресс приводит к размыванию границ между человеческим и машинным авторством, вызывая серьезные вопросы о подлинности контента и требуя разработки новых методов для определения источника текста. Способность БЯМ генерировать убедительный контент открывает как широкие возможности для автоматизации и творчества, так и риски, связанные с распространением дезинформации и манипуляциями.
Традиционные методы обнаружения текстов, созданных искусственным интеллектом, все чаще оказываются неэффективными в связи с быстрым развитием больших языковых моделей. Алгоритмы, основанные на анализе стилистических особенностей, частоты употребления определенных слов или грамматических конструкций, легко обманываются все более сложными и реалистичными текстами, генерируемыми современными LLM. Это создает серьезную проблему для поддержания достоверности информации в сети, поскольку становится все труднее отличить авторский текст от сгенерированного машиной. В связи с этим, возникает настоятельная потребность в разработке новых, более устойчивых методов обнаружения, использующих, например, анализ вероятностных характеристик текста или выявление скрытых закономерностей, несвойственных человеческому письму. Успешное решение этой задачи критически важно для предотвращения распространения дезинформации и защиты от злонамеренного использования сгенерированного контента.
Сохранение доверия к информации, распространяемой в сети, становится все более сложной задачей в связи с распространением текстов, созданных языковыми моделями. Способность искусственного интеллекта генерировать убедительные тексты открывает возможности для злоупотреблений, включая распространение дезинформации, создание фальшивых новостей и манипулирование общественным мнением. Выявление текстов, созданных искусственным интеллектом, необходимо для защиты от этих угроз и обеспечения достоверности информации, доступной пользователям. Это особенно важно в сферах, где точность и надежность данных имеют решающее значение, таких как журналистика, образование и научные исследования. Разработка эффективных методов обнаружения сгенерированного текста, таким образом, является ключевым элементом поддержания информационной безопасности и предотвращения негативных последствий, связанных с использованием искусственного интеллекта в недобросовестных целях.

Перефразирование как Ключ: Новый Подход к Детекции
Метод обнаружения на основе перефразирования заключается в незначительной модификации исходного текста и последующем сравнении оригинала с измененной версией. Суть подхода состоит в том, что алгоритмы машинного перевода и генерации текста демонстрируют иную чувствительность к перефразировке, чем текст, написанный человеком. Это позволяет выявить различия в структуре и лексике, возникающие при перефразировке, и использовать их для различения машинного и человеческого текста. Эффективность метода напрямую зависит от выбора стратегии перефразирования и используемых лингвистических инструментов.
В основе детекции на основе перефразирования лежит предположение о различной устойчивости машинного и человеческого текста к незначительным изменениям формулировок. Машинно-сгенерированные тексты, как правило, демонстрируют большую чувствительность к перефразированию, поскольку они часто создаются на основе статистических закономерностей и могут содержать менее гибкие языковые конструкции. В то время как тексты, написанные людьми, обладают большей семантической и синтаксической вариативностью, что позволяет им сохранять смысл даже после незначительных изменений. Данное различие в поведении и используется для идентификации текстов, созданных искусственным интеллектом.
Для реализации детекции на основе перефразирования необходимо определить метрику расстояния, количественно оценивающую разницу между исходным и перефразированным текстом. Доступны как фиксированные, так и адаптивные варианты таких метрик. Фиксированные метрики, такие как расстояние Левенштейна или косинусное сходство, применяются непосредственно к тексту. Адаптивные метрики, напротив, могут учитывать контекст и специфику перефразирования, например, с помощью моделей машинного обучения, обученных на парах “оригинал-перефразировка”. Выбор метрики влияет на чувствительность и точность детектора, поэтому требуется тщательная оценка и настройка для конкретной задачи и типа генерируемого текста.
