Автор: Денис Аветисян
Новый подход использует «атакующие» вопросы для выявления и устранения слабых мест в логике специализированных языковых моделей, значительно повышая их эффективность.
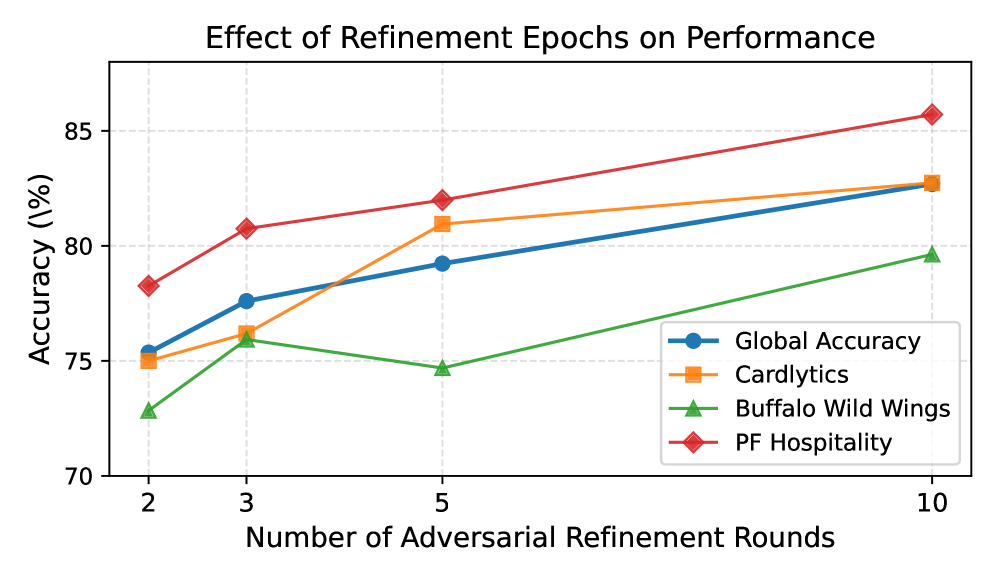
Исследование предлагает фреймворк adversarial learning для адаптации и улучшения интерпретационных способностей языковых моделей в конкретных предметных областях, используя синтетические данные и бенчмарки, такие как LegalBench и TextGrad.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их адаптация к специализированным областям знаний часто сталкивается с нехваткой качественных данных. В статье ‘Agentic Adversarial QA for Improving Domain-Specific LLMs’ предложен инновационный подход, основанный на генерации сложных вопросов, выявляющих слабые места модели в интерпретации предметной области. Данный метод, использующий состязательное обучение, позволяет значительно повысить точность LLM при значительно меньшем объеме синтетических данных. Способствует ли подобная стратегия формированию более эффективных и надежных систем искусственного интеллекта для решения узкоспециализированных задач?
Пределы масштаба: Большие языковые модели и узкопрофильные знания
Несмотря на впечатляющий объем общих знаний, современные большие языковые модели (БЯМ) часто демонстрируют ограниченные возможности в понимании тонкостей и специализированных знаний в конкретных областях. В то время как БЯМ способны генерировать текст, напоминающий человеческий, и отвечать на широкий спектр вопросов, их способность к глубокому анализу и применению узкоспециализированной информации остается недостаточной. Это проявляется в трудностях с интерпретацией контекста, требующего глубокого понимания предметной области, и в склонности к совершению ошибок в задачах, где требуется не просто воспроизведение информации, а её критический анализ и применение в новых ситуациях. Таким образом, хотя БЯМ и способны имитировать знания, истинное понимание и владение специализированными знаниями остаются серьезной проблемой.
Несмотря на впечатляющий рост масштабов языковых моделей, одного лишь увеличения их размера недостаточно для достижения истинного понимания и компетентности. Исследования показывают, что ключевой проблемой является не столько объем данных, сколько способность эффективно интегрировать и использовать разрозненную, специализированную информацию. Современные модели часто сталкиваются с трудностями при работе с узкоспециализированными знаниями, поскольку их архитектура не оптимальна для обработки фрагментированных данных. Необходимы новые методы, позволяющие моделям не просто запоминать факты, но и устанавливать связи между ними, извлекать значимую информацию из скудных источников и применять ее в конкретных ситуациях. Успешное решение этой задачи откроет путь к созданию более надежных и компетентных систем искусственного интеллекта, способных решать сложные задачи в различных областях знаний.
Недостаточность специализированных знаний существенно ограничивает возможности больших языковых моделей в критически важных областях, таких как юридическая практика. Результаты тестов, например, на платформе LegalBench, демонстрируют заметный разрыв в производительности между LLM и экспертами-юристами при решении сложных правовых задач. Данный дефицит указывает на необходимость разработки более целенаправленных подходов к обучению и интеграции узкопрофильных знаний, позволяющих языковым моделям эффективно функционировать в специализированных областях и обеспечивать надежные результаты, соответствующие требованиям профессиональной деятельности.
