Автор: Денис Аветисян
Новая система использует возможности искусственного интеллекта для создания и решения вопросов, связанных с прогнозированием, открывая новые возможности для оценки и улучшения моделей ИИ.
Автоматическая генерация вопросов для прогнозирования и оценка их разрешимости с использованием LLM-агентов, направленная на преодоление проблемы нехватки данных в исследованиях ИИ.
Прогнозирование будущих событий является ключевым аспектом принятия решений, однако создание разнообразных и сложных вопросов для оценки ИИ-систем прогнозирования сопряжено с существенными трудностями. В работе ‘Automating Forecasting Question Generation and Resolution for AI Evaluation’ представлена система автоматической генерации и верификации вопросов для прогнозирования, использующая LLM-агентов и веб-исследования, позволяющая преодолеть проблему дефицита данных. Разработанная система генерирует около 1500 разнообразных вопросов с высокой степенью проверяемости (96%) и точностью разрешения (95%), превосходя показатели ведущих платформ, управляемых экспертами. Может ли автоматизированное создание подобных бенчмарков стать катализатором для развития более точных и надежных ИИ-систем прогнозирования?
Прогностическая Ясность: Оценка Разрешимости Вопросов
Точность прогнозирования напрямую зависит от возможности объективной проверки полученных ответов, однако значительная часть вопросов, требующих прогноза, лишена чётких, автоматизированных путей для верификации. Отсутствие таких путей создает серьезные трудности при оценке эффективности моделей искусственного интеллекта, поскольку субъективная оценка может быть предвзятой и ненадежной. Разработка алгоритмов и метрик, позволяющих автоматически определять правильность ответа, становится ключевой задачей для прогресса в области прогностического моделирования и обеспечения достоверности получаемых результатов. Без надежной системы верификации, потенциал ИИ в прогнозировании остается ограниченным, а ценность полученных прогнозов — под вопросом.
Определение степени “разрешимости” задач искусственным интеллектом является ключевым этапом в развитии систем прогнозирования. Важно установить, способна ли автономная система самостоятельно найти ответ на поставленный вопрос, не требуя вмешательства человека или доступа к заранее подготовленным данным. Этот показатель, отражающий способность агента к самостоятельному решению задач, служит основой для оценки его возможностей и определения областей, где ИИ может быть наиболее эффективен. Чем выше степень разрешимости, тем более надежным и точным будет прогноз, поскольку система способна самостоятельно верифицировать полученные результаты и адаптироваться к изменяющимся условиям. По сути, разрешимость определяет границы возможностей ИИ и служит мерилом его интеллектуального потенциала.
Оценка возможности решения задач искусственным интеллектом начинается с простого, но фундаментального принципа: если задача представляет трудность для человека, то и для ИИ она, вероятнее всего, окажется неразрешимой. Этот подход, использующий человеческую разрешимость в качестве начального критерия, позволяет эффективно отсеивать нереалистичные запросы и фокусироваться на тех задачах, где применение искусственного интеллекта действительно может принести пользу. Прежде чем приступать к разработке сложных алгоритмов, необходимо удостовериться, что задача имеет четкое и понятное решение, доступное для человеческого понимания, что значительно упрощает процесс обучения и оценки эффективности ИИ-систем. Такой подход не только экономит ресурсы, но и гарантирует, что усилия направлены на решение действительно достижимых и значимых проблем.

Систематическая Оценка Вопросов: Контрольный Список Разрешимости
Прогнозирование оценки вопросов использует контрольный список для определения возможности автоматического разрешения. Этот список представляет собой структурированный набор критериев, позволяющих оценить, может ли вопрос быть решен без участия человека. Основная цель — быстро идентифицировать вопросы, для которых существует четкий и доступный источник информации, необходимый для автоматической верификации ответа. Применение контрольного списка позволяет стандартизировать процесс оценки и повысить эффективность автоматизации поддержки, сокращая время ответа и нагрузку на специалистов.
Оценка вопроса в рамках прогнозирования автоматического решения начинается с проверки наличия четко определенного Источника Разрешения (Resolution Source). Этот источник представляет собой базу знаний или систему, содержащую проверенную информацию, используемую для подтверждения правильности ответа. Отсутствие однозначно идентифицируемого источника, содержащего точные и актуальные данные, автоматически исключает возможность автоматического разрешения вопроса, поскольку невозможно будет подтвердить или опровергнуть предложенное решение. Идентификация источника включает определение его типа (например, база данных, документация, API), местоположения и формата данных, которые он содержит.
Оценка доступности источника разрешения является критически важным этапом при прогнозировании оценки вопроса. Данный этап включает в себя проверку возможности получения данных из указанного источника — будь то база данных, API, файл или другой тип хранилища информации. Невозможность извлечения данных из источника, либо значительные задержки при этом, автоматически исключает возможность автоматического разрешения вопроса, поскольку верификация ответа становится невозможной. Проверка доступности включает в себя оценку сетевого подключения, прав доступа, формата данных и соответствия запросам системы обработки.
