Автор: Денис Аветисян
Исследователи предлагают инновационный метод прогнозирования экстремальных колебаний цен на электроэнергию, основанный на возможностях больших языковых моделей.
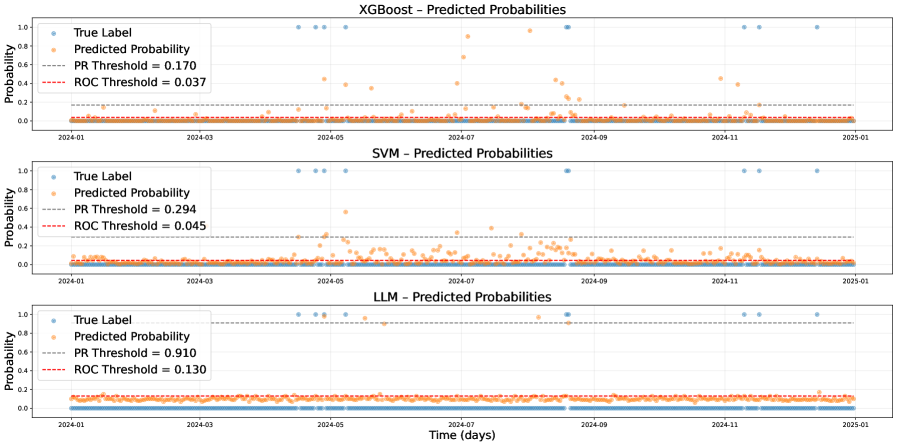
Разработанная система демонстрирует конкурентоспособную точность классификации экстремальных дней в энергетических рынках, особенно при ограниченном объеме исторических данных.
Прогнозирование экстремальных скачков цен на электроэнергию является сложной задачей, особенно в условиях ограниченности исторических данных. В статье ‘A Few-Shot LLM Framework for Extreme Day Classification in Electricity Markets’ предложен инновационный подход, использующий большие языковые модели (LLM) и обучение с небольшим количеством примеров для классификации дней с пиками спроса. Показано, что разработанная система демонстрирует сопоставимую эффективность с традиционными методами машинного обучения, такими как SVM и XGBoost, при этом превосходит их в условиях дефицита данных. Открывает ли это новые перспективы для применения LLM в задачах прогнозирования и управления энергетическими рынками?
Временные аномалии: вызовы точного прогнозирования ценовых скачков
Прогнозирование резких скачков цен на электроэнергию имеет решающее значение для обеспечения стабильности энергосистемы и экономической эффективности, однако остается сложной задачей из-за изменчивой рыночной конъюнктуры и растущей доли возобновляемых источников энергии. Нестабильность, присущая рынку электроэнергии, усугубляется непредсказуемостью производства энергии из возобновляемых источников, таких как солнечная и ветровая энергия, что создает дополнительные трудности для точного прогнозирования. Отсутствие стабильного прогноза приводит к потенциальным рискам для операторов энергосистем, которые должны оперативно реагировать на внезапные изменения цен, а также может привести к экономическим потерям для потребителей и производителей электроэнергии. В связи с этим, разработка надежных и точных методов прогнозирования скачков цен является приоритетной задачей для обеспечения устойчивого и эффективного функционирования энергетического сектора.
Традиционные методы прогнозирования, такие как статистическая регрессия и анализ временных рядов, зачастую оказываются неэффективными при предсказании резких скачков цен на электроэнергию. Это связано с тем, что подобные скачки характеризуются нелинейной динамикой и стремительными изменениями, которые плохо улавливаются линейными моделями. В то время как классические подходы успешно справляются со стабильными тенденциями, они испытывают затруднения при анализе внезапных аномалий и сложных взаимосвязей, возникающих на энергетическом рынке. Неспособность адекватно отразить эти нелинейные зависимости приводит к значительным погрешностям в прогнозах, что, в свою очередь, может негативно сказаться на стабильности энергосистемы и эффективности её функционирования.