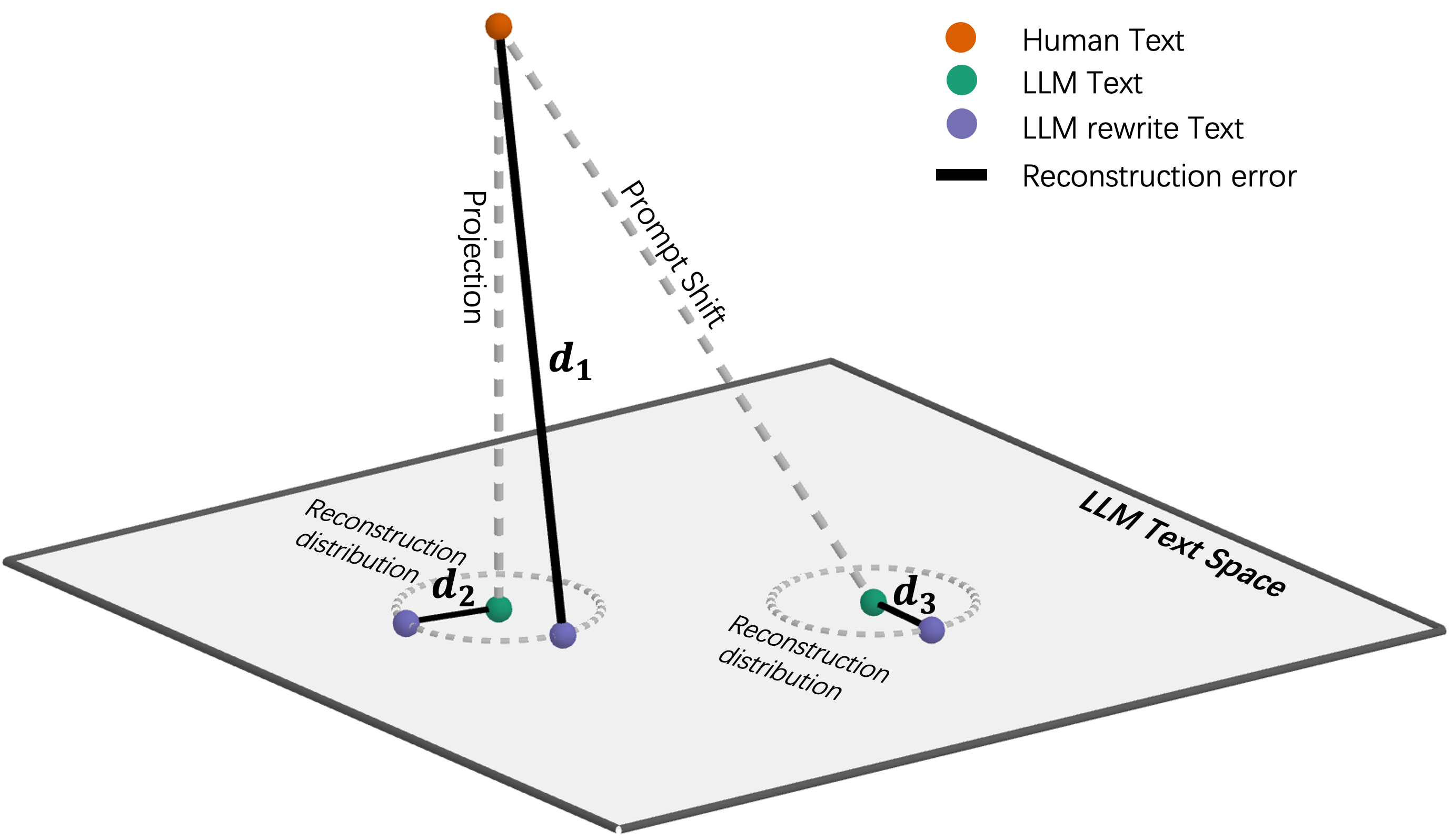
Адаптивные Функции Дистанции: Точность и Гибкость
Адаптивная функция дистанции обучается оптимальному способу измерения различий между версиями текста, что значительно повышает точность обнаружения. В отличие от фиксированных метрик, которые применяют единый критерий оценки, адаптивные функции динамически корректируют процесс вычисления дистанции на основе анализа данных. Этот процесс обучения позволяет учитывать специфические характеристики как человеческого, так и машинного письма, выявляя более тонкие различия и снижая вероятность ложных срабатываний. В результате, такие функции демонстрируют повышенную эффективность в задачах, требующих точного определения изменений в тексте, например, при обнаружении плагиата или автоматическом контроле версий.
