Автор: Денис Аветисян
Новое исследование показывает, что современные системы искусственного интеллекта достигают плато в производительности на стандартных тестах быстрее, чем ожидалось.
Систематический анализ показывает, что возраст бенчмарков и размер тестовых наборов являются ключевыми факторами насыщения, а предлагаемые меры защиты, такие как закрытые тестовые данные, оказываются недостаточно эффективными.
Несмотря на ключевую роль в оценке прогресса моделей искусственного интеллекта, многие бенчмарки быстро достигают насыщения, теряя способность различать лучшие системы. В работе ‘When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation’ представлен систематический анализ насыщения бенчмарков для больших языковых моделей, охватывающий 60 технических отчетов от ведущих разработчиков. Исследование выявило, что возраст бенчмарка и размер тестового набора являются основными факторами, определяющими скорость насыщения, в то время как часто предлагаемые меры защиты, такие как использование закрытых тестовых данных, оказываются малоэффективными. Какие стратегии необходимо разработать для обеспечения долгосрочной релевантности и надежности систем оценки в быстро развивающейся области искусственного интеллекта?
Пределы современной оценки больших языковых моделей
Стремительное развитие больших языковых моделей (БЯМ) создает серьезные трудности в области их надежной оценки. Если ранее проверка возможностей искусственного интеллекта сводилась к относительно простым задачам, то сейчас, когда БЯМ демонстрируют способность генерировать сложные тексты, переводить языки и даже писать код, традиционные методы оценки становятся недостаточными. Возникает парадокс: чем мощнее становится модель, тем сложнее объективно измерить её истинный потенциал и отличить реальные достижения от поверхностной имитации интеллекта. Появляются новые вызовы, связанные с необходимостью разработки более тонких и комплексных метрик, способных уловить нюансы понимания и генерации, а также обеспечить сопоставимость результатов между различными моделями и задачами. Эта проблема становится особенно актуальной в связи с растущей зависимостью от БЯМ в различных сферах, от автоматизации рутинных задач до принятия важных решений.
Результаты, демонстрируемые языковыми моделями в рейтингах, часто оказываются обманчивыми из-за проблемы «загрязнения данных». Суть явления заключается в том, что часть обучающих данных моделей могла невольно попасть в наборы данных, используемые для оценки. Это приводит к искусственно завышенным показателям, поскольку модель уже «видела» ответы на некоторые вопросы во время обучения, а не генерирует их самостоятельно. Таким образом, публикуемые результаты производительности не отражают истинных возможностей модели по обобщению знаний и решению новых задач, ставя под сомнение надежность подобных рейтингов как объективного критерия оценки.
Существующие метрики оценки больших языковых моделей, несмотря на свою полезность, часто оказываются неспособными зафиксировать тонкие нюансы способностей этих систем. Они, как правило, ориентированы на измерение поверхностных характеристик, таких как точность ответа или соответствие заданному формату, упуская из виду способность к рассуждению, творческому подходу или пониманию контекста. Более того, эти метрики подвержены манипуляциям — модели могут быть специально обучены для достижения высоких результатов по конкретным показателям, не демонстрируя при этом реального прогресса в области искусственного интеллекта. Такое “игровое” поведение, когда модель оптимизируется под метрику, а не под решение задачи, ставит под сомнение достоверность оценок и необходимость разработки более сложных и всесторонних методов анализа.