Повышение доли возобновляемых источников энергии и, как следствие, изменение так называемой “чистой нагрузки” — разницы между спросом и прогнозируемой выработкой — значительно усложняет прогнозирование скачков цен на электроэнергию. Традиционные методы, основанные на статистическом анализе и временных рядах, зачастую не способны адекватно учесть нелинейные зависимости и быстрые изменения, обусловленные переменчивостью ветровой и солнечной генерации. Для точного предсказания пиковых нагрузок и, соответственно, предотвращения дестабилизации энергосистемы, требуется разработка более сложных прогностических моделей, способных учитывать взаимосвязи между различными факторами, включая метеорологические условия, потребительское поведение и динамику производства энергии из возобновляемых источников. Такие модели, как правило, опираются на методы машинного обучения и искусственного интеллекта, позволяющие выявлять скрытые закономерности и адаптироваться к меняющимся условиям.
Новый подход: классификация ценовых скачков на основе больших языковых моделей
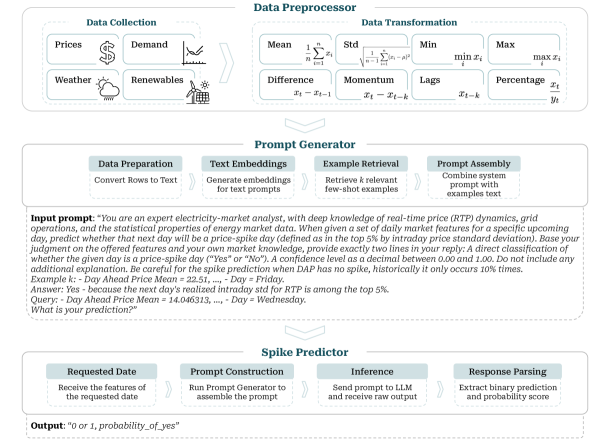
Предлагаемый нами фреймворк классификации скачков цен на электроэнергию, основанный на больших языковых моделях (LLM), представляет собой новый подход к прогнозированию аномальных изменений цен. В отличие от традиционных методов, использующих статистические модели или машинное обучение на структурированных данных, данный фреймворк использует способность LLM выявлять сложные зависимости и паттерны в данных, что позволяет учитывать нелинейные взаимосвязи и контекстуальную информацию. LLM способны обрабатывать большие объемы данных и извлекать из них значимые признаки, которые могут быть упущены при использовании стандартных алгоритмов анализа временных рядов. Это обеспечивает более точное и своевременное прогнозирование скачков цен, что критически важно для эффективного управления энергетическими ресурсами и снижения рисков для потребителей и поставщиков электроэнергии.
Предлагаемая структура классификации скачков цен на электроэнергию состоит из трех ключевых компонентов. Модуль предварительной обработки данных (Data Preprocessor) извлекает релевантные признаки из данных ERCOT System-Wide Data, включая объемы генерации, потребления, метеорологические данные и данные о передаче энергии. Затем модуль генерации запросов (Prompt Generator) преобразует эти числовые признаки в текстовый формат, понятный большой языковой модели (LLM). Наконец, модуль предсказания скачков (Spike Predictor) интерпретирует выходные данные LLM, определяя вероятность возникновения скачков цен и предоставляя соответствующие прогнозы.
Предлагаемый подход к прогнозированию скачков цен на электроэнергию формулирует задачу как задачу языкового моделирования. Это позволяет использовать встроенные возможности больших языковых моделей (LLM) для анализа динамики энергосистемы. Вместо традиционных методов, основанных на числовом анализе временных рядов, LLM обрабатывают данные о ценах и других релевантных факторах как последовательность текстовых токенов. Такой подход позволяет модели выявлять сложные взаимосвязи и закономерности, которые могут указывать на приближающийся скачок цен. Использование LLM позволяет не только прогнозировать вероятность возникновения скачка, но и предоставляет возможность интерпретировать факторы, которые к нему приводят, обеспечивая более точные и своевременные прогнозы.
