Автор: Денис Аветисян
Новые алгоритмы машинного обучения позволяют с высокой точностью предсказывать ежедневный поток пациентов в приемное отделение, что критически важно для эффективного распределения ресурсов.
Сравнительный анализ статистических и машинных моделей прогнозирования поступлений в отделения неотложной помощи с учетом сложности клинических случаев.
Перегруженность отделений неотложной помощи остаётся критической проблемой, требующей точного прогнозирования потока пациентов для эффективного распределения ресурсов. В работе ‘Early predicting of hospital admission using machine learning algorithms: Priority queues approach’ сравниваются статистические и алгоритмы машинного обучения — SARIMAX, XGBoost и LSTM — для прогнозирования ежедневного количества поступающих в отделение неотложной помощи, с разбивкой по отделениям и уровню клинической сложности. Эксперименты показали, что все три модели превосходят наивный сезонный базовый уровень, при этом XGBoost обеспечивает наибольшую точность прогноза общего числа госпитализаций, а SARIMAX — для пациентов высокой степени сложности. Смогут ли эти методы эффективно адаптироваться к непредсказуемым всплескам спроса и обеспечить действительно надёжное планирование ресурсов?
Предвидение потребностей: Основа эффективного здравоохранения
Точное прогнозирование потребности в больничных ресурсах является основополагающим фактором для обеспечения качественной медицинской помощи и эффективной работы учреждения. Недостаточная оценка потребностей может привести к перегрузке персонала, нехватке оборудования и, как следствие, к снижению качества обслуживания пациентов и увеличению времени ожидания. В то же время, избыточное планирование приводит к нерациональному использованию финансовых ресурсов и упущенным возможностям для инвестиций в другие важные области здравоохранения. Таким образом, эффективное прогнозирование позволяет оптимизировать распределение ресурсов, сократить издержки и, самое главное, обеспечить своевременную и адекватную медицинскую помощь каждому пациенту, что в конечном итоге способствует повышению общего уровня здоровья населения.
Традиционные методы прогнозирования нагрузки на больницы часто оказываются неэффективными из-за присущей потоку пациентов сложности и изменчивости. Эти модели, как правило, основаны на исторических данных и не способны адекватно реагировать на неожиданные события, такие как вспышки инфекционных заболеваний или массовые травмы. Непредсказуемость поступлений пациентов, обусловленная множеством факторов — от сезонности до социально-экономических условий — приводит к значительным погрешностям в прогнозах. В результате, больницы сталкиваются с проблемами нехватки ресурсов в пиковые периоды и их избытком в спокойные времена, что негативно сказывается на качестве медицинской помощи и эффективности использования бюджетных средств. Поэтому, для точного определения потребностей в ресурсах необходимы более сложные и адаптивные модели, учитывающие динамику и неопределенность потока пациентов.
Эффективное распределение ресурсов в больнице напрямую зависит от точного понимания потребности в них в каждом отделении. Грубые, усредненные прогнозы оказываются недостаточными, поскольку потребность в койках, медицинском персонале и оборудовании значительно различается между кардиологией, хирургией или отделением интенсивной терапии. Поэтому, для оптимизации использования ресурсов и обеспечения своевременной помощи пациентам, необходимы детальные, специализированные прогнозы спроса для каждого конкретного отделения. Такой гранулярный подход позволяет не только избежать перегрузки одних отделений и недоиспользования других, но и повысить общую эффективность работы больницы и качество оказываемой медицинской помощи.
Уровень сложности клинических групп (DRG) оказывает существенное влияние на потребление ресурсов в стационаре, что требует разработки прогностических моделей, учитывающих различную степень тяжести состояния пациентов. Более сложные случаи, требующие интенсивной терапии, специализированного оборудования и большего времени пребывания в больнице, закономерно увеличивают нагрузку на все подразделения. Исследования показывают, что традиционные методы прогнозирования, не принимающие во внимание вариабельность, связанную с DRG-классификацией, могут приводить к неоптимальному распределению ресурсов и снижению качества оказания медицинской помощи. Современные модели стремятся к интеграции данных о DRG-уровнях сложности с другими факторами, такими как сезонность заболеваний и демографические особенности населения, для повышения точности прогнозов и обеспечения эффективного использования больничных мощностей.
