Автор: Денис Аветисян
Новая система, использующая постоянно обучаемые языковые модели, позволяет более точно прогнозировать актуальные темы в социальных сетях.
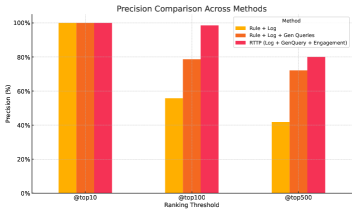
Исследование представляет RTTP — систему, использующую стратегию Mix-Policy DPO для генерации и ранжирования синтетических запросов, что позволяет улучшить предсказание трендов в режиме реального времени и избежать катастрофического забывания.
Обнаружение актуальных новостей в условиях низкой поисковой активности представляет собой фундаментальную проблему «холодного старта», когда недостаточный объем запросов препятствует выявлению новых или нишевых трендов. В данной работе, ‘Real-Time Trend Prediction via Continually-Aligned LLM Query Generation’, предложена система RTTP, использующая непрерывно обучаемую большую языковую модель (LLM) для генерации поисковых запросов непосредственно из новостного контента, а не ожидания пользовательских запросов. Ключевым нововведением является стратегия Mix-Policy DPO, обеспечивающая адаптацию модели без снижения ее производительности и предотвращения катастрофического забывания. Может ли такой подход к генерации синтетических поисковых сигналов открыть новые возможности для своевременного понимания трендов в условиях ограниченных данных?
Неизбежность Динамических Тенденций
Своевременное принятие решений напрямую зависит от способности выявлять зарождающиеся тенденции, однако существующие методы зачастую оказываются неэффективными при работе с быстро меняющимися данными. Традиционные подходы, основанные на анализе статичных массивов информации или упрощенных моделях, не способны уловить тонкие сдвиги в общественном мнении и оперативно реагировать на них. По мере увеличения скорости распространения информации и усложнения онлайн-коммуникаций, задача своевременного выявления новых трендов становится все более актуальной и требует разработки инновационных методов анализа данных, способных обрабатывать огромные потоки информации в режиме реального времени и прогнозировать будущие изменения.
Существующие методы анализа трендов зачастую опираются на устаревшие данные или упрощенные модели, что не позволяет адекватно отразить динамику онлайн-дискуссий. Традиционные подходы, сконцентрированные на статичных наборах данных, упускают из виду быстро меняющиеся интересы пользователей и контекст обсуждений. Это приводит к неточностям в прогнозировании и затрудняет своевременное принятие решений, поскольку упускается сложность и многогранность постоянно развивающихся онлайн-разговоров, где нюансы и скрытые смыслы играют ключевую роль. В результате, анализ ограничивается поверхностным пониманием текущих тенденций, не учитывая их эволюцию и потенциальные изменения.
Основная сложность заключается в эффективной обработке и интерпретации огромных объемов неструктурированного текста с целью выявления значимых изменений в общественном мнении. Современные методы анализа зачастую сталкиваются с трудностями при работе с данными, не имеющими четкой структуры, такими как публикации в социальных сетях, комментарии и онлайн-форумы. Выделение релевантной информации из этого потока требует разработки сложных алгоритмов, способных улавливать тонкие семантические сдвиги и отфильтровывать шум. Успешное решение этой задачи позволит оперативно отслеживать возникающие тренды, предвидеть общественные настроения и принимать обоснованные решения в различных сферах — от маркетинга и политики до здравоохранения и безопасности.
RTTP: Система Прогнозирования Тенденций в Реальном Времени
Система RTTP предназначена для прогнозирования трендов посредством генерации и взвешивания синтетических запросов, отражающих текущую онлайн-дискуссию. Вместо анализа непосредственно пользовательских публикаций, RTTP создает множество искусственных поисковых запросов, моделирующих вероятные интересы пользователей в режиме реального времени. Вес каждого запроса определяется на основе анализа актуальности и распространенности соответствующих тем в онлайн-пространстве. Комбинация этих взвешенных запросов позволяет системе выявлять зарождающиеся тренды и прогнозировать их развитие, обеспечивая более оперативную реакцию на изменения в общественном мнении по сравнению со статическими методами анализа.
В основе системы RTTP лежит CL-LLM — постоянно обновляемая языковая модель, предназначенная для преобразования неструктурированных текстовых публикаций в структурированные поисковые запросы. CL-LLM анализирует входящие данные, такие как посты в социальных сетях, и автоматически формирует запросы, пригодные для поиска релевантной информации. Постоянное обновление модели осуществляется путем обучения на новых данных, что позволяет ей адаптироваться к меняющимся тенденциям в онлайн-дискурсе и поддерживать высокую точность преобразования неструктурированного текста в структурированные запросы, необходимые для прогнозирования трендов.
