Автор: Денис Аветисян
Новое исследование показывает, как модели искусственного интеллекта способны выявлять значимые связи между событиями на рынках прогнозирования, отсеивая случайные корреляции и повышая точность прогнозов.

В статье представлен метод семантической фильтрации на основе больших языковых моделей для выявления причинно-следственных связей во временных рядах рынков прогнозирования и снижения рисков при торговле на основе стратегии «лидер-ведомый».
Несмотря на растущую популярность рынков предсказаний, выявление устойчивых взаимосвязей между событиями затруднено из-за ложных корреляций. В работе ‘LLM as a Risk Manager: LLM Semantic Filtering for Lead-Lag Trading in Prediction Markets’ предложен гибридный подход, сочетающий статистический анализ (причинность Грейнджера) и семантическую фильтрацию на основе больших языковых моделей для выявления взаимосвязей между событиями. Показано, что LLM выступают в роли «семантического риск-менеджера», отсеивая статистически хрупкие связи и фокусируясь на тех, что имеют правдоподобные экономические механизмы, что приводит к снижению убытков и повышению стабильности стратегий торговли. Возможно ли дальнейшее развитие данного подхода для создания более надежных и адаптивных торговых систем на рынках предсказаний?
Раскрытие скрытых сигналов на рынках предсказаний
Рынки предсказаний генерируют обширные временные ряды данных на уровне отдельных событий, предоставляя уникальные возможности для выявления опережающих индикаторов. В отличие от традиционных финансовых рынков, где информация рассеяна и зашумлена, рынки предсказаний концентрируют коллективные прогнозы относительно будущих событий, создавая четкие сигналы, отражающие ожидания участников. Эти данные, фиксирующие изменения вероятностей исходов во времени, позволяют исследователям анализировать динамику прогнозов и обнаруживать закономерности, предшествующие фактическому наступлению событий. Изучение таких временных рядов дает возможность выявить скрытые взаимосвязи и предсказать будущие тенденции с большей точностью, чем при использовании традиционных методов анализа, что делает рынки предсказаний ценным источником информации для различных областей, от экономики и политики до науки и технологий.
Традиционные статистические методы зачастую оказываются неэффективными при анализе данных, генерируемых предсказательными рынками, из-за сложности выявления истинных причинно-следственных связей. Обилие временных рядов и взаимозависимостей между событиями приводит к тому, что случайные корреляции легко могут быть ошибочно приняты за реальные опережающие индикаторы. Проблема усугубляется нелинейностью и динамичностью данных, что требует применения более сложных подходов, способных отделить значимые закономерности от статистического шума. В результате, стандартные методы, такие как автокорреляция или регрессионный анализ, часто дают ложные сигналы, снижая точность прогнозов и затрудняя принятие обоснованных решений.
Установление причинно-следственных связей между сигналами на рынках прогнозирования и последующими событиями имеет первостепенное значение для создания надежных прогностических моделей. Точное выявление этих взаимосвязей позволяет не только повысить точность предсказаний, но и обосновать принятие взвешенных решений в различных областях — от финансового анализа и управления рисками до прогнозирования политических событий и оценки потребительского спроса. Игнорирование этой необходимости может привести к построению хрупких моделей, подверженных ошибкам и неспособных адаптироваться к меняющимся условиям, что в конечном итоге снижает эффективность прогнозирования и качество принимаемых решений. Таким образом, акцент на выявлении истинных взаимосвязей является ключевым фактором для обеспечения надежности и практической ценности рынков прогнозирования.