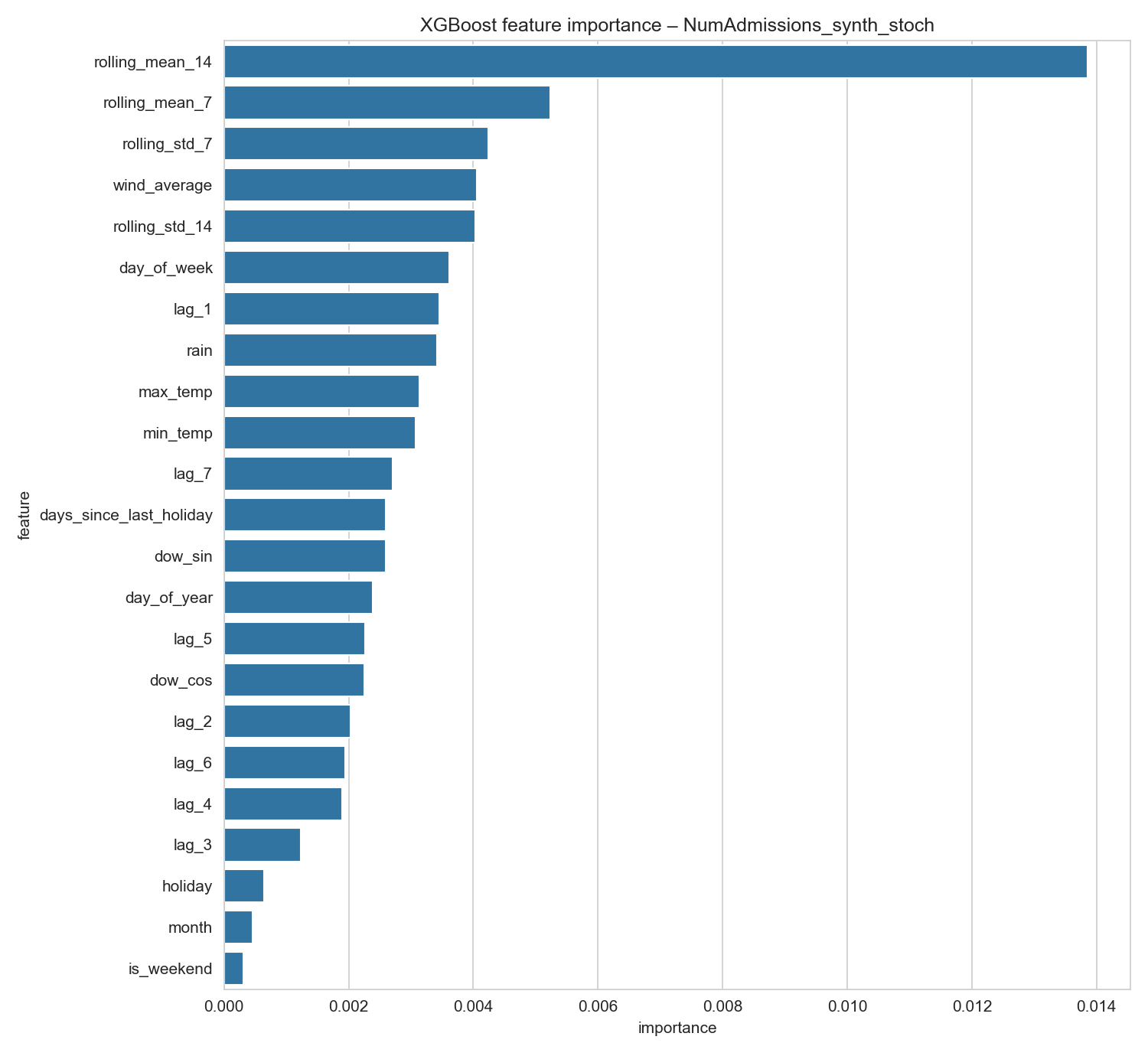
От статистического анализа к машинному обучению: Эволюция прогнозирования
Установленные методы анализа временных рядов, такие как модели ARIMA, SARIMAX и Seasonal Naive, служат базовым уровнем для оценки и сравнения более сложных прогностических подходов. Модель ARIMA (Autoregressive Integrated Moving Average) использует автокорреляцию данных для прогнозирования будущих значений, в то время как SARIMAX (Seasonal ARIMA with Exogenous Regressors) расширяет ARIMA, учитывая сезонность и внешние факторы. Seasonal Naive — это простейшая модель, предполагающая, что значения повторяются с определенным сезонным интервалом. Использование этих моделей позволяет установить минимально достижимую точность прогнозирования и оценить прирост эффективности, достигаемый за счет применения более сложных алгоритмов машинного обучения.