Процесс обучения адаптивной функции расстояния основывается на применении оператора проекции и анализе ошибки реконструкции для уточнения расчета различий между текстовыми версиями. Оператор проекции позволяет определить оптимальное представление текста в некотором пространстве признаков, минимизируя расхождение между исходным текстом и его проекцией. Ошибка реконструкции, измеряющая разницу между исходным текстом и его восстановленной версией после проекции, используется как метрика для корректировки параметров функции расстояния. Итеративное применение этих концепций позволяет функции адаптироваться к специфике как человеческого, так и машинного письма, повышая точность определения различий и снижая вероятность ложноположительных результатов. Error = ||x - \hat{x}||^2, где x — исходный текст, а \hat{x} — его реконструкция.
Адаптивные функции дистанции демонстрируют превосходство над традиционными, фиксированными метриками при оценке различий между текстовыми версиями. В ходе тестирования, эти функции обеспечили среднее относительное улучшение в диапазоне от 57.8% до 80.6% по сравнению с наиболее эффективной базовой моделью. При сравнении с использованием фиксированной функции дистанции, адаптивные функции показали увеличение точности на 97.1%, что свидетельствует о значительном повышении эффективности в задачах, требующих точного определения различий между текстами, созданными человеком и машиной.
Уязвимость Систем: Атаки и Необходимость Устойчивости
Современные методы выявления текстов, сгенерированных большими языковыми моделями, оказались уязвимыми перед так называемыми «атаками противника». Исследования показывают, что даже незначительные, едва заметные изменения в тексте, такие как перефразирование или намеренное внесение незначительной «некогерентности», способны обмануть большинство существующих детекторов. Эти атаки, разработанные для имитации человеческого стиля письма, эксплуатируют слабые места в алгоритмах, полагающихся на статистические закономерности или поверхностные лингвистические признаки. Результаты демонстрируют, что даже самые продвинутые системы могут быть введены в заблуждение, что подчеркивает необходимость разработки более надежных и устойчивых методов обнаружения, способных распознавать манипулированные тексты и отличать их от подлинных.
Атакующие методы, такие как перефразирование и дескогерентные атаки, незаметно изменяют текст, сгенерированный большими языковыми моделями (LLM), стремясь имитировать особенности человеческой речи. Эти манипуляции, как правило, включают в себя незначительные изменения в структуре предложений, замену синонимов и добавление небольших грамматических вариаций, которые остаются практически незаметными для человека. В результате, сгенерированный текст становится сложнее отличить от написанного человеком, что позволяет обходить существующие системы обнаружения, основанные на анализе стилистических особенностей или статистических закономерностей, характерных для машинного текста. Именно эта способность адаптироваться и маскироваться делает подобные атаки особенно опасными и подчеркивает необходимость разработки более совершенных и устойчивых методов выявления текстов, созданных искусственным интеллектом.
Появление атак, направленных на обход систем обнаружения, таких как перефразирование и дескогерентные атаки, подчеркивает критическую необходимость в разработке более устойчивых и надежных методов. Существующие инструменты, ориентированные на выявление признаков, характерных для машинного генерирования текста, оказываются уязвимыми перед намеренными, но едва заметными изменениями. Это указывает на то, что будущие системы должны основываться не только на статистических аномалиях, но и на глубоком семантическом анализе, способном различать истинный человеческий текст и искусственно измененный, имитирующий его. Разработка алгоритмов, устойчивых к манипуляциям, становится ключевым фактором в обеспечении достоверности информации и противодействии злонамеренному использованию языковых моделей.