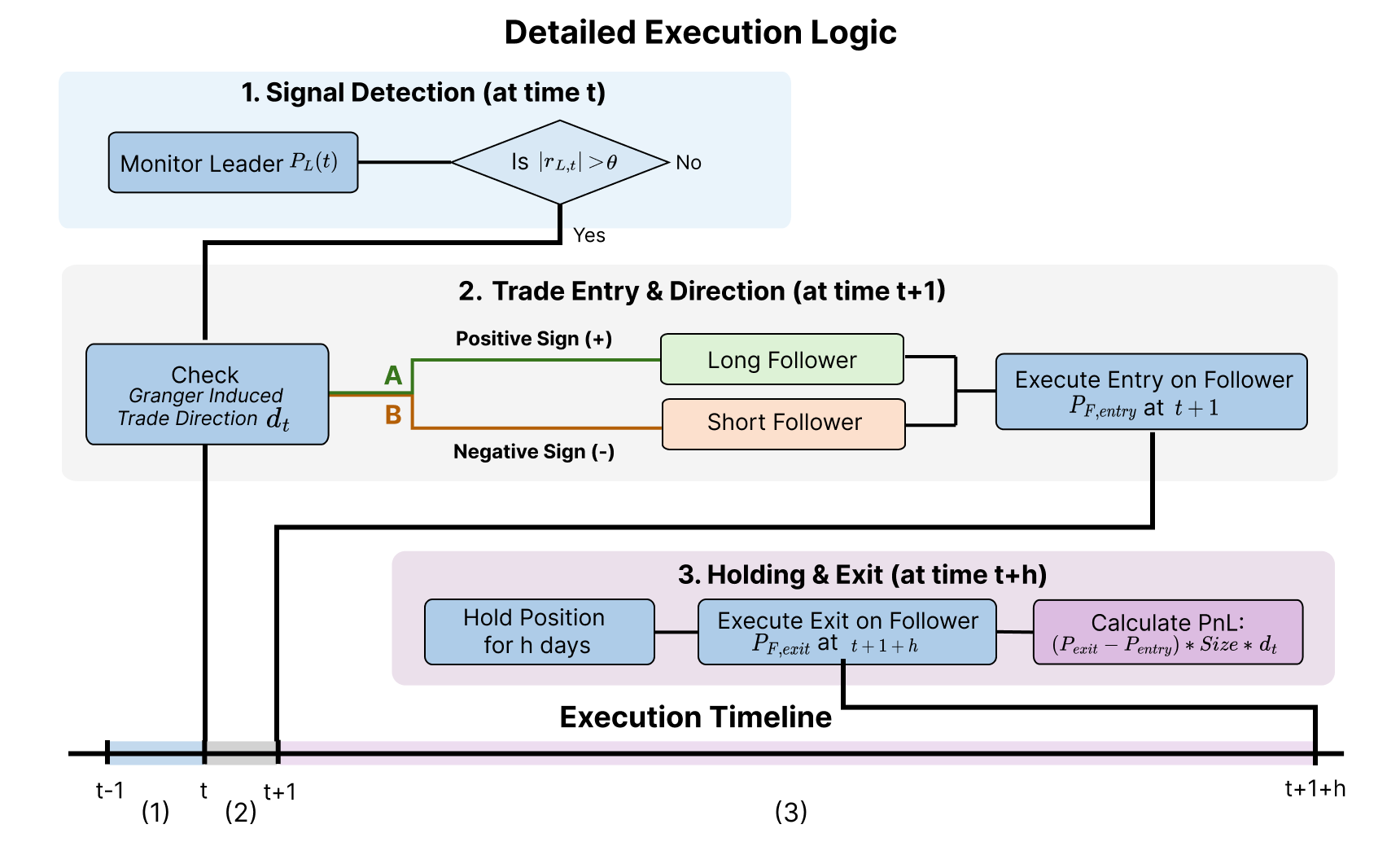
Статистические основы: выявление потенциальных ведущих связей
Причинность Грейнджера — это статистический метод, используемый для определения, может ли одна временная серия прогнозировать другую. В основе метода лежит проверка гипотезы о том, что прошлые значения одной серии содержат информацию, полезную для прогнозирования текущих значений другой серии, что указывает на потенциальную причинно-следственную связь, хотя и не обязательно истинную причинность. Формально, если включение прошлых значений временного ряда X_t улучшает прогноз Y_t, то говорят, что X_t причинно связано с Y_t по Грейнджеру. Метод широко применяется в эконометрике, нейронауке и анализе временных рядов для выявления потенциальных взаимосвязей и зависимостей между переменными.
Эффективное применение анализа причинности Грейнджера требует, чтобы анализируемые временные ряды были стационарными. Нестационарность, проявляющаяся в наличии тренда или сезонности, может привести к ложным результатам. Для достижения стационарности часто используются методы предобработки, такие как дифференцирование, заключающееся в вычислении разностей между последовательными значениями ряда. Дифференцирование первого порядка, \Delta X_t = X_t - X_{t-1} , является наиболее распространенным методом, позволяющим устранить линейный тренд. В некоторых случаях может потребоваться применение дифференцирования более высокого порядка или других методов, например, сезонного дифференцирования, для обеспечения стационарности ряда перед проведением анализа причинности Грейнджера.