Более сложные методы машинного обучения, такие как LSTM (Long Short-Term Memory) и XGBoost (Extreme Gradient Boosting), позволяют учитывать сложные временные зависимости и нелинейные связи в данных. LSTM, являясь разновидностью рекуррентных нейронных сетей, эффективно обрабатывает последовательности данных, запоминая информацию о прошлых событиях и используя её для прогнозирования будущих значений. XGBoost, основанный на алгоритмах градиентного бустинга, способен моделировать нелинейные отношения между переменными, что позволяет повысить точность прогнозов по сравнению с традиционными статистическими методами. В контексте прогнозирования нагрузки на госпитали, эти модели могут учитывать различные факторы, влияющие на поступление пациентов, и выявлять сложные паттерны, которые не улавливаются простыми моделями временных рядов.
Для обучения и валидации моделей прогнозирования, включая статистические и алгоритмы машинного обучения, использовались общедоступные данные об общем количестве госпитализаций. Эти данные, как правило, собираются административными системами здравоохранения и содержат информацию о ежедневном или еженедельном количестве пациентов, поступающих в стационар. Использование таких данных позволяет создать базовый уровень прогнозирования и оценить эффективность более сложных моделей, а также обеспечивает возможность оперативного мониторинга и корректировки прогнозов в реальном времени на основе фактических данных о поступлениях.
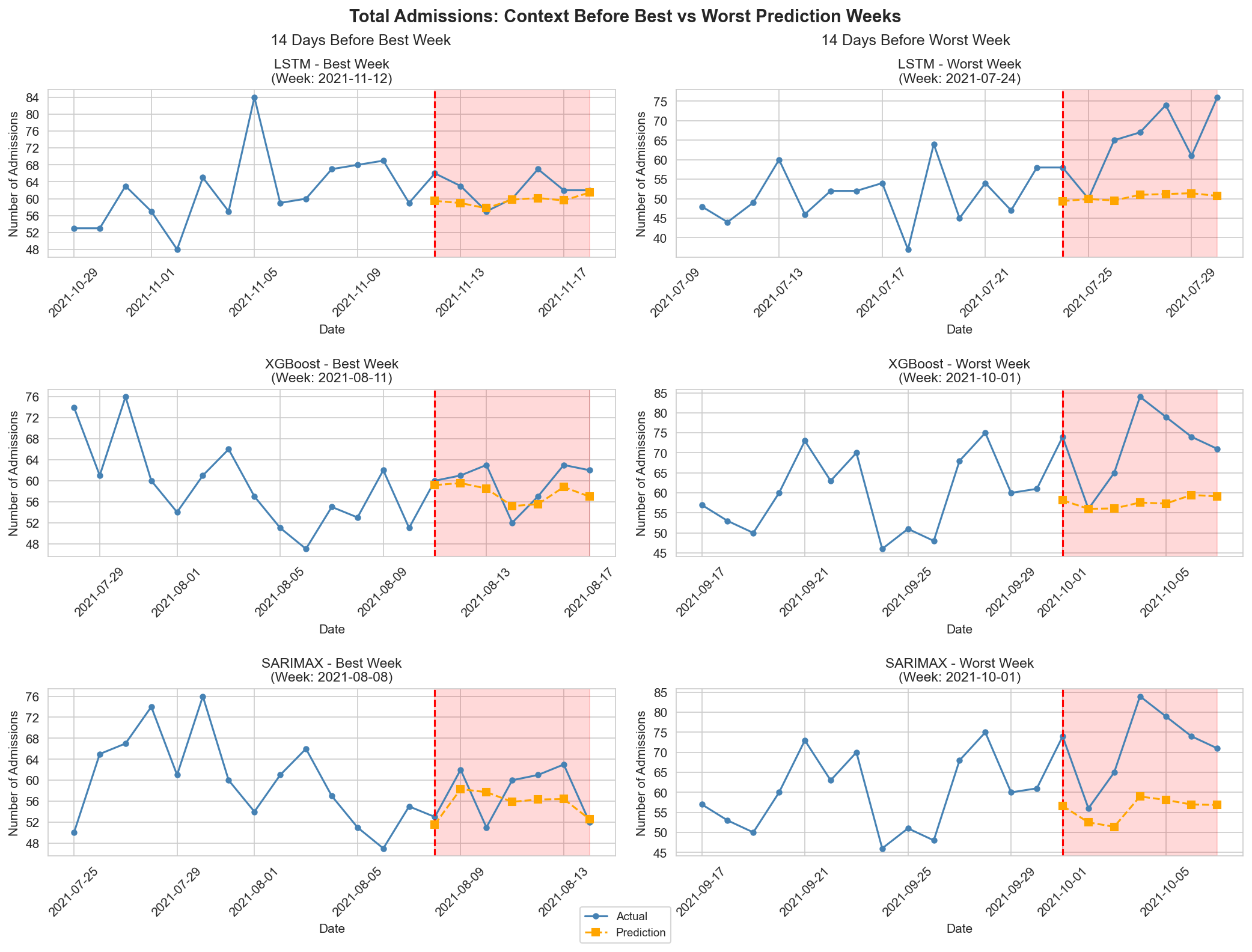
В ходе тестирования разработанных моделей прогнозирования общей госпитализации, средняя абсолютная процентная ошибка (MAPE) составила приблизительно 10-20%. Этот показатель свидетельствует о приемлемой точности прогнозов и подтверждает возможность использования предложенных методов для планирования ресурсов и оптимизации работы медицинских учреждений. Значение MAPE в данном диапазоне указывает на то, что в среднем, прогноз отклоняется от фактического значения на 10-20%, что является допустимым уровнем погрешности для задач краткосрочного и среднесрочного прогнозирования в сфере здравоохранения.
