Автор: Денис Аветисян
Новое исследование показывает, что современные методы машинного обучения позволяют с высокой точностью определять тексты, сгенерированные нейросетями.
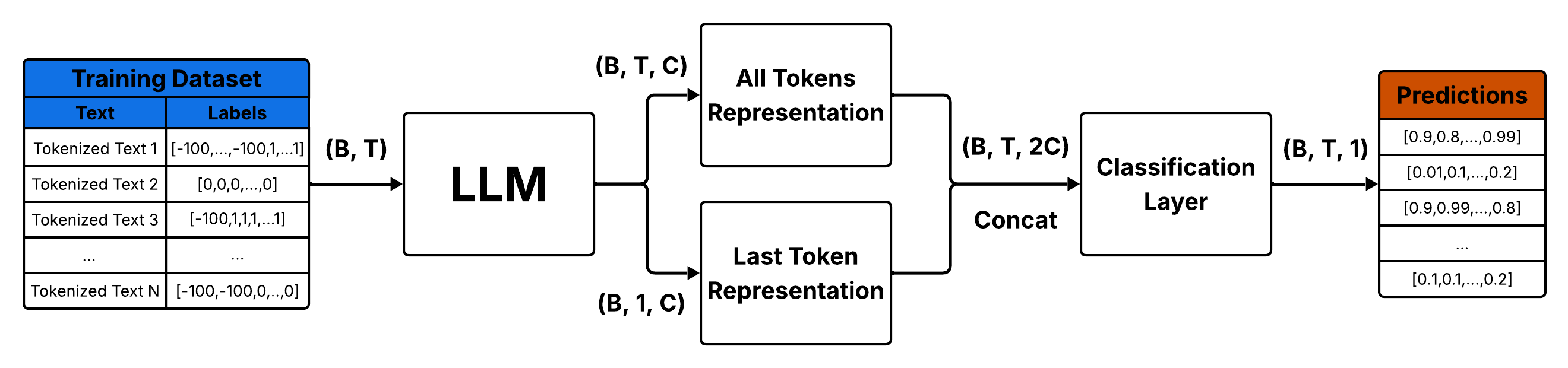
Оценка эффективности тонкой настройки больших языковых моделей для классификации текста, созданного искусственным интеллектом.
Стремительное развитие больших языковых моделей (LLM) создало парадокс: текст, неотличимый от созданного человеком, требует новых подходов к верификации подлинности. В работе, озаглавленной ‘On the Effectiveness of LLM-Specific Fine-Tuning for Detecting AI-Generated Text’, проведено всестороннее исследование методов выявления текстов, сгенерированных искусственным интеллектом, с использованием масштабных корпусов данных и инновационных стратегий обучения. Показано, что специализированная настройка LLM позволяет достичь высокой точности обнаружения, до 99.6\% на уровне отдельных токенов, значительно превосходя существующие открытые решения. Какие перспективы открываются для дальнейшего совершенствования моделей и разработки надежных инструментов защиты от злоупотреблений в сфере цифрового контента?
Растущая сложность: Искусственный интеллект и выявление сгенерированного текста
Современные большие языковые модели (БЯМ) демонстрируют поразительную способность генерировать текст, практически неотличимый от написанного человеком. Этот прогресс обусловлен развитием глубокого обучения и увеличением объемов данных, используемых для тренировки моделей. В результате, БЯМ способны не только имитировать стиль и тон человеческой речи, но и создавать оригинальные тексты, отвечающие заданным параметрам. Размывание границ между авторством человека и машины поднимает важные вопросы об аутентичности контента, авторских правах и необходимости разработки эффективных инструментов для выявления текстов, созданных искусственным интеллектом. Подобные модели уже сегодня способны генерировать статьи, эссе, сценарии и даже программный код, что ставит перед обществом новые вызовы и возможности.