Векторные авторегрессионные (VAR) модели представляют собой статистический инструмент, предназначенный для анализа взаимосвязей между несколькими временными рядами. В отличие от унивариантного анализа, VAR модели одновременно рассматривают несколько переменных как эндогенные, что позволяет учесть их взаимное влияние. Модель VAR порядка p выражает каждую переменную как линейную функцию от её собственных прошлых значений и прошлых значений других переменных в системе. Это достигается путем построения системы уравнений, где каждая переменная регрессируется на лаги всех переменных, включенных в модель. Использование VAR моделей является ключевым этапом при проведении анализа причинности по Грейнджеру, поскольку позволяет оценить, предсказывает ли прошлое одной временной серии будущее другой, учитывая при этом влияние всех остальных переменных в модели.
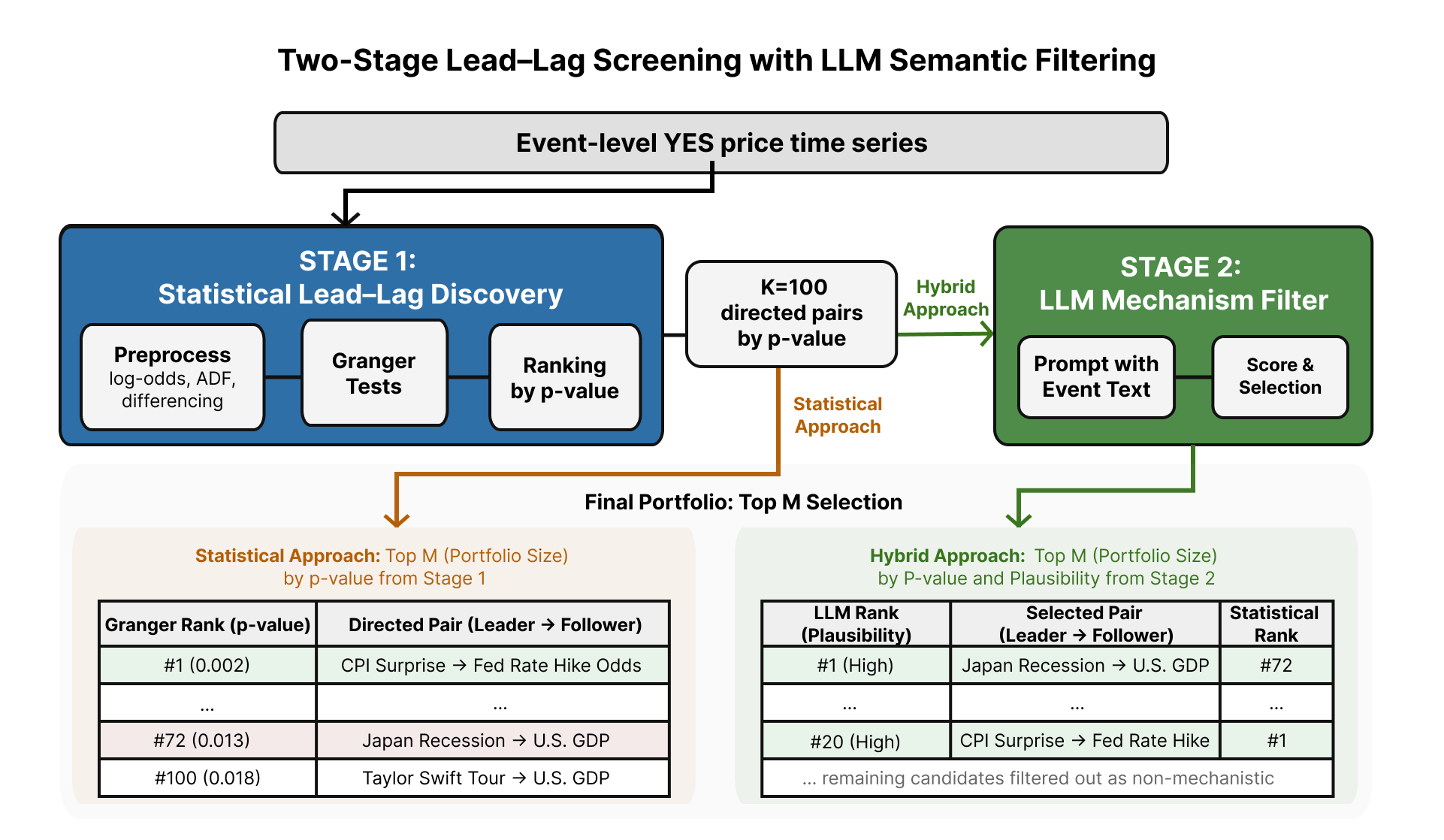
За пределами статистики: подтверждение правдоподобными механизмами
Предложенный гибридный подход объединяет преимущества статистического скрининга с контекстуальным пониманием больших языковых моделей (LLM). Статистический скрининг позволяет быстро выявлять потенциальные взаимосвязи между переменными в больших объемах данных, используя количественные методы для определения статистической значимости. В то же время, LLM обеспечивают возможность оценки правдоподобности этих взаимосвязей, анализируя контекст и логическую согласованность выявленных зависимостей. Сочетание этих двух методов позволяет не только идентифицировать корреляции, но и оценивать их осмысленность, что повышает надежность и интерпретируемость результатов анализа.
