Автор: Денис Аветисян
Исследование показывает, что методы машинного обучения превосходят традиционные модели в предсказании волатильности финансовых рынков, особенно при работе с большим объемом данных и увеличением горизонта прогнозирования.
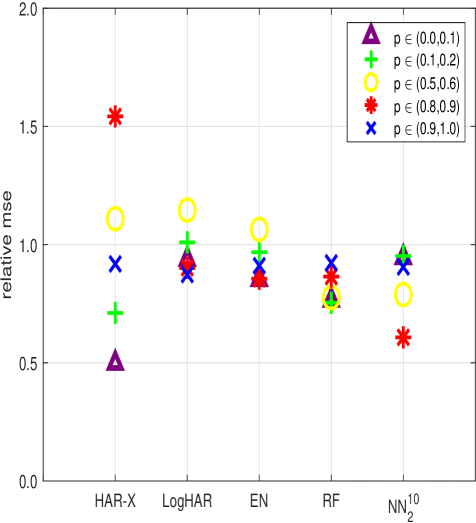
Машинное обучение, включая случайные леса и нейронные сети, демонстрирует улучшенные результаты по сравнению с HAR-моделями в задачах прогнозирования волатильности и оценки рисков.
Прогнозирование волатильности финансовых активов остается сложной задачей, особенно в условиях меняющихся рыночных режимов. В данной работе, ‘A machine learning approach to volatility forecasting’, исследуется применимость методов машинного обучения для прогнозирования реализованной волатильности индекса Dow Jones Industrial Average. Показано, что модели машинного обучения, включая регуляризованные методы, деревья решений и нейронные сети, превосходят традиционные модели HAR, даже при минимальной настройке гиперпараметров и использовании лишь лагов реализованной волатильности. Какие перспективы открываются для дальнейшего развития гибридных моделей, сочетающих преимущества машинного обучения и эконометрических подходов к прогнозированию волатильности?
За пределами Среднего: Понимание Динамики Волатильности
Точное прогнозирование волатильности играет фундаментальную роль в управлении рисками и ценообразовании активов, однако традиционные методы зачастую оказываются неспособными адекватно отразить сложность рыночной динамики. Из-за нелинейности и подверженности рынков внезапным изменениям, основанные на исторических средних или простых моделях подходы часто демонстрируют значительные погрешности, особенно в периоды повышенной неопределенности. Это приводит к недооценке рисков и неоптимальным инвестиционным решениям. Современные исследования фокусируются на разработке более сложных моделей, учитывающих такие факторы, как асимметрия волатильности, кластеризация и влияние макроэкономических показателей, стремясь повысить точность прогнозов и обеспечить более эффективное управление капиталом. Улучшенное прогнозирование волатильности позволяет инвесторам и финансовым учреждениям более адекватно оценивать риски, оптимизировать портфели и разрабатывать стратегии хеджирования, что в конечном итоге способствует стабильности финансовой системы.
Для точного измерения волатильности финансовых рынков все большее значение приобретают данные высокой частоты. Традиционные методы, основанные на дневных ценах, зачастую не способны уловить кратковременные, но существенные колебания, влияющие на ценообразование активов и оценку рисков. Использование данных, собираемых с секундной или даже миллисекундной точностью, позволяет рассчитать ключевые показатели, такие как реализованная дисперсия RV_t = \sum_{i=1}^{n} r_{t,i}^2, представляющая собой сумму квадратов доходностей за определенный период времени. Реализованная дисперсия является несмещенной оценкой волатильности и служит основой для построения более сложных моделей прогнозирования, позволяющих трейдерам и инвесторам эффективно управлять рисками и оптимизировать свои портфели.
Изучение свойств временных рядов, в частности, феномена долгой памяти, является ключевым фактором при создании надежных прогностических моделей. Долгая память означает, что прошлые колебания цен активов оказывают влияние на будущую волатильность в течение продолжительного периода времени, что противоречит традиционным предположениям о независимости и стационарности финансовых данных. Это означает, что модели, игнорирующие долгосрочные зависимости, могут недооценивать риски и давать неточные прогнозы. Учет долгой памяти требует использования специализированных статистических методов и моделей, таких как модели ARCH/GARCH с интегрированием порядка единицы I(1), или фрактальный анализ временных рядов, позволяющих более точно отразить динамику рыночных колебаний и повысить эффективность управления рисками.
Эталонные Модели и Методы Регуляризации
Модель HAR (Heterogeneous Autoregressive) является базовым эталоном для прогнозирования волатильности, использующим запаздывающие значения реализованной дисперсии RV_t для предсказания будущих колебаний. В основе модели лежит предположение о том, что волатильность демонстрирует долгосрочную память, и что текущая волатильность зависит от волатильности в предыдущие периоды. Обычно модель HAR включает в себя компоненты, основанные на запаздывающих значениях реализованной дисперсии на разных временных горизонтах — дневном, недельном и месячном — что позволяет учитывать различные временные зависимости в данных. Реализованная дисперсия, рассчитанная как сумма квадратов доходностей на высокой частоте, служит ключевым входным параметром для построения прогнозов волатильности с помощью модели HAR.