Насыщение эталонных данных: растущая проблема
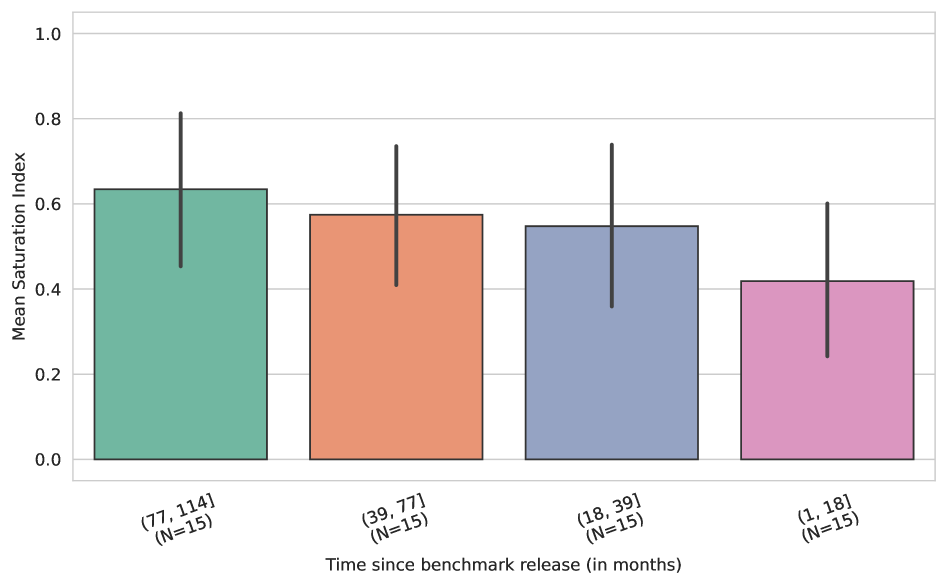
По мере совершенствования моделей машинного обучения, существующие бенчмарки все чаще демонстрируют насыщение, то есть потерю способности различать между лучшими моделями. Это связано с тем, что производительность большинства моделей стремится к максимальным значениям на фиксированном наборе тестовых данных, что приводит к уменьшению разницы в результатах и снижению статистической значимости различий между ними. Следовательно, оценка реального прогресса в развитии моделей становится затруднительной, поскольку бенчмарки перестают обеспечивать достаточную статистическую сепарабельность — способность надежно отличать один подход от другого. Данное явление ограничивает возможности объективной оценки и сравнения различных моделей машинного обучения.
Анализ показал, что потеря различительной способности эталонных наборов данных (бенчмарков) происходит из-за нескольких факторов. Возраст бенчмарка, масштаб тестового набора и степень его «прохождения» (exposure) моделями — все это вносит вклад в снижение способности бенчмарка различать лучшие модели. Согласно нашим данным, 29 из 60 исследованных бенчмарков демонстрируют высокий или очень высокий уровень насыщения, что подтверждается значением Индекса Насыщения (Saturation Index) равным или превышающим 0.7.
Насыщение контрольных тестов, приводящее к снижению их дискриминационной способности, не ограничивается каким-либо конкретным типом задач. Анализ показывает, что как задачи с открытым ответом (Open-Ended Tasks), требующие генерации текста или решения проблем без заранее заданных вариантов, так и задачи с закрытым ответом (Closed-Ended Tasks), предполагающие выбор из предложенных вариантов, демонстрируют признаки насыщения. Это означает, что передовые модели машинного обучения все чаще достигают сопоставимых результатов на обоих типах задач, что затрудняет объективное сравнение их производительности и оценку реального прогресса в области искусственного интеллекта.
