Автор: Денис Аветисян
Новый подход объединяет глубокое обучение с символьным ИИ для создания самообъясняющихся агентов, способных к проактивному управлению сетевыми системами.
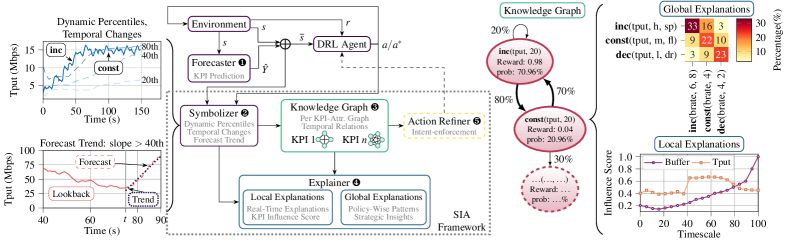
Представлена методика SIA, использующая графы знаний для обеспечения интерпретируемости агентов глубокого обучения с подкреплением, позволяющая повысить эффективность и надежность управления сетями без переобучения.
Несмотря на перспективность адаптивного управления в сетях связи будущего, современные агенты глубокого обучения с подкреплением часто действуют реактивно, игнорируя краткосрочные прогнозы ключевых показателей эффективности. В данной работе, представленной под названием ‘SIA: Symbolic Interpretability for Anticipatory Deep Reinforcement Learning in Network Control’, предлагается система SIA, обеспечивающая интерпретируемость действий агентов, использующих прогнозы для проактивного управления. SIA объединяет символьные представления искусственного интеллекта с графами знаний для объяснения решений в реальном времени, включая новую метрику — «Влияние». Может ли подобный подход к прозрачности и настройке агентов значительно упростить внедрение проактивного управления в мобильных сетях нового поколения?
Динамические сети: вызов предсказуемости
Традиционные системы управления сетями, как правило, опираются на статические конфигурации, что создает значительные трудности в условиях постоянно меняющихся требований и непредсказуемой нагрузки. Они рассчитаны на заранее определенные сценарии и не способны эффективно адаптироваться к внезапным всплескам трафика, изменениям в топологии сети или появлению новых приложений с уникальными потребностями. В результате, сети, управляемые подобным образом, часто испытывают задержки, снижение производительности и даже сбои, особенно в периоды пиковой нагрузки или при возникновении неожиданных событий. Это особенно актуально в современных динамичных средах, где количество подключенных устройств и объем передаваемых данных постоянно растут, а потребности пользователей становятся все более разнообразными и непредсказуемыми.
Эффективная адаптация сетевых систем требует прогнозирования будущих состояний сети, что выходит за рамки возможностей реактивных систем. Традиционные методы управления реагируют на уже произошедшие изменения, что приводит к задержкам и снижению производительности в динамичной среде. Предсказание будущего состояния сети — сложная задача, требующая анализа множества факторов, включая поведение пользователей, внешние события и характеристики сетевого трафика. Реактивные системы, основанные на немедленном отклике на изменения, попросту не способны оперативно справляться с неожиданными пиками нагрузки или внезапными отказами оборудования. Поэтому для обеспечения стабильной и эффективной работы сети необходимы проактивные системы, способные предвидеть будущие потребности и заблаговременно адаптировать свою конфигурацию, обеспечивая бесперебойное функционирование даже в условиях высокой неопределенности.
Для эффективного управления современными сетевыми инфраструктурами требуется переход от реактивных к проактивным стратегиям контроля, основанным на машинном обучении. Традиционные подходы, полагающиеся на заранее заданные конфигурации, оказываются неэффективными в условиях постоянно меняющихся нагрузок и непредсказуемого поведения пользователей. Вместо того чтобы просто реагировать на возникающие проблемы, системы нового поколения способны предвидеть будущие состояния сети, анализируя исторические данные и текущие тенденции. Использование алгоритмов обучения с подкреплением и глубоких нейронных сетей позволяет динамически адаптировать сетевые параметры, оптимизируя производительность и обеспечивая стабильную работу даже в условиях пиковых нагрузок и внезапных изменений. Такой подход позволяет не только минимизировать задержки и потери пакетов, но и повысить общую эффективность использования сетевых ресурсов, открывая возможности для более сложных и требовательных приложений.
Современные методы управления сетями зачастую оказываются неспособными эффективно использовать прогнозы внешних факторов, оказывающих влияние на их производительность. Это связано с тем, что традиционные алгоритмы ориентированы на реактивное управление, то есть на адаптацию к уже произошедшим изменениям, а не на предвидение и смягчение их последствий. Например, внезапный всплеск трафика, вызванный популярным онлайн-событием, или изменение погодных условий, влияющих на качество беспроводной связи, могут привести к значительному ухудшению работы сети, если система не способна заранее предвидеть и компенсировать эти факторы. Разработка методов, позволяющих интегрировать прогнозы, касающиеся поведения пользователей, внешних событий и даже климатических изменений, представляется ключевой задачей для обеспечения стабильной и эффективной работы современных сетевых инфраструктур.