Для валидации статистически выявленных взаимосвязей между переменными, в частности, опережающих (lead-lag) зависимостей, используются большие языковые модели (LLM). LLM анализируют логическую обоснованность этих связей, оценивая, насколько вероятно, что изменение одной переменной действительно может привести к изменению другой. Этот процесс позволяет отфильтровывать ложные корреляции, возникающие случайно или из-за скрытых факторов, которые не учитываются статистическим анализом. Фактически, LLM выступает в роли эксперта, проверяющего правдоподобие выявленных закономерностей и повышающего надежность и интерпретируемость результатов анализа временных рядов.
Интеграция статистического анализа и логического вывода, осуществляемая с помощью больших языковых моделей (LLM), повышает устойчивость модели за счет проверки выявленных корреляций на правдоподобность. Статистическая значимость взаимосвязей, установленных на основе анализа данных, подвергается дополнительной оценке LLM, которые анализируют, соответствует ли обнаруженная зависимость логически обоснованному механизму. Такой подход позволяет отсеивать ложные корреляции, возникающие случайно, и фокусироваться на взаимосвязях, имеющих под собой рациональное объяснение, что в свою очередь повышает надежность и обобщающую способность модели при работе с новыми данными.
Строгая оценка и прирост производительности
Для оценки прогностической способности разработанного гибридного подхода использовалась методика последовательной (rolling) оценки. Данный метод предполагает разделение данных на последовательные временные периоды, в которых модель обучается на предыдущих периодах и тестируется на текущем, не использовавшемся в обучении, периоде. Процесс повторяется последовательно по всему набору данных, обеспечивая надежную оценку производительности модели на невидимых данных и позволяя избежать переобучения. Такой подход позволил получить объективную оценку эффективности гибридной модели в реальных рыночных условиях.
Результаты тестирования показали существенное увеличение общей прибыли (Total PnL) на 205% при использовании гибридного подхода, включающего LLM-верифицированные взаимосвязи лидирования и запаздывания. Данный прирост прибыли был зафиксирован в процессе роллинговой оценки, что подтверждает эффективность интеграции лингвистического анализа в процесс принятия торговых решений. Увеличение PnL является результатом более точного выявления и использования рыночных взаимосвязей, что позволяет максимизировать прибыль от успешно предсказанных сделок.
Анализ показал, что применение данного подхода существенно снижает риски убытков. Среднее снижение величины убытков (Average Loss Magnitude) составило 46.5% по сравнению с использованием исключительно статистических сигналов. Это означает, что в периоды неблагоприятных рыночных условий, система, использующая валидацию LLM для определения лидирующих и отстающих связей, демонстрирует значительно меньшие потери, обеспечивая более стабильную и предсказуемую доходность.
Анализ показал стабильное снижение величины убытков (Average Loss Magnitude) в диапазоне от 22.6% до 48.1% при использовании различных пар событий и периодов удержания позиций. Это указывает на то, что предложенный подход к снижению риска демонстрирует устойчивые результаты вне зависимости от конкретной комбинации анализируемых событий и временного горизонта. Измерения проводились на основе исторических данных и отражают среднее снижение убытков по всем протестированным сценариям.