Количественная оценка надежности эталонных данных: Индекс насыщения
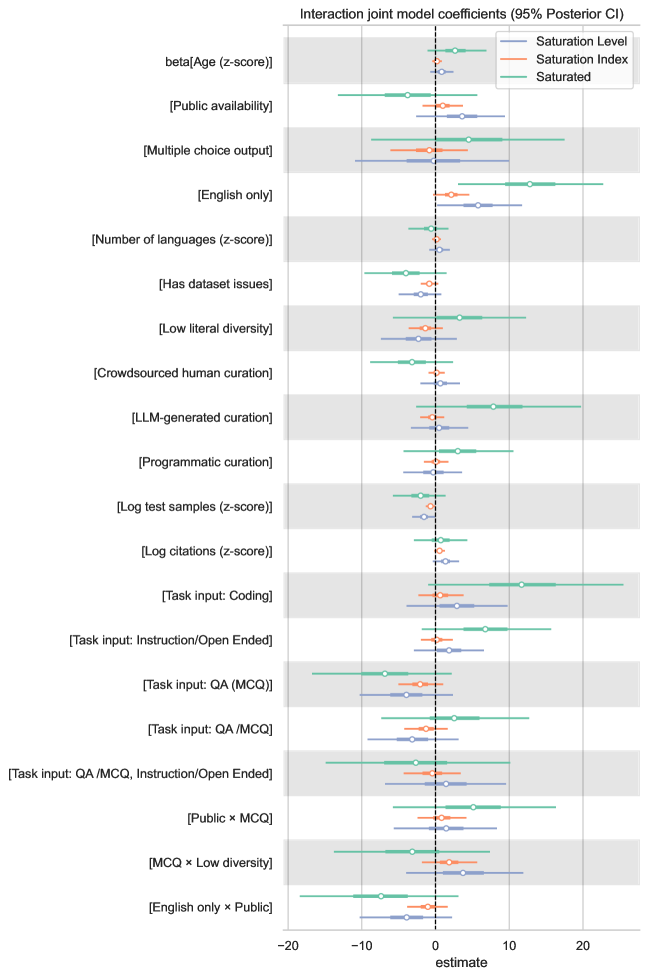
Индекс Насыщенности (Saturation Index) представляет собой методологию для непрерывной количественной оценки степени «насыщенности» бенчмарков, то есть, степени, в которой результаты бенчмарка перестают отражать реальный прогресс в развитии моделей. Оценка осуществляется на основе анализа данных таблиц лидеров (leaderboard data), включающих информацию о результатах различных моделей, а также характеристик самого бенчмарка, таких как размер набора данных, сложность задач и разнообразие примеров. Методика позволяет отслеживать изменения в результатах бенчмарков во времени и выявлять те, в которых доминирующие модели демонстрируют близкие показатели, указывающие на достижение плато и снижение информативности бенчмарка для дальнейшей оценки новых моделей.
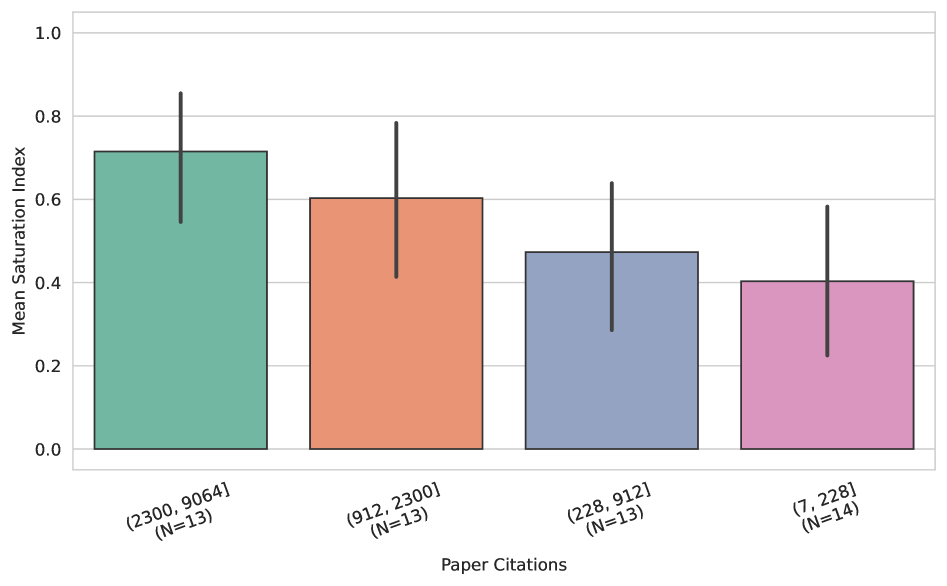
Индекс насыщения предоставляет стандартизированный метод для сопоставления состояния различных бенчмарков, что позволяет обоснованно выбирать и расставлять приоритеты при их использовании. Вместо субъективной оценки, индекс позволяет количественно оценить степень “выхоженности” бенчмарка, то есть насколько сильно его результаты подвержены влиянию оптимизаций, специфичных для данного набора данных. Это особенно важно при сравнении различных бенчмарков, поскольку позволяет учитывать, насколько достоверно они отражают реальные улучшения в производительности моделей. Использование индекса позволяет исследователям и разработчикам концентрировать усилия на бенчмарках, которые по-прежнему предоставляют значимые сигналы об эффективности новых подходов, и избегать траты ресурсов на те, которые уже не позволяют выявить реальные улучшения.