Интеллектуальные агенты для проактивного управления
Глубокое обучение с подкреплением (DRL) представляет собой эффективный инструментарий для разработки адаптивных контроллеров сети. В отличие от традиционных методов, требующих ручной настройки и предварительного определения правил управления, DRL позволяет агенту самостоятельно обучаться оптимальной политике управления посредством взаимодействия со средой. Архитектуры глубоких нейронных сетей используются для аппроксимации функций ценности и политики, что позволяет DRL справляться со сложными, нелинейными задачами управления, характерными для современных сетевых инфраструктур. Обучение происходит итеративно, с использованием алгоритмов, таких как Q-learning или Policy Gradient, позволяющих агенту корректировать свои действия на основе получаемых вознаграждений и штрафов, и в конечном итоге достигать желаемого уровня производительности сети.
Агент глубокого обучения с подкреплением (DRL) формирует оптимальную стратегию управления посредством последовательных проб и ошибок. В процессе обучения агент взаимодействует со средой, выполняя действия и получая числовые вознаграждения (rewards), отражающие эффективность этих действий. Целью является максимизация суммарного вознаграждения, что достигается путем корректировки стратегии управления на основе полученного опыта. Алгоритмы DRL позволяют агенту изучать наиболее эффективные действия в различных ситуациях, адаптируясь к изменяющимся условиям и оптимизируя производительность системы, не требуя явного программирования каждой возможной ситуации. Эффективность обучения напрямую зависит от функции вознаграждения и качества данных, используемых для обучения агента.
Ключевым аспектом использования обучения с подкреплением является способность точно прогнозировать ключевые показатели эффективности (KPI), как контролируемые агентом параметры сети, так и внешние, не зависящие от него факторы. Точное предсказание KPI позволяет агенту оценивать потенциальные результаты своих действий и, следовательно, оптимизировать стратегию управления для достижения поставленных целей. Прогнозирование должно учитывать временные зависимости и динамику изменения KPI, а также учитывать корреляции между различными показателями для повышения точности предсказаний и эффективности управления.
Методы обучения с использованием временных различий (Temporal Difference Learning, TD-Learning) являются ключевыми для обеспечения возможности агента прогнозировать будущие вознаграждения и оптимизировать действия. TD-Learning позволяет агенту оценивать ценность состояний, обновляя эти оценки на основе разницы между ожидаемым и фактическим вознаграждением, полученным после перехода в новое состояние. Этот итеративный процесс, основанный на уравнении Беллмана, позволяет агенту учиться предсказывать долгосрочные вознаграждения, даже если непосредственное вознаграждение отсутствует. Алгоритмы, такие как Q-Learning и SARSA, используют принципы TD-Learning для определения оптимальной стратегии действий, максимизирующей суммарное вознаграждение в долгосрочной перспективе. V(s) = R + \gamma \max_a Q(s', a), где γ — коэффициент дисконтирования.
Повышение точности прогнозирования и эффективности агентов
Высокоточная прогностическая аналитика достигается за счет применения передовых моделей временных рядов, в частности, архитектуры PatchTST. PatchTST, в отличие от традиционных подходов, обрабатывает временные ряды как последовательность патчей, что позволяет эффективно захватывать долгосрочные зависимости и повышать точность прогнозирования. Данная архитектура использует механизм внимания для выделения наиболее релевантных патчей, что позволяет модели фокусироваться на ключевых аспектах данных и игнорировать шум. Эффективность PatchTST подтверждена в различных задачах, требующих точного прогнозирования временных рядов, таких как прогнозирование нагрузки сети, оптимизация ресурсов и планирование.
Многослойные персептроны (MLP) обеспечивают надежные возможности прогнозирования благодаря своей способности моделировать нелинейные зависимости в данных временных рядов. Для повышения устойчивости и скорости обучения MLP применяются методы, такие как обратная нормализация экземпляров (Reversible Instance Normalization — RIN). RIN нормализует активации каждого экземпляра в пакете, что позволяет избежать проблем с исчезающими или взрывающимися градиентами, особенно при работе с длительными последовательностями. Это приводит к улучшению обобщающей способности модели и повышению точности прогнозов, что критически важно для задач управления ресурсами в беспроводных сетях.
Для дальнейшего повышения эффективности, модуль уточнения действий (Action Refinement Module) использует прогнозы, полученные с помощью моделей временных рядов и многослойных персептронов, для корректировки существующей политики агента обучения с подкреплением (DRL). В результате тестирования на задачах выделения ресурсов радиодоступа (RAN slicing) зафиксировано увеличение суммарной награды до 25.7%, а в задачах планирования Massive MIMO — улучшение на 12.0%. Данный подход позволяет повысить производительность DRL-агентов за счет интеграции точных прогнозов в процесс принятия решений.
Эффективность предложенной системы была подтверждена путем интеграции агентов, обученных с подкреплением (DRL), с методами адаптивной потоковой передачи данных (Adaptive Bitrate Streaming), планирования Massive MIMO и сегментации радиосети (RAN Slicing). Результаты экспериментов показали увеличение скорости передачи данных на 9% после переработки архитектуры агента. Данное улучшение демонстрирует практическую применимость предложенного подхода к оптимизации производительности беспроводных сетей в различных сценариях.

