Автор: Денис Аветисян
Исследователи разработали метод, позволяющий извлекать осмысленные темы из небольших текстовых фрагментов, используя возможности генеративных моделей и поиска релевантной информации.

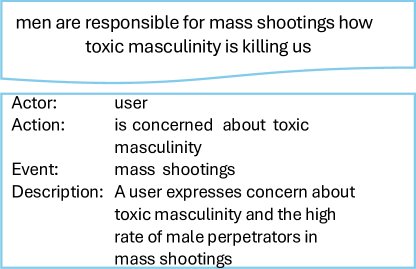
Представлена система NTLRAG, использующая генерацию с дополнением извлечением (Retrieval-Augmented Generation) для создания интерпретируемых повествовательных меток тем из коротких текстов.
Несмотря на прогресс в тематическом моделировании, автоматическое присвоение осмысленных меток темам, выделенным из больших текстовых корпусов, остается сложной задачей. В данной работе представлена система NTLRAG (Narrative Topic Labels derived with Retrieval Augmented Generation), масштабируемый фреймворк, генерирующий семантически точные и понятные человеку нарративные метки тем. Используя методы генерации с расширением извлечением (RAG) и цепочку рассуждений, NTLRAG позволяет создавать нарративные метки, превосходящие по интерпретируемости традиционные списки ключевых слов. Каким образом подобные нарративные метки могут улучшить анализ социальных медиа и другие области работы с неструктурированным текстом?
Трудности осмысления коротких текстов
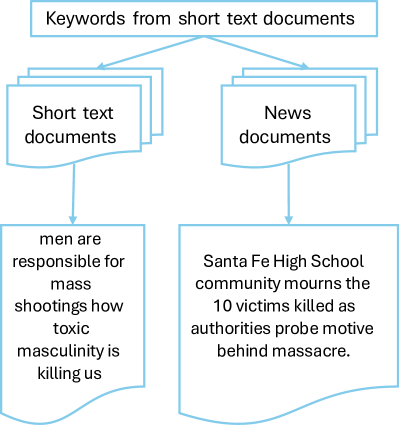
Традиционные методы тематического моделирования сталкиваются с серьезными трудностями при анализе коротких текстов, таких как твиты или SMS-сообщения. В отличие от длинных документов, где контекст и повторяющиеся ключевые слова помогают выделить четкие темы, краткость изложения часто приводит к появлению обобщенных и бессвязных тематических меток. Алгоритмы, разработанные для обработки более объемных данных, не способны уловить тонкие смысловые нюансы, характерные для коротких текстов, что приводит к неточным и малоинформативным результатам. Например, фразы, содержащие многозначные слова или сленг, могут быть неправильно интерпретированы, а отсутствие достаточного контекста препятствует адекватному определению основной темы сообщения. В результате, вместо конкретных и осмысленных категорий, системы выдают общие ярлыки, не отражающие истинное содержание анализируемых данных.
Несмотря на свою основополагающую роль в тематическом моделировании, такие методы, как Latent Dirichlet Allocation и Non-Negative Matrix Factorization, зачастую оказываются недостаточно чувствительными к контексту в коротких текстах. Эти алгоритмы, оперируя статистическими закономерностями в распределении слов, склонны упускать из виду тонкие смысловые нюансы и идиоматические выражения, характерные для кратких сообщений. В результате, темы, выделяемые этими моделями, могут быть обобщенными, неконкретными и не отражать истинного содержания текста, особенно в ситуациях, когда значение зависит от контекста и неявно подразумевается.
Углубленное понимание: контекст и вложения
Современные методы, такие как векторные представления слов (Word Embeddings) и контекстные тематические модели, позволяют значительно улучшить связность тематик за счет учета семантических связей внутри текста. Традиционные модели часто рассматривают слова изолированно, игнорируя контекст и нюансы значения. В отличие от них, векторные представления слов кодируют каждое слово в виде вектора в многомерном пространстве, где близкие по значению слова располагаются ближе друг к другу. Контекстные модели, такие как BERT и подобные, идут еще дальше, учитывая значение слова в зависимости от окружающего его текста. Это позволяет более точно определять тематику и выявлять скрытые связи между словами и документами, приводя к более когерентным и осмысленным результатам тематического моделирования.