Целостность и Доступность Данных: Столпы Разрешимости
Доступность исходных данных напрямую связана с их наличием; заблокированный или пустой источник делает разрешение проблемы невозможным. Отсутствие доступа к данным, например, из-за ограничений прав, технических сбоев или физической недоступности носителей информации, приводит к невозможности проведения анализа и, следовательно, к невозможности достижения разрешения. Даже если данные теоретически существуют, их недоступность эквивалентна их отсутствию с точки зрения процесса разрешения. Недоступность может быть как временной, так и постоянной, что существенно влияет на сроки и возможность завершения работы над задачей.
Недостаточно просто иметь доступ к данным; стабильность методологии сбора данных во времени является равноценно важным фактором. Непостоянство в процедурах сбора, изменения в используемых инструментах или протоколах, а также неполнота данных, собранных в разные периоды, приводят к несопоставимости результатов и искажению общей картины. Это, в свою очередь, делает невозможным достоверный анализ и принятие обоснованных решений, даже если сами данные доступны. Стабильная методология обеспечивает сопоставимость данных, позволяя выявлять тенденции, проводить корректные сравнения и формировать надежную основу для разрешения возникающих вопросов.
Несмотря на доступность данных, отсутствие стабильной методологии сбора информации может существенно снизить её достоверность и, как следствие, подорвать весь процесс разрешения проблемы. Изменения в процедурах сбора, используемом оборудовании или критериях оценки приводят к несопоставимости данных, полученных в разные периоды времени. Это затрудняет выявление реальных тенденций, а также делает невозможным проведение корректного анализа и принятие обоснованных решений. Таким образом, поддержание последовательности методологии является критически важным условием для обеспечения надежности и полезности доступных данных.
Влияние на Автоматизированное Прогнозирование и Перспективы Развития
Разработанная система оценки позволяет выявлять вопросы, наиболее подходящие для автоматического разрешения, тем самым раскрывая потенциал искусственного интеллекта в прогнозировании. Ключевым аспектом является способность фреймворка к структурированному анализу вопросов, что обеспечивает возможность их эффективной обработки алгоритмами машинного обучения. Это, в свою очередь, позволяет автоматизировать процесс прогнозирования, снижая зависимость от ручного анализа и субъективных оценок. Благодаря этой системе, вопросы, обладающие четкими критериями разрешения и доступными источниками информации, могут быть решены искусственным интеллектом с высокой степенью точности, открывая новые горизонты для автоматизированного прогнозирования в различных областях знаний.
Исследование показало, что акцент на вопросах, имеющих надежные и четко определенные источники разрешения, существенно повышает точность и достоверность прогнозов, генерируемых искусственным интеллектом. Приоритезация вопросов, для которых существует ясная и однозначная информация, позволяющая подтвердить или опровергнуть ответ, минимизирует возможность ошибок и увеличивает уверенность в результатах. Такой подход обеспечивает более стабильные и надежные предсказания, поскольку ИИ опирается на проверенные данные, а не на неоднозначные или субъективные оценки. В результате, система демонстрирует высокую эффективность в автоматическом прогнозировании, подтвержденную результатами, сравнимыми с показателями, достигнутыми экспертами-людьми.
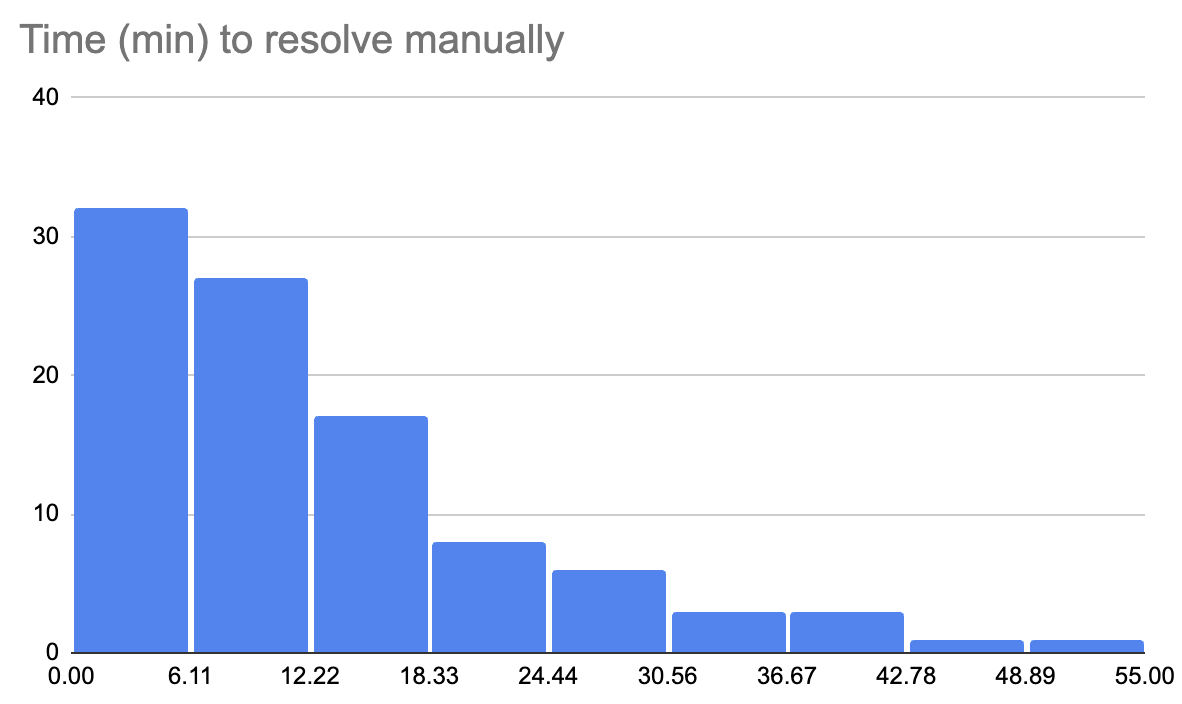
