Автор: Денис Аветисян
Новый подход объединяет возможности анализа графов и языковых моделей, позволяя нейросетям самостоятельно выявлять признаки мошеннических действий.
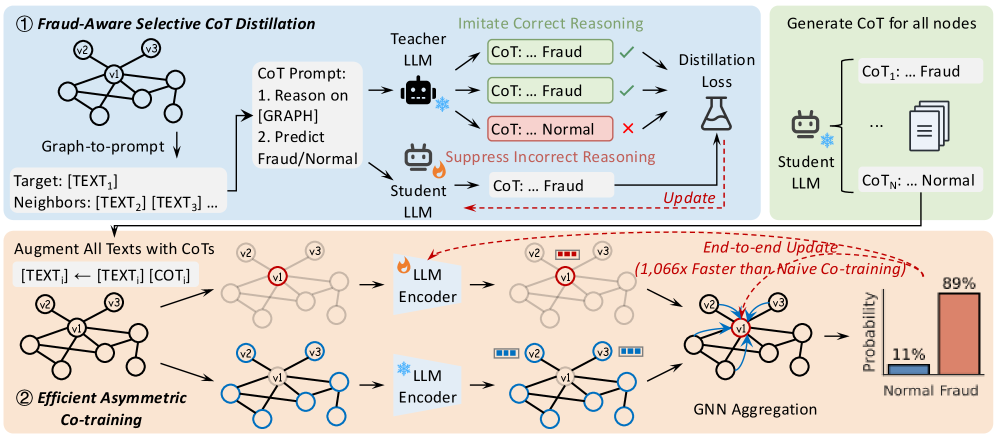
Представлен FraudCoT — фреймворк для обнаружения мошенничества в графах с текстовыми атрибутами, использующий цепочку рассуждений и совместное обучение.
Обнаружение мошеннических действий в графовых данных, обогащенных текстовой информацией, требует одновременного учета как семантики текста, так и взаимосвязей между узлами графа. В данной работе, посвященной ‘Autonomous Chain-of-Thought Distillation for Graph-Based Fraud Detection’, предлагается новый подход FraudCoT, использующий автономное, графо-ориентированное рассуждение типа «цепь мыслей» (Chain-of-Thought) и масштабируемое совместное обучение больших языковых моделей (LLM) и графовых нейронных сетей (GNN). Предложенный механизм селективной дистилляции CoT позволяет генерировать разнообразные пути рассуждений и улучшает понимание семантико-структурных зависимостей, что обеспечивает значительное повышение точности обнаружения мошеннических действий и скорости обучения. Сможет ли подобный симбиоз LLM и GNN открыть новые горизонты в анализе сложных данных и повышении эффективности систем обнаружения аномалий?
Разоблачение Сетей Мошенничества: Вызов для Современных Алгоритмов
Традиционные методы обнаружения мошенничества, разработанные для анализа изолированных транзакций или небольших групп данных, оказываются неэффективными в условиях современной цифровой среды. Объём и сложность взаимосвязанных данных, генерируемых социальными сетями, финансовыми операциями и онлайн-торговлей, экспоненциально возрастают, что делает невозможным применение устаревших алгоритмов. Эти системы, как правило, не способны обрабатывать огромные объёмы информации в реальном времени и выявлять скрытые закономерности, указывающие на мошеннические действия. Более того, мошенники постоянно адаптируются, используя всё более сложные схемы, которые маскируются под легитимные транзакции, что требует принципиально нового подхода к анализу данных и обнаружению аномалий в сложных сетевых структурах.
Выявление скрытых признаков мошенничества в сложных данных, представленных в виде графов и насыщенных текстовой информацией, требует принципиально новых подходов к анализу и представлению информации. Традиционные методы, ориентированные на изолированные транзакции или упрощенные связи, оказываются неэффективными в условиях, когда мошеннические схемы маскируются в сложной сети взаимосвязей. Необходимо разрабатывать такие методы представления данных, которые позволяют учитывать контекст каждой транзакции и связи, а также использовать алгоритмы, способные выявлять аномалии и закономерности, невидимые для человеческого глаза. В частности, перспективным направлением является использование методов обработки естественного языка для анализа текстовых данных, связанных с транзакциями, и построение семантических графов, отражающих взаимосвязи между сущностями и событиями. Это позволяет не только выявлять прямые признаки мошенничества, но и прогнозировать потенциальные риски на основе анализа поведения и намерений участников сети.