Интерпретируемый искусственный интеллект: фреймворк SIA
Разработанная структура «Символическая интерпретация искусственного интеллекта» (SIA) предлагает принципиально новый подход к пониманию логики работы агентов, основанных на обучении с подкреплением (DRL) и способных к прогнозированию. В отличие от традиционных «черных ящиков», SIA позволяет проследить ход мыслей агента, раскрывая, какие факторы и знания формируют его решения. Эта система не просто предоставляет результат, но и объясняет, как этот результат был достигнут, делая процесс принятия решений прозрачным и понятным. Благодаря этому, исследователи и разработчики получают возможность не только оценить эффективность агента, но и выявить потенциальные ошибки или предубеждения в его логике, что критически важно для создания надежных и ответственных систем искусственного интеллекта.
В основе системы интерпретации искусственного интеллекта лежит использование графов знаний, формируемых для каждого ключевого показателя эффективности (KPI). Эти графы представляют собой структурированное отображение понимания агентом состояния сети и доступных действий. Каждый узел в графе соответствует конкретному элементу состояния или действию, а связи между узлами отражают взаимосвязи, установленные агентом в процессе обучения с подкреплением. Такой подход позволяет агенту не просто принимать решения, но и формировать внутреннюю модель мира, которую можно визуализировать и анализировать, что значительно повышает прозрачность и надежность системы принятия решений.
Метрика влияния, или Influence Score (IS), представляет собой ключевой элемент количественной оценки в процессе принятия решений агентом. Она позволяет определить, насколько сильно каждый из ключевых показателей эффективности (KPI) влияет на выбор конкретного действия. IS вычисляется на основе анализа изменений в стратегии агента при незначительных изменениях в значениях KPI, таким образом выявляя наиболее значимые факторы, определяющие поведение системы. Более высокий показатель IS указывает на более существенное влияние соответствующего KPI на процесс принятия решений, что позволяет не только понять логику агента, но и оценить его чувствительность к изменениям в окружающей среде. Таким образом, IS выступает инструментом для интерпретации «внутренней» логики агента и повышения доверия к его действиям.
Разработанный конвейер Symbolic AI Interpretation (SIA) демонстрирует возможность получения объяснений в режиме реального времени, с задержкой менее одной миллисекунды, что подтверждено измеренным значением в 0.65 миллисекунды. Этот показатель позволяет преобразовать агента, функционирующего как “черный ящик”, в прозрачную и понятную систему. Благодаря столь незначительной задержке, процесс принятия решений агентом становится доступным для анализа практически мгновенно, что открывает возможности для контроля, отладки и повышения доверия к системам, использующим обучение с подкреплением. Такая оперативность объяснений особенно важна в критически важных приложениях, где необходима не только эффективность, но и понимание логики, лежащей в основе действий агента.

Предложенная работа демонстрирует, что элегантность и эффективность системы напрямую зависят от ясности её структуры. Авторы, подобно опытным архитекторам, не просто строят систему управления сетью, но и тщательно продумывают её внутреннюю логику, делая её прозрачной и понятной. Как отмечает Роберт Тарьян: «Структура определяет поведение». В данном случае, использование символьного искусственного интеллекта и графов знаний позволяет не только предвидеть слабые места системы, но и оперативно адаптироваться к изменяющимся условиям, избегая болезненных поломок на границах ответственности. SIA, представленная в работе, является ярким примером того, как глубокое понимание структуры может привести к созданию устойчивых и предсказуемых систем управления.
Куда Дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода — попытку обуздать непредсказуемость обучения с подкреплением через призму символьных представлений. Однако, не стоит обманываться кажущейся простотой. Успех предложенной схемы не гарантирует универсальности. Вполне вероятно, что расширение графов знаний, необходимое для более сложных сетевых топологий, быстро приведёт к экспоненциальному росту вычислительных затрат. Мы оптимизируем не то, что нужно, если интерпретируемость достигается ценой масштабируемости. Хорошая архитектура незаметна, пока не ломается, и, в данном случае, устойчивость к усложнению — ключевой вопрос.
Более того, представленная система всё ещё требует предварительного построения графа знаний. Это, по сути, перекладывание сложности с агента на человека-проектировщика. Истинная автономия агента заключается в способности самостоятельно формировать и адаптировать свои представления о мире. Следующим шагом видится разработка механизмов для динамического построения и обновления графов знаний непосредственно в процессе обучения, возможно, с использованием методов обучения без учителя или самообучения.
Зависимости — настоящая цена свободы. В стремлении к интерпретируемости необходимо помнить, что каждое символьное представление — это абстракция, неизбежно упрощающая реальность. Вопрос в том, насколько эта упрощённость допустима для конкретной задачи и как минимизировать потерю информации. Будущие исследования должны быть направлены на поиск баланса между интерпретируемостью, масштабируемостью и точностью, а не на достижение абсолютной прозрачности любой ценой.
Оригинал статьи: https://arxiv.org/pdf/2601.22044.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-01-30 17:50