Разработанная система продемонстрировала уровень отмены прогнозов в 3,9%, что сопоставимо с историческим показателем платформы Metaculus, составляющим около 8%. Этот результат свидетельствует о вполне достижимой возможности автоматической генерации вопросов для прогнозирования. Низкий процент отмен указывает на то, что вопросы, сформулированные системой, как правило, разрешаются успешно и не требуют отмены из-за неясности или отсутствия данных, что подтверждает жизнеспособность подхода и открывает перспективы для масштабного применения искусственного интеллекта в сфере прогнозирования и анализа будущих событий.
Исследования показали, что система автоматического разрешения вопросов демонстрирует высокую точность — 96% правильных ответов из ста проверенных экспертами. Лишь в четырех случаях из ста зафиксированы ошибки, что подтверждает надежность и стабильность работы системы. Такая высокая степень соответствия между автоматическими прогнозами и экспертной оценкой указывает на потенциал использования искусственного интеллекта для решения задач прогнозирования и анализа, требующих высокой точности и объективности. Этот результат свидетельствует о возможности автоматизации процесса прогнозирования без значительной потери качества, открывая перспективы для более эффективного использования ресурсов и ускорения принятия решений.
Анализ результатов показал абсолютное единогласие в определении источников разрешения вопросов, что свидетельствует о высокой степени ясности и однозначности исходных материалов для автоматической обработки. Данное обстоятельство критически важно для обеспечения надежности и точности прогнозов, формируемых искусственным интеллектом. Отсутствие расхождений в интерпретации источников разрешения позволяет исключить субъективные ошибки и гарантирует, что система последовательно и корректно оценивает доступную информацию, создавая прочную основу для автоматизированного прогнозирования и анализа.
Исследование демонстрирует, что автоматизация генерации вопросов для прогнозирования — это не просто техническая задача, но и создание сложной экосистемы, где каждый вопрос — потенциальная точка отказа или, наоборот, возможности для эволюции системы. Как однажды заметила Барбара Лисков: «Хороший дизайн — это проектирование системы так, чтобы изменения в одной части не приводили к каскадным сбоям в других». В данной работе акцент сделан на повышение надежности и адаптивности системы прогнозирования, особенно в условиях дефицита данных. Автоматически генерируемые вопросы, оцениваемые на предмет разрешимости, позволяют выявить слабые места и предвидеть потенциальные сбои, что соответствует философии создания систем, способных к самовосстановлению и эволюции.
Куда же дальше?
Представленная работа, стремясь автоматизировать рождение вопросов для прогнозирования, лишь обнажает более глубокую проблему. Система, генерирующая вопросы, — это, по сути, эхо прошлого, запечатлённое в алгоритмах. Она обещает возможность оценки, но оценка эта всегда ретроспективна, всегда ограничена горизонтом известного. Каждая зависимость от LLM-агентов — это не просто технический выбор, а обещание, данное прошлому, обещание, которое, возможно, не будет выполнено в будущем, когда ландшафт данных преобразится.
Иллюзия контроля над процессом генерации вопросов — это, конечно, удобно. Но системы, как известно, живут циклами. Всё, что построено, когда-нибудь начнёт само себя чинить, адаптироваться, мутировать. Реальная задача не в создании эталонного набора вопросов, а в разработке механизмов, способных к самовосстановлению и адаптации к непрерывно меняющемуся потоку информации. Данные, как вода, текут; попытки их удержать приводят лишь к застою.
В конечном счёте, предложенный подход — это лишь один из инструментов в арсенале исследователя. Важнее осознать, что создание «робастного бенчмарка» — это миф. Истинная мера прогресса — это не точность прогнозов, а способность системы к самообучению и адаптации к неожиданностям. Системы не строят, их выращивают, и каждое архитектурное решение — это пророчество о будущем сбое.
Оригинал статьи: https://arxiv.org/pdf/2601.22444.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-02 09:56