FraudCoT: Разумная Система для Обнаружения Мошенничества на Основе Графов
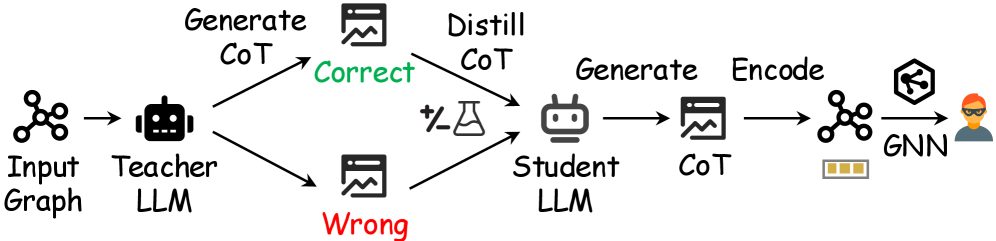
FraudCoT представляет собой унифицированный фреймворк для обнаружения мошеннических действий на основе графов, объединяющий цепочку рассуждений (chain-of-thought) с эффективным совместным обучением (co-training). Данный подход позволяет построить систему, способную анализировать взаимосвязи между сущностями, представленными в виде графа, и генерировать объяснения для своих решений. Совместное обучение используется для итеративной переподготовки компонентов системы — графовой нейронной сети и большой языковой модели — с использованием взаимно дополняющих друг друга данных и меток, что повышает общую точность и надежность обнаружения мошеннических операций. Фреймворк предназначен для обработки сложных сценариев, где для выявления мошенничества требуется не только анализ атрибутов отдельных объектов, но и учет контекста и взаимосвязей между ними.
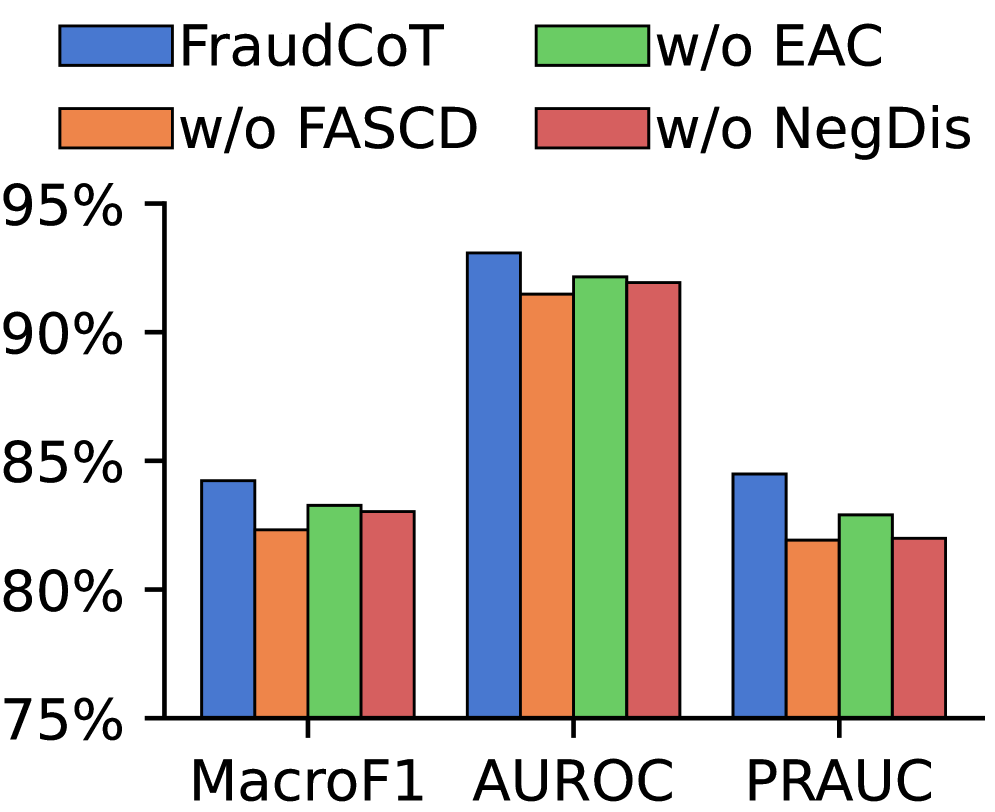
Архитектура FraudCoT объединяет возможности графовых нейронных сетей (GNN) и больших языковых моделей (LLM) для повышения точности выявления мошеннических операций. GNN эффективно обрабатывают и анализируют взаимосвязи в графовых данных, представляющих транзакции и сущности, в то время как LLM обеспечивают возможность логического вывода и интерпретации сложных паттернов. В результате, FraudCoT демонстрирует улучшение метрики AUPRC (Area Under the Precision-Recall Curve) до 8.8% по сравнению с современными базовыми моделями, что свидетельствует о значительном повышении эффективности обнаружения мошеннических действий.
Обогащение Представлений с Помощью Цепочки Рассуждений
FraudCoT использует метод «Chain-of-Thought» (CoT) для генерации объяснений, сопутствующих прогнозам о мошеннических операциях. Вместо простой выдачи результата («мошенничество» или «не мошенничество»), система предоставляет цепочку рассуждений, описывающую, какие факторы и логические шаги привели к конкретному заключению. Это значительно повышает интерпретируемость модели, позволяя пользователям понять, почему было принято то или иное решение, и, как следствие, повышает доверие к системе обнаружения мошенничества. Генерируемые объяснения позволяют проводить аудит предсказаний, выявлять потенциальные ошибки и улучшать общую эффективность модели.
