Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий более эффективно настраивать генеративные модели, превосходящий существующие подходы в стабильности и качестве результатов.
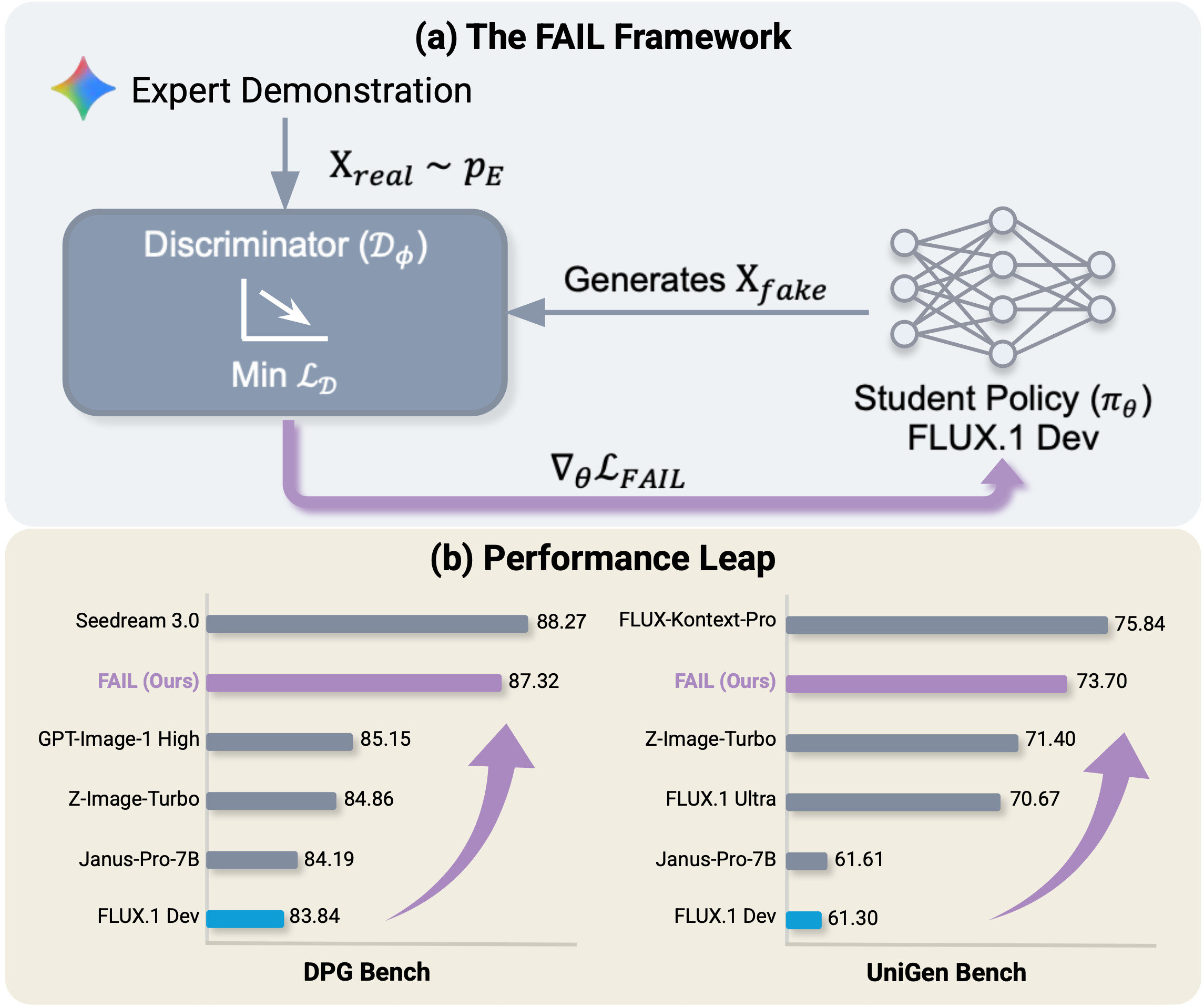
В статье представлена методика FAIL — adversarial imitation learning для пост-тренировочной оптимизации flow matching и diffusion моделей.
Несмотря на успехи в генеративном моделировании, точная адаптация моделей к предпочтениям пользователей и исправление смещения политики в новых условиях остаются сложной задачей. В данной работе, представленной под названием ‘FAIL: Flow Matching Adversarial Imitation Learning for Image Generation’, предложен новый подход к постобучению моделей, основанный на состязательном обучении и имитации экспертных демонстраций. Метод FAIL позволяет минимизировать расхождение между политикой модели и экспертом без использования явных наград или парных сравнений, демонстрируя конкурентоспособные результаты в задачах генерации изображений и видео. Способна ли данная схема состязательного обучения стать надежным регулятором и предотвратить «взлом» системы вознаграждений в задачах обучения с подкреплением?