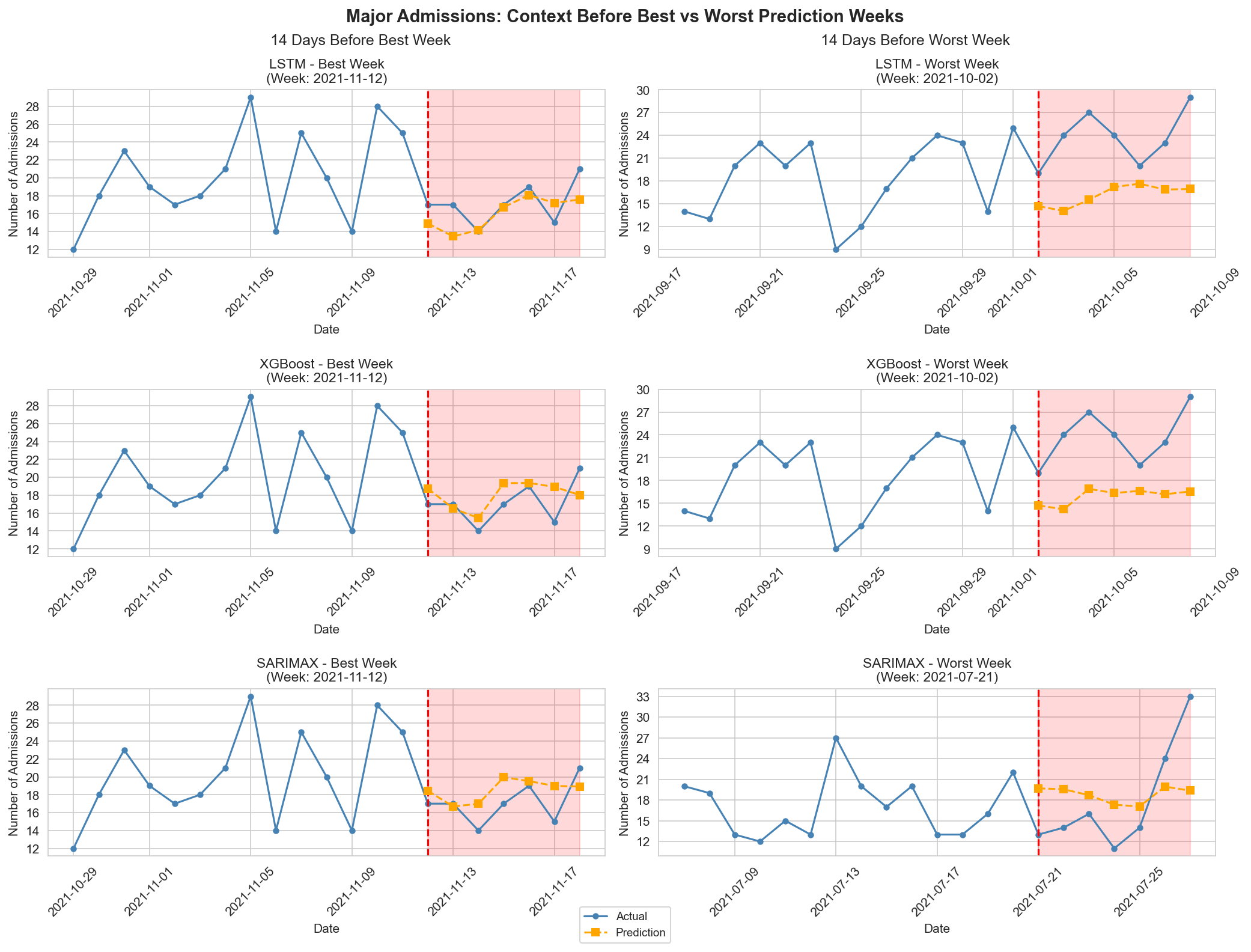
Точность моделей прогнозирования тесно связана со способностью адекватно отражать спрос по конкретным отделениям (Ward-Specific Demand). Неточное представление потребности в ресурсах отдельных отделений, например, хирургии, терапии или реанимации, приводит к систематическим ошибкам в прогнозе общей загрузки больницы. Модели, игнорирующие специфику нагрузки на каждое отделение, будут переоценивать или недооценивать потребность в койках, персонале и медикаментах. Таким образом, учет динамики спроса по каждому отделению является критически важным для повышения точности прогнозирования и эффективного распределения ресурсов, что подтверждается анализом влияния различных факторов на конечный результат.