В связи с растущей способностью языковых моделей генерировать тексты, практически неотличимые от созданных человеком, возникла острая необходимость в разработке надежных методов выявления текстов, сгенерированных искусственным интеллектом. Данная потребность обусловлена серьезными опасениями, касающимися распространения дезинформации, плагиата и подделки информации. Выявление машинного происхождения текста становится критически важным для поддержания достоверности контента в различных сферах, включая журналистику, научные исследования и образование. Эффективные инструменты обнаружения помогут обеспечить прозрачность и ответственность в эпоху, когда границы между человеческим и машинным творчеством стираются, позволяя отличать оригинальный контент от сгенерированного, и тем самым защитить целостность информации.
Традиционные методы обнаружения текстов, созданных искусственным интеллектом, оказываются все менее эффективными в связи с непрерывным развитием больших языковых моделей (LLM). Алгоритмы, основанные на анализе стилистических особенностей, частотности определенных слов или грамматических конструкций, легко обходятся новыми версиями LLM, способными имитировать человеческий стиль письма с высокой точностью. Это требует разработки принципиально новых подходов к обнаружению машинного происхождения текста, например, основанных на анализе «цифровых отпечатков» LLM, выявлении статистических аномалий в структуре текста или использовании методов машинного обучения, способных адаптироваться к изменяющимся характеристикам генерируемого контента. Актуальные исследования направлены на создание систем, способных не просто выявлять признаки автоматической генерации, но и определять конкретную модель, использованную для создания текста, что позволит более эффективно бороться с распространением дезинформации и плагиата.
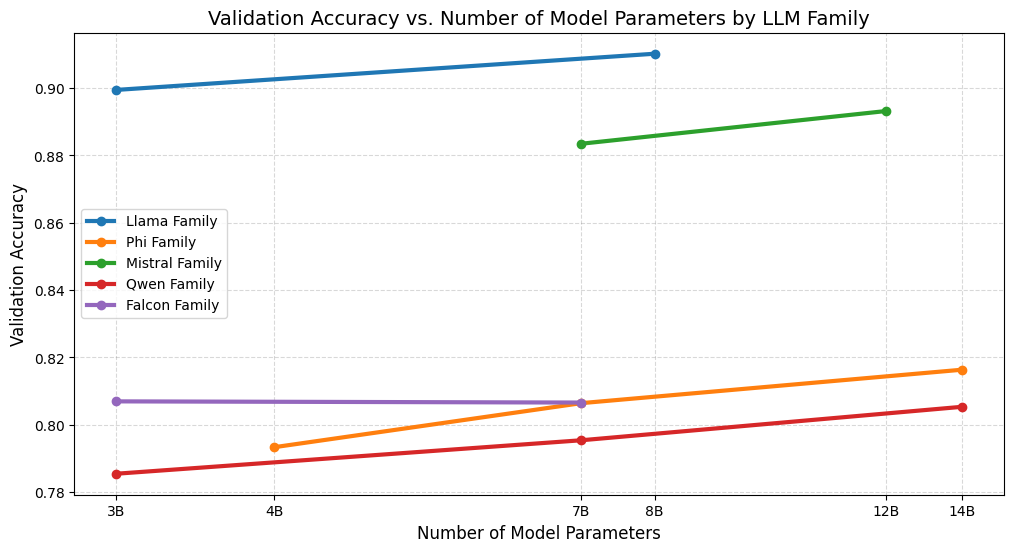
Тонкая настройка LLM: Мощный инструмент обнаружения
Тонкая настройка больших языковых моделей (LLM) предполагает обучение предварительно обученных моделей на специализированных наборах данных, содержащих как тексты, написанные человеком, так и сгенерированные искусственным интеллектом. Этот процесс позволяет LLM развивать способность различать эти два типа текста, что достигается путем корректировки внутренних параметров модели на основе предоставленных примеров. Обучение проводится с использованием алгоритмов контролируемого обучения, где модель учится сопоставлять входные тексты с соответствующими метками, указывающими на их происхождение — человеческое или машинное. Эффективность тонкой настройки напрямую зависит от качества и разнообразия обучающего набора данных, а также от выбора архитектуры модели и параметров обучения.
Для эффективной дообучения больших языковых моделей (LLM) необходим надежный конвейер обработки данных, включающий сбор, очистку и подготовку обучающих данных. Этот процесс часто включает в себя промпт-инжиниринг — разработку и использование разнообразных запросов (промптов) для генерации широкого спектра примеров текста, как созданных человеком, так и искусственным интеллектом. Разнообразие примеров, полученных с помощью промпт-инжиниринга, критически важно для повышения способности модели различать эти два типа текста и обеспечивает более точную классификацию.