Выравнивание генеративных моделей: проблема и перспективы
Современные генеративные модели, такие как FLUX, демонстрируют впечатляющие результаты в различных тестах, включая UniGen-Bench и DPG-Bench, успешно генерируя контент, соответствующий заданным параметрам. Однако, несмотря на эти успехи, модели часто сталкиваются с трудностями в последовательном согласовании с человеческими предпочтениями. Несмотря на способность воспроизводить заданные шаблоны и выполнять инструкции, генерируемые ими ответы не всегда соответствуют ожиданиям пользователей в сложных и неоднозначных ситуациях. Эта неспособность надежно соответствовать субъективным критериям оценки представляет собой серьезную проблему, ограничивающую практическое применение этих мощных систем и требующую разработки новых подходов к обучению и контролю.
Несмотря на значительные успехи генеративных моделей, таких как FLUX, в решении различных задач, тонкая настройка с использованием контролируемых данных и оптимизация на основе предпочтений зачастую оказываются недостаточными в сложных ситуациях. Исследования показывают, что эти методы, хотя и улучшают производительность, не способны обеспечить стабильное соответствие модели ожиданиям человека при решении неоднозначных или требующих глубокого понимания контекста задач. Это указывает на фундаментальную проблему в управлении мощными генеративными системами — простого следования заданным предпочтениям недостаточно для достижения надежного и предсказуемого поведения в реальных сценариях, требуя разработки принципиально новых подходов к обучению и контролю.
Для достижения надежного согласования генеративных моделей с человеческими ожиданиями, недостаточно полагаться лишь на простые сигналы предпочтений. Исследования показывают, что настоящий прорыв возможен при переходе к методикам, имитирующим поведение экспертов в конкретной области. Это предполагает не просто определение “нравится/не нравится”, а детальное воспроизведение логики принятия решений, используемых профессионалами при решении сложных задач. Такой подход, ориентированный на экспертное поведение, позволяет моделям не только соответствовать поверхностным предпочтениям, но и демонстрировать глубокое понимание контекста и способность генерировать более качественные и релевантные результаты, особенно в ситуациях, требующих специализированных знаний и критического мышления.
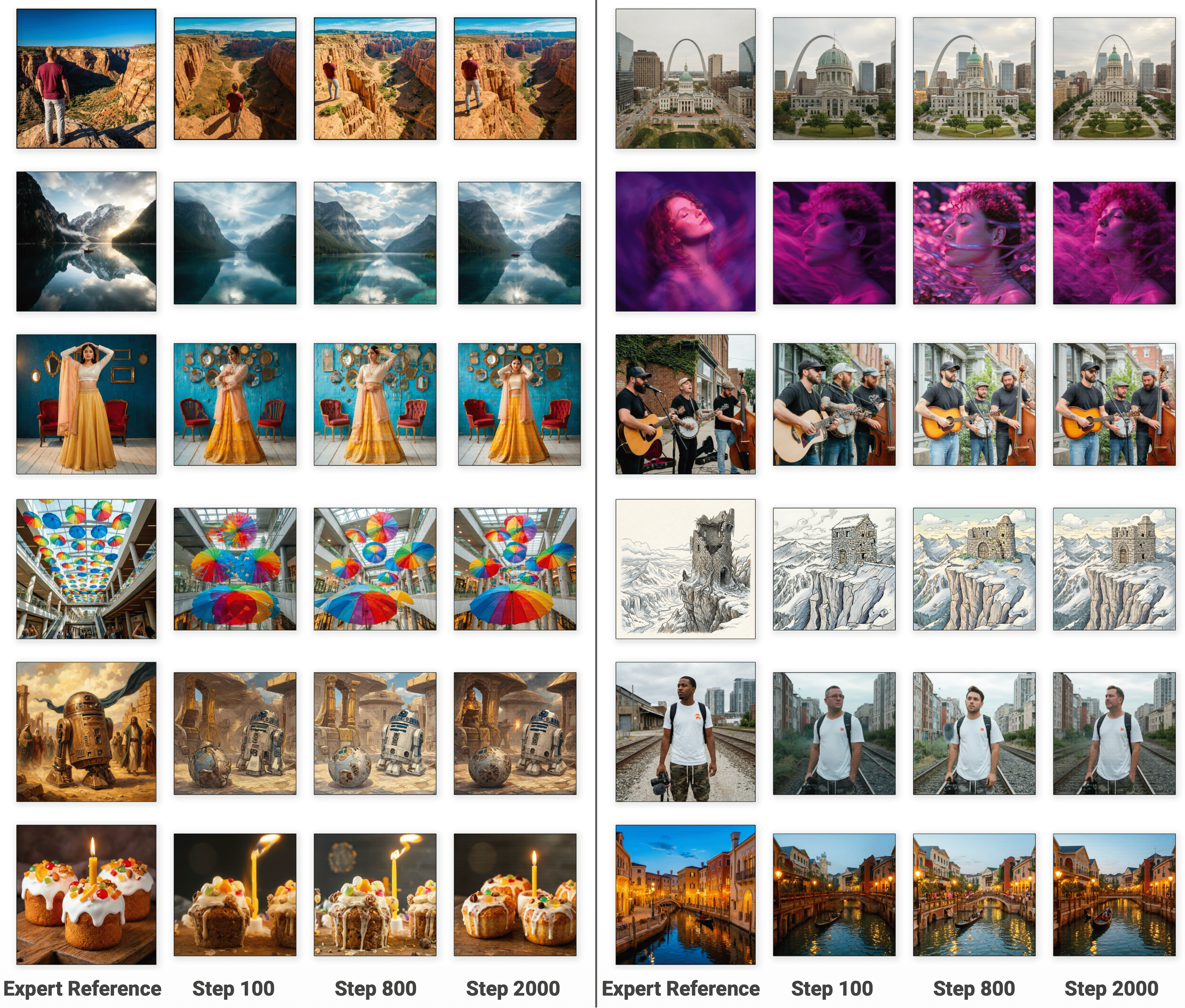
За пределами поведенческого клонирования: эра состязательного подражания