Отслеживание Индекса Насыщения позволяет исследователям выявлять бенчмарки, утратившие способность предоставлять значимую информацию. Разработанная модель демонстрирует высокую точность в различении насыщенных и ненасыщенных бенчмарков, достигая показателя AUROC в 0.98. Это указывает на эффективность метода в определении бенчмарков, результаты которых больше не отражают реальный прогресс или различия между моделями, что позволяет сосредоточить ресурсы на более информативных задачах и метриках.
Характеристики эталонных данных и их долгосрочная ценность
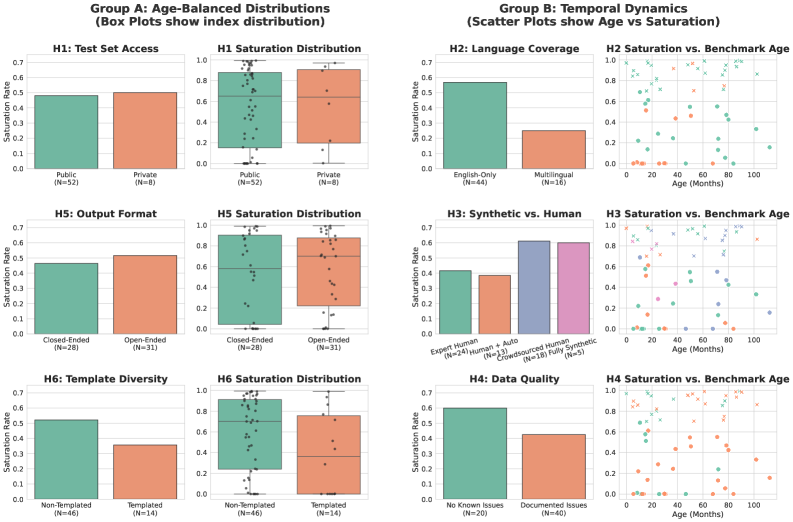
Исследования показывают, что подверженность насыщению — явлению, когда модели искусственного интеллекта достигают пределов производительности на определенном наборе данных — значительно различается в зависимости от типа используемого эталона. Эталоны, созданные человеком, как правило, быстрее достигают насыщения, поскольку они отражают конкретные лингвистические особенности и знания, которые модели относительно легко освоить. В то время как синтетические эталоны, генерируемые алгоритмически, обладают большей вариативностью и сложностью, что замедляет процесс насыщения. Это связано с тем, что синтетические данные могут включать в себя более широкий спектр лингвистических конструкций и менее предсказуемые паттерны, требующие от моделей более глубокого понимания языка и способности к обобщению. Таким образом, выбор между эталонами, созданными человеком, и синтетическими, играет ключевую роль в оценке истинных возможностей моделей и обеспечении долгосрочной релевантности метрик производительности.
Исследования показывают, что масштаб бенчмарка, а именно сравнение англоязычных и многоязычных наборов данных, оказывает существенное влияние на его долгосрочную полезность. Бенчмарки, ограниченные только английским языком, демонстрируют тенденцию к более быстрому насыщению и снижению дискриминационной способности по мере развития моделей машинного обучения. Это связано с тем, что модели быстро достигают высокого уровня производительности на относительно ограниченном наборе данных. В отличие от них, многоязычные бенчмарки, охватывающие широкий спектр языков и лингвистических особенностей, обеспечивают более устойчивый вызов для моделей и позволяют более точно оценивать их способность к обобщению и адаптации к новым языковым контекстам. Таким образом, для поддержания релевантности оценки, необходимо постоянное обновление и разработка новых эталонных наборов, учитывающих текущий уровень развития моделей и обладающих достаточной сложностью для выявления прогресса.