Представления, дополненные цепочкой рассуждений (CoT-Augmented Representations), строятся на основе стандартных векторных представлений узлов графа (Node Embeddings), но расширяют их, фиксируя не только сам факт предсказания, но и логическую цепочку, приведшую к нему. Это позволяет захватить контекстуальную информацию о процессе принятия решения моделью, предоставляя более полное понимание причин, по которым был сделан конкретный прогноз. В отличие от традиционных представлений, отражающих лишь конечное состояние, CoT-представления кодируют промежуточные шаги рассуждений, что повышает интерпретируемость и позволяет анализировать логику модели.
Селективная дистилляция Chain-of-Thought (CoT) представляет собой метод эффективной передачи способности к рассуждению, изначально присущей мощным языковым моделям (LLM), к более компактной и производительной «студенческой» модели. В отличие от традиционной дистилляции, селективная дистилляция CoT фокусируется на передаче именно обоснований, сгенерированных LLM, а не только конечных предсказаний. Это достигается путем отбора наиболее информативных шагов рассуждений, которые затем используются для обучения студенческой модели, позволяя ей воспроизводить логику принятия решений исходной LLM, но с существенно меньшими вычислительными затратами и задержками. Процесс позволяет сохранить ключевые способности к рассуждению при переходе к более легковесной модели, что особенно важно для развертывания в условиях ограниченных ресурсов.
Асимметричное Со-Обучение для Повышения Эффективности
Асимметричное со-обучение (Asymmetric Co-training) отделяет кодирование целевых узлов от кодирования их соседей в графе. Такое разделение позволяет масштабировать процесс обучения на графах больших размеров, поскольку снижает вычислительную сложность и требования к памяти. Вместо одновременного обновления представлений как целевых узлов, так и их соседей, асимметричный подход позволяет обучать эти представления независимо друг от друга, что существенно повышает эффективность обучения и позволяет обрабатывать графы с миллионами узлов и связей без значительных затрат ресурсов.