Эффективность дообучения больших языковых моделей (LLM) напрямую зависит от используемых алгоритмов оптимизации, в частности, Adam Optimizer, который обеспечивает адаптивную настройку параметров модели. В задачах токельной классификации, где необходимо определить, сгенерирован ли каждый токен человеком или искусственным интеллектом, в качестве функции потерь часто применяется Binary Cross-Entropy Loss. Данная функция измеряет разницу между предсказанными вероятностями и фактическими метками для каждого токена, позволяя алгоритму оптимизации корректировать веса модели для минимизации ошибки и повышения точности классификации. Выбор функции потерь и алгоритма оптимизации критически важен для достижения оптимальных результатов при дообучении LLM для задач определения авторства текста.
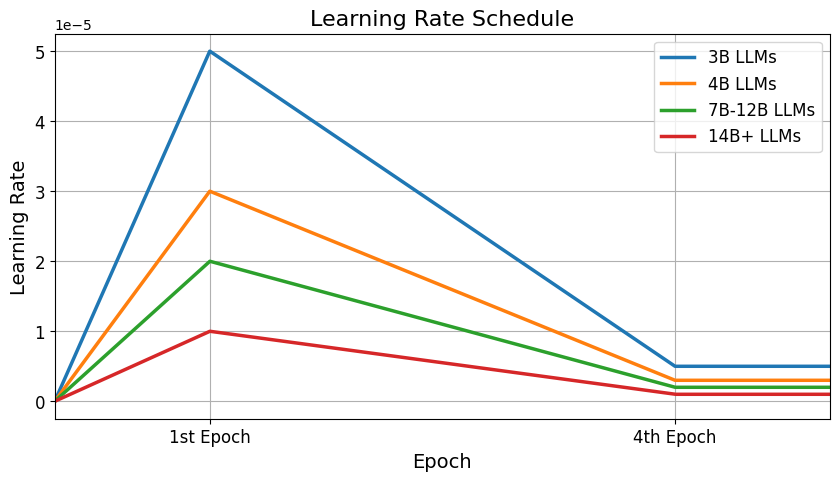
Оптимизация тонкой настройки: Подходы «Per LLM» и «Per LLM Family»
В настоящее время исследуются два основных подхода к тонкой настройке больших языковых моделей (LLM): индивидуальная настройка (Per LLM Fine-tuning) и настройка семейства моделей (Per LLM Family Fine-tuning). В первом случае каждая LLM обучается выявлять текст, сгенерированный именно ею. Второй подход предполагает, что модели внутри одного семейства обучаются обнаруживать выходные данные любой модели, входящей в это же семейство. Такая стратегия позволяет учитывать уникальные стилистические особенности и уязвимости каждой модели или семейства моделей, повышая эффективность обнаружения сгенерированного текста.
Каждая большая языковая модель (LLM) характеризуется уникальным стилистическим отпечатком и специфическими уязвимостями, обусловленными архитектурой, данными обучения и процедурами генерации. Это означает, что универсальные детекторы, обученные на широком спектре LLM, могут демонстрировать сниженную эффективность в выявлении текста, сгенерированного конкретной моделью. Специализированное обучение, направленное на распознавание особенностей конкретной LLM или семейства моделей, позволяет детекторам лучше адаптироваться к этим нюансам и значительно повысить точность выявления сгенерированного текста, поскольку учитываются специфические закономерности и слабые места каждой модели.
Эксперименты с использованием набора данных RAID продемонстрировали значительные улучшения в производительности при использовании целевых стратегий тонкой настройки. На 100-миллионном токеновом бенчмарке достигнута почти идеальная точность на уровне отдельных токенов. Ансамбль, обученный по принципу «Per LLM Family», показал Recall 0.980 и Precision 0.660, что свидетельствует о высокой способности обнаруживать сгенерированный текст внутри семейства моделей, хотя и с некоторым уровнем ложных срабатываний.