Синтетические данные как мост к экспертным знаниям
Генерация синтетических данных представляет собой эффективное решение для расширения обучающих наборов и повышения обобщающей способности моделей машинного обучения. Вместо сбора и разметки реальных данных, синтетические данные создаются алгоритмически, что позволяет увеличить объем обучающей выборки, особенно в случаях, когда доступ к реальным данным ограничен или сопряжен с проблемами конфиденциальности. Использование синтетических данных позволяет модели лучше справляться с новыми, ранее не встречавшимися ситуациями, снижая риск переобучения и повышая надежность прогнозов. Эффективность данного подхода подтверждается в различных областях, включая компьютерное зрение, обработку естественного языка и анализ данных.
Методы Knowledge-Instruct и EntiGraph расширяют возможности генерации синтетических данных путем преобразования извлеченных фактов в обучающие пары «инструкция-ответ» и расширения графов знаний, ориентированных на сущности, соответственно. Knowledge-Instruct позволяет создавать данные для обучения моделей, способных следовать инструкциям, используя структурированные знания. EntiGraph, в свою очередь, увеличивает объем информации в графах знаний, что улучшает способность моделей понимать взаимосвязи между сущностями и повышает точность ответов на запросы, связанные с этими сущностями. Оба подхода направлены на повышение эффективности обучения моделей за счет использования структурированных знаний и расширения объема доступных данных.
Метод аугментации на основе перефразирования позволяет увеличить разнообразие обучающих данных путем переформулировки существующего текста. Этот подход генерирует новые примеры, сохраняя при этом исходный смысл, что способствует созданию более устойчивых и универсальных моделей. Перефразирование может быть реализовано с использованием различных техник, включая замену синонимов, изменение структуры предложений и использование алгоритмов машинного перевода для создания вариаций текста. В результате, модель обучается на большем количестве разнообразных примеров, что повышает её способность к обобщению и снижает риск переобучения, особенно в условиях ограниченного объема исходных данных.
Оптимизация обучения для надежной производительности
Тонкая настройка, использующая перенос обучения (Transfer Learning), является критически важной для адаптации больших языковых моделей (LLM) к конкретным задачам и предметным областям. Вместо обучения модели с нуля, перенос обучения позволяет использовать предварительно обученные веса модели, полученные на большом корпусе данных, и адаптировать их к целевой задаче с использованием значительно меньшего объема данных. Этот подход существенно сокращает время обучения и вычислительные затраты, а также позволяет достичь более высокой производительности, особенно в условиях ограниченного количества размеченных данных для целевой задачи. Эффективность тонкой настройки зависит от степени сходства между исходной и целевой задачами, а также от выбора подходящей стратегии обучения и гиперпараметров.
Инструктивная настройка (Instruction Tuning) представляет собой усовершенствованный метод дообучения больших языковых моделей (LLM), заключающийся в тренировке на парах «инструкция-ответ». В процессе обучения модель получает на вход четко сформулированную инструкцию и соответствующий ожидаемый ответ, что позволяет ей более эффективно понимать и выполнять сложные запросы. В отличие от простого дообучения на текстовых данных, инструктивная настройка фокусируется на улучшении способности модели следовать указаниям и генерировать ответы, соответствующие заданным требованиям, что значительно повышает ее полезность в задачах, требующих точного выполнения команд и предоставления конкретной информации.
Для оптимизации промптов и обучающих данных применяются передовые методы, такие как дифференцируемое подсказывание (Differentiable Prompting). Этот подход позволяет вычислять градиенты относительно входных подсказок, что даёт возможность их автоматической настройки для повышения производительности модели. Инструменты, такие как TextGrad, облегчают реализацию дифференцируемого подсказывания. Дополнительно, генерация вопросов (Question Generation) используется для создания разнообразных обучающих примеров, расширяя охват данных и повышая обобщающую способность модели. Оба метода направлены на улучшение качества входных данных и, как следствие, повышение точности и надежности больших языковых моделей.
Для повышения устойчивости больших языковых моделей (LLM) применяются методы состязательного обучения (Adversarial Learning) и распределённо-устойчивой оптимизации (Distributionally Robust Optimization). Состязательное обучение предполагает намеренное создание входных данных, предназначенных для выявления уязвимостей модели, что позволяет улучшить её способность справляться с непредсказуемыми или враждебными входными данными. Распределённо-устойчивая оптимизация, в свою очередь, учитывает вариативность данных и стремится минимизировать риск снижения производительности модели при изменении распределения входных данных. Эти подходы позволяют создавать более надёжные и стабильные LLM, способные эффективно работать в различных условиях и с разнообразными данными.