Коррекция искажений: Синтетические контрфакты для надежного прогнозирования
Для смягчения влияния внешних факторов, искажающих исторические данные, была применена модель Prophet для генерации синтетических контрфактических данных. Данная модель позволила создать искусственно сгенерированный набор данных, заменяющий искаженные или отсутствующие исторические наблюдения. Это позволило обеспечить более репрезентативный набор данных для обучения моделей прогнозирования, компенсируя влияние аномальных событий и обеспечивая стабильность и достоверность результатов анализа временных рядов.
Искусственно сгенерированные данные используются для замены искаженных исторических наблюдений, что позволяет обучать модели на более репрезентативном наборе данных. Искажения в исторических данных могут возникать вследствие внешних факторов или аномалий, приводя к смещению и снижению точности прогнозов. Заменяя эти искаженные данные синтетическими, созданными на основе модели Prophet, мы обеспечиваем более объективную основу для обучения моделей, что способствует повышению их способности к обобщению и точному прогнозированию будущих значений. Этот подход особенно важен в ситуациях, когда доступные исторические данные не полностью отражают реальную динамику явления.
Сгенерированные синтетические контрфактические данные были интегрированы в существующие прогностические модели для повышения их устойчивости к искажениям в исторических данных. В частности, данные использовались для обучения и валидации как статистических моделей временных рядов SARIMAX, так и моделей машинного обучения, включая XGBoost и LSTM. Такой подход позволил оценить влияние корректировки исторических данных на точность прогнозирования в различных моделях и выявить оптимальные конфигурации для каждой из них, что является ключевым для поддержания стабильности прогнозов при внешних воздействиях и колебаниях спроса по отделениям.
При использовании модели SARIMAX для прогнозирования поступлений пациентов с высокой степенью сложности была достигнута средняя абсолютная процентная ошибка (MAPE) в 20.07%. В то же время, применение модели XGBoost для прогнозирования общего количества поступлений позволило добиться MAPE в 10.32%. Полученные результаты демонстрируют различную эффективность моделей в зависимости от типа прогнозируемых данных, при этом XGBoost показывает более высокую точность при прогнозировании общего числа поступлений, а SARIMAX — меньшую при прогнозировании поступлений пациентов с высокой степенью сложности.
Использование синтетических контрфактических данных направлено на повышение точности прогнозирования при наличии непредсказуемых событий и колебаний спроса в конкретных отделениях больницы (Ward-Specific Demand). В условиях, когда исторические данные искажены внешними факторами, искусственно сгенерированные данные позволяют обучать модели на более репрезентативном наборе, компенсируя влияние аномалий. Данный подход позволяет улучшить качество прогнозов, что критически важно для эффективного планирования ресурсов и обеспечения своевременной медицинской помощи. В ходе экспериментов, интеграция синтетических данных в статистические (SARIMAX) и машинные (XGBoost, LSTM) модели продемонстрировала снижение ошибки прогнозирования, подтверждая эффективность данного метода.