Валидация и анализ эффективности обнаружения
Статистический анализ играет ключевую роль в объективной оценке эффективности различных методов обнаружения текстов, сгенерированных искусственным интеллектом. Он позволяет выйти за рамки субъективных впечатлений и получить количественные данные о точности, надежности и устойчивости каждого подхода. Исследование ключевых метрик, таких как доля правильно обнаруженных текстов, количество ложных срабатываний и точность, дает возможность выявить сильные и слабые стороны каждого алгоритма. Такой анализ необходим для сравнения различных методов, определения оптимальных параметров и выявления областей, требующих дальнейшего улучшения. Использование статистических методов обеспечивает воспроизводимость результатов и позволяет строить обоснованные выводы о применимости каждого метода в различных сценариях и для разных типов текстов.
Тщательный анализ показателей обнаружения, таких как процент правильно выявленных текстов, количество ложных срабатываний и точность, позволяет исследователям выявлять слабые места в алгоритмах определения сгенерированного ИИ текста. Оценивая эти ключевые метрики, можно понять, в каких случаях системы наиболее подвержены ошибкам — например, при обработке коротких текстов, текстов определенного стиля или при наличии специфических лингвистических конструкций. Это, в свою очередь, дает возможность целенаправленно улучшать алгоритмы, оптимизируя их для повышения надежности и снижения количества ошибочных выводов, что особенно важно для обеспечения достоверности информации и предотвращения злоупотреблений.
Модель Phi-4 представляет собой ценный эталон для оценки методов обнаружения текстов, сгенерированных искусственным интеллектом, обеспечивая стандартизированную платформу для сопоставления и воспроизводимости результатов. Её сравнительно небольшие размеры при сохранении высокого качества генерации позволяют исследователям более эффективно тестировать и калибровать алгоритмы обнаружения, минимизируя вычислительные затраты. Использование Phi-4 в качестве общего ориентира позволяет сравнивать различные подходы к обнаружению, выявлять их сильные и слабые стороны, а также обеспечивать прозрачность и надежность научных исследований в этой области. Благодаря её доступности и чёткой спецификации, результаты, полученные с использованием Phi-4, могут быть легко воспроизведены другими исследователями, способствуя прогрессу в разработке более точных и надежных систем обнаружения.