Простое поведенческое клонирование (Behavioral Cloning) часто сталкивается с трудностями при воспроизведении тонкостей экспертной политики. Это связано с тем, что модель обучается на конечном наборе данных, собранном экспертом, и может не обобщать на состояния, не представленные в этом наборе. В результате возникает несоответствие распределений (distribution mismatch) между данными, на которых обучалась модель, и реальными данными, получаемыми в процессе работы. Модель, обученная таким образом, может демонстрировать неуверенное поведение или даже совершать ошибки в ситуациях, незначительно отличающихся от тех, что были представлены в обучающем наборе, что ограничивает ее надежность и применимость в реальных сценариях.
Метод состязательного обучения с подражанием (Adversarial Imitation Learning) представляет собой альтернативный подход к задаче выравнивания (alignment) поведения агента с экспертным, формулируя процесс как игру между генератором и дискриминатором. Генератор стремится создать образцы, имитирующие действия эксперта, а дискриминатор оценивает реалистичность этих образцов, стремясь отличить их от реальных действий эксперта. В процессе этой игры генератор постоянно улучшает свои стратегии, чтобы обмануть дискриминатор, что приводит к генерации более правдоподобных и точных образцов поведения, более точно отражающих экспертную политику. Данный подход позволяет преодолеть ограничения простого поведенческого клонирования, особенно в ситуациях, когда экспертные данные ограничены или зашумлены.
В основе подхода Adversarial Imitation лежит надежный Дискриминатор, задача которого — точная оценка качества генерируемых образцов. В качестве Дискриминатора часто используются модели Vision-Language (VLM), Visual Foundation Models (VFM) или архитектуры Flow Matching (FM). VLM и VFM способны анализировать визуальные данные и сопоставлять их с текстовыми описаниями, что позволяет оценивать соответствие генерируемых действий экспертной политике. Flow Matching (FM) обеспечивает более стабильное обучение и генерацию данных, фокусируясь на непрерывном отображении данных. Эффективность всего подхода напрямую зависит от способности Дискриминатора точно различать реалистичные и нереалистичные образцы, что требует тщательной разработки и обучения этой компоненты.
FAIL: выравнивание политик с помощью надежной оценки градиента
Метод Flow Matching Adversarial Imitation Learning (FAIL) решает проблему оценки градиентов в задачах имитационного обучения, используя передовые методы, такие как Pathwise Derivative и Score Function Estimator. Pathwise Derivative позволяет оценить градиент функции потерь, прослеживая путь через вероятностное пространство, в то время как Score Function Estimator, основанный на оценке градиента логарифма плотности вероятности, обеспечивает более стабильную оценку градиента в условиях высокой размерности. Использование этих методов позволяет FAIL эффективно обучаться на сложных распределениях данных, избегая проблем, связанных с нестабильными или неточными оценками градиентов, характерными для традиционных подходов к имитационному обучению.