К эффективным и адаптивным системам искусственного интеллекта
Исследования показали, что комбинирование синтетической генерации данных с оптимизированными методологиями обучения, такими как тонкая настройка и обучение по инструкциям, значительно повышает эффективность больших языковых моделей (LLM), особенно в узкопрофильных областях. Разработанная авторами система генерации состязательных вопросов демонстрирует впечатляющий прирост точности в 18.99% по сравнению с базовой моделью. Этот подход позволяет создавать более релевантные и сложные обучающие примеры, что, в свою очередь, способствует улучшению способности модели к обобщению и решению задач в конкретной предметной области. Полученные результаты свидетельствуют о перспективности использования синтетических данных в качестве эффективного инструмента для повышения производительности LLM при ограниченном объеме размеченных данных.
Метод дистилляции моделей позволяет создавать более компактные и эффективные версии крупных языковых моделей без существенной потери точности. Суть подхода заключается в передаче знаний от сложной, хорошо обученной модели — “учителя” — к более простой, “студенческой” модели. В процессе обучения “студент” стремится воспроизвести не только предсказания “учителя”, но и вероятностное распределение этих предсказаний, что позволяет ему усвоить более тонкие нюансы и обобщающие способности. Это особенно важно для развертывания моделей на устройствах с ограниченными ресурсами или для ускорения процесса инференса, поскольку более компактная модель требует меньше вычислительной мощности и памяти, сохраняя при этом высокую производительность.
Активное обучение представляет собой эффективный подход к снижению затрат на ручную разметку данных, что особенно важно при работе с большими объемами информации. Вместо того, чтобы помечать все данные, система самостоятельно определяет наиболее информативные экземпляры, требующие внимания специалиста. Этот процесс позволяет существенно сократить количество данных, нуждающихся в ручной обработке, при этом сохраняя или даже повышая точность модели. Вместо слепого перебора, алгоритм активно выбирает примеры, которые максимально способствуют обучению, эффективно используя ограниченные ресурсы для разметки и обеспечивая более быструю адаптацию модели к новым задачам и доменам. Такой подход позволяет создавать более эффективные и экономичные системы искусственного интеллекта, требующие меньше усилий и времени на подготовку данных.
Сочетание методов синтетической генерации данных, оптимизированных стратегий обучения и активного обучения позволяет создавать адаптивные, эффективные и устойчивые к изменениям системы искусственного интеллекта, способные решать сложные задачи в специализированных областях. В результате проведенных исследований, разработанный подход продемонстрировал улучшение показателей на 3.89% по сравнению с конкурентом EntiGraph, при этом потребовалось приблизительно в 70 раз меньше обучающих токенов. Такая значительная экономия ресурсов открывает новые возможности для обучения и развертывания ИИ-систем даже в условиях ограниченных вычислительных мощностей, обеспечивая высокую производительность и точность в решении узкоспециализированных задач.
Исследование демонстрирует, что для повышения эффективности языковых моделей в специфических областях необходимо не просто увеличение объема данных, а создание состязательной среды, выявляющей слабые места в интерпретационном мышлении. Авторы предлагают метод генерации сложных вопросов, заставляющих модель «проявлять себя» и выявлять пробелы в знаниях. Этот подход созвучен идеям Клода Шеннона: «Информация — это мера преодоления неопределенности». В данном контексте, каждый сложный вопрос — это преодоление неопределенности в знаниях модели, а процесс обучения — это минимизация этой неопределенности. Создание состязательных вопросов, направленных на выявление слабых мест, позволяет не только улучшить результаты на бенчмарках, таких как LegalBench, но и создать более надежные и интерпретируемые системы.
Куда Дальше?
Представленная работа, по сути, демонстрирует, что даже небольшие языковые модели способны к значительному росту, если их намеренно подвергать тщательно продуманным испытаниям. Это напоминает о старом принципе: если что-то не ломается, значит, оно недостаточно интересно. Однако, стоит признать, что генерация «враждебных» вопросов — это искусство, требующее постоянной калибровки. Простое увеличение сложности не всегда ведет к улучшению понимания; часто это лишь выявляет новые способы обмана системы.
Будущие исследования должны сосредоточиться на автоматизации этого процесса «враждебного» обучения, стремясь к созданию самообучающихся систем, способных самостоятельно выявлять и эксплуатировать слабые места в своих знаниях. Особый интерес представляет вопрос о переносе этих методов на другие области, где интерпретируемость и надежность имеют критическое значение — например, в диагностике или в принятии юридических решений. В конце концов, истинное понимание рождается не из безупречного воспроизведения, а из умения справляться с неожиданностями.
Неизбежно возникает вопрос: какова конечная цель этого цикла улучшения? Создать идеальную систему искусственного интеллекта, неотличимую от человеческого разума? Или же просто научиться лучше понимать собственные когнитивные ограничения, отраженные в этих машинных моделях? Возможно, ответ лежит где-то посередине, в постоянном стремлении к познанию, которое и есть, по сути, и есть сама игра.
Оригинал статьи: https://arxiv.org/pdf/2602.18137.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- OM ПРОГНОЗ. OM криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SUI ПРОГНОЗ. SUI криптовалюта
2026-02-23 22:36