Уточнение предсказаний: инженерия запросов для повышения точности
Эффективное проектирование запросов (prompt engineering) является ключевым фактором для раскрытия предсказательной силы больших языковых моделей (LLM). Для создания информативных и разнообразных запросов используются такие методы, как модели эмбеддингов и максимальная предельная релевантность (Maximal Marginal Relevance, MMR). Модели эмбеддингов позволяют представить текстовые данные в виде векторов, что облегчает поиск семантически близких примеров. MMR, в свою очередь, обеспечивает отбор наиболее релевантных и одновременно разнообразных примеров, избегая избыточности в запросе и повышая способность LLM к обобщению и точному прогнозированию.
Для эффективного формирования промптов, используемых для повышения точности предсказаний больших языковых моделей (LLM), применяется библиотека FAISS (Facebook AI Similarity Search). FAISS обеспечивает быстрый и масштабируемый поиск наиболее релевантных примеров из большого корпуса данных. Алгоритмы FAISS позволяют находить векторы, наиболее близкие к векторному представлению текущего запроса, что позволяет отобрать примеры, наиболее подходящие для включения в промпт. Использование FAISS значительно снижает вычислительные затраты и время, необходимые для поиска релевантных данных, по сравнению с полным перебором, обеспечивая LLM доступ к наиболее значимой информации для точного прогнозирования.
Метод обучения с небольшим количеством примеров (few-shot learning) позволяет языковой модели (LLM) обобщать информацию и прогнозировать скачки в разнообразных рыночных условиях, используя ограниченный набор демонстрационных данных. Вместо обучения на больших объемах данных, LLM анализирует несколько представленных примеров, выявляет закономерности и применяет их к новым, ранее не встречавшимся ситуациям. Это особенно ценно в динамичных рыночных средах, где исторические данные могут быть нерелевантными, а возможность быстро адаптироваться к новым условиям критически важна для точного прогнозирования пиковых значений и колебаний.
Проверка надежности: оценка производительности с помощью строгих метрик
Для оценки производительности разработанного фреймворка использовался комплексный набор метрик, включающий в себя точность (Accuracy), прецизионность (Precision), полноту (Recall), F1-меру и кривые рабочих характеристик приемника (Receiver Operating Characteristic curves — ROC). Точность отражает общую долю правильно классифицированных объектов, в то время как прецизионность и полнота позволяют оценить качество классификации для каждого класса в отдельности. F1-мера является гармоническим средним между прецизионностью и полнотой, обеспечивая сбалансированную оценку. ROC-кривые визуализируют зависимость между долей правильно обнаруженных положительных примеров и долей ложноположительных срабатываний, позволяя оценить способность модели к различению классов при различных порогах классификации.
При обучении на полном наборе данных, разработанная система демонстрирует сопоставимые показатели точности (Accuracy), прецизионности (Precision), полноты (Recall) и F1-меры с традиционными алгоритмами машинного обучения, такими как Support Vector Machines (SVM), Weighted K-Nearest Neighbor (KNN) и XGBoost. Полученные результаты свидетельствуют о конкурентоспособности предложенного подхода при наличии достаточного объема обучающих данных и позволяют рассматривать его в качестве альтернативы существующим методам классификации и прогнозирования. Статистический анализ не выявил значимых различий между предложенным фреймворком и указанными моделями, что подтверждается соответствующими метриками.
В условиях ограниченного объема данных, разработанная языковая модель (LLM) демонстрирует существенное превосходство над традиционными алгоритмами машинного обучения, такими как Support Vector Machines (SVM) и XGBoost. В ходе экспериментов было установлено, что LLM обеспечивает более высокую точность и стабильность результатов при обучении на небольших выборках, что свидетельствует о её устойчивости в сценариях с дефицитом данных. Это преимущество особенно важно для задач, где сбор и аннотация большого количества данных затруднены или невозможны, позволяя эффективно использовать доступные ресурсы и достигать приемлемого уровня производительности.