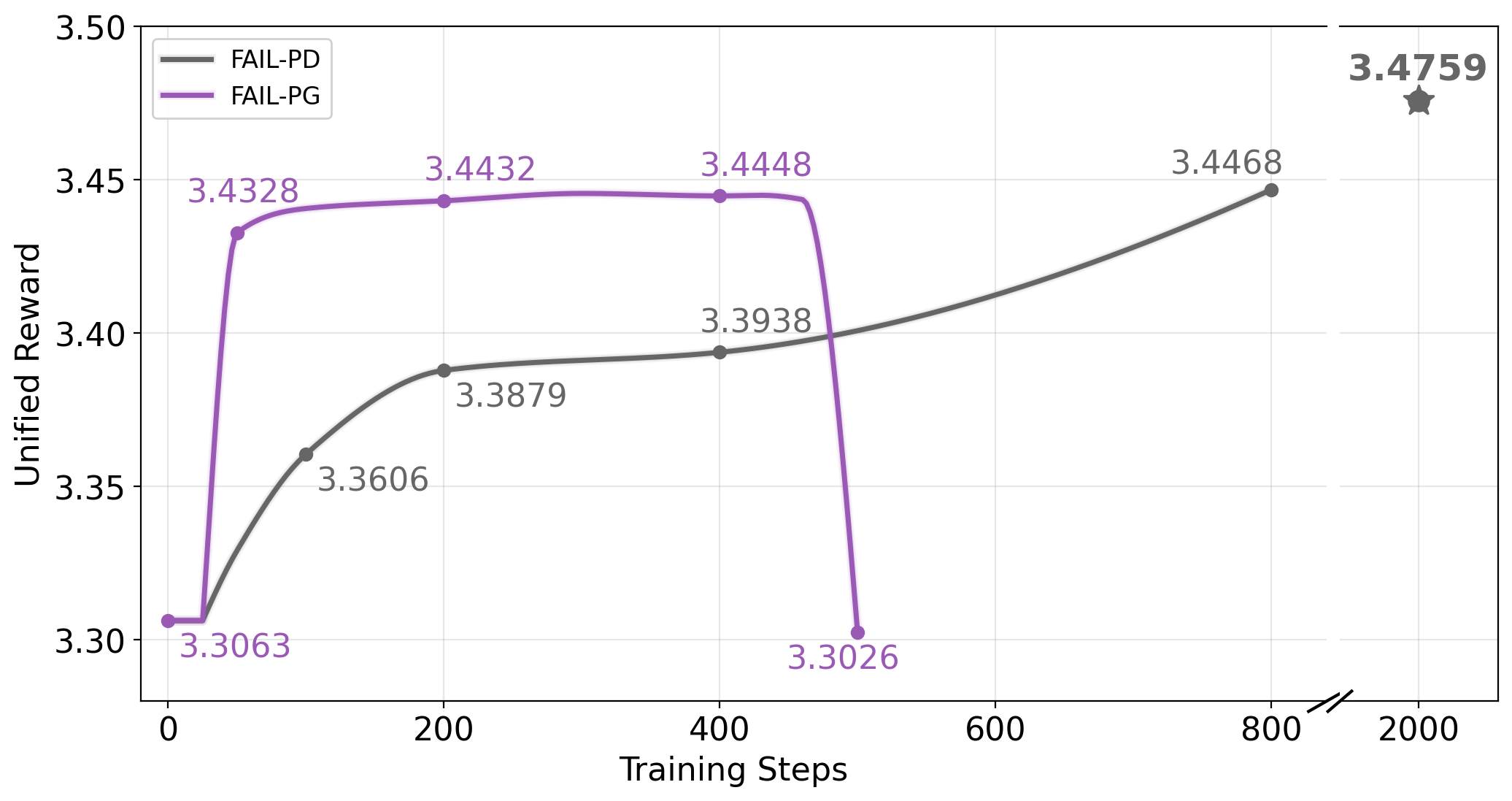
Варианты FAIL-PD и FAIL-PG предоставляют гибкие возможности оценки градиентов, что способствует стабильному и эффективному обучению генератора. FAIL-PD (Pathwise Derivative) использует производную по пути для оценки градиента, в то время как FAIL-PG (Score Function Estimator) применяет оценку функции плотности вероятности. Выбор между этими методами позволяет адаптировать процесс обучения к специфике задачи и данным, оптимизируя скорость сходимости и качество генерируемых образцов. Использование различных методов оценки градиента позволяет минимизировать дисперсию и смещение, обеспечивая более надежное обучение генеративной модели.