Понимание прогнозов: Превращение данных в действенные решения
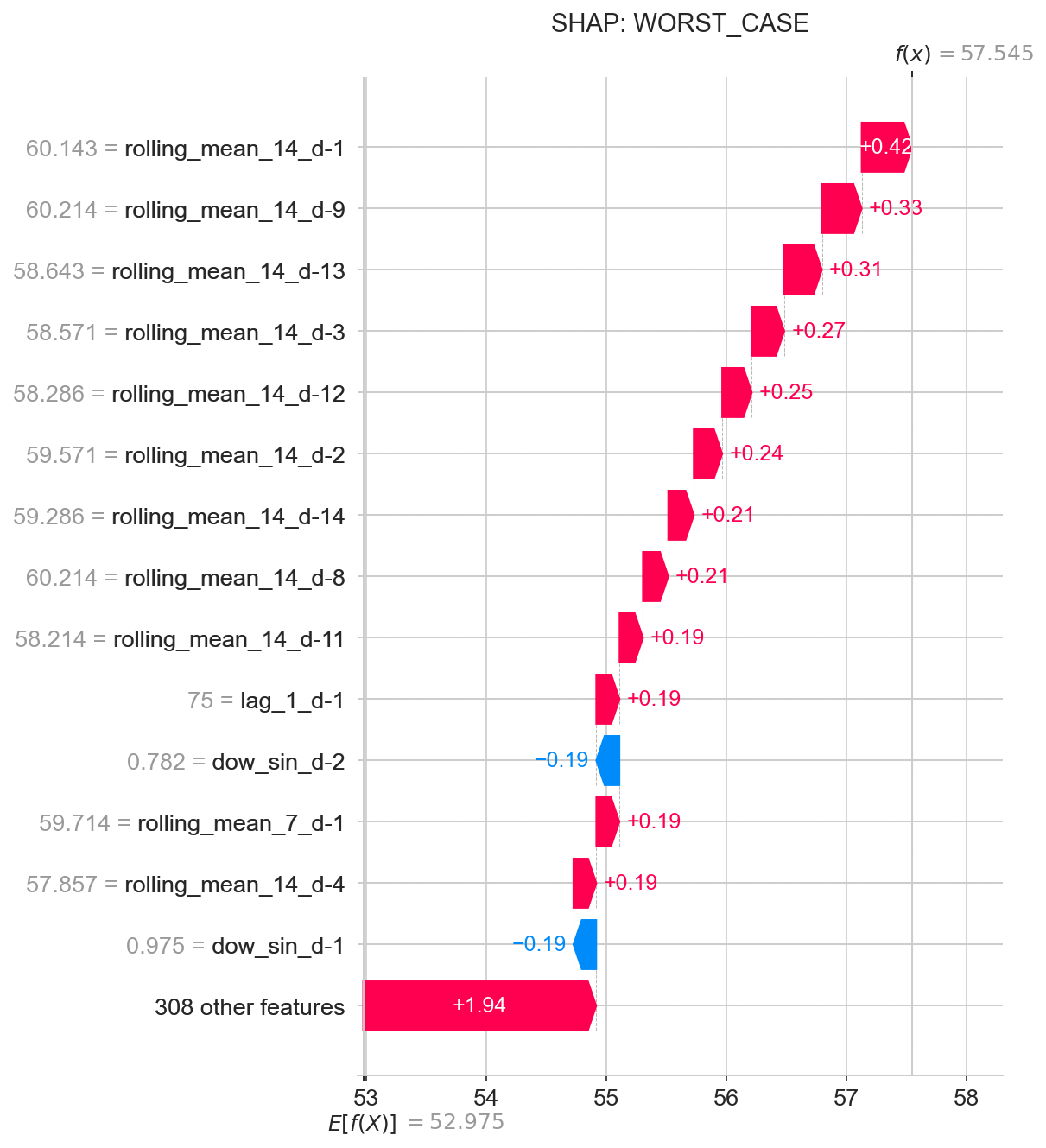
Для объяснения вклада каждой отдельной характеристики в прогнозы, полученные моделью XGBoost, были использованы значения SHAP (SHapley Additive exPlanations). Этот метод, основанный на теории игр, позволяет оценить, насколько каждая характеристика способствует отклонению прогноза от среднего значения. В результате анализа значений SHAP удалось не только определить, какие факторы наиболее сильно влияют на предсказания модели, но и понять, как именно каждый фактор влияет — увеличивает или уменьшает прогнозируемый спрос. Такой детальный анализ обеспечивает прозрачность модели и позволяет оценить надежность ее предсказаний, что критически важно для принятия обоснованных управленческих решений.