Перспективы и влияние: оптимизация энергосистемы и дальнейшие исследования
Точное прогнозирование резких скачков цен на электроэнергию открывает возможности для проактивного управления энергосистемой, существенно снижая риск возникновения аварийных отключений и повышая общую надежность функционирования сети. Анализ данных позволяет заблаговременно выявлять периоды повышенного спроса или потенциальные сбои в поставках, что дает возможность операторам энергосистемы своевременно перераспределять ресурсы, активировать резервные мощности или предлагать потребителям альтернативные источники энергии. Таким образом, предсказывая пиковые нагрузки, можно не только избежать перегрузок и каскадных отказов, но и оптимизировать использование генерирующих мощностей, снижая издержки и повышая эффективность всей энергосистемы, обеспечивая стабильное электроснабжение для потребителей.
Разработанная система способна к интеграции в системы принятия решений в режиме реального времени, что открывает возможности для оптимизации распределения ресурсов в энергетической сети. Это позволяет операторам сети оперативно реагировать на изменяющиеся условия, прогнозировать потенциальные перегрузки и эффективно управлять доступными мощностями. За счет точного прогнозирования пиковых нагрузок и динамического перераспределения ресурсов, возможно не только снижение эксплуатационных издержек, но и повышение общей надежности и устойчивости энергосистемы. Внедрение подобного подхода способствует более эффективному использованию возобновляемых источников энергии и снижению зависимости от традиционных электростанций, что в конечном итоге приводит к экономии средств и улучшению экологической обстановки.
Дальнейшие исследования направлены на расширение возможностей разработанной системы за счет интеграции дополнительных источников данных, включая информацию о погодных условиях, прогнозах нагрузки и состоянии оборудования. Особое внимание уделяется изучению передовых методов промпт-инжиниринга, позволяющих оптимизировать взаимодействие с языковыми моделями и повысить точность прогнозирования. Кроме того, ведется разработка методов количественной оценки неопределенности прогнозов с использованием конформного предсказания, что позволит оценить надежность получаемых результатов и принимать более обоснованные решения в управлении энергосистемой. Это позволит не только повысить эффективность работы сети, но и обеспечить ее устойчивость к различным внешним факторам и неожиданным ситуациям.
Представленное исследование демонстрирует, что даже при ограниченном объеме данных, современные большие языковые модели способны эффективно прогнозировать экстремальные скачки цен на электроэнергию. Этот подход, основанный на обучении с небольшим количеством примеров, открывает новые возможности для виртуальных электростанций и управления возобновляемыми источниками энергии. Винтон Серф однажды заметил: «Интернет — это не просто технология, это способ организации информации». Подобно тому, как интернет структурирует данные, представленная модель структурирует временные ряды цен, выявляя закономерности, которые позволяют предвидеть критические моменты. Такой подход подчеркивает, что системы, как и сети, развиваются и адаптируются, и их долговечность зависит не только от эффективности алгоритмов, но и от способности извлекать уроки из ограниченной информации.
Куда Ведет Время?
Представленный подход, использующий большие языковые модели для прогнозирования ценовых скачков на рынке электроэнергии, безусловно, демонстрирует свою жизнеспособность, особенно в условиях дефицита данных. Однако, подобно любому улучшению, и эта архитектура подвержена старению. Совершенство модели — лишь временная иллюзия, а откат к менее точным прогнозам — неизбежное путешествие назад по стрелке времени. Ключевой вопрос заключается не в достижении абсолютной точности, а в понимании скорости ее эрозии.
Перспективы дальнейших исследований лежат не столько в усложнении модели, сколько в адаптации к динамике самих данных. Устойчивость к «шуму» и способность к самообучению на неполных или противоречивых данных — вот где кроется истинный потенциал. Важно понимать, что рынок электроэнергии — это не статичная система, а постоянно эволюционирующая среда, где любые прогнозы обречены на частичную несостоятельность.
Интеграция с виртуальными электростанциями и прогнозированием выработки энергии из возобновляемых источников — перспективное направление, но и оно не избавит от фундаментальной проблемы: любое, даже самое совершенное, предсказание — лишь временная задержка перед лицом неопределенности. Истинное мастерство заключается не в победе над временем, а в умении достойно стареть вместе с ним.
Оригинал статьи: https://arxiv.org/pdf/2602.16735.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-21 21:52