Модель LogHAR является усовершенствованием базовой модели HAR путем применения логарифмических преобразований к данным о реализованной волатильности. Это преобразование направлено на стабилизацию дисперсии и уменьшение влияния выбросов, что потенциально может улучшить точность прогнозирования волатильности. В частности, логарифмирование позволяет более эффективно моделировать асимметричные паттерны волатильности и снизить влияние экстремальных значений, часто наблюдаемых на финансовых рынках. log(RV_t) — типичное представление логарифмически преобразованной реализованной волатильности на временном шаге t.
Линейные регрессионные методы, такие как Ridge Regression, Lasso Regression и Elastic Net, могут быть использованы для моделирования волатильности, однако требуют тщательной регуляризации для предотвращения переобучения. Применение регуляризации необходимо для снижения влияния мультиколлинеарности и повышения обобщающей способности модели. Несмотря на это, на горизонте прогнозирования в один день эти модели последовательно демонстрируют более низкую производительность по сравнению с более продвинутыми методами, такими как деревья решений и нейронные сети, показывая относительное улучшение среднеквадратичной ошибки (MSE) до 20%.
За Пределами Линейности: Продвинутое Машинное Обучение для Волатильности
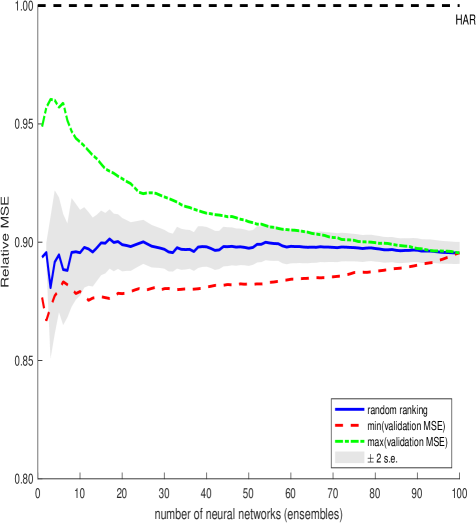
Метод случайного леса (Random Forest) представляет собой ансамблевый алгоритм машинного обучения, способный моделировать сложные паттерны волатильности. В его основе лежит объединение множества деревьев решений, каждое из которых обучается на случайной подвыборке данных и случайном подмножестве признаков. Такой подход позволяет снизить переобучение и повысить обобщающую способность модели. Каждое дерево в лесу прогнозирует значение волатильности, а итоговый прогноз формируется путем усреднения прогнозов всех деревьев, что обеспечивает более устойчивый и точный результат по сравнению с использованием одного дерева решений.
Нейронные сети, моделируя принципы работы человеческого мозга, предоставляют возможность выявления более сложных зависимостей в данных о волатильности, чем традиционные модели. Однако, для достижения оптимальной производительности, требуется тщательная настройка гиперпараметров и архитектуры сети. Ключевыми методами оптимизации являются Adaptive Learning Rate, который динамически изменяет скорость обучения для ускорения сходимости и предотвращения переобучения, и Dropout, представляющий собой случайное отключение нейронов во время обучения, что способствует повышению обобщающей способности модели и снижению зависимости от конкретных признаков.
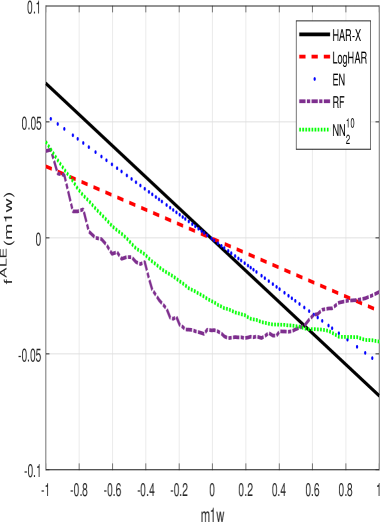
Оценка важности признаков с использованием методов, таких как Accumulated Local Effect (ALE), является ключевым аспектом интерпретации прогнозов, генерируемых сложными моделями машинного обучения для анализа волатильности. В ходе тестирования эти модели демонстрируют стабильное превосходство над традиционными HAR (Heterogeneous Autoregressive) моделями, позволяя снизить среднеквадратичную ошибку (Mean Squared Error) на величину до 40% при прогнозировании на месячный горизонт. Анализ показывает, что модели машинного обучения более эффективно улавливают долгосрочную структуру волатильности, что подтверждается более высокой автокорреляцией ошибок прогнозирования на длительных временных горизонтах.
Более сложные модели машинного обучения, такие как нейронные сети и случайные леса, демонстрируют улучшенное моделирование долгосрочной памяти волатильности по сравнению с традиционными моделями HAR. Это подтверждается более высокой автокорреляцией ошибок прогнозирования на более длительных горизонтах внутри выборки. Высокая автокорреляция указывает на то, что ошибки прогнозирования в текущий момент времени коррелируют с ошибками в предыдущие моменты времени, что свидетельствует о способности модели лучше улавливать и воспроизводить долгосрочные зависимости в волатильности. Иными словами, эти модели способны более точно предсказывать будущую волатильность, учитывая информацию о волатильности в более отдаленном прошлом.