Анализ важности признаков в модели XGBoost позволил выявить ключевые факторы, определяющие спрос на ресурсы. Исследование показало, что такие переменные, как сезонность, количество поступающих пациентов и средняя продолжительность госпитализации оказывают наибольшее влияние на прогнозируемый спрос. Выделение этих доминирующих факторов предоставляет ценную информацию для оптимизации распределения ресурсов, позволяя администраторам больниц сосредоточиться на управлении именно этими переменными для повышения эффективности и улучшения качества обслуживания пациентов. В частности, понимание влияния сезонности позволяет заранее планировать увеличение запасов и персонала в периоды пикового спроса, что способствует более плавной работе системы здравоохранения.
Возможность интерпретации прогнозов модели позволяет администраторам больниц понимать не просто сколько ресурсов потребуется, но и почему модель пришла к такому выводу. Анализ вклада отдельных факторов, таких как сезонность, количество поступающих пациентов или специфические особенности отделений, раскрывает логику принятия решений моделью. Это знание критически важно для обоснования стратегических решений, например, увеличения штата в определенное время года или перераспределения ресурсов между отделениями. Вместо слепого следования прогнозам, администраторы получают инструмент для оценки рисков и возможностей, что приводит к более эффективному планированию и оптимизации использования ресурсов, а также к повышению качества оказания медицинской помощи.
Улучшение точности прогнозирования и повышение прозрачности моделей машинного обучения оказывают существенное влияние на оптимизацию распределения ресурсов в медицинских учреждениях и, как следствие, на качество оказания помощи пациентам. Осознание причин, по которым модель предсказывает определенный уровень потребности в ресурсах, позволяет администраторам больниц принимать более обоснованные решения, избегая как перерасхода, так и дефицита. Принимая во внимание различия в потребностях различных отделений — например, повышенная потребность в интенсивной терапии или специализированном оборудовании в кардиологическом отделении — становится возможным более точное и адресное распределение ресурсов. Такой подход не только снижает затраты, но и обеспечивает своевременное предоставление необходимой помощи каждому пациенту, что в конечном итоге способствует улучшению результатов лечения и повышению удовлетворенности пациентов.

Исследование, посвященное прогнозированию поступлений в отделения неотложной помощи, подчеркивает сложность точного предсказания редких всплесков спроса. Это напоминает о неизбежности старения любой системы, даже самой совершенной. Как отмечал Дональд Дэвис: «Все системы стареют — вопрос лишь в том, делают ли они достойно». Невозможно создать модель, которая бы идеально предсказывала все возможные сценарии, особенно учитывая динамичность и непредсказуемость потока пациентов. Важно не стремиться к недостижимому совершенству, а строить системы, способные адаптироваться и функционировать эффективно даже в условиях неопределенности, признавая, что технический долг, в данном случае — это неточности прогнозов, рано или поздно потребует корректировки.
Что впереди?
Представленное исследование, подобно любому логированию жизни системы, зафиксировало текущее состояние прогнозирования нагрузки на отделения неотложной помощи. Достигнута определенная точность в предсказании рутинных колебаний, но, как и в любой хронологии, редкие всплески спроса остаются тенью, ускользающей от алгоритмов. Это не недостаток моделей, но напоминание о том, что система здравоохранения — не статичный объект, а динамичная среда, подверженная непредсказуемым воздействиям.
Развертывание более сложных архитектур, безусловно, возможно, но истинный прогресс, вероятно, лежит в плоскости интеграции. Необходима не просто предсказательная модель, а система, способная адаптироваться к изменяющимся условиям в режиме реального времени, используя данные не только о прошлых поступлениях, но и о внешних факторах — эпидемиологической обстановке, погодных условиях, социальных событиях. Это переход от пассивного предсказания к активному управлению.
И, как всегда, остается вопрос о цене. Каждая дополнительная доля процента точности требует все больше вычислительных ресурсов и усилий. В конечном итоге, важно помнить, что цель — не создание идеальной модели, а обеспечение достойного функционирования системы в условиях неопределенности. Время — не метрика, а среда, и в этой среде все системы стареют.
Оригинал статьи: https://arxiv.org/pdf/2601.15481.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
- Золото прогноз
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-26 01:01