Использование внутренней структуры графа позволяет модели эффективно обобщать данные даже при ограниченном количестве размеченных примеров. Вместо обработки узлов изолированно, модель учитывает связи между ними, что позволяет ей выявлять закономерности и делать прогнозы на основе контекста. Это особенно важно в задачах, где количество размеченных данных ограничено, поскольку модель может использовать информацию о соседних узлах для повышения точности и надежности прогнозов на неразмеченных данных. Такой подход позволяет значительно снизить потребность в больших объемах размеченных данных, делая обучение более эффективным и экономичным.
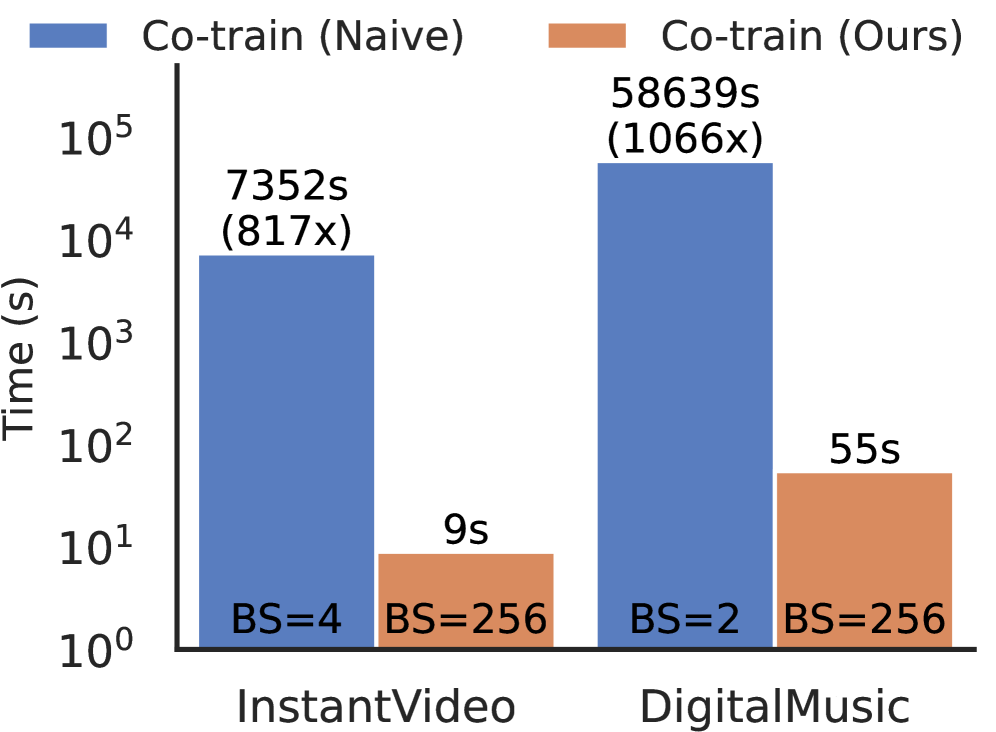
Оптимизация всего фреймворка, основанная на функции потерь Unlikelihood Loss, позволяет достичь значительного прироста производительности в задачах обнаружения мошеннических операций. В ходе обучения модель минимизирует вероятность правильной классификации соседних узлов в графе, что способствует более эффективному извлечению признаков и повышению точности. Экспериментальные данные демонстрируют, что данная оптимизация обеспечивает ускорение пропускной способности обучения до 1066 раз по сравнению с наивным ко-обучением, что делает подход применимым для обработки графов очень большого размера и в условиях ограниченных вычислительных ресурсов.
К Более Надёжному и Интерпретируемому Будущему
Система FraudCoT представляет собой существенный прогресс в области обнаружения мошеннических действий, предлагая повышенную устойчивость и прозрачность по сравнению с традиционными подходами. В отличие от “черных ящиков”, где принятие решений остается непрозрачным, FraudCoT стремится к созданию систем, способных не только выявлять подозрительную активность, но и предоставлять четкое обоснование своих выводов. Это достигается за счет интеграции различных источников информации и использования методов, позволяющих отслеживать логику принятия решений. В результате, FraudCoT способствует повышению доверия к системам обнаружения мошенничества, облегчая проверку и аудит, а также позволяя оперативно реагировать на новые виды мошеннических схем и адаптировать стратегии защиты.