В отличие от статических методов прогнозирования трендов, система RTTP обеспечивает более адаптивный подход благодаря непрерывному обучению на новых данных. Традиционные системы, использующие фиксированные параметры и исторические данные, часто отстают от быстро меняющейся онлайн-среды. RTTP, используя постоянно обновляемую языковую модель CL-LLM, динамически адаптируется к текущему дискурсу, что позволяет ей выявлять и прогнозировать тренды с большей оперативностью и точностью. Такой подход обеспечивает значительное повышение производительности, подтвержденное относительным улучшением точности на 91.4% (precision@500) по сравнению с базовыми методами.
Система RTTP использует платформы Facebook Search и Meta AI App для сбора данных и оценки эффективности. В ходе тестирования, RTTP продемонстрировала относительное улучшение точности на 91.4% по метрике precision@500 при обнаружении трендов, по сравнению с базовыми методами. Precision@500 измеряет долю релевантных результатов в первых 500 предсказаниях, что свидетельствует о значительно более высокой способности системы выявлять актуальные тенденции в режиме реального времени.

Борьба с Катастрофическим Забыванием в CL-LLM
Непрерывное обучение языковых моделей, таких как CL-LLM, подвержено явлению катастрофического забывания (catastrophic forgetting). Суть этого эффекта заключается в том, что при обучении на новых данных модель постепенно утрачивает знания, приобретенные на предыдущих этапах. Это происходит из-за того, что веса нейронной сети оптимизируются для текущей задачи, что может приводить к перезаписи или искажению представлений, сформированных ранее. В результате модель демонстрирует ухудшение производительности на старых задачах, даже если она продолжает хорошо справляться с новыми. Катастрофическое забывание представляет собой серьезную проблему для систем непрерывного обучения, требующих сохранения и интеграции знаний на протяжении длительного времени.
Для смягчения катастрофического забывания в процессе непрерывного обучения, мы используем стратегию Mix-Policy DPO (Direct Preference Optimization). Данный подход сочетает в себе данные, полученные в результате взаимодействия с моделью (on-policy), и данные из статических наборов данных (off-policy). Использование комбинации этих типов данных позволяет повысить стабильность процесса обучения и улучшить сохранение ранее усвоенных знаний, предотвращая резкое ухудшение производительности модели при поступлении новой информации. В частности, off-policy данные служат своеобразным “якорем”, удерживающим модель от полного забывания старых навыков, а on-policy данные обеспечивают адаптацию к новым задачам.
Стратегия Mix-Policy DPO, основанная на Direct Preference Optimization (DPO), решает проблему так называемого “эффекта сжатия” (squeezing effect), возникающего при оптимизации на основе предпочтений. Этот эффект проявляется в тенденции модели к снижению разнообразия рассуждений, когда она начинает отдавать предпочтение узкому спектру ответов, кажущихся наиболее вероятными. Mix-Policy DPO смягчает это, комбинируя данные, полученные как с использованием текущей политики (on-policy), так и данные, собранные ранее (off-policy). Такое смешанное обучение позволяет модели сохранять более широкую базу знаний и поддерживать разнообразие в процессе генерации ответов, предотвращая потерю способности к сложному и нестандартному мышлению.
Оценка модели CL-LLM с использованием эталонного теста MMLU продемонстрировала повышенную устойчивость к катастрофическому забыванию и улучшенные возможности рассуждения. В ходе месячного тестирования точность модели снизилась всего на 5%, что свидетельствует об эффективном сохранении ранее полученных знаний. Для сравнения, модели, обученные с использованием Supervised Fine-Tuning (SFT), продемонстрировали практически полную потерю точности, подтверждая превосходство подхода, используемого в CL-LLM, в задачах непрерывного обучения и долгосрочного сохранения информации.

Более Широкое Воздействие и Перспективы Развития
Система RTTP, основанная на сочетании CL-LLM и алгоритма Mix-Policy DPO, представляет собой надежное и гибкое решение для выявления зарождающихся тенденций в самых разных областях. В отличие от традиционных методов анализа, требующих ручного мониторинга и экспертной оценки, RTTP автоматически обрабатывает большие объемы данных из онлайн-источников, выявляя слабые сигналы и закономерности, предвещающие значительные изменения. Эта способность к адаптации и масштабируемости делает систему ценным инструментом не только для маркетинговых исследований и прогнозирования потребительского спроса, но и для оперативного реагирования в сфере общественного здравоохранения, управления кризисными ситуациями и мониторинга социальных настроений, позволяя своевременно выявлять и анализировать формирующиеся тренды.