Уточнение Прогноза: Учет Высших Моментов
Анализ финансовых рынков традиционно фокусируется на дисперсии, измеряемой как реализованная волатильность. Однако, для более полного понимания динамики колебаний цен, недостаточно ограничиваться только этим показателем. Исследования показывают, что учет высших моментов распределения, таких как реализованная квартильность, позволяет получить более детальную картину рыночных флуктуаций. Реализованная квартильность, по сути, отражает «толщину хвостов» распределения, то есть вероятность экстремальных событий. Учитывая эти моменты, можно более точно моделировать ненормальное поведение рынков, которое часто проявляется в периоды кризисов или высокой волатильности. Таким образом, расширение анализа за рамки простой дисперсии позволяет получить более реалистичное представление о рисках и потенциальных убытках, что особенно важно для инвесторов и управляющих активами.
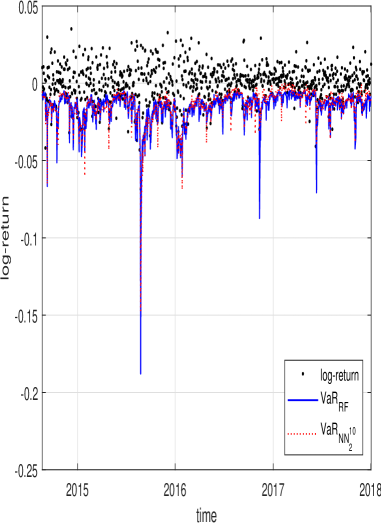
Интеграция усовершенствованных статистических показателей, таких как реализованная квартильность, в существующие модели прогнозирования волатильности представляет собой перспективный путь к повышению точности финансовых оценок. Вместо того, чтобы полагаться исключительно на дисперсию, использование моментов высшего порядка позволяет более полно учесть асимметрию и эксцесс рыночных колебаний, что особенно важно в периоды турбулентности. Такой подход не только улучшает предсказательную силу моделей, но и способствует более адекватному определению рисков, позволяя инвесторам и финансовым аналитикам принимать более обоснованные решения. Применение этих методов позволяет создавать более надежные оценки Value-at-Risk (VaR) и оптимизировать стратегии управления портфелем, что, в конечном итоге, способствует снижению потенциальных убытков и повышению доходности инвестиций.
Повышение точности прогнозов волатильности непосредственно влияет на качество оценки Value-at-Risk (VaR) и, как следствие, на принятие более обоснованных инвестиционных решений. Исследования показали, что, хотя применение моделей машинного обучения и демонстрирует снижение потенциальных потерь по VaR, эта разница статистически не столь значима. Гораздо более существенное улучшение наблюдается в снижении среднеквадратичной ошибки (MSE), что указывает на то, что более точное предсказание волатильности, даже если не всегда приводит к резкому уменьшению VaR, значительно повышает надежность модели в целом и позволяет более эффективно управлять рисками, основываясь на более реалистичных оценках.
Исследование демонстрирует, что традиционные модели прогнозирования волатильности, такие как HAR, уступают более современным методам машинного обучения, особенно при работе с большим объемом данных и увеличением горизонта прогнозирования. Это подтверждает идею о том, что системы, даже самые устойчивые, подвержены старению и требуют постоянной адаптации. Как однажды заметил Стивен Хокинг: «Со временем все становится проще». Данное наблюдение применимо и к финансовым моделям: упрощение, достигаемое за счет использования более сложных алгоритмов машинного обучения, позволяет им лучше отражать динамику рынка и, следовательно, продлевать их «жизнь» в условиях постоянно меняющейся реальности. Стабильность, основанная на устаревших подходах, лишь откладывает неизбежное — необходимость в инновациях.
Что дальше?
Представленная работа, демонстрируя превосходство алгоритмов машинного обучения в прогнозировании волатильности, лишь обнажает глубину нерешенных вопросов. Успех, достигнутый за счёт увеличения числа предикторов, кажется симптоматичным: система усложняется, чтобы лучше отразить хаотичную природу рынка, но это лишь откладывает неизбежное столкновение с непредсказуемостью. Каждая абстракция несёт груз прошлого, и, хотя модели становятся точнее в краткосрочной перспективе, их долговечность вызывает обоснованные сомнения.
Будущие исследования должны сосредоточиться не на погоне за краткосрочной точностью, а на разработке систем, способных адаптироваться к меняющимся условиям. Интерес представляет изучение методов регуляризации, позволяющих сохранять устойчивость моделей при увеличении их сложности. Однако, истинный прогресс, вероятно, потребует выхода за рамки чисто статистических подходов и интеграции знаний о фундаментальных факторах, определяющих динамику рынка.
В конечном счёте, задача прогнозирования волатильности — это попытка удержать ускользающую тень. И хотя современные методы позволяют на короткое время приблизиться к этой цели, следует помнить, что только медленные изменения сохраняют устойчивость. Все системы стареют — вопрос лишь в том, делают ли они это достойно.
Оригинал статьи: https://arxiv.org/pdf/2601.13014.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-22 06:15