Методы, такие как BERTopic и Структурная тематическая модель (Structural Topic Model), демонстрируют эффективность объединения векторных представлений (embeddings) с алгоритмами кластеризации и метаданными для улучшения процесса обнаружения тем. Векторные представления, полученные с помощью моделей, таких как BERT, позволяют улавливать семантические связи между словами и документами, что существенно повышает когерентность выделяемых тем. Применение кластеризации, например, алгоритма UMAP или HDBSCAN, к этим векторным представлениям позволяет автоматически группировать схожие документы. Интеграция метаданных, таких как дата публикации или автор, в процесс кластеризации и назначения тем позволяет дополнительно уточнить и обогатить результаты тематического моделирования, предоставляя более детальное и контекстуально-релевантное представление данных.
Эффективное использование современных методов тематического моделирования, основанных на векторных представлениях слов и контекстных моделях, требует надежных механизмов информационного поиска для определения релевантного контекста. В стандартных конвейерах тематического моделирования данный этап часто игнорируется или упрощается, что приводит к снижению качества и связности выделенных тем. Определение наиболее значимых документов или фрагментов текста, относящихся к конкретному запросу или проблеме, позволяет точно настроить алгоритмы кластеризации и выявить более четкие и осмысленные тематические группы. Недостаточное внимание к поиску релевантного контекста может привести к формированию тем, которые не отражают истинную семантическую структуру данных и содержат шум или нерелевантную информацию.
NTLRAG: Новая архитектура нарративных тематических меток
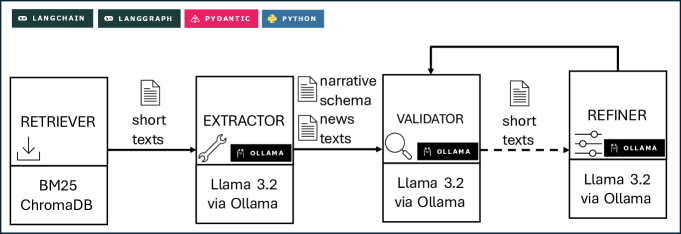
NTLRAG представляет собой усовершенствованный подход к традиционному тематическому моделированию, использующий возможности генерации с извлечением информации (Retrieval-Augmented Generation). В отличие от стандартных методов, которые часто ограничиваются выявлением ключевых слов, NTLRAG динамически дополняет процесс тематического моделирования релевантной информацией, извлеченной из корпуса текстов. Это позволяет создавать не просто метки тем, а содержательные и связные описания, отражающие суть и контекст обсуждаемых нарративов, что существенно повышает информативность и удобочитаемость генерируемых тематических меток.
В основе системы поиска информации в NTLRAG лежит алгоритм BM25, обеспечивающий эффективный поиск релевантных документов. Для хранения векторных представлений слов (Word Embeddings) используется векторная база данных ChromaDB. Это позволяет осуществлять быстрый семантический поиск, сопоставляя запросы не по ключевым словам, а по смысловому содержанию, что значительно повышает точность и скорость извлечения необходимой информации из корпуса текстов.
В основе NTLRAG лежит подход, использующий “нарративную схему” для генерации тематических меток. В отличие от традиционных методов, выдающих лишь ключевые слова, NTLRAG формирует описательные резюме, отражающие суть контента. Оценка человеческой интерпретируемости сгенерированных меток, проведенная в ходе экспериментов, составила в среднем 2.467 баллов, что демонстрирует способность системы создавать понятные и информативные тематические ярлыки, выходящие за рамки простого набора терминов.