Разработанная система, способная выявлять зарождающиеся тренды, имеет значительные последствия для широкого спектра областей. В сфере маркетинга она позволяет компаниям оперативно адаптироваться к меняющимся предпочтениям потребителей и оптимизировать рекламные кампании. В области общественного здравоохранения система может служить инструментом раннего предупреждения о вспышках заболеваний или изменениях в отношении к вакцинации. При управлении кризисными ситуациями она обеспечивает возможность быстрого реагирования на общественные настроения и предотвращения распространения дезинформации. Фактически, любая сфера, где понимание общественного мнения является критически важным, может извлечь выгоду из этой технологии, позволяющей более эффективно прогнозировать и реагировать на динамично меняющуюся обстановку.
Для повышения точности прогнозирования, дальнейшие исследования направлены на интеграцию системы RTTP с моделями анализа временных рядов, в частности, InceptionTime, успешно применяемой Amazon в обнаружении трендов. Такое объединение позволит не просто выявлять текущие запросы, но и прогнозировать их изменение во времени, учитывая закономерности и сезонность, характерные для больших объемов данных. Использование InceptionTime в сочетании с RTTP предполагает анализ исторических данных запросов, что позволит системе более эффективно предсказывать возникновение новых тенденций и отслеживать динамику уже существующих, существенно расширяя возможности для принятия обоснованных решений в различных сферах, от маркетинга до управления кризисными ситуациями.
Система RTTP продемонстрировала высокую точность генерации запросов, достигнув показателя в 90,5% и опередив базовые модели SFT на 4%. Данный результат свидетельствует о способности системы эффективно формулировать релевантные поисковые запросы для выявления возникающих трендов. Более того, интеграция статистических методов, таких как Пуассоновская модель, используемая в системах Google Trends и X, может значительно повысить чувствительность системы к незначительным изменениям в онлайн-активности. Это позволит RTTP не только фиксировать явные тенденции, но и предвидеть зарождающиеся изменения в общественном мнении и потребительском поведении, обеспечивая более прогностическую и адаптивную систему анализа трендов.

Системы предсказания трендов, как и любые сложные конструкции, обречены на компромиссы. Данная работа демонстрирует попытку смягчить неизбежное — катастрофическое забывание — посредством непрерывного обучения языковой модели. Подобный подход, безусловно, заслуживает внимания, хотя и напоминает попытку удержать воду решетом. Как однажды заметил Джон Маккарти: «Искусственный интеллект — это не создание машин, думающих как люди, а создание машин, которые могут делать вещи, которые требуют интеллекта». В контексте данной статьи, это означает не просто предсказание трендов, но и создание системы, способной адаптироваться к постоянно меняющемуся ландшафту социальных сетей, не теряя при этом ценность накопленных знаний. Иллюзия стабильности, не более.
Что Дальше?
Представленная работа, стремясь предсказывать тренды посредством непрерывно обучаемой языковой модели, неизбежно сталкивается с фундаментальным вопросом: возможно ли вообще ‘обучить’ систему предвидению? Скорее, речь идет не о построении пророка, а о культивировании сложной экосистемы, где каждая новая итерация обучения — это лишь очередная адаптация к непредсказуемости социальных потоков. Проблема катастрофического забывания, хотя и смягчена предложенной стратегией Mix-Policy DPO, остаётся тенью, напоминающей о том, что любое ‘знание’ — это лишь временное состояние, подверженное эрозии.
Вместо того, чтобы стремиться к совершенству предсказания, более плодотворным представляется путь к пониманию ошибок. Система, умеющая не столько угадывать тренды, сколько выявлять аномалии и неожиданные сдвиги в данных, окажется куда более ценной. Необходимо сместить фокус с максимизации точности на минимизацию риска неожиданных провалов. Ведь если система молчит, это не признак её мудрости, а лишь затишье перед бурей.
Будущие исследования, вероятно, будут сосредоточены на разработке методов, позволяющих модели не только генерировать запросы, но и оценивать степень своей собственной неопределенности. Необходимо научить систему признавать свои ограничения и сообщать о них. Иначе, в погоне за предсказанием трендов, можно легко потерять из виду главное — непредсказуемость самой жизни.
Оригинал статьи: https://arxiv.org/pdf/2601.17567.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-27 22:32