Анализ показал, что возраст эталонного набора данных является ключевым фактором, определяющим степень его насыщения — более старые наборы демонстрируют значительно более высокие показатели насыщения. Это указывает на то, что насыщение происходит не из-за отдельных особенностей проектирования, а вследствие динамики структурного раскрытия и ограничений, связанных с разрешающей способностью используемых метрик. Иными словами, по мере развития моделей машинного обучения, они постепенно «выучивают» особенности старых эталонов, что приводит к снижению их способности различать реальные улучшения в производительности. Таким образом, для поддержания релевантности оценки, необходимо постоянное обновление и разработка новых эталонных наборов, учитывающих текущий уровень развития моделей и обладающих достаточной сложностью для выявления прогресса.
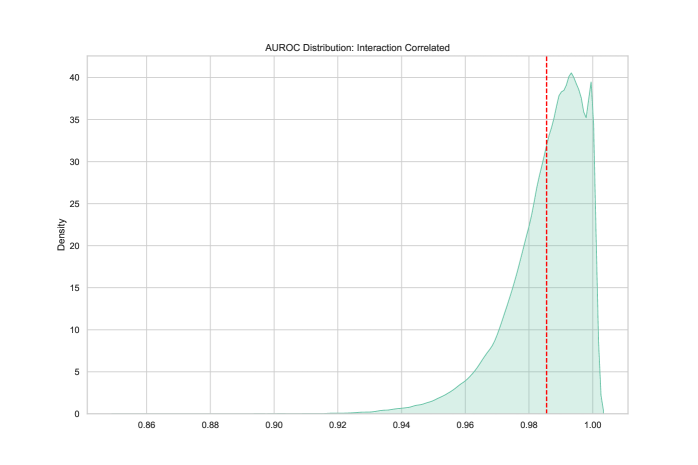
Исследование демонстрирует, что оценка больших языковых моделей сталкивается с проблемой насыщения, когда существующие бенчмарки перестают адекватно отражать прогресс. Этот процесс подчеркивает важность понимания того, как возраст набора данных и его размер влияют на результаты. Подобно тому, как в сложном организме изменение одной части влияет на всю систему, устаревание бенчмарков искажает картину реального развития моделей. Карл Фридрих Гаусс однажды заметил: «Я не знаю, как я выгляжу в глазах других, но я кажусь себе человеком, который размышляет над проблемами». Данное исследование, подобно глубокому размышлению Гаусса, подчеркивает необходимость непрерывного мониторинга и обновления бенчмарков для обеспечения достоверной оценки возможностей ИИ.
Куда двигаться дальше?
Наблюдаемое насыщение эталонов оценки больших языковых моделей обнажает простую истину: любая система, даже столь амбициозная, подвержена энтропии. Попытки задержать неизбежное, такие как создание приватных тестовых наборов, оказываются лишь временной отсрочкой, а не решением. Каждая новая зависимость от конкретного эталона — это скрытая цена свободы от необходимости постоянного переосмысления метрик и методов оценки.
Более глубокое понимание динамики насыщения требует смещения фокуса с отдельных эталонов на целостную экосистему оценки. Необходимо рассматривать возраст эталона и размер тестового набора не как изолированные факторы, а как симптомы более фундаментальной проблемы: неспособности существующих метрик адекватно отражать реальные возможности моделей. Очевидно, что структура определяет поведение, и в данном случае, структура оценки определяет границы развития моделей.
Будущие исследования должны быть направлены на разработку адаптивных систем оценки, способных к самокоррекции и непрерывному обучению. Вместо поиска идеального эталона, следует сосредоточиться на создании механизмов, позволяющих быстро выявлять и устранять устаревшие или предвзятые метрики. Иначе, рискуем создать иллюзию прогресса, замаскировав стагнацию за красивыми цифрами.
Оригинал статьи: https://arxiv.org/pdf/2602.16763.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-21 13:24