В основе FAIL лежит использование функции потерь на основе расхождения Кульбака-Лейблера (KL Divergence), что позволяет генератору более точно приблизить свое распределение к распределению эксперта, тем самым улучшая процесс выравнивания. Экспериментальные результаты показывают, что предложенный фреймворк достигает оценки 73.70 на UniGen-Bench и 87.32 на DPG-Bench, что значительно превосходит результаты базового алгоритма FLUX. Применение KL Divergence способствует стабильности обучения и повышению качества генерируемых данных.
Оценка и подтверждение выравнивания с человеком
Эффективность метода FAIL и подобных ему подходов оценивается, в конечном итоге, по качеству генерируемых результатов, которое измеряется с помощью таких метрик, как HPSv3 и UnifiedReward. В ходе исследований модели, обученные с применением FAIL, продемонстрировали результат в 11.28 баллов по шкале HPSv3, что свидетельствует о значительном улучшении по сравнению с базовым показателем FLUX, составлявшим 10.43. Данный прирост указывает на то, что разработанные методы позволяют создавать генеративные модели, способные производить более предпочтительные для пользователей результаты, и подтверждает их практическую ценность в области искусственного интеллекта.
Устойчивое выравнивание, основанное на экспертных данных, напрямую влияет на способность генеративных моделей последовательно создавать результаты, предпочитаемые людьми. Исследования показывают, что использование высококачественных данных, размеченных специалистами, позволяет моделям не просто генерировать технически корректный контент, но и адаптироваться к тонким нюансам человеческих предпочтений. Этот подход приводит к созданию моделей, которые не требуют постоянной ручной корректировки и способны самостоятельно предлагать решения, наиболее соответствующие ожиданиям пользователей, обеспечивая тем самым повышенное доверие и удобство использования.
Разработка современных генеративных моделей — это не просто погоня за высокими показателями в стандартных тестах. Главная задача — создание систем, заслуживающих доверия, демонстрирующих стабильную и предсказуемую работу, и приносящих реальную пользу пользователям. Акцент смещается с количественных оценок на качественные характеристики, такие как надежность и соответствие ожиданиям. Это предполагает создание моделей, способных генерировать контент, который не просто формально соответствует требованиям, но и является полезным, безопасным и этически приемлемым для широкого круга потребителей. В конечном итоге, успех подобных разработок измеряется не цифрами, а степенью уверенности и удовлетворенности пользователей.

Наблюдая за увлечением flow matching и диффузионными моделями, становится очевидно, что каждая новая архитектура лишь маскирует фундаментальную проблему — необходимость в тонкой настройке. Авторы предлагают FAIL, пытаясь обуздать этот хаос через adversarial imitation learning. Это, конечно, прогресс, но он лишь откладывает неизбежное. Как заметил Дэвид Марр: «Любая вычислительная модель — это всего лишь упрощение реальности, и её точность ограничена теми допущениями, которые мы делаем». В данном случае, FAIL пытается решить проблему post-training alignment, но рано или поздно, найдётся способ обойти эти ограничения, и модель снова начнёт генерировать артефакты. Всё новое — это просто старое с худшей документацией, и эта тенденция, похоже, не собирается меняться.
Что дальше?
Предложенный в данной работе метод FAIL, безусловно, демонстрирует некоторую стабильность в пост-тренировочной адаптации генеративных моделей. Однако, стоит помнить, что любая «стабильность», достигнутая посредством состязательного обучения, — это лишь отсрочка неизбежного. Рано или поздно, дискриминатор найдёт способ обмануть даже самую изощрённую модель, и тогда все эти «улучшения» окажутся просто очередным слоем технического долга. Сейчас это назовут AI и получат инвестиции, а через год начнут искать специалистов по «устранению последствий».
Очевидно, что сама постановка задачи «пост-тренировочной адаптации» является симптомом более глубокой проблемы. Вместо того, чтобы тратить ресурсы на исправление уже созданных моделей, возможно, стоило бы задуматься о создании алгоритмов, которые изначально генерируют более контролируемый и предсказуемый результат. Начинаю подозревать, что они просто повторяют модные слова, пытаясь замаскировать фундаментальную неспособность понять, что происходит внутри этих чёрных ящиков.
В конечном счёте, данная работа — ещё один шаг в бесконечной гонке между создателями и «исправителями» моделей. И, как показывает печальный опыт, рано или поздно, то, что когда-то было простым bash-скриптом, превратится в чудовищный монстр, требующий постоянного внимания и ресурсов. Документация, как обычно, соврёт.
Оригинал статьи: https://arxiv.org/pdf/2602.12155.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-13 23:57