За пределами Сравнения: Детекция «Из Коробки» и Будущее Развития
Метод определения текста, сгенерированного искусственным интеллектом, без использования размеченных обучающих данных, представляет собой перспективное направление исследований. В отличие от традиционных подходов, требующих обширных наборов данных для обучения моделей, данный метод позволяет идентифицировать машинный текст, опираясь на внутренние характеристики языковых моделей и статистические закономерности, присущие генерируемому ими тексту. Это особенно важно в условиях быстрого развития больших языковых моделей и необходимости оперативно выявлять автоматизированно созданный контент, не тратя ресурсы на сбор и аннотацию данных. Возможность распознавания машинного текста «из коробки», без предварительного обучения, открывает широкие перспективы для применения в различных областях, включая борьбу с дезинформацией, проверку подлинности контента и обеспечение достоверности информации в цифровой среде.
Для выявления текстов, сгенерированных большими языковыми моделями (LLM), применяются различные методы, основанные на анализе статистических закономерностей в выходных данных. Подходы, такие как обнаружение на основе логитов (Logits-Based Detection), исследуют распределение вероятностей, присваиваемых моделью различным токенам, выявляя характерные особенности, отличающие машинный текст от написанного человеком. Параллельно разрабатываются методы машинного обучения (Machine Learning-Based Detection), которые обучаются на косвенных признаках, таких как сложность синтаксиса или специфические лексические паттерны, чтобы автоматически классифицировать текст как сгенерированный моделью или написанный человеком. Эти методы позволяют идентифицировать неявные «следы» машинного авторства, даже без наличия размеченных обучающих данных, что делает их особенно ценными в условиях быстрого развития технологий генерации текста.
Непрерывные исследования в области разработки надежных методов обнаружения и, одновременно, изучение потенциальных атак, направленных на обход этих методов, представляются крайне важными для сохранения доверия к информации в цифровую эпоху. Представленный подход демонстрирует высокую эффективность, достигая показателя площади под кривой ROC (AUC) до 92%, что указывает на способность точно различать текст, созданный человеком, и сгенерированный языковыми моделями. Дальнейшее углубление в эту область позволит не только совершенствовать существующие инструменты обнаружения, но и предвидеть и нейтрализовать новые, более изощренные методы обмана, обеспечивая тем самым целостность информационного пространства.
Предложенный подход к обнаружению текстов, сгенерированных большими языковыми моделями, отличается лаконичностью и эффективностью. Авторы фокусируются на адаптивном определении расстояния между текстами, что позволяет не только точно идентифицировать искусственно созданный контент, но и успешно противостоять попыткам обхода защиты. Это соответствует принципу, сформулированному Джоном фон Нейманом: «В науке нет ничего абсолютного, только относительное». Подобно тому, как расстояние между текстами определяется адаптивно, так и оценка подлинности текста требует гибкого подхода, учитывающего контекст и особенности генерации. Акцент на устойчивости к adversarial attacks подчеркивает важность постоянного совершенствования методов обнаружения, чтобы опережать развитие генеративных моделей.
Куда Далее?
Предложенный подход, основанный на адаптивном определении расстояния между текстами, демонстрирует устойчивость к известным атакам. Однако, абстракции стареют. Устойчивость — не абсолют. Неизбежно появятся новые методы генерации, новые способы обхода детекторов. Требуется не просто улучшать существующие метрики, а искать принципиально иные подходы к определению «подлинности» текста. Каждая сложность требует алиби.
Особое внимание следует уделить анализу семантических изменений, вносимых при переписывании. Простое сравнение поверхностных характеристик текста — недостаточный критерий. Необходимо учитывать контекст, намерения автора, тон повествования. Более того, стоит задаться вопросом: действительно ли цель — обнаружение «машинного» текста, или же поиск любых признаков манипуляции и дезинформации?
Следующий этап — переход от бинарной классификации (“сгенерирован” или “не сгенерирован”) к оценке степени вероятности машинного происхождения текста. Это позволит не только обнаруживать подделки, но и оценивать качество генерации, что критически важно для развития самих генеративных моделей. И, конечно, необходимо помнить: совершенство достигается не когда нечего добавить, а когда нечего убрать.
Оригинал статьи: https://arxiv.org/pdf/2601.21895.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-02-01 01:51