Последствия и направления дальнейших исследований
Предложенный гибридный подход, объединяющий статистическое моделирование и возможности больших языковых моделей, обладает значительным потенциалом для применения в различных сферах, выходящих за рамки предсказательных рынков. В частности, в финансах это может способствовать более точному анализу рисков и прогнозированию динамики цен активов. В экономике данный подход позволит усовершенствовать моделирование макроэкономических показателей и прогнозирование экономических циклов. В сфере управления цепочками поставок гибридная система может оптимизировать логистические процессы, предсказывать сбои и обеспечивать более устойчивое снабжение. Возможность валидации статистических взаимосвязей с помощью языковых моделей повышает надежность прогнозов и обеспечивает более глубокое понимание сложных систем, открывая новые горизонты для принятия обоснованных решений в различных отраслях.
Включение больших языковых моделей (LLM) в процесс проверки статистических взаимосвязей открывает новые возможности для повышения надежности и понятности прогностических моделей, особенно в сложных системах. Традиционные статистические методы часто сталкиваются с трудностями при интерпретации результатов и выявлении ложных корреляций. LLM, обученные на огромных объемах текстовых данных, способны анализировать контекст и логическую согласованность выявленных зависимостей, подтверждая или опровергая их правдоподобность. Такой подход позволяет не просто предсказывать результаты, но и объяснять, почему модель пришла к определенному выводу, что существенно повышает доверие к ней и облегчает принятие обоснованных решений. В результате, прогностические модели становятся более устойчивыми к шуму и выбросам, а их результаты — более интерпретируемыми для экспертов и лиц, принимающих решения.
Дальнейшие исследования направлены на усовершенствование процесса оценки, осуществляемой большими языковыми моделями (LLM). Особое внимание уделяется повышению точности и надежности этой оценки, что позволит более эффективно выявлять и подтверждать статистические взаимосвязи в сложных системах. Планируется расширение области применения данного подхода, включая анализ значительно более крупных и сложных наборов данных, охватывающих разнообразные сферы, такие как финансовые рынки, экономическое моделирование и управление цепочками поставок. Улучшение алгоритмов оценки LLM позволит не только повысить предсказательную силу моделей, но и углубить понимание лежащих в их основе закономерностей, открывая новые возможности для принятия обоснованных решений.
Исследование демонстрирует, что большие языковые модели способны улавливать закономерности в динамике предсказательных рынков, отсеивая случайные корреляции и выделяя связи, подкрепленные экономической логикой. Это особенно важно, учитывая, что простое обнаружение опережающих индикаторов не гарантирует истинной причинно-следственной связи. В связи с этим, как некогда заметил Жан-Поль Сартр: «Существование предшествует сущности». Подобно тому, как человек создает себя посредством выбора, модель выявляет значимые взаимосвязи, отбрасывая наносное и фокусируясь на реальных движущих силах рынка. Игнорирование этого принципа приводит к иллюзорным выводам и неверным прогнозам.
Куда же это всё ведёт?
Представленная работа демонстрирует, что большие языковые модели способны отсеивать статистический шум в данных рынков предсказаний, выделяя связи между событиями, имеющие хоть какую-то экономическую логику. Однако, следует помнить: модель — это не зеркало реальности, а зеркало аналитика, отражающее его представления о «логичности». Критерий значимости обнаруженных связей, увы, остаётся вопросом интерпретации, а не строгой математики. Идея фильтрации на основе «правдоподобия» — интересная, но требует более чёткой формализации, дабы избежать субъективности.
Перспективным направлением представляется не просто выявление опережающих связей (Granger causality), а построение полноценных каузальных моделей, учитывающих множество взаимосвязанных факторов. Проблема в том, что корреляция, даже отфильтрованная языковой моделью, ещё не доказывает причинно-следственную связь. Требуется интеграция с методами, позволяющими оценивать силу и направленность влияния одного события на другое, а не просто констатировать факт их временной последовательности.
В конечном счёте, вопрос не в том, чтобы найти «идеальный» алгоритм для торговли на рынках предсказаний, а в том, чтобы создать инструмент, позволяющий более глубоко понимать динамику событий и оценивать риски. И если модель помогает избежать очевидных ошибок — это уже неплохо. Но эйфории от слова «инсайт» следует избегать — всегда полезно спросить: а где критерий его значимости?
Оригинал статьи: https://arxiv.org/pdf/2602.07048.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-10 21:44