Повышение интерпретируемости и практической значимости
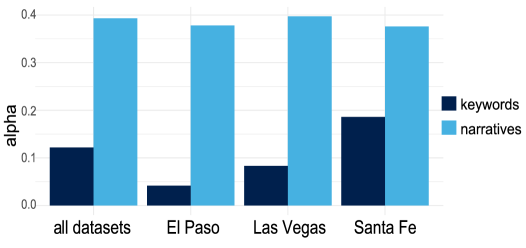
Исследования показали, что метки тем, генерируемые системой NTLRAG, демонстрируют значительно более высокую степень понятности для человека по сравнению с традиционными подходами, основанными на ключевых словах. Средняя оценка понятности для меток, созданных NTLRAG, составила 2.467, в то время как для простых списков ключевых слов этот показатель равен лишь 1.61. Такое существенное различие указывает на то, что NTLRAG способна создавать более связные и осмысленные описания, которые легче воспринимаются и интерпретируются людьми, что является важным шагом к созданию более прозрачных и доступных систем искусственного интеллекта. Системы должны говорить на языке человека, а не на языке статистики.
Исследование продемонстрировало выдающийся уровень понимания сгенерированных системой NTLRAG повествовательных описаний. Подавляющее большинство — 49 из 50 проанализированных текстов — получили наивысшую оценку от экспертов-оценщиков. Этот результат свидетельствует о способности системы создавать не просто информативные, но и легко воспринимаемые и понятные описания, значительно превосходящие традиционные подходы, основанные на ключевых словах. Высокая оценка человеко-читаемости указывает на потенциал данной технологии для широкого применения в задачах, требующих ясного и эффективного представления сложных данных.
Результаты оценки показали, что подавляющее большинство экспертов — 94.73% — либо отдают предпочтение нарративам, сгенерированным NTLRAG, либо оценивают их наравне со списками ключевых слов. Примечательно, что в 63.25% случаев нарративы были строго предпочтены ключевым словам, что свидетельствует о значительном преимуществе предложенного подхода в плане понятности и удобства восприятия информации. Это указывает на то, что NTLRAG способен не просто извлекать информацию, но и представлять ее в форме, более доступной и логичной для человека, что повышает ценность и практическую применимость полученных результатов.
Исследование, представленное в данной работе, демонстрирует, что попытки навязать жесткие структуры коротким текстам часто приводят к потере смысла. Авторы предлагают подход, позволяющий системе не просто извлекать ключевые слова, а формировать нарративные метки, отражающие суть документа. В этом есть глубокая мудрость, ведь, как говорил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». Попытки сразу создать идеальную систему классификации, не учитывая контекст и нюансы языка, обречены на неудачу. Необходимо позволить системе эволюционировать, подобно тому, как вырастает экосистема, а не строить ее по заранее заданному плану. Подход NTLRAG, акцентируя внимание на генерации нарративов, позволяет системе ‘взрослеть’ и приобретать более глубокое понимание смысла.
Что дальше?
Представленная работа, касающаяся генерации нарративных меток тем, несомненно, представляет собой шаг вперёд в попытке примирить автоматизированный анализ текста с человеческим восприятием. Однако, как и любое вмешательство в сложную систему, она лишь обнажает новые уровни неопределённости. Утверждать, что метки, полученные через Retrieval-Augmented Generation, более «интерпретируемы», — значит признать, что интерпретируемость — это не свойство системы, а готовность человека к самообману. Зависимости от исходных данных, используемых для «обогащения» генерации, никуда не делись; они просто замаскированы слоем кажущейся логики.
Будущие исследования неизбежно столкнутся с вопросом масштабируемости. Способность системы поддерживать когерентность и осмысленность при обработке больших объемов текста — это не техническая задача, а экзистенциальный предел. Каждый архитектурный выбор — это пророчество о будущей неспособности адаптироваться к неожиданным данным. Вместо погони за идеальной меткой, возможно, стоит сосредоточиться на создании систем, способных честно признавать собственную некомпетентность.
В конечном счете, технологии сменяются, зависимости остаются. Попытки создать «умные» системы анализа текста лишь иллюзию контроля над хаосом информации. Истинная мудрость заключается в признании того, что системы — это не инструменты, а экосистемы, которые можно лишь взращивать, а не строить.
Оригинал статьи: https://arxiv.org/pdf/2602.17216.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-22 23:00