Новая структура FraudCoT открывает принципиально новые возможности в выявлении сложных схем мошенничества, объединяя анализ структурных связей и семантического содержания данных. Вместо традиционного рассмотрения транзакций изолированно, система анализирует не только что происходит, но и как эти операции связаны между собой, а также что они означают в контексте общей сети взаимодействий. Это позволяет выявлять сложные паттерны, которые ранее оставались незамеченными, поскольку мошенники часто используют сложные сети взаимосвязанных транзакций для маскировки своих действий. Благодаря такому подходу, FraudCoT способна обнаруживать не просто отдельные подозрительные операции, а целые организованные схемы, что значительно повышает эффективность борьбы с мошенничеством.
Система FraudCoT значительно повышает доверие к процессам выявления мошенничества благодаря предоставлению четких путей обоснования принятых решений. Вместо простого указания на факт мошенничества, она демонстрирует логическую цепочку, приведшую к такому заключению, что позволяет экспертам понять и проверить достоверность анализа. Это не только укрепляет уверенность в результатах, но и способствует большей ответственности, поскольку каждое решение подкреплено прозрачными аргументами. В результате, FraudCoT позволяет разрабатывать более эффективные стратегии предотвращения мошенничества, основанные на глубоком понимании выявленных закономерностей и способности к их дальнейшей верификации и адаптации.
Исследование демонстрирует стремление к созданию систем, способных к самостоятельному анализу и обучению, что перекликается с философией глубокого понимания механизмов работы. Авторы предлагают FraudCoT — подход, объединяющий графовые нейронные сети и цепочку рассуждений, позволяя системе не просто выявлять мошеннические действия, но и объяснять логику своих решений. Как заметил Линус Торвальдс: «Если вы не пишете свой собственный код, то вы не контролируете ситуацию». В данном случае, способность FraudCoT к автономному рассуждению — это своего рода «написание собственного кода» для обнаружения мошенничества, позволяющее системе адаптироваться и совершенствоваться без постоянного вмешательства человека. По сути, это признание того, что идеальных систем не существует, и каждый «патч» — это шаг к более глубокому пониманию сложности задачи обнаружения мошенничества в графовых структурах.
Куда же дальше?
Представленный подход, объединяющий графовые нейронные сети и цепное рассуждение, безусловно, открывает новые горизонты в обнаружении мошенничества. Однако, стоит признать, что настоящая сложность заключается не в построении системы, а в её способности адаптироваться к постоянно эволюционирующим схемам обмана. Автоматическое дистилляционное обучение, как показано в работе, — это лишь первый шаг к созданию самообучающейся системы, способной предвидеть и парировать новые атаки. Ключевым вопросом остаётся масштабируемость: сможет ли эта архитектура эффективно работать с графами, содержащими миллионы или даже миллиарды узлов и связей, не теряя при этом скорости и точности?
Очевидным направлением для дальнейших исследований является расширение возможностей цепного рассуждения. Текущие модели часто полагаются на заранее заданные шаблоны логических выводов. Более продвинутый подход потребует создания систем, способных самостоятельно генерировать и проверять гипотезы, используя не только текстовые атрибуты графа, но и внешние источники информации. Фактически, задача сводится к созданию искусственного интеллекта, способного мыслить как опытный следователь, умеющий видеть закономерности, которые ускользают от поверхностного анализа.
И, наконец, не стоит забывать о «человеческом факторе». Любая система обнаружения мошенничества должна быть не только эффективной, но и прозрачной. Необходимо разработать методы, позволяющие объяснять логику принятия решений, чтобы пользователи могли доверять системе и использовать её в качестве инструмента поддержки, а не как «чёрный ящик». В конечном счёте, цель состоит не в том, чтобы заменить человека, а в том, чтобы усилить его возможности.
Оригинал статьи: https://arxiv.org/pdf/2601.22949.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-02 23:34