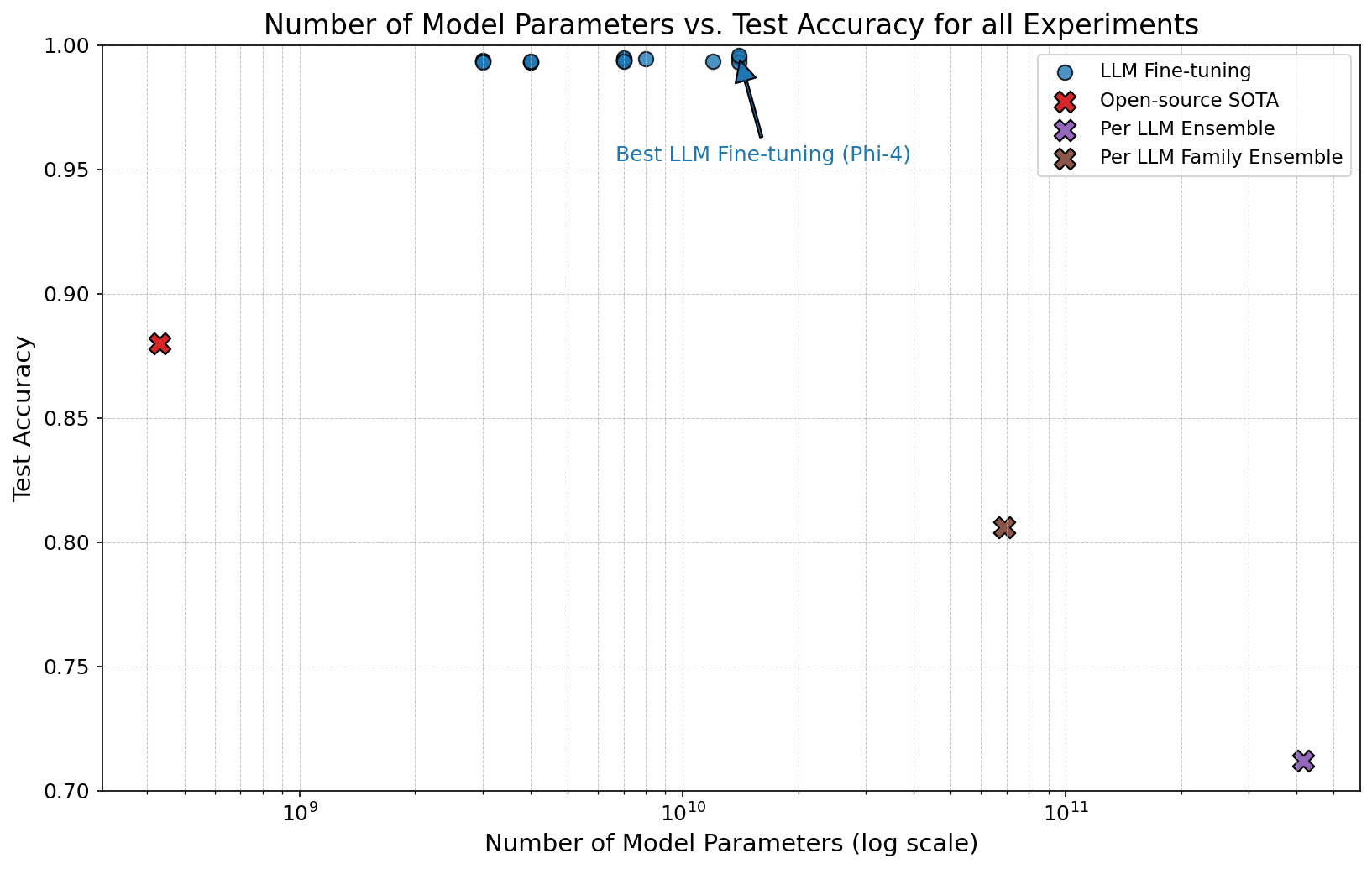
Исследование, представленное в статье, подчеркивает важность адаптации систем к постоянно меняющейся среде, что созвучно идеям Кena Thompson. Он однажды заметил: «Все системы стареют — вопрос лишь в том, делают ли они достойно». Действительно, как и в случае с обнаружением текста, сгенерированного ИИ, системы обнаружения должны постоянно адаптироваться к новым моделям и техникам генерации. Успех fine-tuning больших языковых моделей, описанный в статье, демонстрирует, что способность к эволюции и адаптации — ключевой фактор для поддержания эффективности системы во времени. Логирование, как хроника жизни системы, позволяет отслеживать эту эволюцию и вовремя вносить необходимые коррективы, обеспечивая тем самым её достойное старение.
Что дальше?
Исследование, представленное в данной работе, демонстрирует, что способность различать текст, созданный человеком, и текст, сгенерированный языковыми моделями, — это не вопрос абсолютной точности, а скорее временное состояние. Успех тонкой настройки больших языковых моделей для обнаружения ИИ-генерируемого текста — это лишь одна точка на кривой, постоянно меняющейся под воздействием эволюции самих моделей. Стабильность этой «точности» — иллюзия, кэшированная временем и объемом обучающих данных.
Очевидно, что гонка вооружений между генераторами и детекторами продолжится. Более сложные модели генерации будут требовать более сложных детекторов, и так до бесконечности. Важнее, однако, признать, что сама постановка вопроса о «подлинности» текста может оказаться несостоятельной. Задержка, которую несет в себе каждый запрос на определение авторства, — это налог, который платит каждый анализ. В конечном итоге, возможно, более плодотворным будет изучение влияния ИИ-генерируемого контента, а не попытки его просто идентифицировать.
Поиск оптимальных стратегий обучения — по моделям или по семействам моделей — это лишь техническая деталь. Реальный вызов заключается в понимании того, что любая система, включая и эту, неизбежно стареет. Вопрос не в том, как остановить этот процесс, а в том, как обеспечить достойное старение, признавая ограниченность любого метода и его временный характер.
Оригинал статьи: https://arxiv.org/pdf/2601.20006.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-29 11:33